Il y a deux ans, j'ai commencé le développement un de plus un générateur de code gratuit de la spécification OpenAPI v3 à TypeScript (il est disponible sur Github ). Au départ, je me suis fixé pour objectif de générer efficacement des types de données primitifs et complexes en TypeScript, en tenant compte de diverses fonctionnalités du schéma JSON , telles que oneOf / anyOf / allOf , etc. (La solution native de Swagger a eu quelques problèmes avec cela). Une autre idée était d'utiliser des schémas de spécifications pour la validation à l'avant, à l'arrière et dans d'autres parties du système.

Maintenant, le générateur de code est relativement prêt - il est au stade MVP . Il a beaucoup de ce qui est nécessaire en termes de génération de types de données, ainsi qu'une bibliothèque expérimentale pour générer des services frontaux (jusqu'à présent pour Angular). Dans cet article, je veux montrer les développements et dire comment ils peuvent vous aider si vous utilisez TypeScript et OpenAPI v3. En cours de route, je veux partager quelques idées et considérations qui ont surgi dans mon processus de travail. Eh bien, si ça vous intéresse, vous pouvez lire la trame de fond que j'ai cachée dans le spoiler afin de ne pas compliquer la lecture de la partie technique.
Table des matières
- Contexte
- La description
- Installation et utilisation
- Entraînez-vous à utiliser un générateur de code
- Utilisation des types de données générés dans les applications
- Décomposition des circuits dans la spécification OAS
- Décomposition imbriquée
- Services générés automatiquement pour travailler avec l'API REST
- Pourquoi est-ce nécessaire?
- Génération de services
- Utilisation des services générés
- Au lieu d'une postface
Contexte
Développer pour lire (sauter)Tout a commencé il y a deux ans - puis j'ai travaillé dans une entreprise développant une plate-forme d'exploration de données et j'étais responsable du frontend (principalement TypeScript + Angular). Les caractéristiques du projet étaient des structures de données complexes avec un grand nombre de paramètres (30 ou plus) et des relations commerciales pas toujours évidentes entre elles. L'entreprise se développait et l'environnement logiciel subissait des changements assez fréquents. Le frontend devait être bien informé dans les nuances, car certains calculs étaient dupliqués au front et au backend. Autrement dit, ce fut le cas lorsque l'utilisation d'OpenAPI est plus que appropriée. J'ai trouvé une période dans l'entreprise où, en quelques mois, l'équipe de développement a acquis une spécification unique, qui est devenue une base de connaissances commune pour le dos, le devant et même le département principal, qui était caché derrière le large dos du backend Web. La version OpenAPI a été choisie «pour la croissance» - alors encore assez jeune v3.0
Ce n'était plus une spécification dans un ou plusieurs fichiers YML / JSON statiques, et non le résultat d' annotateurs , mais toute une bibliothèque de composants, méthodes, modèles et propriétés, organisés conformément au concept DDD de la plateforme. La bibliothèque était divisée en répertoires et fichiers, et un collecteur spécialement organisé a produit des documents de l'OEA pour chaque domaine. Une méthode expérimentale a été construite pour le flux de travail, qui pourrait être décrite comme Design-First.
Il y a un bon article dans le blog de la société Yandex.Money, qui parlait de Design First
Design First et la spécification générale ont contribué à la décralisation des connaissances, mais un nouveau problème est apparu - maintenir la pertinence du code. La spécification décrit plusieurs dizaines de méthodes et des dizaines (et plus tard des centaines) d'entités. Mais le code devait être écrit manuellement: types de données, services pour travailler avec REST, etc. Un ou deux sprints avec des histoires parallèles ont considérablement changé l'image; ajouter de la complexité à la fusion de plusieurs histoires et au facteur humain. La routine menaçait d'être significative, et la solution semblait évidente - vous avez besoin de génération de code. Après tout, les spécifications de l'OEA contenaient déjà tout le nécessaire pour ne pas le retaper manuellement. Mais ce n'était pas si simple.
L'interface est à la toute fin du cycle de production, j'ai donc ressenti des changements plus douloureux que mes collègues des autres départements. Lors de la conception de l'API REST, l'environnement principal était décisif, et même après l'approbation de «Design First», l'inertie est restée; pour le front end, tout semblait moins évident. En fait, j'ai compris cela dès le début et j'ai commencé à sonder le sol à l'avance - alors que le discours d'une spécification «universelle» ne faisait que commencer. Il n'a pas été question d'écrire votre propre générateur de code; Je voulais juste trouver quelque chose de prêt.
