HighLoad ++ Moscou 2018, salle des congrès. 9 novembre, 15h00
Résumés et présentation:
http://www.highload.ru/moscow/2018/abstracts/4066Yuri Nasretdinov (VKontakte): le rapport parlera de l'expérience de la mise en œuvre de ClickHouse dans notre entreprise - pourquoi nous en avons besoin, combien de données nous stockons, comment nous les écrivons, etc.

Ressources supplémentaires:
utilisation de Clickhouse comme substitut pour ELK, Big Query et TimescaleDB Yuri Nasretdinov: - Bonjour à tous! Je m'appelle Yuri Nasretdinov, car ils m'ont déjà présenté. Je travaille chez VKontakte. Je vais parler de la façon dont nous insérons des données dans «ClickHouse» à partir de notre flotte de serveurs (des dizaines de milliers).
Que sont les journaux et pourquoi les collecter?
Ce dont nous allons parler: ce que nous avons fait, pourquoi nous avions besoin de "ClickHouse", respectivement - pourquoi nous l'avons choisi, quel genre de performances vous pouvez obtenir à peu près sans rien configurer spécifiquement. Je vais vous en dire plus sur les tables tampons, sur les problèmes que nous avons rencontrés avec elles et sur nos solutions que nous avons développées à partir de l'open source - KittenHouse and Lighthouse.
Pourquoi avons-nous dû faire quoi que ce soit (sur VKontakte, tout va toujours bien, non?). Nous voulions collecter des journaux de débogage (et il y avait des centaines de téraoctets de données là-bas), peut-être, en quelque sorte, il est plus pratique de lire les statistiques; et nous avons des dizaines de milliers de serveurs à partir desquels tout cela doit être fait.
Pourquoi avons-nous décidé? Nous avions probablement des solutions pour stocker les journaux. Ici - il y a un tel "Backend VK" public. Je recommande fortement d'y souscrire.

Que sont les journaux? Il s'agit d'un moteur qui renvoie des tableaux vides. Les moteurs en «VK» sont ce que d'autres appellent des microservices. Et un tel autocollant sourit (pas mal de likes). Comment ça? Eh bien, écoutez!

Que peut-on utiliser pour stocker les journaux en général? Il est impossible de ne pas mentionner le Khadup. Ensuite, par exemple, Rsyslog (stockage dans les fichiers de ces journaux). LSD Qui sait ce qu'est le LSD? Non, pas ce LSD. Les fichiers sont également stockés, respectivement. Eh bien, ClickHouse est une étrange version en quelque sorte.
Clickhouse et concurrents: exigences et opportunités
Que voulons-nous? Nous voulons que nous n'ayons pas eu besoin de prendre un bain de vapeur spécial avec l'opération, afin que cela fonctionne de préférence, avec une configuration minimale. Nous voulons écrire beaucoup et écrire rapidement. Et nous voulons le garder tous les mois, années, c'est-à-dire pendant longtemps. Nous pouvons vouloir régler une sorte de problème avec lequel ils sont venus, ils ont dit - "Quelque chose ne fonctionne pas ici pour nous", - c'était il y a 3 mois), et nous voulons pouvoir le voir il y a 3 mois ". Compression des données - on comprend pourquoi ce sera un plus - car la quantité d'espace occupé est réduite.

Et nous avons une exigence tellement intéressante: nous écrivons parfois la sortie de certaines commandes (par exemple, les journaux), cela peut être plus de 4 kilo-octets assez calmement. Et si cette chose fonctionne sur UDP, alors elle n'a pas besoin de dépenser ... elle n'aura pas de "surcharge" pour la connexion, et pour un grand nombre de serveurs ce sera un plus.

Voyons ce que l'open source nous offre. Premièrement, nous avons un moteur de journaux - c'est notre moteur; il sait tout, même les longues lignes peuvent écrire. Eh bien, il ne compresse pas les données de manière transparente - nous pouvons compresser nous-mêmes de grandes colonnes si nous le voulons ... nous, bien sûr, ne le voulons pas (si possible). Le seul problème est qu'il ne peut donner que ce qui est placé dans sa mémoire; le reste, pour lire, vous devez obtenir le binlog de ce moteur et, en conséquence, cela prend un certain temps.

Quelles sont les autres options? Par exemple, Khadup. Facilité d'utilisation ... Qui pense que le Hadoup est facile à configurer? Avec l'enregistrement, bien sûr, il n'y a aucun problème. Avec la lecture, des questions se posent parfois. En principe, je dirais que très probablement pas, en particulier pour les journaux. Stockage à long terme - bien sûr, oui, compression des données - oui, longues lignes - il est clair que vous pouvez écrire. Mais pour enregistrer à partir d'un grand nombre de serveurs ... Quoi qu'il en soit, nous devons faire quelque chose nous-mêmes!
Rsyslog. En fait, nous l'avons utilisé comme solution de rechange, de sorte qu'il serait possible de lire un binlog sans vidage, mais il ne pouvait pas écrire sur de longues lignes, en principe, il ne pouvait pas écrire plus de 4 kilo-octets. La compression des données doit être effectuée de la même manière. La lecture ira des fichiers.

