chapitres précédents
30. Interprétation de la courbe d'apprentissage: biais important
Supposons que votre courbe d'erreur sur un échantillon de validation ressemble à ceci:
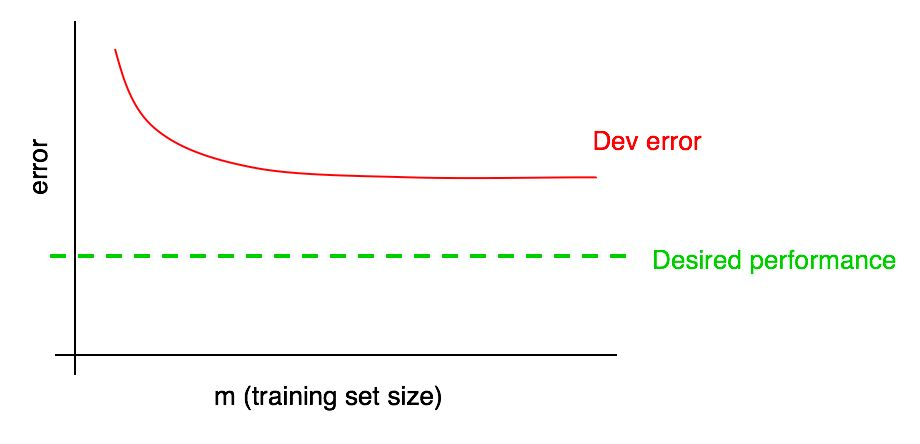
Nous avons déjà dit que si une erreur d'algorithme dans l'échantillon de validation atteint un plateau, il est peu probable que vous atteigniez le niveau de qualité souhaité simplement en ajoutant des données.
Mais il est difficile d'imaginer à quoi ressemblera l'extrapolation de la courbe de la dépendance de la qualité de l'algorithme sur l'échantillon de validation (erreur Dev) lors de l'ajout de données. Et si l'échantillon de validation est petit, répondre à cette question est encore plus difficile du fait que la courbe peut être bruyante (avoir une large répartition des points).
Supposons que nous ayons ajouté à notre graphique une courbe de la dépendance de l'ampleur de l'erreur sur la quantité de données de l'échantillon de test et obtenu l'image suivante:
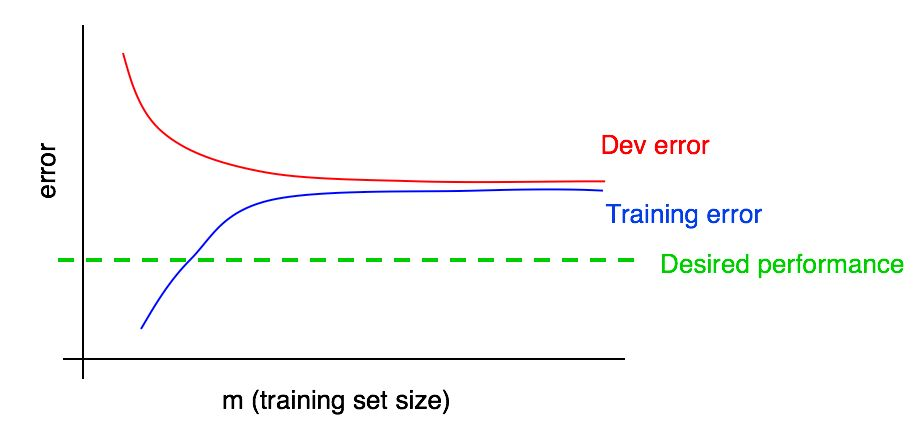
En regardant ces deux courbes, vous pouvez être absolument sûr que l'ajout de nouvelles données à lui seul ne donnera pas l'effet souhaité (cela ne permettra pas d'augmenter la qualité de l'algorithme). Où tirer cette conclusion?
Rappelons les deux points suivants:
- Si nous ajoutons plus de données à l'ensemble d'apprentissage, l'erreur d'algorithme dans l'ensemble d'apprentissage ne peut qu'augmenter. Ainsi, la ligne bleue de notre graphique ne changera pas ou se déplacera et s'éloignera du niveau de qualité souhaité de notre algorithme (ligne verte).