J'étais déçu. Il y avait deux problèmes: OAS version 3.0, avec le soutien de qui, semble-t-il, personne n'était pressé, et la qualité des solutions elles-mêmes - à ce moment (je me souviens que c'était il y a deux ans), j'ai réussi à trouver deux solutions relativement prêtes à l'emploi: de Swagger et de Microsoft (il semble que ). Dans le premier, la prise en charge d'OAS 3.0 était en version bêta profonde. Le second ne fonctionnait qu'avec la version 2.x, mais il n'y avait pas de prévisions sans ambiguïté. Soit dit en passant, je n'ai pas pu démarrer le générateur de code Microsoft même sur un document de test au format Swagger 2.0. La solution de Swagger a fonctionné, mais un schéma plus ou moins compliqué avec des liens $ ref s'est transformé en une "ERREUR!" Incompréhensible, et des dépendances récursives l'ont envoyé dans une boucle infinie. Il y avait des problèmes avec les types primitifs . De plus, je ne comprenais pas très bien comment travailler avec les services générés automatiquement - ils semblaient être faits pour le spectacle, et leur utilisation réelle créait plus de problèmes qu'ils n'en résolvaient (à mon avis). Et enfin, l'intégration du fichier JAR dans un CI / CD orienté NPM était gênante: j'ai dû télécharger manuellement l' instantané nécessaire , qui semblait peser 13 mégaoctets, et faire quelque chose avec. En général, j'ai fait une pause et j'ai décidé de regarder ce qui allait se passer ensuite.
Après environ cinq mois, le problème de la génération de code s'est à nouveau posé. J'ai dû réécrire et développer une partie de l'application Web, et en même temps, je voulais refactoriser les anciens services pour travailler avec l'API REST et les types de données. Mais l'évaluation de la complexité n'était pas optimiste: d'une semaine-homme à deux - et ce uniquement pour les services REST et les descriptions de type. Je ne dirai pas que cela m'a beaucoup déprimé, mais quand même. D'un autre côté, je n'ai jamais trouvé de solution pour la génération de code et n'ai pas attendu, et sa mise en œuvre prendrait à peine moins de temps. Autrement dit, il n'y avait aucun doute à ce sujet: l'avantage est douteux, les risques sont grands. Personne ne soutiendrait cette idée, et je n'ai pas proposé. Pendant ce temps, les vacances de mai approchaient et la société me «devait» plusieurs jours pour travailler le week-end. Pendant deux semaines, je me suis enfui de toutes les expériences de travail en Géorgie, où j'ai vécu pendant près d'un an.
Entre les fêtes et les fêtes, je devais faire quelque chose et j'ai décidé d'écrire ma décision. Travailler dans les cafés d'été près de Vake Park était étonnamment productif, et je suis retourné à Peter avec un générateur de code prêt à l'emploi pour les types de données. Puis pendant un mois, j'ai «terminé» les services le week-end avant qu'il ne soit prêt à travailler.
Dès le début, j'ai ouvert le générateur de code, travaillant dessus pendant mon temps libre. Bien qu'en fait, il ait écrit pour un projet de travail. Je ne dirai pas que la révision / rodage s'est déroulée sans problème; et je ne dirai pas qu'ils étaient importants. Mais à un moment donné, j'ai remarqué que j'ai cessé d'utiliser la documentation Redoc / Swagger: naviguer dans le code était plus pratique, à condition que le code soit toujours à jour et commenté. Bientôt, j'ai «marqué» mes réalisations, sans les développer du tout, jusqu'à ce qu'un collègue (maintenant il y a six mois que je quitte pour une autre entreprise) me conseille de les prendre plus au sérieux (il a aussi trouvé le nom).
Je n'avais pas assez de temps libre, et plusieurs mois il m'a fallu pour finaliser en arrière plan: aire de jeux , application test, réorganisation du projet. Maintenant, je suis prêt à recevoir des commentaires.
La description
À l'heure actuelle, la solution pour la génération de code comprend trois bibliothèques NPM intégrées dans @codegena @codegena et situées dans un mono-référentiel commun:
Installation et utilisation
L'option la plus pratique consiste à utiliser dans les scripts NodeJS exécutés à partir de la CLI. Vous devez d'abord installer les dépendances:
npm i @codegena/oapi3ts, @codegena/ng-api-service, @codegena/oapi3ts-cli
Ensuite, créez un fichier js (par exemple update-typings.js ) avec le code:
"use strict"; var cliLib = require('@codegena/oapi3ts-cli'); var cliApp = new cliLib.CliApplication; cliApp.createTypings();
Et lancez-le en passant trois paramètres:
node ./update-typings.js --srcPath ./specs/todo-app-spec.json --destPath ./src/lib --separatedFiles true
Dans destPath aura des fichiers générés et, en fait, le contenu de ce répertoire dans le référentiel du projet est créé de la même manière. Voici le script de génération , et voici comment il s'exécute dans les scripts NPM. Cependant, si vous le souhaitez, vous pouvez l'utiliser même dans le navigateur, comme cela se fait dans le Playground .