Ensuite, il y a le "mauvais" développement du LSD. La même chose est essentiellement la même chose que "Rsyslog": il prend en charge les longues lignes, mais il ne sait pas comment utiliser UDP et, en fait, à cause de cela, malheureusement, il y a beaucoup de choses à réécrire. Le LSD doit être refait pour que vous puissiez enregistrer à partir de dizaines de milliers de serveurs.

Oh, ici! Une option amusante est ElasticSearch. Eh bien, comment dire? Tout va bien avec la lecture, c'est-à-dire qu'il lit rapidement, mais pas très bien avec l'écriture. Premièrement, s'il compresse les données, il est très faible. Très probablement, une recherche à part entière nécessite des structures de données plus volumineuses que le volume d'origine. Il est difficile à exploiter, souvent des problèmes surviennent. Et, encore une fois, une entrée dans le "Elastic" - nous devons tous le faire nous-mêmes.

Ici ClickHouse - l'option idéale, bien sûr. La seule chose est que l'enregistrement à partir de dizaines de milliers de serveurs est un problème. Mais elle est au moins une, nous pouvons essayer de le résoudre d'une manière ou d'une autre. Et le reste du rapport traite de ce problème. À quelle performance globale de ClickHouse pouvez-vous vous attendre?
Comment allons-nous intégrer? MergeTree
Combien d'entre vous n'ont pas entendu parler de ClickHouse, ne sais pas? Besoin de dire, pas nécessaire? Très vite. L'insert contient 1 à 2 gigabits par seconde, des rafales allant jusqu'à 10 gigabits par seconde peuvent réellement résister à cette configuration - il y a deux Xeons à 6 cœurs (ce n'est même pas les plus puissants), 256 gigaoctets de RAM, 20 téraoctets par RAID (personne configuré, paramètres par défaut). Alexey Milovidov, le développeur de ClickHouse, pleure probablement, que nous n'avons rien configuré (tout fonctionnait comme ça pour nous). Par conséquent, une vitesse de balayage d'environ 6 milliards de lignes par seconde peut être obtenue si les données sont bien compressées. Si vous aimez% sur une ligne de texte, faites - 100 millions de lignes par seconde, c'est-à-dire que cela semble très rapidement.

Comment allons-nous intégrer? Eh bien, vous savez que dans "VK" - en PHP. Nous, de chaque travailleur PHP, allons coller HTTP dans «ClickHouse», dans la plaque MergeTree pour chaque entrée. Qui voit le problème dans ce circuit? Pour une raison quelconque, tout le monde n'a pas levé la main. Disons-le.
Premièrement, il existe de nombreux serveurs - en conséquence, il y aura de nombreuses connexions (mauvaises). Ensuite, dans MergeTree, il est préférable d'insérer les données pas plus d'une fois par seconde. Et qui sait pourquoi? D'accord. Je vais vous en dire un peu plus à ce sujet. Une autre question intéressante est que, pour ainsi dire, nous ne faisons pas d'analyse, nous n'avons pas besoin d'enrichir les données, nous n'avons pas besoin de serveurs intermédiaires, nous voulons intégrer directement dans «ClickHouse» (de préférence - le plus droit, le mieux).

