Dans cet article, je veux partager mon expérience dans l'utilisation de cette bibliothèque open source sur l'exemple de la mise en œuvre d'une tâche avec l'analyse de fichiers
PDF / DOC / DOCX contenant des CV de spécialistes.
Ici, je décrirai également les étapes de mise en œuvre de l'outil de préparation de l'ensemble de données. Ensuite, il sera possible de former le modèle
BERT sur l'ensemble de données reçu dans le cadre de la tâche de reconnaissance des entités à partir des textes (
Named Entity Recognition - ci-après
NER ).
Alors, par où commencer. Naturellement, vous devez d'abord installer et configurer l'environnement pour exécuter notre outil. Je vais installer sur
Windows 10 .
Sur Habré il y a déjà plusieurs articles des développeurs de cette bibliothèque, où il y a juste un guide d'installation détaillé. Et dans cet article, je voudrais tout rassembler, du lancement à la formation de modèle. J'indiquerai également des solutions à certains des problèmes que j'ai rencontrés en travaillant avec cette bibliothèque.
IMPORTANT: lors de l'installation, il est important de respecter les versions de tous les produits et composants, car souvent des problèmes surviennent avec des versions incompatibles. Cela est particulièrement vrai pour la bibliothèque TensorFlow . Il arrive même que pour certaines tâches, jusqu'à la validation nécessaire sur GitHub, vous devez l'utiliser. Dans le cas de DeepPavlov , la conformité avec uniquement la version prise en charge est suffisante.
Je vais indiquer les versions de produit de la configuration de travail et les spécifications de mon ordinateur portable sur lequel j'ai commencé le processus de formation du réseau neuronal. Je fournirai quelques liens qui décrivent également l'installation et la configuration de la bibliothèque open-source
DeepPavlov .
Liens utiles des développeurs DeepPavlov
Versions des composants pour l'installation
- Python 3.6.6 - 3.7
- Visual Studio Community 2017 (facultatif)
- Outils de génération Visual C ++ 14.0.25420.1
- nVIDIA CUDA 10.0.130_411.31_win10
- cuDNN-10.0-windows10-x64-v7.6.5.32
Configuration de l'environnement pour la prise en charge du GPU
- Installez Python ou Visual Studio Community 2017 inclus avec Python . Dans mon installation, j'ai utilisé la deuxième méthode, l'installation de Visual Studio Community avec le support Python .
Bien sûr, vous devez ajouter manuellement le chemin d'accès au dossierC:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64
à la variable système PATH , où Python est installé à partir de Visual Studio, mais ce n'est pas un problème pour moi, il est important pour moi de savoir que j'ai installé une version pour Python .
Mais c'est mon cas, vous pouvez tout installer séparément. - L'étape suivante consiste à installer les outils de génération Visual C ++ .
- Ensuite, installez nVIDIA CUDA .
IMPORTANT: si la bibliothèque nVIDIA CUDA a déjà été installée, vous devez supprimer tous les composants précédemment installés de nVIDIA, jusqu'au pilote vidéo. Et seulement alors, sur une installation propre du pilote vidéo, effectuez l'installation de nVIDIA CUDA .
- Installez maintenant cuDNN pour nVIDIA CUDA .
Pour ce faire, vous devez vous inscrire à l' adhésion au programme pour développeurs NVIDIA (c'est gratuit).

- Télécharger la version cuDNN pour CUDA 10.0

- Décompressez l'archive dans un dossier
C:\Users\<_>\Downloads\cuDNN
- Copiez tout le contenu du dossier .. \ cuDNN dans le dossier où nous avons installé CUDA
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
- Redémarrez l'ordinateur. Facultatif, mais je recommande.
Installez DeepPavlov
- Créez et activez l'environnement Python virtuel.
IMPORTANT: je l'ai fait via Visual Studio.
- Pour ce faire, j'ai créé un nouveau projet pour le code From Existing Python .