- La ligne d'erreur rouge dans l'échantillon de validation est généralement plus élevée que la ligne d'erreur bleue de l'algorithme dans l'échantillon d'apprentissage. Ainsi, dans toutes les circonstances envisageables, l'ajout de données n'entraînera pas une nouvelle diminution de la ligne rouge, elle ne la rapprochera pas du niveau d'erreur souhaité. Cela est presque impossible, étant donné que même l'erreur dans l'échantillon d'apprentissage est plus élevée que souhaité.
La prise en compte des deux courbes de la dépendance de l'erreur de l'algorithme sur la quantité de données dans les échantillons de validation et d'apprentissage sur le même graphique vous permet d'extrapoler avec plus de confiance la courbe d'erreur de l'algorithme d'apprentissage à partir de la quantité de données dans l'échantillon de validation.
Supposons que nous ayons une estimation de la qualité souhaitée de l'algorithme sous la forme d'un niveau optimal d'erreurs dans notre système. Dans ce cas, les graphiques ci-dessus sont une illustration d'un cas standard de «manuel» de l'apparence de la courbe d'apprentissage avec un niveau élevé de biais amovible. À la plus grande taille de l'échantillon d'apprentissage, correspondant vraisemblablement à toutes les données dont nous disposons, il existe un grand écart entre l'erreur d'algorithme dans l'échantillon d'apprentissage et la qualité souhaitée de l'algorithme, ce qui indique un niveau élevé de biais évité. De plus, l'écart entre l'erreur dans l'échantillon d'apprentissage et l'erreur dans l'échantillon de validation est faible, ce qui indique une petite dispersion.
Plus tôt, nous avons discuté des erreurs d'algorithmes formés sur des échantillons de formation et de validation uniquement au point le plus à droite au-dessus du graphique, ce qui correspond à l'utilisation de toutes les données de formation dont nous disposons. La courbe des dépendances de l'erreur sur la quantité de données de l'échantillon d'apprentissage, construites pour différentes tailles de l'échantillon utilisé pour la formation, nous donne une image plus complète de la qualité de l'algorithme formé sur différentes tailles de l'échantillon d'apprentissage.
31. Interprétation de la courbe d'apprentissage: autres cas
Considérez la courbe d'apprentissage:
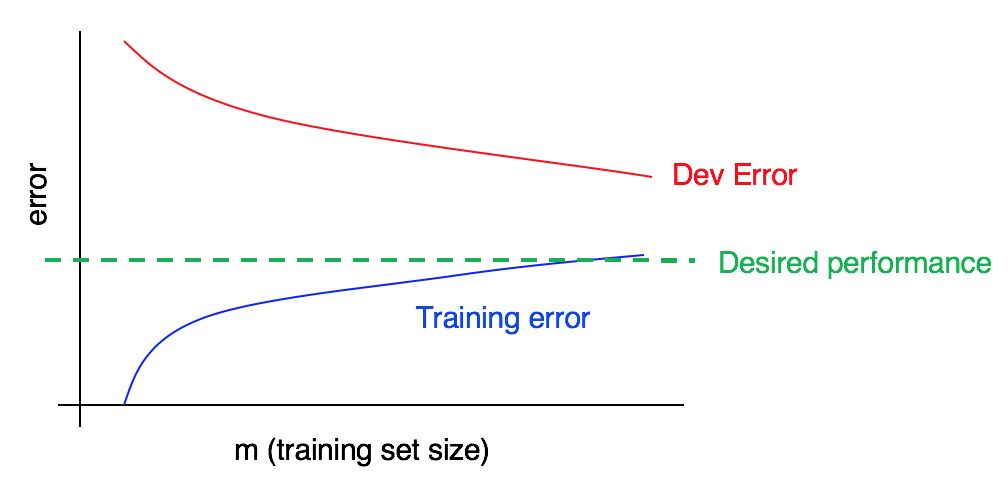
Y a-t-il un biais élevé, une analyse syntaxique élevée, ou les deux à la fois?
