Bonjour à tous!
Vous connaissez peut-être déjà l'initiative Machine Learning for Social Good (# ml4sg) de la communauté Open Data Science. Dans son cadre, les passionnés utilisent des méthodes d'apprentissage automatique pour résoudre gratuitement des problèmes importants sur le plan social. Nous, l'équipe du projet Lacmus (#proj_rescuer_la), sommes engagés dans la mise en œuvre de solutions modernes de Deep Learning pour retrouver les personnes perdues en dehors de la zone peuplée: dans la forêt, sur le terrain, etc.

Selon des estimations approximatives, en Russie, plus de cent mille personnes disparaissent chaque année. La partie tangible d'entre eux sont des gens qui ont perdu leur chemin loin de l'habitation humaine. Heureusement, certains de ceux qui sont perdus sont choisis par eux-mêmes; des équipes bénévoles de recherche et de sauvetage sont mobilisées pour aider les autres. Le détachement le plus célèbre est peut-être Lisa Alert, mais je tiens à souligner qu'il n'est pas le seul.
Les principales méthodes de recherche actuelles, au XXIe siècle, consistent à peigner les environs à pied à l'aide de moyens techniques, qui ne sont souvent pas plus compliqués qu'une sirène ou un phare bourdonnant. Le sujet, bien sûr, est pertinent et brûlant, donne lieu à de nombreuses idées pour utiliser le progrès scientifique et technologique dans la recherche de réalisations; certains d'entre eux sont même incarnés sous forme de prototypes et testés lors de compétitions spécialement organisées. Mais la forêt est la forêt, et les conditions réelles de la recherche, couplées aux ressources matérielles limitées, rendent ce problème difficile et encore très loin d'une solution complète.
Récemment, les sauveteurs utilisent de plus en plus de véhicules aériens sans pilote (UAV) pour arpenter de vastes zones du territoire, photographiant le terrain à une hauteur de 40 à 50 m. En une seule opération de recherche et de sauvetage, plusieurs milliers de photographies sont obtenues et, à ce jour, les volontaires les parcourent manuellement. Il est clair qu'un tel traitement est long et inefficace. Après deux heures d'un tel travail, les volontaires se fatiguent et ne peuvent pas continuer la recherche, et après tout, la santé et la vie des gens dépendent de sa vitesse.
En collaboration avec les équipes de recherche et de sauvetage, nous développons un programme de recherche de personnes disparues sur les images prises avec des drones. En tant que spécialistes de l'apprentissage automatique, nous nous efforçons de rendre la recherche automatique et rapide.

Différences par rapport à des solutions similaires
Il serait injuste de dire que Lacmus est le seul projet développé dans cette direction. Cependant, il semble que peu de personnes se développent en étroite coopération avec les équipes de secours, en se concentrant sur leurs besoins et capacités urgents. Il y a quelque temps, le concours Odyssey a eu lieu, dans lequel différentes équipes ont concouru à la formation de la meilleure solution pour rechercher et sauver des personnes, y compris en utilisant des drones. Étant au stade initial de développement, nous avons assisté à ce concours non pas en tant que participants, mais en tant qu'observateurs. En comparant les résultats du concours, des informations sur des projets similaires et notre expérience dans la communication avec des équipes telles que Lisa Alert, Owl, Extreme, je tiens à noter les problèmes inhérents à de nombreux analogues:
- Le coût de la mise en œuvre. Certaines équipes du concours Odyssey développent leurs propres drones et drones innovants. Mais vous devez comprendre que les OSP en Russie fonctionnent généralement à but non lucratif, et équiper les opérateurs de drones avec des machines d'une valeur supérieure à 1 000 000 de roubles est trop cher. De plus, il ne suffit pas de produire un avion, il faut en établir la maintenance. Il est difficile pour les petites entreprises d'offrir des solutions au même prix que celles de concurrents chinois coriaces.
- L'orientation commerciale de nombreuses solutions. Il n'y a rien de mal avec les projets d'entreprise, mais trouver des personnes perdues dans la forêt est une tâche assez spécifique; tous les développements commerciaux ne peuvent pas y être intégrés. Vous pouvez faire un merveilleux drone et y coller un neurone reconnaissant les cultures, mais un tel projet ne sera probablement pas utile pour trouver des gens dans la forêt en utilisant des équipes de recherche bénévoles: ici, vous avez besoin de la solution la moins chère mais la plus efficace. Les caméras multicanaux coûteuses ne conviennent pas ici. Seulement RVB, seulement hardcore. Pour les mêmes raisons, les imageurs thermiques disparaissent également, dont les modèles bon marché ont une très faible résolution. (Et en général, les imageurs thermiques sont ici inefficaces, car une personne gelée dans la forêt émet trop peu de chaleur).