Entraînez-vous à utiliser un générateur de code
Ensuite, je veux parler de ce que nous obtiendrons en conséquence: quelle est l'idée de la façon dont cela nous aidera. Une aide visuelle sera le code de l'application de démonstration. Il se compose de deux parties: un backend (sur le framework NestJS ) et un frontend (sur Angular ). Si vous le souhaitez, vous pouvez même l' exécuter localement .
Même si vous n'êtes pas familier avec Angular et / ou NestJS, cela ne devrait pas poser de problème: les exemples de code qui seront fournis devraient être compris par la plupart des développeurs TypeScript.
Bien que l'application soit simplifiée au maximum (par exemple, le backend stocke les données dans une session et non dans la base de données), j'ai essayé de recréer le flux de données et les fonctionnalités de la hiérarchie des types de données inhérentes à l'application réelle. Il est prêt à 80-85%, mais la «finition» peut être retardée, mais pour l'instant il est plus important de parler de ce qui existe déjà.
Utilisation des types de données générés dans les applications
Supposons que nous ayons une spécification OpenAPI (par exemple, celle-ci ) avec laquelle nous devons travailler. Peu importe que nous créons quelque chose à partir de zéro ou que nous prenions en charge, il y a une chose importante que nous sommes le plus susceptibles de commencer - la saisie. Nous commencerons soit à décrire les types de données de base, soit à y apporter des modifications. La plupart des programmeurs le font afin de faciliter leur développement futur. Vous n'avez donc pas à vous pencher à nouveau sur la documentation, gardez à l'esprit les listes de paramètres; et vous pouvez être sûr que l'EDI et / ou le compilateur remarqueront une faute de frappe.
Notre spécification peut inclure ou non la section components.schems . Mais dans tous les cas, il décrira des ensembles de paramètres, demandes et réponses - et nous pouvons l'utiliser. Prenons un exemple:
@Controller('group') export class AppController {
Il s'agit d'un fragment de contrôleur pour la structure NestJS avec des paramètres ( RewriteGroupParameters ), un corps de demande ( RewriteGroupRequest ) et un corps de réponse ( RewriteGroupResponse<T> ) RewriteGroupResponse<T> . Déjà dans ce fragment de code, nous pouvons voir les avantages de la frappe:
- Si nous confondons le nom du paramètre
groupId détruit, en spécifiant groupId place, nous obtenons immédiatement une erreur dans l'éditeur.

- Si la méthode this.appService.rewriteGroup (groupId, body) a des paramètres typés, nous pouvons contrôler l'exactitude du paramètre de