En conséquence, comment l'insertion est-elle implémentée dans MergeTree? Pourquoi vaut-il mieux ne pas l'insérer plus d'une fois par seconde ou moins? Le fait est que "ClickHouse" est une base de données en colonnes et trie les données dans l'ordre croissant de la clé primaire, et lorsque vous insérez, le nombre de fichiers est créé par au moins le nombre de colonnes dans lesquelles les données sont triées dans l'ordre croissant de la clé primaire (un répertoire séparé est créé, un ensemble de fichiers sur disque pour chaque insert). Ensuite, l'insertion suivante va, et en arrière-plan, ils fusionnent dans une plus grande "partition". Étant donné que les données sont triées, vous pouvez «jongler» avec deux fichiers triés sans consommer beaucoup de mémoire.
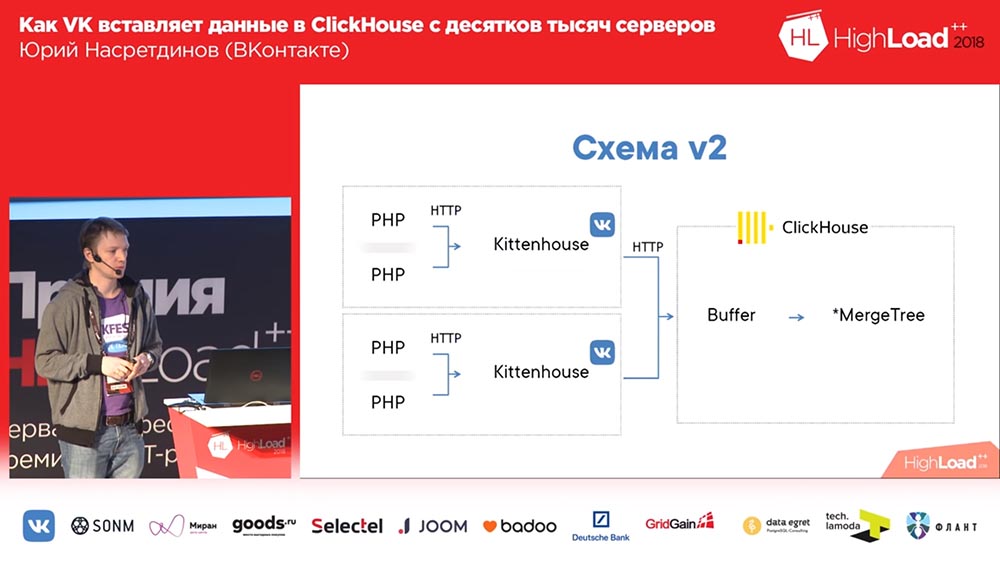
Mais, comme vous pouvez l'imaginer, si vous écrivez 10 fichiers pour chaque insertion, «ClickHouse» se terminera rapidement (ou votre serveur), il est donc recommandé d'insérer en gros lots. En conséquence, nous n'avons jamais lancé le premier schéma en production. Nous en avons immédiatement lancé un qui a le numéro 2 ici:

Imaginez ici qu'il y a environ un millier de serveurs sur lesquels nous avons lancé, il n'y a que PHP. Et sur chaque serveur, il y a notre agent local, que nous avons appelé «Kittenhouse», qui détient une connexion à «ClickHouse» et insère des données toutes les quelques secondes. Il n'insère pas de données dans MergeTree, mais dans la table du spouleur, qui ne sert pas à insérer directement dans MergeTree immédiatement.
Travailler avec des tables tampons
Qu'est ce que c'est Les tables tampons sont un morceau de mémoire mélangé (c'est-à-dire que vous pouvez souvent les insérer dedans). Ils sont constitués de plusieurs pièces et chacune fonctionne comme une mémoire tampon indépendante, et elles sont vidées indépendamment (si vous avez plusieurs pièces dans la mémoire tampon, il y aura de nombreux insertions par seconde). Vous pouvez lire à partir de ces tables - puis vous lisez l'union du contenu du tampon et de la table parent, mais à ce moment, l'enregistrement est bloqué, il est donc préférable de ne pas lire à partir de là. Et un très bon QPS est montré par les tables de tampons, c'est-à-dire que jusqu'à 3 000 QPS, vous n'aurez aucun problème avec l'insertion. Il est clair que si l'alimentation a été perdue sur le serveur, les données peuvent être perdues, car elles n'ont été stockées qu'en mémoire.

Dans le même temps, le schéma avec le tampon est compliqué par ALTER, car vous devez d'abord supprimer l'ancienne table de tampon avec l'ancien schéma (les données ne seront pas perdues en même temps, car elles seront vidées avant la suppression de la table). Ensuite, vous "modifiez" la table dont vous avez besoin et créez à nouveau la table tampon. Par conséquent, bien qu'il n'y ait pas de table tampon, vos données ne circulent nulle part, mais vous pouvez même localement sur disque.

Qu'est-ce que Kittenhouse et comment ça marche?
Qu'est-ce que KittenHouse? Ceci est un proxy. Devinez quelle langue? J'ai rassemblé les sujets les plus hype dans mon rapport - c'est «Clickhouse», allez, je me souviens peut-être d'autre chose. Oui, c'est écrit en Go, parce que je ne sais pas vraiment écrire en C, je ne veux pas.

En conséquence, il conserve une connexion avec chaque serveur, peut écrire en mémoire. Par exemple, si nous écrivons des journaux d'erreurs dans «Clickhouse», puis si «Clickhouse» n'a pas le temps d'insérer des données (après tout, si trop sont écrites), alors nous ne gonflons pas de mémoire - nous jetons simplement le reste. Parce que, si nous écrivons plusieurs gigabits par seconde d'erreurs, nous pouvons probablement en lancer. Kittenhouse sait comment. De plus, il sait comment livrer de manière fiable, c'est-à-dire qu'il écrit sur un disque sur la machine locale et de temps en temps (là, une fois en quelques secondes), il essaie de fournir des données à partir de ce fichier. Et au début, nous avons utilisé le format Values habituel - pas un format binaire, un format texte (comme dans le SQL standard).