- Les architectures de réseaux de neurones populaires utilisées dans les solutions connues - YOLO, SSD, VGG - ont des mesures de bonne qualité sur des ensembles de données publics comme ImageNet, mais ne fonctionnent pas bien sur les images dans notre domaine plutôt spécifique. (À propos du choix de l'architecture du réseau neuronal, des options et fonctionnalités éprouvées utilisées à la fin - ci-dessous).
- Presque personne n'utilise les opportunités pour optimiser les modèles d'inférence. Dans les zones de recherche, il n'y a souvent pas de connexion Internet, vous devez donc traiter les images reçues localement. La plupart des sauveteurs utilisent des ordinateurs portables avec des GPU de faible puissance, ou sans eux, exécutant des réseaux de neurones sur des processeurs conventionnels. Il est facile de calculer que si une moyenne de 10 secondes est consacrée au traitement d'une seule image, 1 000 images seront traitées en environ 3 heures. Ici, nous pouvons dire que chaque seconde est importante.
- Fermeture des développements existants. Toutes les solutions que nous connaissons sont fermées et propriétaires. Mais le problème est trop complexe pour être résolu par les forces d'une petite poignée de personnes, et pas toutes celles qui sont prêtes à aider. Par conséquent, nous développons une solution entièrement Open Source: il est étrange de penser qu'un sujet qui attire autant de bénévoles travaillant «sur le terrain» ne sera pas tout aussi intéressant pour les informaticiens.
- Absence de liberté de distribution. Les OSP volontaires ne sont souvent pas centralisés, les approches de travail et les applications sont transférées de main en main, les logiciels avec des copies sous licence ne fonctionneront pas ici. C'est pourquoi nous avons, entre autres, choisi une stratégie open source et de distribution ouverte afin que chacun puisse télécharger notre solution et l'utiliser. Nous sommes pour l'open science et l'open source!
Préparation des données
Il semblerait que si chaque opération de recherche utilisant des UAV apporte des milliers de photos, la gamme de données accumulées devrait être énorme - prendre et former. Tout n'a pas été aussi simple, car:
- Il n'y a pas de stockage centralisé pour les données balisées. Les photos prises lors des opérations de recherche ne seront pas utilisées ou traitées à l'avenir.
- Les données obtenues sont très déséquilibrées. Dans un cliché avec la personne retrouvée, il y a plusieurs milliers de photographies «vierges». Étant donné que les informations sur les images numérisées ne sont enregistrées nulle part, afin de trouver celles qui sont nécessaires, un énorme travail doit être effectué une deuxième fois - par les efforts d'une petite équipe qui n'a pas «d'yeux entraînés».
- Chaque image, en elle-même, est également «déséquilibrée»: la personne désirée occupe une infime fraction de la zone d'image entière sur elle. De toute évidence, un bon réseau de neurones ne devrait pas seulement être en mesure de dire que, à son avis, une personne est présente dans l'image - il doit encercler un endroit spécifique (c'est-à-dire effectuer la tâche de détecter des objets, pas de classer des images). Sinon, l'opérateur passera plus de temps et d'énergie à la regarder, et il peut également rejeter par erreur la photo souhaitée. Mais pour cela, le réseau neuronal doit apprendre des données balisées, sur les photographies, où l'objet souhaité est marqué à l'aide d'un logiciel spécial. Personne ne le fera pendant une opération de recherche - pas avant.
- Les statistiques sur les poses dans lesquelles les personnes ont été trouvées, la période de l'année, le type de terrain et d'autres caractéristiques des photos ne sont pas prises en compte. De telles données seraient très utiles pour créer des images d'entraînement «synthétiques» à l'aide de photographies mises en scène, de monteurs photo ou de modèles génératifs - mais pour utiliser tout cela, vous devez comprendre à quoi ressemble une photographie avec une personne vraiment perdue. Maintenant, lors de la reconstruction de telles photographies, il faut s'appuyer sur l'expérience subjective d'experts en sauvetage.