body transmis. Et si le format des données d'entrée de la méthode du contrôleur ou de la méthode de service change, nous le saurons immédiatement. À l'avenir, je note que la méthode d'entrée de la méthode de service a un type de données différent de RewriteGroupRequest , mais dans notre cas, ils seront identiques les uns aux autres. Cependant, si tout à coup la méthode de service est modifiée et commence à accepter ToDoGroup au lieu de ToDoGroupBlank , l'EDI et le compilateur afficheront immédiatement les emplacements des écarts:
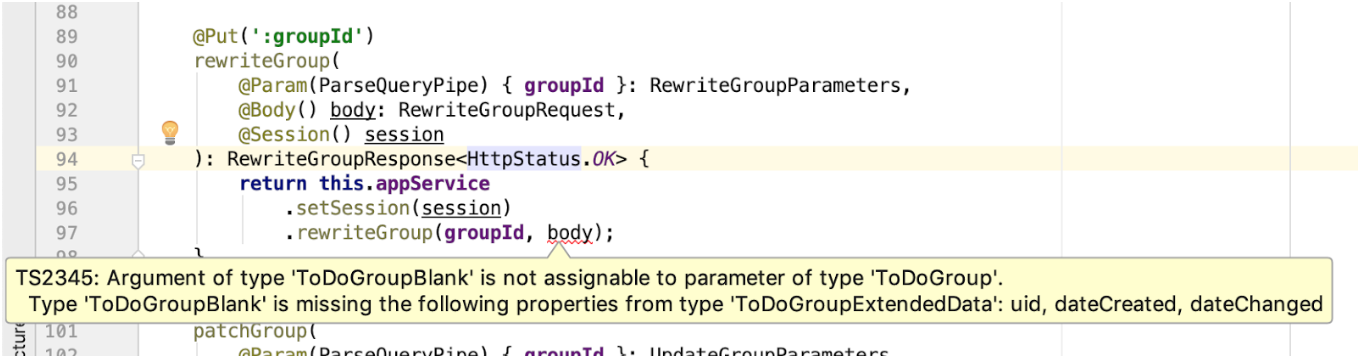
- De la même manière, nous pouvons contrôler la conformité du résultat retourné. Si la spécification de l'état d'une réponse réussie change et devient
202 au lieu de 200 , nous le découvrirons également, car RewriteGroupResponse est un générique avec un type énuméré :

Voyons maintenant un exemple de l'application frontale qui fonctionne avec une autre méthode API :
protected initSelectedGroupData(truth: ComponentTruth): Observable<ComponentTruth> { return this.getGroupsService.request(null, { isComplete: null, withItems: false }).pipe( pickResponseBody<GetGroupsResponse<200>>(200, null, true), switchMap<ToDoGroup[], Observable<ComponentTruth>>( groups => this.loadItemsOfSelectedGroups({ ...truth, groups }) ) ); }
N'allons pas de l'avant et analysons l'opérateur pickResponseBody personnalisé pickResponseBody , mais concentrons-nous sur le raffinement du type GetGroupsResponse . Nous l'utilisons dans une chaîne d'opérateurs RxJS, et l'opérateur qui le suit a un raffinement d'entrée de ToDoGroup[] . Si ce code fonctionne, les types de données indiqués correspondent les uns aux autres. Ici, nous pouvons également contrôler la correspondance de type, et si le format de réponse dans notre API change soudainement, cela n'échappera pas à notre attention:
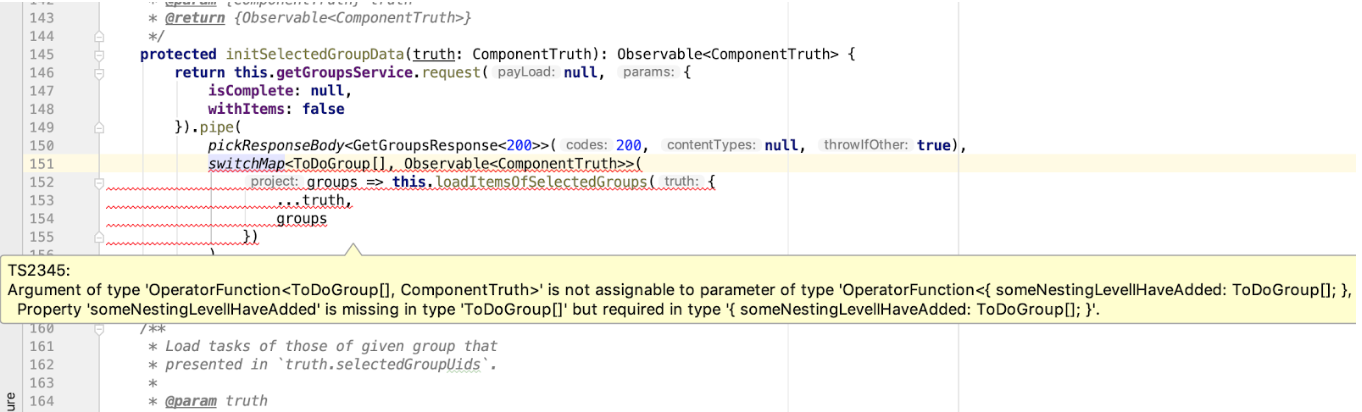
Et bien sûr, les paramètres d'appel de this.getGroupsService.request également saisis. Mais c'est le sujet des services générés.
Dans les exemples ci-dessus, nous voyons que le typage des demandes, des réponses et des paramètres peut être utilisé dans diverses parties du système - frontend, backend, etc. Si le backend et le frontend sont dans le même mono-référentiel et ont un éco-environnement compatible, ils peuvent utiliser la même bibliothèque partagée avec le code généré. Mais même si le backend et le frontend sont pris en charge par des équipes différentes et n'ont rien en commun à l'exception de la spécification publique OAS, il leur sera toujours plus facile de synchroniser leur code.
