Présentation
Comprendre comment le classificateur décompose l'espace multidimensionnel initial d'attributs en plusieurs classes cibles est une étape importante pour analyser tout problème de classification et évaluer la solution obtenue à l'aide de l'apprentissage automatique.
Les approches modernes de visualisation des décisions des classificateurs utilisent principalement des diagrammes de dispersion qui ne peuvent afficher que les projections des échantillons d'apprentissage originaux, mais ne montrent pas explicitement les limites réelles de la prise de décision, ou utilisent la structure interne du classificateur (par exemple, kNN, SVM, régression logistique) pour laquelle il est facile de construire une géométrie interprétation. Cette méthode ne convient pas pour la visualisation, par exemple, d'un classificateur de réseau neuronal.
L'article "Visualisation basée sur l'image des limites de décision du classificateur" (Rodrigues et al., 2018) propose une méthode alternative efficace, belle et assez simple pour visualiser les solutions du classificateur, qui est dépourvue des inconvénients ci-dessus. À savoir, la méthode convient aux classificateurs de toute nature et établit les limites de la prise de décision en utilisant des images avec un taux d'échantillonnage arbitraire.
Ce message est un bref aperçu des principales idées et résultats de l'article d'origine.
Description de la méthode
La base de la méthode est l'échantillonnage inverse (eng. Upsampling) du plan de l'image  qui est représenté par un ensemble de pixels dans l'espace de fonctionnalité
qui est représenté par un ensemble de pixels dans l'espace de fonctionnalité  .
.
La méthode nécessite deux mappages  - projection directe de l'espace caractéristique vers le plan image et l'inverse
- projection directe de l'espace caractéristique vers le plan image et l'inverse  . En tant que telles cartographies, LAMP (Joia et al. 2011) et iLAMP (Amorim et al. 2012) , respectivement, sont utilisés.
. En tant que telles cartographies, LAMP (Joia et al. 2011) et iLAMP (Amorim et al. 2012) , respectivement, sont utilisés.
Immeuble
Pour créer une image, vous devez attribuer une couleur à chaque pixel. Pour cela, pour chaque pixel  va trouver
va trouver  points de l'hyperespace source où
points de l'hyperespace source où  - un paramètre spécifié par l'utilisateur. Laissez le pixel a déjà
- un paramètre spécifié par l'utilisateur. Laissez le pixel a déjà  de vrais prototypes de l'ensemble de formation. Ensuite, choisissez uniformément
de vrais prototypes de l'ensemble de formation. Ensuite, choisissez uniformément  les points restants de la surface des pixels et trouver le prototype pour eux à travers la projection arrière
les points restants de la surface des pixels et trouver le prototype pour eux à travers la projection arrière  . Ainsi, la couleur de chaque pixel sera déterminée par au moins points de l'espace source, et l'image entière sera peinte.
. Ainsi, la couleur de chaque pixel sera déterminée par au moins points de l'espace source, et l'image entière sera peinte.