- En plus des difficultés techniques, des obstacles juridiques sont possibles qui imposent des restrictions sur la propriété des images obtenues. Souvent, nos demandes d'aide pour la collecte de données restent totalement sans réponse. En raison de l'absence de telles données, de problèmes juridiques ou d'une paresse courante - ce n'est pas clair.
Ainsi, des informations précieuses ne sont en aucun cas utilisées pour la formation de réseaux de neurones, étant perdues ou mortes quelque part sur des disques et des stockages cloud, au lieu d'améliorer le volume et la qualité de l'échantillon d'apprentissage. Nous écrivons un service qui nous permettra, entre autres, de télécharger de précieuses photos (à ce sujet également ci-dessous), mais il y a, comme toujours, plus de tâches que de personnes.
De plus, à ce jour, le réseau a très peu de bons ensembles de données (ouverts) avec des images d'UAV. Le plus approprié que nous avons trouvé est
Stanford Drone Dataset (SDD) . Il s'agit d'une photographie d'une hauteur au-dessus du campus universitaire, avec des objets marqués de la classe "Piéton" (piéton), ainsi que des cyclistes, des bus et des voitures. Malgré un angle de prise de vue similaire, les piétons photographiés et l'environnement ont peu de choses en commun avec ce qui se passe sur nos photos. Les expériences menées sur cet ensemble de données ont montré que les métriques de qualité des détecteurs formés sur lui sur nos données montrent un résultat faible. En conséquence, nous utilisons maintenant SDD pour former le soi-disant backbone, qui extrait les attributs de haut niveau, et les couches extrêmes doivent être complétées sur les images de notre domaine.
C'est pourquoi nous avons d'abord communiqué avec divers moteurs de recherche et sauveteurs pendant une longue période, essayant de comprendre à quoi ressemble une personne perdue dans la forêt sur une photo d'en haut. En conséquence, nous avons collecté des statistiques uniques sur 24 poses, dans lesquelles les personnes disparues sont le plus souvent trouvées. Nous avons filmé et marqué notre propre ensemble de données - Lacmus Drone Dataset (LaDD), qui dans la première version comprenait plus de 400 images. La prise de vue a été réalisée principalement avec l'aide de DJI Mavic Pro et Phantom d'une hauteur de 50 à 100 mètres, la résolution des images était de 3000x4000, la taille moyenne d'une personne était de 50x100 px. À l'heure actuelle, nous avons déjà la quatrième version de l'ensemble de données avec 2 000 images, à la fois réelles et «simulées». Nous continuons à travailler sur la reconstitution de l'ensemble de données et la cinquième version est à nos portes.
Au fur et à mesure que nous reconstituons notre ensemble de données, nous en sommes venus à la nécessité de séparer les images par saison. Le fait est qu'un modèle formé aux photos d'hiver montre de meilleurs résultats qu'un modèle formé sur l'ensemble des données, soit en été soit au printemps séparément. Peut-être que les signes sur fond neigeux sont mieux extraits que sur l'herbe bruyante.

Dans le même temps, lorsque vous vous entraînez uniquement sur des photos d'hiver, le nombre de faux positifs (faux positifs) augmente. Apparemment, les images de saisons différentes sont des paysages (domaines) trop différents et le réseau neuronal n'est pas en mesure de les généraliser. Cela reste à voir, et jusqu'à présent, nous voyons deux façons:
- Faites beaucoup de «petites» grilles et apprenez-les séparément pour différents domaines (un pour l'hiver, un autre pour l'été ... Outre les saisons, vous pouvez également ventiler par zone: par exemple, un modèle pour la bande médiane et les plaines, un autre pour le sud, etc.) .
- Augmentez à plusieurs reprises nos données et essayez de former le modèle à la fois sur tous les domaines. Sur la base de la solution d'un problème similaire dans un article de Yandex, nous avons tendance à essayer cette option particulière. Il est difficile de collecter un grand nombre de vraies photos avec des personnes perdues pour les raisons déjà décrites, donc, peut-être, nous essaierons de recréer des exemples pédagogiques réalistes basés sur des images «vides» (il y en a beaucoup). Nous pourrons donc bientôt avoir des GAN.