Mais c'est arrivé. Nous avons utilisé une livraison fiable, écrit des journaux, puis décidé (c'était un cluster de test conditionnel) ... Pendant plusieurs heures, ils l'ont éteint et retiré, et il y avait un insert de milliers de serveurs - il s'est avéré que le Clickhouse avait toujours un «Thread on connexion »- en conséquence, sur mille connexions, l'insert actif entraîne une charge moyenne sur le serveur d'environ mille et demi. Étonnamment, le serveur a accepté les demandes, mais ces données ont néanmoins été insérées après un certain temps; mais il était très difficile pour le serveur de le réparer ...
Ajouter nginx
Une telle solution pour le modèle Thread per connection est nginx. Nous avons mis nginx devant le Clickhouse, en même temps réglé l'équilibrage à deux répliques (nous avons augmenté la vitesse d'insertion de 2 fois, mais pas le fait qu'il devrait en être ainsi), et limité le nombre de connexions à Clickhouse, à l'amont et, par conséquent, plus que dans 50 composés, il semble inutile d'insérer.

Ensuite, nous avons réalisé qu'en général, ce schéma présente des inconvénients, car nous avons un nginx ici. En conséquence, si ce nginx se couche, malgré la présence de répliques, nous perdons des données ou, du moins, n'écrivons nulle part. Par conséquent, nous avons fait notre répartition de charge. Nous avons également compris que «Clickhouse» est toujours adapté aux journaux, et le «démon» a également commencé à écrire ses propres journaux dans «Clickhouse» - très pratique, pour être honnête. Nous l'utilisons toujours pour d'autres "démons".

Ensuite, ils ont découvert un problème si intéressant: si vous utilisez une méthode pas tout à fait standard pour insérer en mode SQL, alors un analyseur à part entière AST SQL est forcé, ce qui est plutôt lent. En conséquence, nous avons ajouté des paramètres pour que cela ne se produise jamais. Nous avons fait l'équilibrage de charge, des bilans de santé, de sorte que si l'on décède, nous laissons toujours des données. Nous avons obtenu suffisamment de tables pour que nous ayons besoin de différents clusters «Clickhouse». Et nous avons commencé à penser à d'autres utilisations - par exemple, nous voulions écrire des journaux à partir de modules nginx, et ils ne peuvent pas communiquer à l'aide de notre RPC. Eh bien, je voudrais leur apprendre en quelque sorte comment envoyer - par exemple, via UDP pour recevoir des événements sur localhost, puis les envoyer au «Clickhouse».
Un pas de la décision
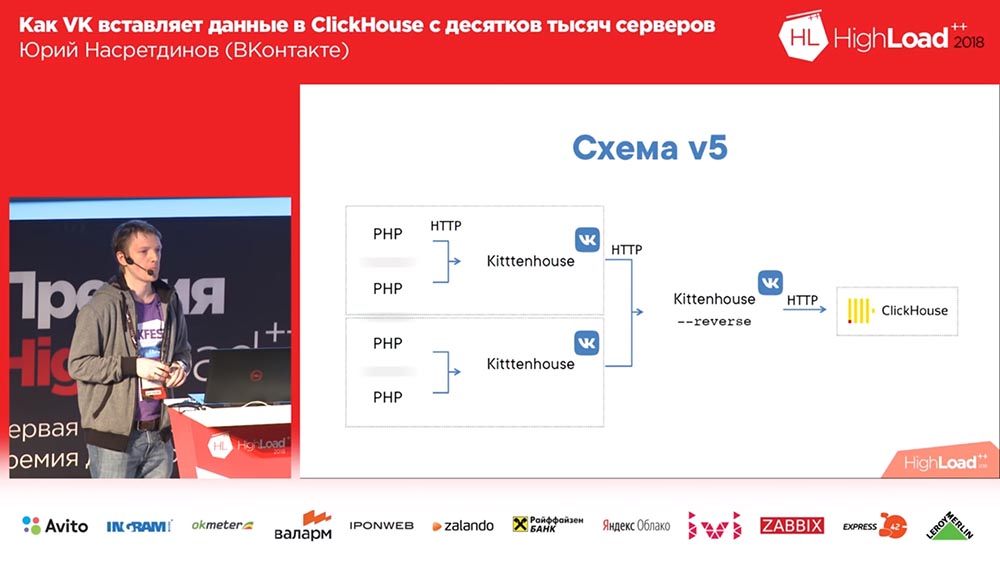
Le schéma final a commencé à ressembler à ceci (la quatrième version de ce schéma): sur chaque serveur devant le Clickhouse, il y a nginx (sur le même serveur, en plus) et il envoie simplement des requêtes par proxy à l'hôte local avec une limite sur le nombre de connexions de 50 pièces. Et maintenant, ce schéma fonctionnait déjà, il était assez bon avec lui.

Nous avons vécu comme ça pendant environ un mois. Tout le monde était content, ajouter des tables, ajouter, ajouter ... En général, il s'est avéré que la façon dont nous avons ajouté des tables tampons n'était pas très optimale (disons-le). Nous avons fait 16 pièces dans chaque table et un intervalle flash pendant quelques secondes; nous avions 20 tables et 8 insertions par seconde sont allées à chaque table - et à ce moment le «Clickhouse» a commencé ... les enregistrements ont commencé à devenir vierges. Ils n'ont même pas réussi ... Nginx avait une chose si intéressante par défaut que si les connexions se terminaient en amont, cela donne simplement "502" à toutes les nouvelles demandes.