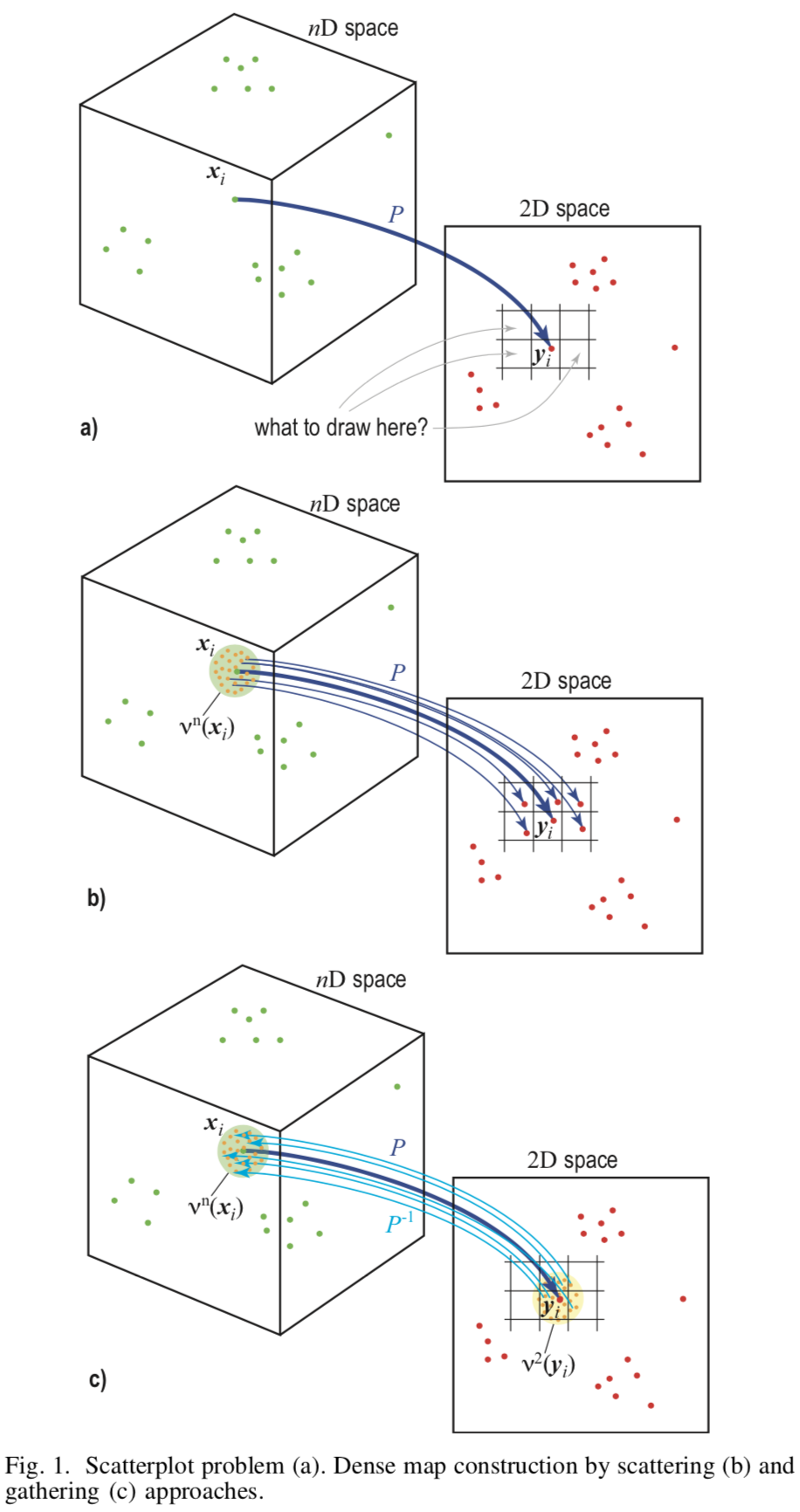
[Fig.1] Illustration schématique de différentes approches
Définition des couleurs
La couleur  chaque pixel déterminé par un vote majoritaire pour les étiquettes de classe des préimages correspondantes.
chaque pixel déterminé par un vote majoritaire pour les étiquettes de classe des préimages correspondantes.
![d (y) = \ text {argmax} _ {k \ in C} \ sum_ {y_i \ in y} [f (P ^ {- 1} (y_i)) = k]](https://habrastorage.org/getpro/habr/post_images/469/c8d/c50/469c8dc5021ee22be2190d80d4a8f9bd.svg)
où  - beaucoup de toutes les classes,
- beaucoup de toutes les classes,  - classificateur.
- classificateur.
Chaque classe se verra attribuer un ton (eng. Hue)  - si la projection a des points de l'échantillon réel et un ton légèrement changé
- si la projection a des points de l'échantillon réel et un ton légèrement changé  pour les pixels dans lesquels il n'y a que des points synthétiques.
pour les pixels dans lesquels il n'y a que des points synthétiques.
Confusion
Définir le mélange de pixels (à partir de la confusion anglaise)  - comme le rapport du nombre d'étiquettes de la classe dominante au nombre total d'images inversées de pixels :
- comme le rapport du nombre d'étiquettes de la classe dominante au nombre total d'images inversées de pixels :
![c (y) = \ frac {\ max_ {k \ in C} \ sum_ {y_i \ in y} [f (P ^ {- 1} (y_i)) = k]} {| y |}](https://habrastorage.org/getpro/habr/post_images/62d/5e7/47f/62d5e747f958e587200665af682cbae9.svg)
Haute valeur indique la cohérence du classificateur, tandis qu'une valeur faible signale une approche de la frontière de division. Mélanger les informations encodées en saturation de pixels  - plus la consistance est élevée, plus la saturation est élevée.