Processus d'apprentissage
La nature de nos images est considérablement différente des images d'ensembles de données populaires comme ImageNet, COCO, etc. Étant donné que les réseaux de neurones développés pour de tels ensembles pouvaient être mal adaptés à notre tâche, il était nécessaire de mener une étude de l'applicabilité de diverses architectures. Pour ce faire, nous avons pris des modèles pré-formés sur ImageNet, nous les avons recyclés sur le Stanford Drone Dataset, après quoi nous avons «gelé» les dorsales, et les parties restantes des détecteurs ont été formées directement sur nos images. Les meilleures métriques sont présentées dans le tableau:
En plus des nombres dans le tableau ci-dessus, vous devez faire attention à une telle caractéristique des images du jeu de données du drone Lacmus comme un grand déséquilibre des classes: le rapport de la zone d'arrière-plan à la zone du rectangle (ancre) avec l'objet souhaité est de plusieurs milliers. Lors de la formation du détecteur, cela pose deux problèmes:
- La plupart des régions avec un arrière-plan ne contiennent aucune information utile.
- Les régions avec des objets en raison de leur petit nombre ne contribuent pas non plus de manière significative à la formation des poids.
Afin de contourner ces problèmes, divers programmes de formation, paramètres réseau et exemples de formation ont été utilisés. L'une des architectures de réseaux de neurones que nous avons testées, RetinaNet, vise précisément à réduire les effets négatifs d'un déséquilibre de grande classe. Les créateurs de RetinaNet l'ont conçu pour augmenter la précision des détecteurs à un étage (couvrant l'image avec un réseau dense de rectangles-ancres prédéfinis puis affinant ceux qui couvrent le mieux l'objet) par rapport à des détecteurs à deux étages de meilleure qualité, mais plus lents (les élèves apprennent à trouver les régions candidates en premier , puis précisez leur position). Du point de vue des auteurs de l'article sur RetinaNet, les détecteurs à un étage perdent précisément en raison du déséquilibre causé par un grand nombre d'ancres vides. Dans ce contexte, notre choix a été fait en faveur de RetinaNet avec le backbone ResNet50.
L'architecture de ce réseau a
été introduite en 2017. La principale caractéristique de RetinaNet, qui vous permet de faire face aux effets négatifs des déséquilibres de classe lors de la formation, est la fonction de perte de
perte focale d' origine:
Où
p est la probabilité estimée du contenu dans la région de l'objet souhaité estimée par le modèle (pour le dire simplement, la sortie du réseau neuronal si elle est réduite à l'intervalle [0, 1]).
Dans d'autres domaines, la fonction de perte devrait, en règle générale, être résistante aux instances atypiques (exemples concrets), qui sont très probablement des valeurs aberrantes; leur impact sur la musculation doit être réduit. Dans la perte focale, au contraire, l'influence d'un arrière-plan fréquent (inliers, exemples faciles) est réduite, et les objets rarement vus ont la plus grande influence lors de l'apprentissage des poids RetinaNet. Cela est dû à cette partie de la formule:
Coefficient
dans l'exposant détermine le «poids» des exemples durs dans la fonction de perte totale.
Au cours du processus de formation RetinaNet, la fonction de perte est calculée pour toutes les orientations considérées des zones candidates (ancres), à partir de tous les niveaux de mise à l'échelle de l'image. Au total, il y a environ 100k zones pour une image, ce qui est très différent de l'approche d'échantillonnage heuristique (RPN) ou de la recherche d'instances rares (OHEM, SSD) avec un petit nombre de zones (environ 256) pour chaque mini-lot. La valeur de perte focale est calculée comme la somme des valeurs de fonction pour toutes les ancres, normalisée par le nombre d'ancres contenant les objets souhaités. La normalisation est effectuée uniquement sur eux, et non sur le nombre total, car la grande majorité des ancres sont un fond facilement identifiable, avec peu de contribution à la fonction de perte globale.
Structurellement, RetinaNet se compose d'un backbone et de deux définitions supplémentaires de sous-réseau de classification et de sous-réseau de régression de boîte.