- Nous appuyons sur la dernière fenêtre, mais sur Terminer, nous ne cliquons pas encore. Vous devez décocher la case " Détecter les environnements virtuels "

- Cliquez sur Terminer .
- Vous devez maintenant créer un environnement virtuel.

- Nous laissons tout par défaut.

- Ouvrez le dossier du projet sur la ligne de commande. Et exécutez la commande:
.\env\Scripts\activate.bat

- Maintenant, tout est prêt à installer DeepPavlov . Nous exécutons la commande:
pip install deeppavlov
- Ensuite, vous devez installer TensorFlow 1.14.0 avec prise en charge GPU . Pour ce faire, exécutez la commande:
pip install tensorflow-gpu==1.14.0
- Presque tout est prêt. Il vous suffit de vous assurer que TensorFlow utilisera la carte graphique pour les calculs. Pour ce faire, nous écrivons un simple script devices.py , le contenu suivant:
from tensorflow.python.client import device_lib print(device_lib.list_local_devices())
ou tensorflow_test.py :
import tensorflow as tf tf.test.is_built_with_cuda() tf.test.is_gpu_available(cuda_only=False, min_cuda_compute_capability=None)
- Après avoir exécuté devices.py , nous devrions voir quelque chose comme ceci:
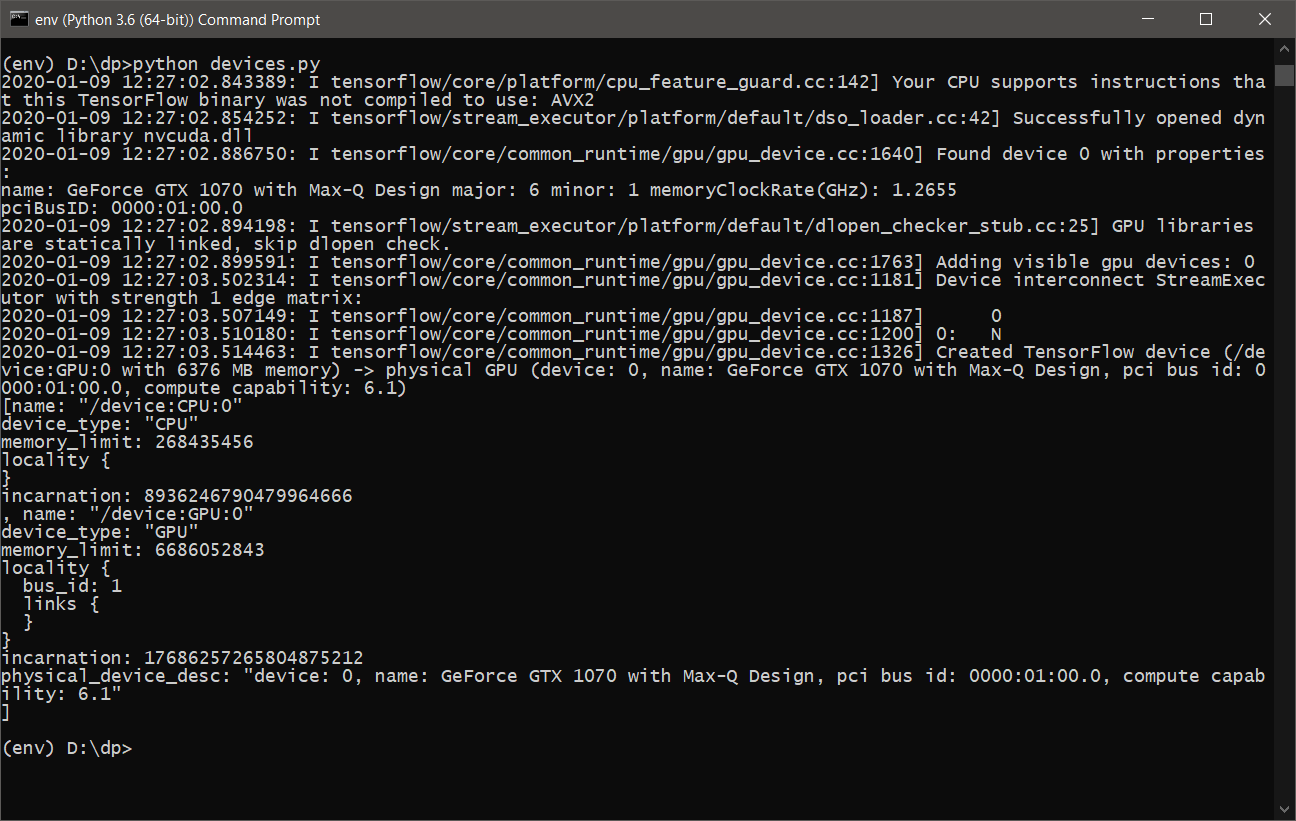
- Vous êtes maintenant prêt à apprendre et à utiliser DeepPavlov avec prise en charge GPU .