- plus la consistance est élevée, plus la saturation est élevée.
Densité
Bien qu'un minimum ait été généré des points de pré-image pour chaque pixel, il peut y avoir des pixels pour lesquels il y a beaucoup plus de points réels de l'ensemble d'apprentissage. Ces pixels doivent être pris en compte lors du rendu. Pour ce faire, entrez la densité de pixels  comme le nombre de ses points d'image inverses de . On pourrait utiliser cette densité directement pour déterminer la luminosité d'un pixel comme
comme le nombre de ses points d'image inverses de . On pourrait utiliser cette densité directement pour déterminer la luminosité d'un pixel comme  , mais les auteurs de l'article soulignent que cela ne donne pas le résultat souhaité, car certains tons sont évidemment plus sombres que d'autres. Par conséquent, un réglage plus sophistiqué est utilisé à la fois de saturation et de luminosité grâce à un paramètre de densité normalisé.
, mais les auteurs de l'article soulignent que cela ne donne pas le résultat souhaité, car certains tons sont évidemment plus sombres que d'autres. Par conséquent, un réglage plus sophistiqué est utilisé à la fois de saturation et de luminosité grâce à un paramètre de densité normalisé.

Alors si ![\ hat {\ rho} \ in [0, 0,5]](https://habrastorage.org/getpro/habr/post_images/5f3/8f9/0c5/5f38f90c57fe8c26092278e6a36b55c7.svg) - la luminosité dépend linéairement du paramètre à l'intérieur