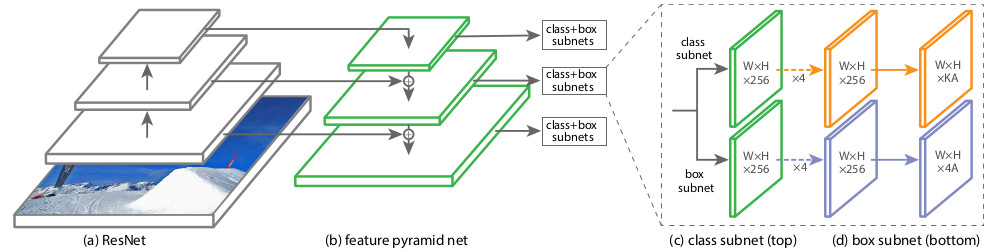
En tant qu'épine dorsale, le
réseau FPN, appelé
Feature Pyramid Network , qui fonctionne au-dessus de l'un des réseaux de neurones convolutifs couramment utilisés (par exemple, ResNet50), est utilisé. FPN a des sorties latérales supplémentaires des couches cachées du réseau de convolution, formant des niveaux pyramidaux à différentes échelles. Chaque niveau est complété par une «voie descendante», c'est-à-dire des informations de niveaux supérieurs qui sont plus petites, mais contiennent des informations sur des zones d'une plus grande zone. Cela ressemble à une augmentation artificielle (par exemple, en répétant simplement les éléments) d'une carte d'entités plus «minimisée» à la taille de la carte actuelle, en les ajoutant élément par élément et en les transférant à la fois aux niveaux inférieurs de la pyramide et à l'entrée d'autres sous-réseaux (c'est-à-dire dans le sous-réseau de classification et Sous-réseau de régression de boîte). Cela vous permet de sélectionner à partir de l'image d'origine une pyramide de signes à différentes échelles, sur laquelle des objets petits et grands peuvent être détectés. Le FPN est utilisé dans de nombreuses architectures, améliorant la détection d'objets de différentes tailles: RPN, DeepMask, Fast R-CNN, Mask R-CNN, etc.
Vous pouvez en savoir plus sur FPN dans l'
article d' origine.
Dans notre réseau, comme dans l'original, FPN avec 5 niveaux numérotés avec
par
. Niveau
a la permission de
fois plus petit que l'image d'entrée (nous n'entrerons pas dans les détails de quels points de ResNet ils viennent - cela cassera la jambe). Tous les niveaux de la pyramide ont le même nombre de canaux C = 256 et le nombre d'ancres A environ 1000 (selon la taille des images).
Les ancres ont des zones de [16 x 16] à [256 x 256] pour chaque niveau de la pyramide de
avant
en conséquence, avec un pas de déplacement (foulées) [8 - 128] px. Cette taille vous permet d'analyser de petits objets et certains environs. Par exemple, une branche, si vous ne tenez pas compte de sa réalité environnante, ressemble beaucoup à une personne menteuse.
Le FPN d'origine utilise trois rapports d'aspect des ancres (1: 2, 1: 1, 2: 1); RetinaNet aspect ratio [
]. 9- , / 16 400 px.
Classification Subnet . (Fully ConvNet, FCN), FPN. , :
- (W x H x C)
- 33
- ReLU
- 33 ( ) ,
- -
x A, K — . — Pedestrian.
Box Regression Subnet 4- . , FPN, Classification Subnet. , , (4 ) — :
, , IoU (Intersection over Union) > 0.5.
1, 0. .
( ) forward . 1k , 0,05. , threshold = 0,5.
RetinaNet
towardsdatascience .
, . OpenSource-, Github fizyr:
keras-retinanet , .
, , 20-30 . , :
Et aussi ...
- Nvidia Jetson
- Corral Edge TPU
tensoflow 1.14 CPU AVX Intel nndl. AVX ( 2012 ) , Core 2 Duo!
Albumentations .
:
La production
docker
desktop- c , . Nvidia Cuda CuDNN TensorFlow — . , Python . - , . — Docker. web- . , docker-. GUI . GUI , , , , . Docker API, GUI, . , Docker , .
#
. 3 :
dotnext . «! - ! - ? », — ! GUI # AvaloniaUI, 64- Win10, Linux Mac.
AvaloniaUI — , . WPF, , . , 2D- , WPF. , WPF.
, SkiaSharp GTK ( Unix ). X11 . , , (!). .Net Core Bios', AvaloniaUI .
AvaloniaUI , , . , 2019 , . WPF C# — . ( electron), , .
 ...
..., , issue. , ,
,
.