Décomposition des circuits dans la spécification OAS
Dans les exemples précédents, vous avez probablement prêté attention aux ToDoGroup ToDoGroupBlank , ToDoGroup , avec lesquelles RewriteGroupResponse et GetGroupsResponse . En fait, RewriteGroupResponse n'est qu'un alias générique pour ToDoGroup , HttpErrorBadRequest , etc. Il est facile de deviner que ToDoGroup et HttpErrorBadRequest sont les schémas de la section de spécification components.schemas référencée par le point de terminaison rewriteGroup (directement ou par l' intermédiaire d'intermédiaires ):
"responses": { "200": { "description": "Todo group saved", "content": { "application/json": { "schema": { "$ref": "#/components/schemas/ToDoGroup" } } } }, "400": { "$ref": "#/components/responses/errorBadRequest" }, "404": { "$ref": "#/components/responses/errorGroupNotFound" }, "409": { "$ref": "#/components/responses/errorConflict" }, "500": { "$ref": "#/components/responses/errorServer" } }
Il s'agit de la décomposition habituelle des structures de données, et son principe est le même que dans d'autres langages de programmation. Les composants, à leur tour, peuvent également être décomposés: reportez-vous à d'autres composants (y compris de manière récursive), utilisez une combinaison et d'autres fonctionnalités du schéma JSON. Mais quelle que soit la complexité, ils doivent être correctement convertis en descriptions des types de données. Je veux montrer comment vous pouvez utiliser la décomposition dans OpenAPI et à quoi ressemblera le code généré.
Les composants d'une spécification OAS bien conçue chevaucheront le modèle DDD des applications l'utilisant. Mais même si la spécification est imparfaite, vous pouvez vous y fier en créant votre propre modèle de données. Cela vous donnera plus de contrôle sur la correspondance de vos types de données avec les types de données des sous-systèmes intégrés.
Puisque notre application est une liste de tâches, l'essentiel est la tâche. Il est logique de le mettre dans les composants en premier lieu, car d'autres entités et points de terminaison y seront en quelque sorte connectés. Mais avant cela, vous devez comprendre deux choses:
- Nous décrivons non seulement l'abstraction, mais aussi les règles de validation, et plus elles sont précises et sans ambiguïté, mieux c'est.
- Comme toute entité stockée dans une base de données, une tâche a deux types de propriétés: service et entrée par l'utilisateur.
Il s'avère que, selon le scénario d'utilisation, nous avons deux structures de données: la tâche que l'utilisateur vient de créer et la tâche qui est déjà stockée dans la base de données. Dans le second cas, il a un UID unique, une date de création, de modification, etc., et ces données doivent être affectées au backend. J'ai décrit deux entités ( ToDoTaskBlank et ToDoTask ) de telle manière que la première est un sous-ensemble de la seconde:
"components": { "ToDoTaskBlank": { "title": "Base part of data of item in todo's group", "description": "Data about group item needed for creation of it", "properties": { "groupUid": { "description": "An unique id of group that item belongs to", "$ref": "#/components/schemas/Uid" }, "title": { "description": "Short brief of task to be done", "type": "string", "minLength": 3, "maxLength": 64 }, "description": { "description": "Detailed description and context of the task. Allowed using of Common Markdown.", "type": ["string", "null"], "minLength": 10, "maxLength": 1024 }, "isDone": { "description": "Status of task: is done or not", "type": "boolean", "default": "false", "example": false }, "position": { "description": "Position of a task in group. Allows to track changing of state of a concrete item, including changing od position.", "type": "number", "min": 0, "max": 4096, "example": 0 }, "attachments": { "type": "array", "description": "Any material attached to the task: may be screenshots, photos, pdf- or doc- documents on something else", "items": { "$ref": "#/components/schemas/AttachmentMeta" }, "maxItems": 16, "example": [] } }, "required": [ "isDone", "title" ], "example": { "isDone": false, "title": "Book soccer field", "description": "The complainant agreed and