- la luminosité dépend linéairement du paramètre à l'intérieur ![[V_ {min} = 0,1, V_ {max} = 1]](https://habrastorage.org/getpro/habr/post_images/b1e/ef5/e22/b1eef5e220c553d3c437ee6ddb9f4f08.svg) . À
. À ![\ hat {\ rho} \ in [0,5, 1]](https://habrastorage.org/getpro/habr/post_images/4cc/04d/a79/4cc04da7997da643ef6671babba1ec57.svg) commence à croître linéairement la saturation de
commence à croître linéairement la saturation de  avant
avant  .
.
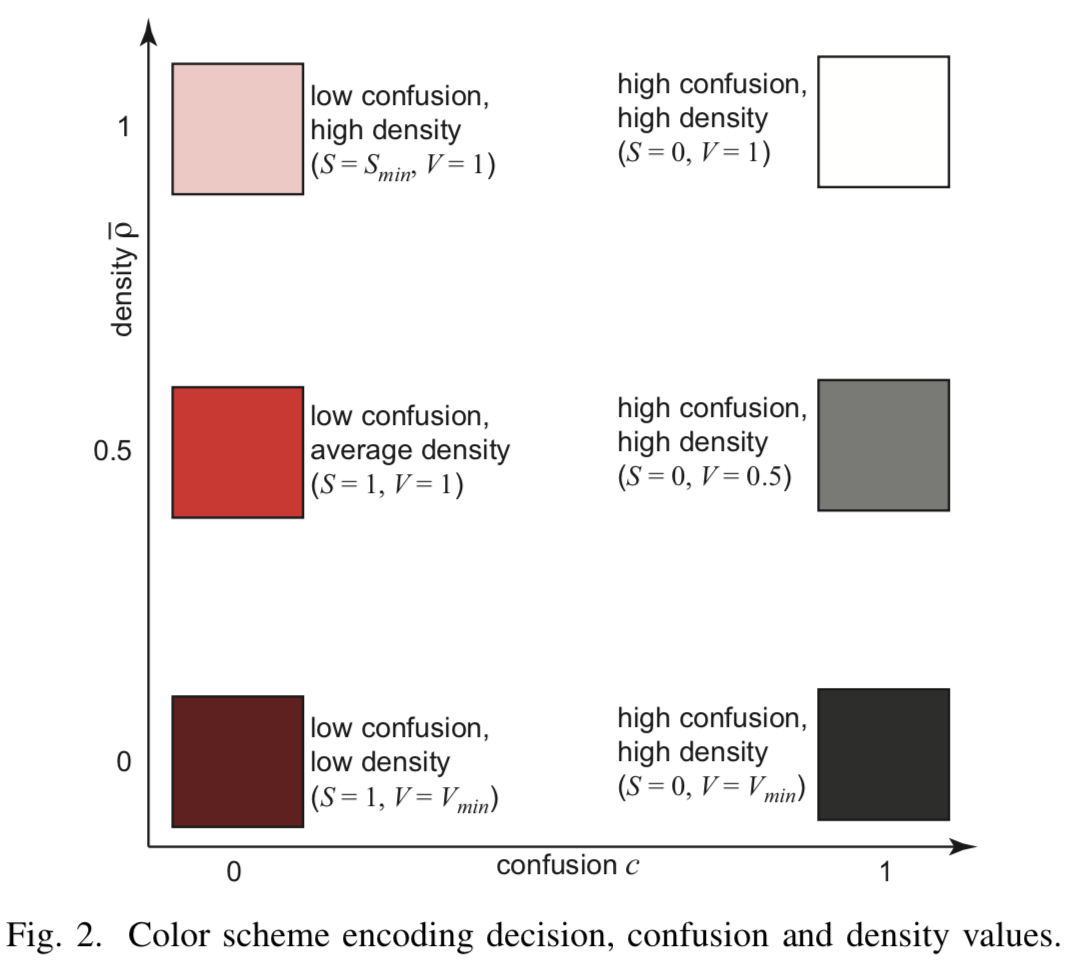
[Fig.2] Codage couleur
Expériences et résultats
Pour les expériences, les problèmes de classification binaire sur l'ensemble d'images numériques MNIST et de classification multiclasse sur l'ensemble de données de segmentation d'image , qui contient 2 310 images divisées en 7 classes, ont été résolus. Il y a 19 attributs pour chaque image.
Imagerie des résultats avec différents paramètres de résolution  et le nombre minimum de prototypes pour le classificateur binaire LogisticRegression sur MNIST sont montrés dans la figure [3]. Les classes sont séparées par une ligne droite avec une grande précision et l'algorithme de visualisation fait un excellent travail. Avec une résolution croissante, les nuages des points source se dissolvent presque complètement parmi les nombreux points générés.