Et ici chez nous (je viens de regarder les journaux dans le très «Clickhouse» que j'ai regardé) quelque part environ un demi pour cent des demandes échoue. En conséquence, l'utilisation du disque était élevée, il y avait de nombreuses fusions. Eh bien, qu'ai-je fait? Naturellement, je n'ai pas commencé à comprendre pourquoi la connexion et l'amont se terminent.
Remplacement de nginx par un proxy inverse
J'ai décidé que nous devons gérer cela nous-mêmes, ne le donnez pas à nginx - nginx ne sait pas quelles tables sont dans le "Clickhouse", et j'ai remplacé nginx par un proxy inverse, que j'ai également écrit.
Que fait-il? Il fonctionne sur la base de la bibliothèque fasthttp "goosh", c'est-à-dire rapide, presque aussi rapide que nginx. Désolé, Igor, si vous êtes ici (note: Igor Sysoev est un programmeur russe qui a créé le serveur Web nginx). Il peut comprendre de quel type de requêtes il s'agit - INSERT ou SELECT - respectivement, il conserve différents pools de connexions pour différents types de requêtes.

Par conséquent, même si nous n'avons pas le temps de répondre aux demandes, les "sélections" passeront, et vice versa. Et il regroupe les données dans des tables tampons - avec un petit tampon: s'il y avait des erreurs, des erreurs de syntaxe, etc. - afin qu'elles influencent légèrement le reste des données, parce que lorsque nous insérions simplement dans les tables tampons, nous avions de petites « bachi ”, et toutes les erreurs de syntaxe n'ont affecté que ce petit morceau; et ici, ils affecteront déjà le grand tampon. Petit est 1 mégaoctet, c'est-à-dire pas si petit.

L'insertion d'une synchronisation et le remplacement de nginx font essentiellement la même chose que nginx auparavant - le Kittenhouse n'a pas besoin d'être changé localement pour cela. Et comme il utilise fasthttp, il est très rapide - vous pouvez effectuer plus de 100 000 requêtes par seconde d'insertions simples via des proxy inverses. Théoriquement, vous pouvez insérer une ligne dans un proxy inverse kittenhouse, mais ce n'est certainement pas le cas.

Le schéma a commencé à ressembler à ceci: Kittenhouse, un proxy inverse regroupe de nombreuses demandes dans des tables, et à son tour, les tables tampons les insèrent dans les principales.
Killer - solution temporaire, Chaton - permanent
Il y avait un problème si intéressant ... Avez-vous utilisé fasthttp? Qui a utilisé fasthttp avec les requêtes POST? Probablement, cela ne valait pas la peine en fait, car il met en mémoire tampon le corps de la demande par défaut, et nous avons défini la taille de la mémoire tampon de 16 mégaoctets. L'insert a cessé d'être à temps à un moment donné, et de tous les dizaines de milliers de serveurs, des morceaux de 16 mégaoctets ont commencé à entrer, et ils ont tous été mis en mémoire tampon avant d'être envoyés au Clickhouse. En conséquence, la mémoire s'est épuisée, le tueur hors mémoire est venu, a tué le proxy inverse (ou «Clickhouse», qui pourrait théoriquement «manger» plus que le proxy inverse). Le cycle a été répété. Pas un très beau problème. Bien que nous ne soyons tombés sur cela qu'après quelques mois de fonctionnement.
Qu'ai-je fait? Encore une fois, je n'aime pas vraiment comprendre ce qui s'est exactement passé. Il me semble assez évident qu'il n'est pas nécessaire de mettre en mémoire tampon. Je n'ai pas pu patcher fasthttp, bien que j'aie essayé. Mais j'ai trouvé un moyen de faire en sorte qu'il n'y ait pas besoin de patcher quoi que ce soit, et j'ai trouvé ma propre méthode dans HTTP - appelée KITTEN. Eh bien, c'est logique - "VK", "Kitten" ... Comment sinon? ..