recruited more members to play soccer." } }, "ToDoTask": { "title": "Item in todo's group", "description": "Describe data structure of an item in group of tasks", "allOf": [ { "$ref": "#/components/schemas/ToDoTaskBlank" }, { "type": "object", "properties": { "uid": { "description": "An unique id of task", "$ref": "#/components/schemas/Uid", "readOnly": true }, "dateCreated": { "description": "Date/time (ISO) when task was created", "type": "string", "format": "date-time", "readOnly": true, "example": "2019-11-17T11:20:51.555Z" }, "dateChanged": { "description": "Date/time (ISO) when task was changed last time", "type": "string", "format": "date-time", "readOnly": true, "example": "2019-11-17T11:20:51.555Z" } }, "required": [ "dateChanged", "dateCreated", "position", "uid" ] } ] } }
En sortie, nous obtenons deux interfaces TypeScript, et la première sera héritée par la seconde :
export interface ToDoTaskBlank {
Nous avons maintenant les descriptions de base de l'entité Task, et nous nous y référons dans le code de notre application comme cela a été fait dans l' application de démonstration :
import { ToDoTask, ToDoTaskBlank, } from '@our-npm-scope/our-generated-lib'; export interface ToDoTaskTeaser extends ToDoTask { isInvalid?: boolean; isJustCreated?: boolean; isPending?: boolean; prevTempUid?: string; }
Dans cet exemple, nous avons décrit une nouvelle entité, ajoutant à ToDoTask les propriétés qui nous manquent du côté de l'application frontale. En fait, nous avons élargi le modèle de données résultant en tenant compte des spécificités locales. Autour de ce modèle, un ensemble d' outils locaux et quelque chose comme un DTO primitif se développent progressivement:
export function downgradeTeaserToTask( taskTeaser: ToDoTaskTeaser ): ToDoTask { const task = { ...taskTeaser }; if (!task.description || !task.description.trim()) { delete task.description; } else { task.description = task.description.trim(); } delete task.isJustCreated; delete task.isPending; delete task.prevTempUid; return task; } export function downgradeTeaserToTaskBlank( taskTeaser: ToDoTaskTeaser ): ToDoTaskBlank { const task = downgradeTeaserToTask(taskTeaser) as any; delete task.dateChanged; delete task.dateCreated; delete task.uid; return task; }
Quelqu'un préfère rendre le modèle de données plus intégral et utiliser des classes. export class ToDoTaskTeaser implements ToDoTask {
Mais c'est une question de style, de pertinence et de développement de l'architecture de l'application. En général, quelle que soit l'approche, nous pouvons compter sur un modèle de données de base et avoir plus de contrôle sur la conformité du typage. Donc, si pour une raison quelconque, l' uid de ToDoTask devient un nombre, nous connaîtrons toutes les parties du code qui nécessitent une mise à jour:

Décomposition imbriquée
Nous avons donc maintenant l'interface ToDoTask et nous pouvons la référencer. De même, nous décrirons ToDoTaskGroup et ToDoTaskGroupBlank , et ils contiendront des propriétés de types ToDoTask et ToDoTaskBlank , respectivement. Mais maintenant, nous allons diviser le «groupe de tâches» en deux, et non trois, composants: pour plus de clarté, nous allons décrire le delta dans ToDoGroupExtendedData . Je veux donc démontrer une approche dans laquelle un composant est créé à partir des deux autres:
"ToDoGroup": { "allOf": [ { "$ref": "#/components/schemas/ToDoGroupBlank" }, { "$ref": "#/components/schemas/ToDoGroupExtendedData" } ] }
Après avoir commencé la génération de code, nous obtenons une construction TypeScript légèrement différente:
export type ToDoGroup = ToDoGroupBlank &
Puisque ToDoGroup n'a pas son propre «corps», le générateur de code a préféré le transformer en une union d'interfaces. Cependant, si vous ajoutez la troisième partie avec votre propre schéma (anonyme), le résultat sera une interface avec deux ancêtres (mais il vaut mieux ne pas le faire). Et notons que la propriété items de l'interface ToDoGroupBlank typée comme un tableau de ToDoTaskBlank et est redéfinie dans ToDoGroupBlank sur ToDoTask . Ainsi, le générateur de code est capable de transférer les nuances plutôt complexes de décomposition du schéma JSON vers TypeScipt.