.Pour une compréhension complète de ce concept, il convient de regarder la présentation de Nikita Tsukanov @kekekeks . Il est le développeur de ce framework, y est bien familiarisé et en .NET en général.Backend
En plus de l'application de bureau, nous développons une infrastructure mlOps pour mener des expériences et trouver la meilleure architecture de réseau neuronal dans le cloud. En utilisant le côté serveur, nous voulons:- agréger les données et les stocker de manière centralisée;
- automatiser le processus d'apprentissage d'un réseau de neurones, créer un environnement pour la recherche et en donner accès à d'autres;
- fournir un accès au cloud aux équipes de recherche et de sauvetage afin qu'elles puissent également utiliser les données accumulées si nécessaire;
L'architecture globale du système ressemble à ceci:
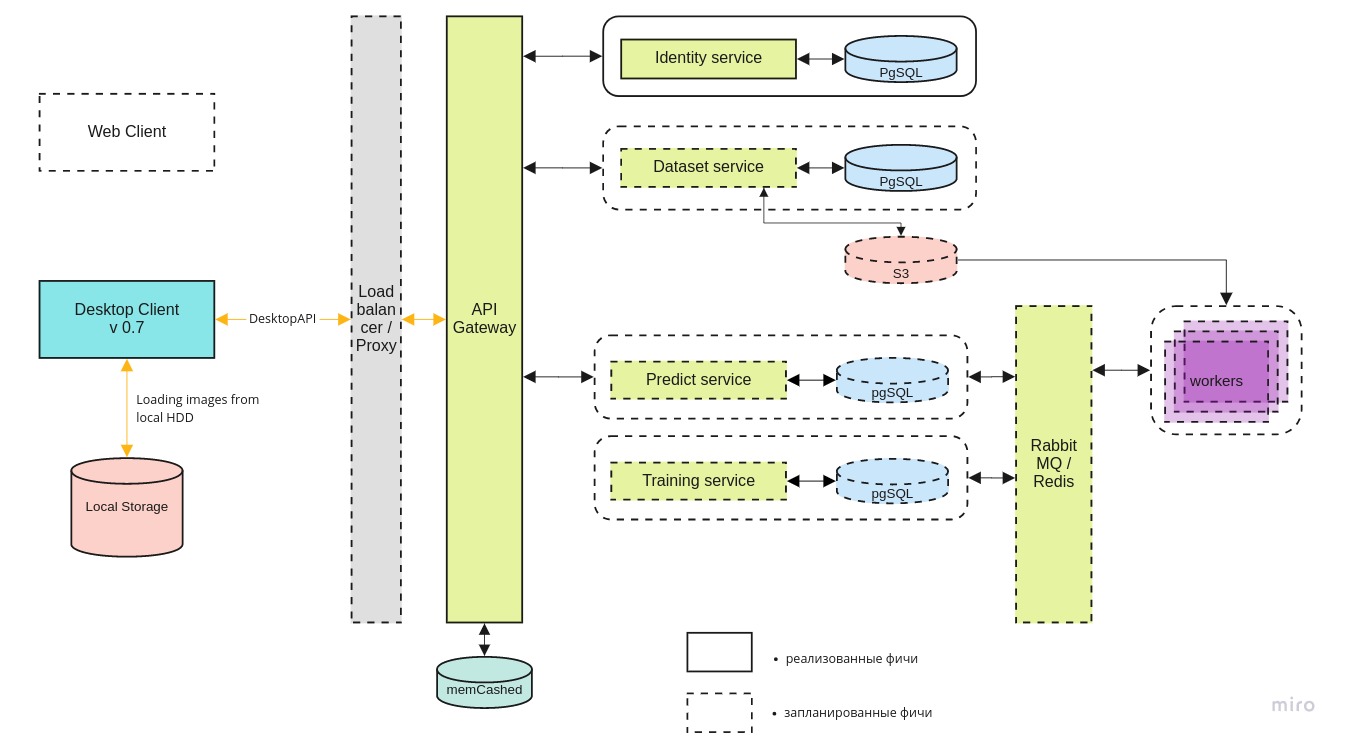 Desktop-client
Desktop-client peut fonctionner à la fois avec la version locale du conteneur Docker et la dernière version sur le serveur central, via l'API REST.
Le microservice d'
identité fournit l'accès au serveur uniquement aux utilisateurs autorisés.