DeepPavlov sur l'API REST
Pour démarrer et installer le service pour l'API REST, vous devez exécuter les commandes suivantes:
- Installer dans un environnement virtuel actif
python -m deeppavlov install ner_ontonotes_bert_mult
- Téléchargez le modèle ner_ontonotes_bert_mult à partir des serveurs DeepPavlov
python -m deeppavlov download ner_ontonotes_bert_mult
- Exécutez l'API REST
python -m deeppavlov riseapi ner_ontonotes_bert_mult -p 5005
Ce modèle sera disponible sur
http: // localhost: 5005 . Vous pouvez spécifier votre port.
Tous les modèles seront téléchargés par défaut en cours de route.
C:\Users\<_>\.deeppavlov
Configuration de DeepPavlov pour la formation
Avant de commencer le processus d'apprentissage, nous devons configurer
DeepPavlov afin que le processus d'apprentissage ne "
plante " pas avec l'erreur que la mémoire de notre carte vidéo est pleine. Pour cela, nous avons des fichiers de configuration pour chaque modèle.
Comme dans l'exemple des développeurs, je vais également utiliser le modèle
ner_ontonotes_bert_mult . Toutes les configurations par défaut de
DeepPavlov sont situées le long du chemin:
<_>\env\Lib\site-packages\deeppavlov\configs\ner
Dans mon cas, le fichier sera nommé comme le modèle
ner_ontonotes_bert_mult.json .
Pour ma configuration d'ordinateur portable, j'ai dû changer la valeur de
batch_size dans le bloc de
train à 4.

Sinon, ma carte vidéo s'est «étouffée» après quelques minutes et le processus d'apprentissage est tombé avec une erreur.
Configuration de Nobook
- Modèle: MSI GS-65
- Processeur: Core i7 8750H 2200 MHz
- La quantité de mémoire installée: 32 Go DDR-4
- Disque dur: 512 Go SSD
- Carte vidéo: GeForce GTX 1070 8192 Mo
Outil de préparation de jeu de données
Pour former le modèle, vous devez préparer un ensemble de données. L'ensemble de données se compose de trois fichiers
train.txt ,
valid.txt ,
test.txt . Avec une ventilation des données dans le train de pourcentage suivant - 80%, valide et test pour 10%.
L'ensemble de données pour le modèle BERT est le suivant:
Ivan B-PERSON Ivanov I-PERSON Senior B-WORK_OF_ART Java I-WORK_OF_ART Developer I-WORK_OF_ART IT B-ORG - I-ORG Company I-ORG Key O duties O : 0 Java B-WORK_OF_ART Python B-WORK_OF_ART CSS B-WORK_OF_ART JavaScript B-WORK_OF_ART Russian B-LOC Federation I-LOC . O Petr B-PERSON Petrov I-PERSON Junior B-WORK_OF_ART Web I-WORK_OF_ART Developer I-WORK_OF_ART Boogle B-ORG IO ' O ve O developed O Web B-WORK_OF_ART - O Application O . Skills O : O ReactJS B-WORK_OF_ART Vue B-WORK_OF_ART - I-WORK_OF_ART JS I-WORK_OF_ART HTML B-WORK_OF_ART CSS B-WORK_OF_ART Russian B-LOC Federation I-LOC . O ...