et le nombre minimum de prototypes pour le classificateur binaire LogisticRegression sur MNIST sont montrés dans la figure [3]. Les classes sont séparées par une ligne droite avec une grande précision et l'algorithme de visualisation fait un excellent travail. Avec une résolution croissante, les nuages des points source se dissolvent presque complètement parmi les nombreux points générés.
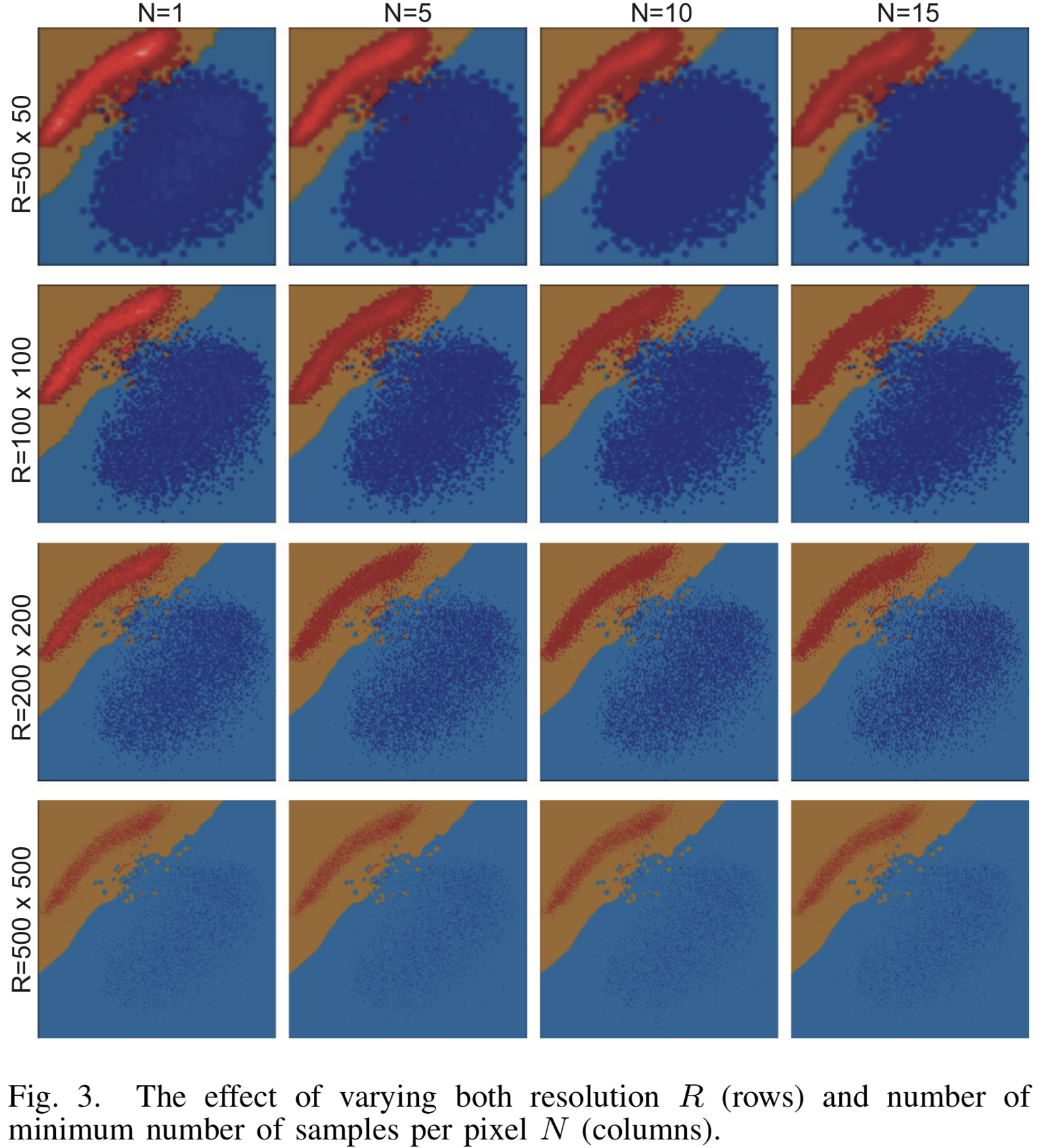
[Fig. 3] Le résultat de la visualisation pour divers paramètres de résolution et le nombre minimal d'échantillons N pour le classificateur LogisticRegression
Visualisation lorsque  pour trois classificateurs différents pour la classification multiple dans la figure [4]. Les projections des points de départ sont fortement mitigées et il n'est pas possible de construire des frontières de division explicites aux endroits où les projections des cas de test sont accumulées. Cependant, en dehors du cluster principal, des limites de classe explicites ont été obtenues, dont les informations ne sont pas affichées sur les projections ordinaires, mais uniquement à l'aide de points synthétiques.
pour trois classificateurs différents pour la classification multiple dans la figure [4]. Les projections des points de départ sont fortement mitigées et il n'est pas possible de construire des frontières de division explicites aux endroits où les projections des cas de test sont accumulées. Cependant, en dehors du cluster principal, des limites de classe explicites ont été obtenues, dont les informations ne sont pas affichées sur les projections ordinaires, mais uniquement à l'aide de points synthétiques.