Le service de jeu de
données est utilisé pour stocker à la fois les images elles-mêmes et leur balisage.
Le service
Predict vous permet de traiter rapidement un grand nombre d'images en présence d'un large canal pour les pilotes.
Un service de
formation est nécessaire pour tester de nouveaux modèles et recycler les modèles existants à mesure que de nouvelles données arrivent.
La file d'attente des tâches est gérée à l'aide de RabbitMQ / Redis.
Recherche de capacités GPU
Malgré le fait que l'inférence du réseau neuronal peut fonctionner même sur un simple ordinateur portable, un GPU est nécessaire pour former le modèle. Techniquement, vous pouvez l'entraîner sur le CPU, mais en pratique cela prend trop de temps. Toutes les personnes qui viennent dans l'équipe ne disposent pas d'un ordinateur adapté au Deep Learning, nous sommes donc à la recherche de capacités GPU centralisées.
En ce moment, nous négocions avec
DTL et nous espérons que la coopération se développera. Le caractère unique des serveurs GPU DTL est l'utilisation du refroidissement par immersion: immersion des racks dans un fluide diélectrique spécial. Cela ressemble à ceci:

 (Note du photographe: le bleu n’est pas une lueur Cherenkov. C’est un point culminant en eux).
(Note du photographe: le bleu n’est pas une lueur Cherenkov. C’est un point culminant en eux).Digression lyrique. "Connaissez-vous le réseau neuronal de Beeline?"
Honnêtement, je ne veux pas vraiment toucher à ce sujet (glissant), mais il continue de nous toucher, il est donc impossible de prétendre que nous sommes dans le réservoir. Oui, nous connaissons le réseau neuronal de Beeline. Selon les retours des pilotes coopérant avec nous, cela fonctionne moins bien que notre version et uniquement sur les plateformes haut de gamme. Selon les développeurs de Beeline - le projet est gelé et ne se développe pas actuellement. Du point de vue du bon sens, les nouvelles dans l'esprit de Beeline ont été les premières en Russie à développer un tel réseau de neurones, ce n'est guère vrai. Peu de gens mettent même en œuvre des architectures conçues par des laboratoires comme Facebook Research ou Google Brain, encore moins en créer une. Le plus souvent, il s'agit simplement d'adapter une bibliothèque OpenSource publique aux besoins de votre domaine. La fréquence à laquelle les bibliothèques ouvertes sont utilisées dans les logiciels commerciaux russes est connue de tous ceux qui développent ce logiciel. Pour la plupart, il n'y a même pas de violation de la licence; mais laisser de côté les réalisations de l'OpenSource internationale dans son ensemble et faire des relations publiques bruyantes est au moins moche. Il semble que nos réalisations aient également été utilisées: en particulier, dans
notre gamification nos photos ont été
éclairées. Comparez avec la photo «hiver» de la section sur l'ensemble de données Lacmus:

Il y a d'autres raisons de croire que la question ne se limitait pas aux données ici.
Ce qui est mauvais pour nous en premier lieu, c'est que le réseau de neurones de Beeline est maintenant sans torsion à l'impossibilité. Quand il est mentionné, il est impossible de comprendre s’il s’agit vraiment d’elle, ou de notre application, ou en général de l’option de quelqu’un d’autre. Dans des conditions de décentralisation, de mauvaise contrôlabilité de la MOC et d'un petit nombre de canaux de rétroaction, toute information sur la prévalence et la qualité du travail de Lacmus serait utile, ainsi que sur des développements similaires - mais le battage médiatique autour de Beeline éclipsait tout.
Nous prévoyons de continuer à surveiller la situation pour l'instant, mais notre demande à la communauté est, premièrement, de dire «réseau de neurones Beeline» seulement quand ils sont sûrs à 100% qu'il en est ainsi, et deuxièmement, de lire les licences open source et d'indiquer honnêtement la paternité.