Si une demande arrive au serveur avec la méthode Kitten, alors le serveur doit répondre «miaou» - logiquement. S'il répond à cela, alors on pense qu'il comprend ce protocole, puis j'intercepte la connexion (il existe une telle méthode dans fasthttp), et la connexion passe en mode "brut". Pourquoi ai-je besoin de ça? Je veux contrôler la façon dont la lecture des connexions TCP se produit. TCP a une propriété merveilleuse: si personne ne lit de ce côté, l'enregistrement commence à attendre et la mémoire n'est pas spécialement dépensée pour cela.
Et donc j'ai lu quelque part à partir de 50 clients à la fois (de cinquante car cinquante devrait certainement suffire, même si ça vient d'un autre DC) ... La consommation a diminué avec cette approche au moins 20 fois, mais honnêtement je , Je n'ai pas pu mesurer exactement combien, car il est déjà inutile (il est déjà devenu au niveau d'erreur). Le protocole est binaire, c'est-à-dire qu'il y a un nom de table et des données; il n'y a pas d'en-tête http, donc je n'ai pas utilisé de socket web (je n'ai pas besoin de communiquer avec les navigateurs - j'ai fait un protocole qui correspond à nos besoins). Et avec lui, tout allait bien.
La table tampon est triste
Récemment, nous sommes tombés sur une autre caractéristique intéressante des tables tampons. Et ce problème est déjà beaucoup plus douloureux que les autres.
Imaginez cette situation: vous utilisez déjà activement «Clickhouse», vous avez des dizaines de serveurs «Clickhouse» et vous avez des requêtes qui se lisent depuis très longtemps (par exemple, plus de 60 secondes); et vous venez et faites Alter en ce moment ... Et tant que les "sélections" qui ont commencé avant "Alter" ne sont pas incluses dans ce tableau, "Alter" ne démarre pas - probablement certaines caractéristiques du fonctionnement de "Clickhouse" cet endroit. Peut-être que cela peut être corrigé? Ou pas?
, , , . , , , «» ( – , , ), … , «» ( - «» ) – , - : ( , ), «» , - , . , «», – .

(, ) – «» query_thread_log. , - . 840 (100 ). , (, , , ) «» (inserts). , «» – «» . , – , . Pourquoi? , ! .

, ? «». .
«KitttenHouse»
, ? . ! : , , - . , .

, «», – , (, - ) , , – .

? . , , 10 , – -, , . , , , , – , «», 100 - – , , , . , . , .
, , . : , - , , , read only . ? . – - , - … ( , «», ClickHouse) ? ? , . . : , . , . .
. . , - ?.. «»? - … «»? , , . , . , .

– . , . , : , , ( ), – , .

Sequel Pro, «», . : «, -?» ? 2018-? , «» (MySQL) , «», ! «», – , .
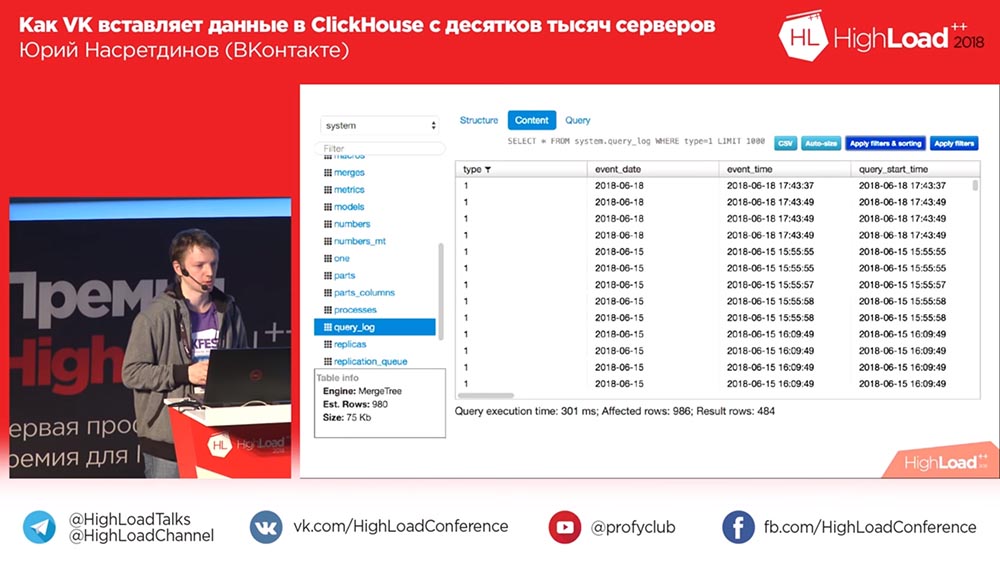
, , , , , , , , affected rows ( ), . .
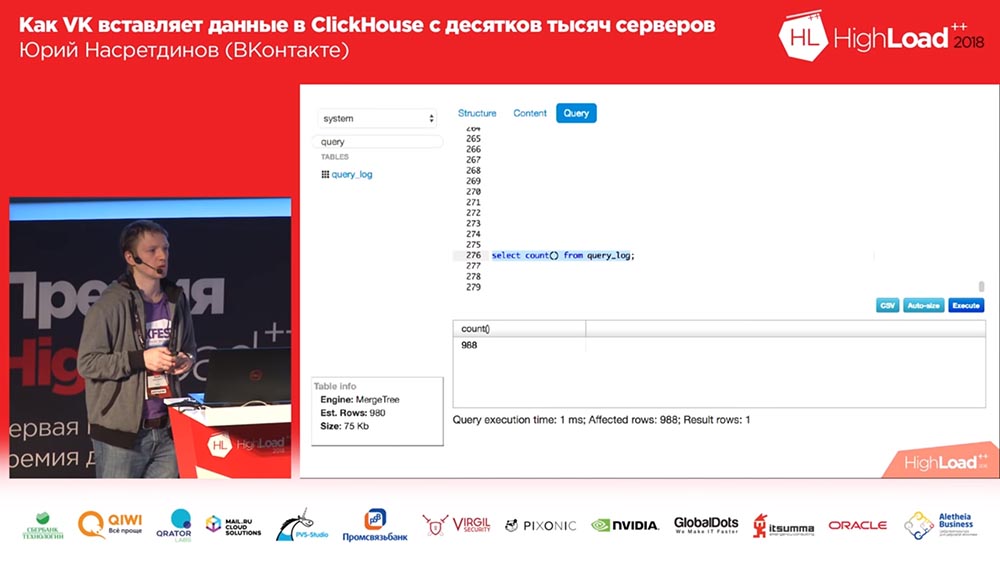
. «», . - - . .
«»
, «», , . , , – . , … , , .