import { ToDoTaskBlank } from './to-do-task-blank'; export interface ToDoGroupBlank {
import { ToDoTask } from './to-do-task'; export interface ToDoGroupExtendedData {
Et bien sûr, dans ToDoTask / ToDoTaskBlank nous pouvons également utiliser la décomposition. Vous avez peut-être remarqué que la propriété attachments est décrite comme un tableau d'éléments de type AttachmentMeta . Et ce composant est décrit comme suit:
"AttachmentMeta": { "description": "Common meta data model of any type of attachment", "oneOf": [ {"$ref": "#/components/schemas/AttachmentMetaImage"}, {"$ref": "#/components/schemas/AttachmentMetaDocument"}, {"$ref": "#/components/schemas/ExternalResource"} ] }
Autrement dit, ce composant fait référence à d'autres composants. Puisqu'il n'a pas son propre schéma, le générateur de code n'en fait pas un type de données séparé afin de ne pas multiplier les entités, mais transforme une description anonyme du type énuméré:
attachments?: Array< | AttachmentMetaImage
Dans le même temps, pour les composants AttachmentMetaImage et AttachmentMetaDocument , des interfaces non anonymes sont décrites qui sont importées dans les fichiers qui les utilisent:
import { AttachmentMetaDocument } from './attachment-meta-document'; import { AttachmentMetaImage } from './attachment-meta-image';
Mais même dans AttachmentMetaImage, nous pouvons trouver un lien vers une autre interface ImageOptions rendue, qui est utilisée deux fois, y compris à l'intérieur d'une interface anonyme (le résultat de la conversion de additionalProperties ):
import { ImageOptions } from './image-options'; export interface AttachmentMetaImage {
Ainsi, sur la ToDoTask ToDoGroup ToDoTask ou ToDoGroup , nous intégrons en fait plusieurs entités dans le code et une chaîne de leurs connexions commerciales, ce qui nous donne plus de contrôle sur les changements dans le sur-système qui vont au-delà de notre code. Bien sûr, cela n'a pas de sens dans tous les cas. Mais si vous utilisez OpenAPI, vous pouvez avoir un petit bonus supplémentaire, en plus de la documentation réelle.
Services générés automatiquement pour travailler avec l'API REST
Pourquoi est-ce nécessaire?
Si nous prenons une application frontale statistique moyenne qui fonctionne avec une API REST plus ou moins complexe, une partie considérable de son code sera constituée de services (ou simplement de fonctions) pour accéder à l'API. Ils comprendront:
- Mappages d'URL et de paramètres
- Validation des paramètres, demande et réponse
- Extraction de données et traitement d'urgence
Il est désagréable que, à bien des égards, cela soit typique et ne contienne aucune logique unique. Supposons un exemple - comme un aperçu général, le travail avec l'API peut être construit:
Un exemple schématique simplifié de travail avec l'API REST import _ from 'lodash'; import { Observable, fromFetch, throwError } from 'rxjs'; import { switchMap } from 'rxjs/operators';
Vous pouvez utiliser une abstraction de haut niveau pour travailler avec REST - selon la pile utilisée, elle peut être: Axios , Angular HttpClient , ou toute autre solution similaire. Mais très probablement, votre code coïncidera essentiellement avec cet exemple. Il comprendra certainement:
- Services ou fonctions pour accéder à des points de terminaison spécifiques (fonction
getTasksFromServer dans notre exemple) - Morceaux de code qui traitent le résultat (fonction
getRemainedTasks )
Dans une application du monde réel, ce code sera plus compliqué: la spécification de l'application de démonstration décrit 5-6 options de réponse . Souvent, l'API REST est conçue de telle manière que chaque état de réponse du serveur doit être géré en conséquence. Mais même la vérification des données d'entrée a tendance à devenir plus difficile lors du développement de l'application: plus il faut de temps pour prendre en charge et traiter les révisions d'erreurs, plus vous voulez en savoir sur les goulots d'étranglement dans la circulation des données dans l'application.
Des erreurs peuvent se produire au niveau de chaque nœud d'accueil de composants logiciels, dont la détection intempestive (ainsi que la recherche de problèmes difficiles à diagnostiquer) peut être très coûteuse pour les entreprises. Par conséquent, il y aura des vérifications de clarification supplémentaires. À mesure que la base de code augmente et que le nombre de cas couverts, la complexité des modifications augmente. Mais les affaires sont un changement constant et il n'y a pas moyen de les contourner. Par conséquent, nous devons nous soucier de la façon dont nous apporterons des modifications à l'avance.
Pour en revenir à la rubrique OpenAPI, nous notons que dans les spécifications de l'OEA, il peut y avoir suffisamment d'informations pour:
- Décrire tous les points finaux nécessaires sous forme de fonctions ou de services
- Associez-les aux types de données souhaités.
- URL
— . , , / — 5, 10 200, . , , : , , , RxJS- pickResponseBody , , - ; tapResponse , side-effect (tap) HTTP-. , - . , , .
, — -, . , , , "" / API "-" "" . - , "" ( ), .
, REST API Angular. , , /. . , , . , , .. .
" " . Angular-, update-typings.js :
"use strict"; var cliLib = require('@codegena/oapi3ts-cli'); var cliApp = new cliLib.CliApplication; cliApp.createTypings(); cliApp.createServices('angular');
, Angular- API . , - - , . , RewriteGroupService . ApiService , , , -:
, JSON Schema , . , , :
import { schema as domainSchema } from './schema.b4c655ec1635af1be28bd6';
, schema.b4c655ec1635af1be28bd6.ts , , .