Résumé
Au cours de l'année 2019, les membres de la Fondation Lacmus:
- Nous avons tourné et balisé un ensemble de données unique, dont la dernière version comprend plus de 2000 images;
- essayé plusieurs architectures de réseaux de neurones différentes et choisi la plus appropriée;
- Nous avons sélectionné les meilleurs hyperparamètres du réseau neuronal et l'avons formé sur nos propres données uniques pour la reconnaissance la plus précise;
- développé une application multiplateforme pour les opérateurs d'UAV avec la possibilité d'utiliser lorsqu'ils travaillent hors ligne;
- optimisé le travail de notre réseau de neurones pour travailler sur des ordinateurs portables économiques et à faible consommation;
À l'heure actuelle, les meilleurs indicateurs de la métrique mAP du réseau neuronal LAPMUS sont de 94%. Notre programme est prêt à être utilisé dans de véritables opérations de recherche et sauvetage et a été testé sur des cycles généraux. Dans les zones ouvertes de type "champ" et "brise-vent", tous les tests "perdus" ont été trouvés. Déjà maintenant, Lakmus est utilisé par les équipes de secours et aide à trouver des gens.
Et nous avons également reçu le prix du projet de l'année d'Open Data Science:

Cette année, nous prévoyons:
- trouver un partenaire pour une infrastructure d'hébergement fiable;
- implémenter l'interface Web et mlOps;
- former un grand ensemble de données synthétiques sur le moteur UE4 ou à l'aide de GAN;
- lancer un concours InClass à Kaggle pour tous ceux qui souhaitent améliorer leurs compétences DL / CV et rechercher les meilleures solutions SOTA;
- ajouter à notre rétinanet encore plus d'implémentations de dorsales et de variations de cette architecture;
Nous manquons vraiment de travailleurs pour mettre en œuvre ces plans, nous serons donc ravis de tous, quel que soit le niveau et l'orientation de la formation.
Si ensemble nous pouvons sauver au moins une personne de plus, alors tous les efforts ne seront pas vains.
Comment aider le projet
Nous sommes un projet OpenSource et nous accepterons volontiers tout le monde! Voici les liens vers nos dépôts github:
Si vous êtes développeur et que vous souhaitez rejoindre le projet, vous pouvez écrire à Perevozchikov Georgy Pavlovich,
gosha20777 dans tous les réseaux sociaux,
gosha20777@live.ru ou rejoindre le projet via le canal
# ml4sg en slack ODS (si vous y êtes).
Nous avons besoin de:
- Développeurs ML
- Développeurs C # / go / python;
- Travailleurs de première ligne;
- Beckers;
- Juste des gens actifs de n'importe quelle direction! Nous serons toujours ravis de vous voir!
Si vous n'êtes pas impliqué dans le développement, vous pouvez également aider le projet:
- Vous pouvez nous aider à rédiger des articles;
- Vous pouvez nous aider à rédiger la documentation utilisateur et un wiki (et corriger les erreurs de grammaire là-bas)))
- Vous pouvez rester dans le rôle d'un chef de produit et effectuer des tâches dans trello;
- Vous pouvez nous proposer une idée;
- Vous pouvez distribuer ce message;
À propos de l'équipe
Chef de projet: Georgy Pavlovich Perevozchikov,
gosha20777 .
Une liste incomplète des personnes impliquées (en fait, elle est beaucoup plus longue, si vous avez été injustement oublié, dites-le-moi et nous ajouterons):
- Les participants ODS les plus actifs de la chaîne #proj_rescuer_la : Kseniia, balezz, ei-grad, Palladdiumm, sharov_am, dartov
- Participants au projet en dehors des SAO: Martynova Viktoriya Viktorovna (organisation du projet, collecte et étiquetage des données), Denis Petrovich Shurankov (organisation de collecte des données), Daria Pavlovna Perevozchikova (taguée environ 30% de toutes les photos).
- Opérateurs d'UAV de l'équipe de Liza Alert, qui ont aidé avec les images et la formation de l'ensemble de données: Partyzan, Vanteyich, Sevych, Californie, Tarekon, Evgen, GB.
Remerciements spéciaux:
- Aux programmeurs d'AvaloniaUI - le meilleur framework .NET: worldbeater , kekekeks , Larymar
- Administrateurs ODS pour l'organisation de la communauté la plus cool: natekin, Sasha, mephistopheies.
Cet article a été co-écrit avec
balezz et
gosha20777 habrozhitelami .
Tout le monde doit être ingénieux et ne jamais se perdre!
 Démonstration vidéo du travail pour le dessert. Version pré-early-alpha. Pour ceux qui ont lu jusqu'au bout. Février 2019.
Démonstration vidéo du travail pour le dessert. Version pré-early-alpha. Pour ceux qui ont lu jusqu'au bout. Février 2019.