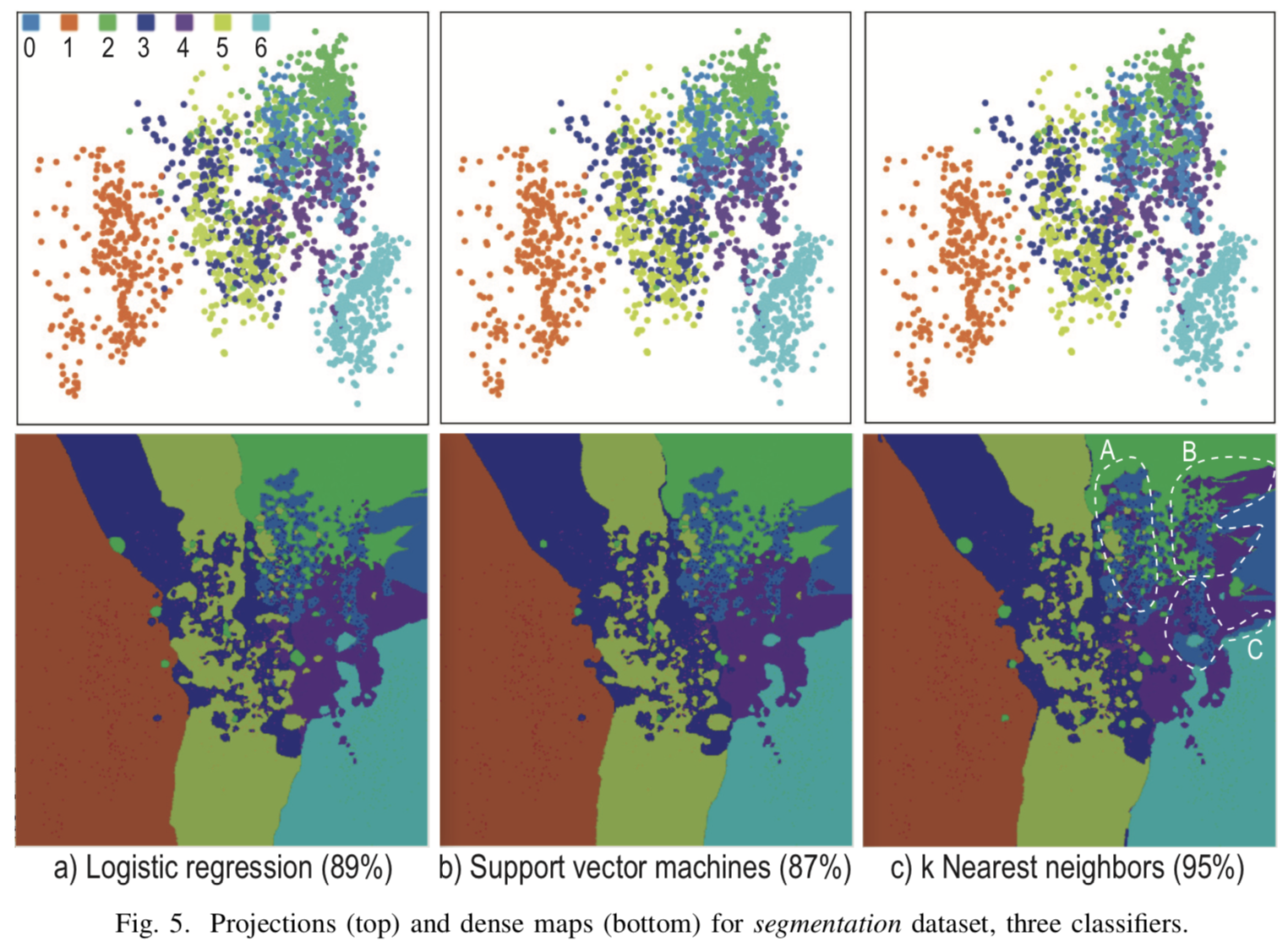
[Fig. 4] Le résultat de la visualisation de trois classificateurs différents pour k = 7, R = 500x500, N = 5
Conclusion
La visualisation des limites de classe peut être utilisée dans la construction et le débogage d'un algorithme décisif, dans la sélection d'hyperparamètres, dans la lutte contre la reconversion, pour présenter et analyser les résultats.
La méthode décrite par les auteurs de l'article d'origine peut être utilisée pour tout problème de classification, où les données peuvent être représentées comme un ensemble de signes d'une dimension fixe. Contrairement à d'autres algorithmes de visualisation, cette approche peut être utilisée pour tout classificateur arbitrairement complexe et pour les ensembles de données avec un nombre arbitraire d'exemples, même avec un très petit, car même avec de petites l'algorithme fonctionne de manière stable, sans perdre beaucoup de qualité.