La courbe d'erreur bleue sur les données d'entraînement est relativement faible, la courbe d'erreur rouge sur les données de validation est significativement plus élevée que l'erreur bleue sur les données d'entraînement. Ainsi, dans ce cas, le biais est faible, mais l'écart est important. L'ajout de données de formation supplémentaires peut aider à combler l'écart entre l'erreur dans l'échantillon de validation et l'erreur dans l'échantillon de formation.
Considérez maintenant ce tableau:
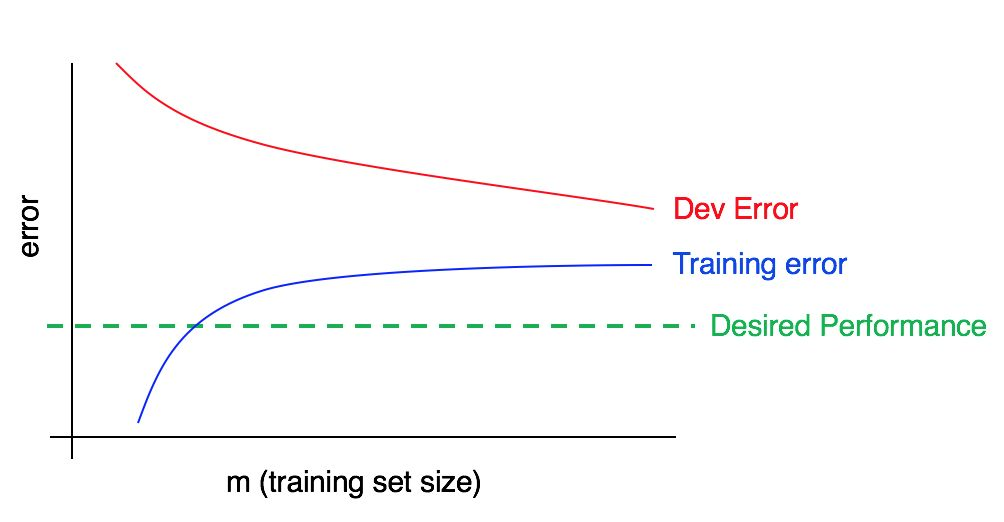
Dans ce cas, l'erreur dans l'échantillon d'apprentissage est importante; elle est nettement supérieure à l'algorithme correspondant au niveau de qualité souhaité. L'erreur dans l'échantillon de validation est également significativement plus élevée que l'erreur dans l'échantillon d'apprentissage. Ainsi, nous avons affaire simultanément à un biais et une dispersion importants. Vous devriez chercher des moyens de réduire et de compenser et de disperser votre algorithme.
32. Construire des courbes d'apprentissage
Supposons que vous ayez un très petit échantillon de formation, composé de seulement 100 exemples. Vous entraînez votre algorithme à l'aide d'un sous-ensemble sélectionné au hasard de 10 exemples, puis de 20 exemples, puis de 30 et ainsi de suite à 100, augmentant le nombre d'exemples avec un intervalle de dix exemples. Ensuite, en utilisant ces 10 points, vous construisez votre courbe d'apprentissage. Vous pouvez constater que la courbe semble bruyante (valeurs supérieures ou inférieures à celles attendues) pour les échantillons d'entraînement plus petits.
Lorsque vous entraînez l'algorithme avec seulement 10 exemples sélectionnés au hasard, vous n'aurez peut-être pas de chance et cela se révélera être un sous-échantillon de formation particulièrement «mauvais» avec une plus grande part d'exemples ambigus / mal marqués. Ou, à l'inverse, vous pouvez rencontrer un sous-échantillon de formation particulièrement «bon». La présence d'un petit échantillon d'apprentissage implique que la valeur des erreurs dans les échantillons de validation et d'apprentissage peut être sujette à des fluctuations aléatoires.