TCP? , «» UDP. TCP… , , : «, ! , UDP». , TCP . , , – - ; , .
«» «» HighLoad Siberia, « »… , … , , . - , - , – , ( , , ).
. ! Github
. «» .
 :
: – , . , VHS.
( – ): – VHS, ?
 :"Vous aussi, vous ne pouvez pas déterminer complètement comment le Clickhouse fonctionnera ou ne fonctionnera pas!" Amis, 5 minutes pour les questions!
:"Vous aussi, vous ne pouvez pas déterminer complètement comment le Clickhouse fonctionnera ou ne fonctionnera pas!" Amis, 5 minutes pour les questions!Des questions
Question du public (ci-après - H): - Bonjour. Merci beaucoup pour le rapport. J'ai deux questions. Je vais commencer par une frivole: le nombre de lettres t du nom «Kittenhouse» sur les schémas (3, 4, 7 ...) affecte-t-il la satisfaction des chats?
UN: - La quantité de quoi?
Z: - Les lettres t. Il y en a trois t, quelque part trois t.
UN: - Ai-je vraiment corrigé cela? Bien sûr que oui! Ce sont des produits différents - je vous ai menti tout le temps. D'accord, je plaisante - ce n'est pas le cas. Ah, ici! Non, c'est la même chose, je suis scellé.
 Z:
Z: - Merci. La deuxième question est sérieuse. Pour autant que je sache, dans «Clickhouse», les tables tampons vivent exclusivement en mémoire, elles ne sont pas mises en mémoire tampon sur le disque et, par conséquent, ne sont pas persistantes.
UN: - Oui.
Z: - Et en même temps, sur votre client, une mise en mémoire tampon sur le disque est effectuée, ce qui implique une certaine garantie de livraison de ces mêmes journaux. Mais au Clickhouse, ce n'est pas garanti. Expliquez comment la garantie est exécutée, pour quelle raison? .. Ce mécanisme est plus détaillé
UN: - Oui, théoriquement, il n'y a pas de contradictions, car vous pouvez détecter un million de façons différentes en réalité lorsque le «Clickhouse» tombe. Si le «Clickhouse» plante (s'il n'est pas correctement complété), vous pouvez, en gros, rembobiner votre journal que vous avez noté un peu et recommencer à partir du moment où tout allait bien. Rembobinons il y a une minute, c'est-à-dire, on pense qu'il a tout flashé en une minute.
Z: - Autrement dit, le Kittenhouse garde la fenêtre plus longue et en cas de chute peut-elle la reconnaître et la dérouler?
UN: - Mais c'est en théorie. En pratique, nous ne le faisons pas et la livraison fiable est de zéro à l'infini. Mais en moyenne. Nous sommes convaincus que si le «Clickhouse» plante pour une raison quelconque ou que les serveurs «redémarrent», nous perdons un peu. Dans tous les autres cas, rien ne se passera.
Z: - Bonjour. Dès le début, il m'a semblé que vous utiliseriez vraiment UDP dès le début du rapport. Vous avez http, tout ça ... Et la plupart des problèmes que vous avez décrits, si je comprends bien, ont été causés par cette solution particulière ...
UN: - Qu'utilisons-nous TCP?
Z: - En fait, oui.
ONU: - Non.
Z: - C'est avec fasthttp que vous avez eu des problèmes, avec la connexion vous avez eu des problèmes. Si vous venez d'utiliser UDP, vous gagneriez du temps. Eh bien, il y aurait des problèmes avec les longs messages ou autre chose ...
UN: - Avec quoi?
 Z:
Z: - Avec de longs messages, car il peut ne pas rentrer dans le MTU, autre chose ... Eh bien, là, vos problèmes peuvent survenir. La question est: pourquoi n'est-ce pas UDP?
UN: - Je pense que les auteurs qui ont développé TCP / IP sont beaucoup plus intelligents que moi et savent mieux sérialiser les paquets (pour qu'ils aillent), en même temps ajuster la fenêtre d'envoi, ne pas surcharger le réseau et donner des commentaires sur ce lit, sans compter de l'autre côté ... Tous ces problèmes, à mon avis, seraient également dans UDP, seulement je devrais écrire encore plus de code que je l'ai déjà écrit afin d'implémenter la même chose moi-même et très probablement ce serait mauvais. Je n'aime même pas écrire en C, pas comme ça ...
Z: - Tout simplement pratique! Envoyé ok et n'attendez rien - vous avez absolument asynchrone. Un avis est revenu que tout va bien - cela signifie qu'il est venu; n'est pas venu - cela signifie mauvais.