, Angular-.
Angular-ApiModule :
import { ApiModule, API_ERROR_HANDLER } from '@codegena/ng-api-service'; import { CreateGroupItemService, GetGroupsService, GetGroupItemsService, UpdateFewItemsService } from '@codegena/todo-app-scheme'; @NgModule({ imports: [ ApiModule, // ... ], providers: [ RewriteGroupService, { provide: API_ERROR_HANDLER, useClass: ApiErrorHandlerService }, // ... ], // ... }) export class TodoAppModule { }
, [])( https://angular.io/guide/dependency-injection ):
@Injectable() export class TodoTasksStore { constructor( protected createGroupItemService: CreateGroupItemService, protected getGroupsService: GetGroupsService, protected getGroupItemsService: GetGroupItemsService, protected updateFewItemsService: UpdateFewItemsService ) {} }
— , request , :
return this.getGroupsService.request(null, { isComplete: null, withItems: false }).pipe( pickResponseBody<GetGroupsResponse<200>>(200, null, true), switchMap<ToDoGroup[], Observable<ComponentTruth>>( groups => this.loadItemsOfSelectedGroups({ ...truth, groups }) ) );
request Observable<HttpResponse<R> | HttpEvent<R>> , , . , , . , , , . RxJS- pickResponseBody .
, , , . API, . . , :
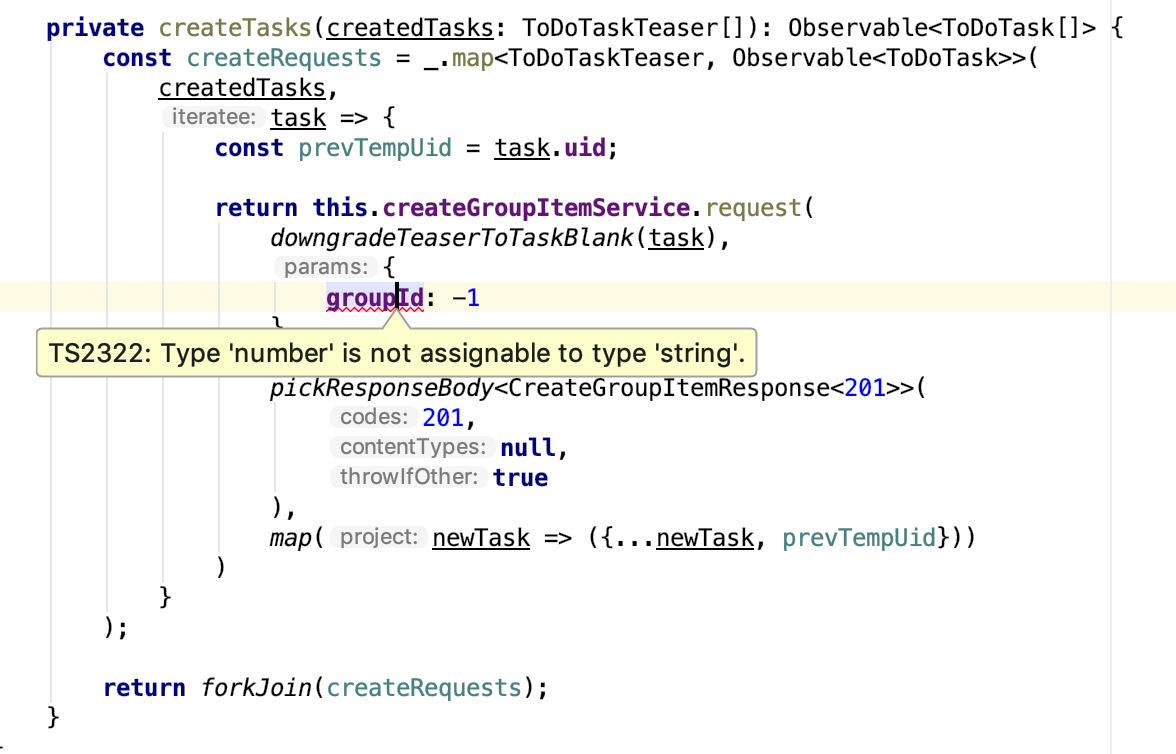
. JSON Schema . , "" - . , Sentry Kibana , . . , , .
, . , :)
Au lieu d'une postface
, . -, " " — . , , , .
— , - / ( ). , — .
Merci d'avoir lu.