Si les données utilisées pour votre application utilisant l'apprentissage automatique sont fortement biaisées vers une classe (comme avec le problème de classification des chats, dans lequel la proportion d'exemples négatifs est beaucoup plus grande que la proportion de positifs), ou si nous avons affaire à un grand nombre de classes (telles que reconnaissance de 100 espèces animales différentes), la chance d'obtenir un échantillon de formation particulièrement «non représentatif» ou médiocre augmente également. Par exemple, si 80% de vos exemples sont des exemples négatifs (y = 0), et seulement 20% sont des exemples positifs (y = 1), alors il y a de fortes chances qu'un sous-ensemble de formation de 10 exemples contienne uniquement des exemples négatifs, dans ce cas très il est difficile d'obtenir quelque chose de raisonnable à partir de l'algorithme entraîné.
Si, en raison du bruit de la courbe d'apprentissage dans l'échantillon d'apprentissage, il est difficile de faire une évaluation des tendances, on peut proposer les deux solutions suivantes:
Au lieu de former un seul modèle pour 10 exemples de formation, sélectionner avec remplacement plusieurs (disons 3 à 10) sous-échantillons de formation aléatoires différents dans l'échantillon initial composé de 100 exemples. Former le modèle sur chacun d'eux et calculer pour chacun de ces modèles l'erreur sur l'échantillon de validation et d'apprentissage. Comptez et tracez l'erreur moyenne sur les échantillons d'apprentissage et de validation.
Remarque de l'auteur: Un échantillon avec remplacement signifie ce qui suit: sélectionnez au hasard les 10 premiers exemples différents parmi 100 pour former le premier sous-échantillon de formation. Ensuite, pour former le deuxième sous-échantillon de formation, prenez à nouveau 10 exemples, mais en excluant ceux sélectionnés dans le premier sous-échantillon (encore une fois sur une centaine d'exemples). Ainsi, un exemple spécifique peut apparaître dans les deux sous-échantillons. Cela distingue un échantillon avec remplacement d'un échantillon sans remplacement; dans le cas d'un échantillon sans remplacement, le deuxième sous-échantillon d'apprentissage serait sélectionné parmi seulement 90 exemples qui ne faisaient pas partie du premier sous-échantillon. En pratique, la méthode de sélection des exemples avec ou sans substitution ne devrait pas être d'une grande importance, mais la sélection d'exemples avec substitution est une pratique courante.
Si votre échantillon d'apprentissage est biaisé vers l'une des classes, ou s'il comprend plusieurs classes, choisissez un sous-échantillon «équilibré» composé de 10 exemples d'apprentissage, choisis au hasard parmi 100 échantillons d'échantillons. Par exemple, vous pouvez être sûr que 2/10 exemples sont positifs et 8/10 négatifs. Pour résumer, vous pouvez être sûr que la proportion d'exemples de chaque classe dans l'ensemble de données observées est aussi proche que possible de leur part dans l'échantillon de formation initiale.
Je ne m'embêterais avec aucune de ces méthodes jusqu'à ce que la représentation graphique des courbes d'erreur conduise à la conclusion que ces courbes sont excessivement bruyantes, ce qui ne nous permet pas de voir des tendances compréhensibles. Si vous avez un grand échantillon de formation - disons environ 10 000 exemples et que la distribution de vos cours n'est pas très biaisée, vous n'aurez peut-être pas besoin de ces méthodes.
Enfin, la construction d'une courbe d'apprentissage peut être coûteuse d'un point de vue informatique: par exemple, vous devez former dix modèles, dans les 1000 premiers exemples, dans le second 2000, et ainsi de suite jusqu'au dernier contenant 10000 exemples. La formation de modèles sur de petites quantités de données est beaucoup plus rapide que la formation de modèles sur de grands échantillons. Ainsi, au lieu de répartir uniformément les tailles des sous-échantillons d'apprentissage sur une échelle linéaire, comme décrit ci-dessus (1000, 2000, 3000, ..., 10000), vous pouvez former des modèles avec une augmentation non linéaire du nombre d'exemples, par exemple, 1000, 2000, 4000, 6000 et 10 000 exemples. Cela devrait tout de même vous donner une compréhension claire de la tendance de la dépendance de la qualité du modèle au nombre d'exemples de formation dans les courbes d'apprentissage. Bien sûr, cette technique n'est pertinente que si le coût de calcul de la formation de modèles supplémentaires est élevé.
suite