UN: - J'ai besoin de cela et d'un autre - Je dois pouvoir envoyer les deux avec une garantie de livraison et sans garantie de livraison. Ce sont deux scénarios différents. Certains journaux que je n'ai pas besoin de perdre ou de ne pas perdre dans des limites raisonnables.
Z: - Je ne prendrai pas de temps. Cela devrait être discuté plus longtemps. Je vous remercie
Présentateur: - Qui a des questions - des stylos dans le ciel!
 Z:
Z: - Salut, je suis Sasha. Quelque part au milieu du rapport, il y avait le sentiment qu'il était possible, outre TCP, d'utiliser une solution toute faite - une sorte de Kafka.
UN: "Eh bien ... je vous ai dit que je ne voulais pas utiliser de serveurs intermédiaires, parce que ... pour Kafka - il se trouve que nous avons dix mille hôtes; en fait, nous avons plus - des dizaines de milliers d'hôtes. Avec Kafka, sans procuration, cela peut aussi faire mal. De plus, plus important encore, il donne toujours une "latence", donne les hôtes supplémentaires dont vous avez besoin. Et je ne veux pas les avoir - je veux ...
Z: - Mais finalement ça s'est avéré quand même.
UN: - Non, il n'y a pas d'hôtes! Tout fonctionne sur les hôtes Clickhouse.
Z: - Mais qu'en est-il du Kittenhouse, dont l'inverse est - où vit-il?
 UN:
UN: - Chez l'hôte de Klickhouse, il n'écrit rien sur le disque.
Z: - Eh bien, disons.
Présentateur: - Vous satisfait? Pouvons-nous donner un salaire?
Z: - Oui, oui. En fait, il y a beaucoup de béquilles pour obtenir la même chose, et maintenant - la réponse précédente sur le sujet du TCP contredit, à mon avis, cette situation. C'est comme si vous pouviez tout faire sur votre genou en beaucoup moins de temps.
ONU: - Et pourquoi n'ai-je pas voulu utiliser "Kafka", car il y avait beaucoup de plaintes dans le télégramme "Clickhouse" dans Telegram, par exemple, des messages de "Kafka" ont été perdus. Pas de Kafka elle-même, mais dans l'intégration de Kafka et Klikhaus; ou quelque chose ne s'y connectait pas. En gros, il faudrait alors que le client écrive alors à Kafka. Je ne pense pas qu'une solution plus simple et plus fiable serait obtenue.
Z: - Dites-moi, pourquoi n'avez-vous pas essayé des lignes ou un bus commun? Puisque vous dites qu'il était possible avec vous de manière asynchrone de parcourir la file d'attente les journaux eux-mêmes et également d'obtenir de manière asynchrone la file d'attente en réponse?
 UN:
UN: - Veuillez suggérer quelles files d'attente pourraient être utilisées?
Z: - Tout, même sans garantie qu'ils vont dans l'ordre. Tout Redis, RMQ ...
UN: - J'ai le sentiment que Redis ne sera probablement pas en mesure de tirer un tel volume d'insertion même sur un hôte (dans le sens de plusieurs serveurs) qui sort le Clickhouse. Je ne peux pas le confirmer avec des preuves (je ne l'ai pas comparé), mais il me semble que Redis n'est pas la meilleure solution ici. En principe, vous pouvez considérer ce système comme une file d'attente de messages impromptue, mais uniquement pour «Clickhouse»
Présentateur: - Yuri, merci beaucoup. Je propose de terminer les questions et réponses à ce sujet et de dire laquelle des personnes qui ont posé la question nous donnera un livre.
ONU: - Je voudrais donner un livre à la première personne qui a posé une question.
Présentateur: - Super! Super! Super! Merci beaucoup!
Un peu de publicité :)
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en recommandant à vos amis
des VPS basés sur le cloud pour les développeurs à partir de 4,99 $ , un
analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur les VPS (KVM) E5-2697 v3 (6 cœurs) 10 Go DDR4 480 Go SSD 1 Gbit / s à partir de 19 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher au centre de données Equinix Tier IV à Amsterdam? Nous avons seulement
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99 $! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?