Le format de l'ensemble de données est le suivant:
<_><><_>
IMPORTANT: après la fin de la phrase, il doit y avoir un saut de ligne. Si l'offre contient plus de 75 jetons, il est également nécessaire de mettre un saut de ligne, sinon lors de l'apprentissage du modèle, le processus échouera.
Pour préparer le jeu de données, j'ai écrit une interface Web où il est possible de télécharger des fichiers
DOC / PDF / DOCX sur un serveur, de les analyser en texte brut, puis d'exécuter ce texte via un modèle actif avec accès à l'API REST tout en enregistrant le résultat dans une base de données intermédiaire. Pour cela, j'utilise
MongoDB .
Une fois les actions ci-dessus terminées, vous pouvez procéder à la formation de l'ensemble de données pour nos besoins.
Pour ce faire, dans mon interface Web écrite, j'ai créé un panneau séparé où il est possible de rechercher par jetons de jeu de données, puis de changer le type de jeton et le texte du jeton lui-même.
L'outil sait également comment, automatiquement, sur la base d'une liste de mots, mettre à jour le type de jeton spécifié par l'utilisateur sur demande.
En général, l'outil permet d'automatiser une partie du travail, mais vous devez toujours faire beaucoup de travail manuel.
Une interface pour vérifier le résultat et diviser l'ensemble de données en trois fichiers est également implémentée.
Formation DeepPavlov
Nous sommes donc arrivés à la partie la plus intéressante. Pour le processus d'apprentissage, vous devez d'abord télécharger le modèle
ner_ontonotes_bert_mult , si vous ne l'avez pas déjà fait, vous devez effectuer les deux premières étapes de la section
DeepPavlov vers l'API REST ci-dessus.
Avant de commencer le processus d'apprentissage, vous devez suivre deux étapes:
- Supprimez complètement le dossier avec le modèle formé:
C:\Users\<_>\.deeppavlov\models\ner_ontonotes_bert_mult
Depuis ce modèle a été formé sur un ensemble de données différent. - Copiez les fichiers de jeu de données préparés train.txt, valid.txt, test.txt dans le dossier
C:\Users\<_>\.deeppavlov\downloads\ontonotes
Vous pouvez maintenant démarrer le processus d'apprentissage.
Pour commencer la formation, vous pouvez écrire un simple script
train.py de la forme suivante:
from deeppavlov import configs, train_model ner_model = train_model(configs.ner.ner_ontonotes_bert_mult, download=False)
ou utilisez la ligne de commande:
python -m deeppavlov train <_>\env\Lib\site-packages\deeppavlov\configs\ner\ner_ontonotes_bert_mult.json
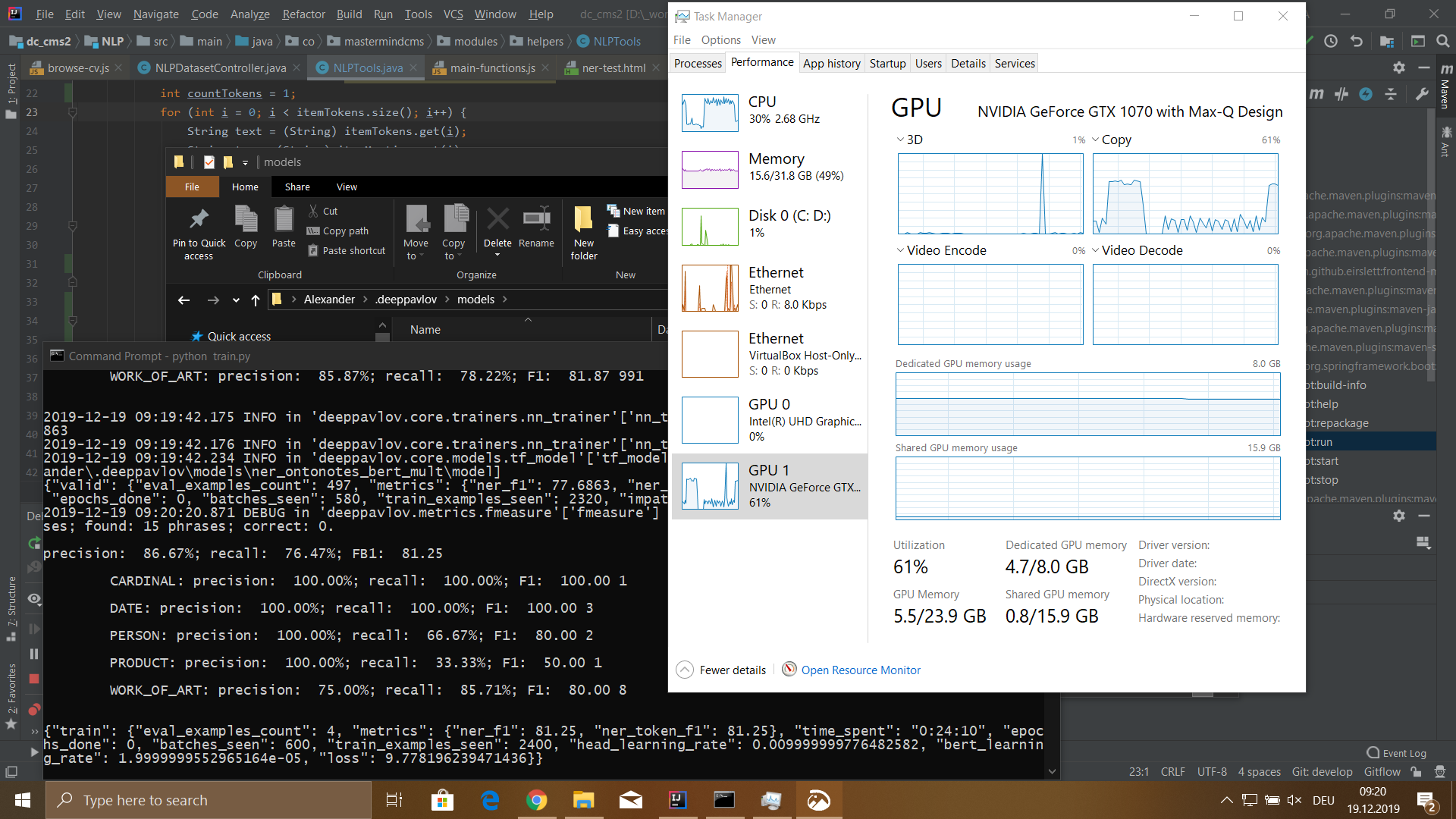
Résultats
J'ai formé un modèle sur un ensemble de données d'une taille de 115 540 jetons. Cet ensemble de données a été généré à partir de 100 fichiers de CV d'employés. Le processus d'apprentissage m'a pris 5 heures 18 minutes.
Le modèle avait les significations suivantes:
- précision: 76,32%;
- rappel: 72,32%;
- FB1: 74,27;
- perte: 5,4907482981681826;
Après avoir édité plusieurs problèmes dans la génération automatique de l'ensemble de données, j'ai reçu une
perte ci-dessous. Mais en général, j'étais satisfait du résultat. Bien sûr, j'ai encore beaucoup de questions sur l'utilisation de cette bibliothèque, et ce que j'ai décrit ici n'est qu'une goutte dans le seau.
J'ai beaucoup aimé la bibliothèque pour sa simplicité et sa facilité d'utilisation. Au moins pour la tâche
NER . Je serai très heureux de discuter d'autres fonctionnalités de cette bibliothèque et j'espère que quelqu'un trouvera le matériel de cet article utile.