Comme tout le monde le sait déjà, le tri peut être basé sur les échanges, les insertions, la sélection, la fusion et la distribution.
Mais si différentes méthodes sont combinées dans l'algorithme, alors il appartient à la classe des sortes hybrides.

Cet article a été écrit avec le soutien d'EDISON.
Nous sommes engagés dans la réalisation et la maintenance de sites sur 1C-Bitrix , ainsi que dans le développement d'applications mobiles Android et iOS .
Nous aimons la théorie des algorithmes! ;-)
Rappelons rapidement quels sont les algorithmes de tri des classes et quelles sont les fonctionnalités de chacun d'eux.
Exchange Sorts
Les éléments du réseau sont comparés deux à deux et des échanges sont effectués pour des paires désordonnées.
Le représentant le plus efficace de cette classe est le
tri rapide légendaire.
Tri d'insertion
Les éléments de la partie non triée du tableau sont insérés à leur place dans la zone triée.
Dans cette classe, le
tri par insertions simples est le plus souvent utilisé. Bien que cet algorithme ait une complexité moyenne de O (
n 2 ), ce tri fonctionne très rapidement avec des tableaux presque ordonnés - sur eux la complexité atteint O (
n ). De plus, ce tri est l'une des meilleures options pour le traitement de petits tableaux.
Le tri à l'aide de l'arbre de recherche binaire appartient également à cette classe.
Trier par sélection

Dans la zone non ordonnée, l'élément minimum / maximum est sélectionné, qui est transféré à la fin / au début de la partie non triée du tableau.
Le tri avec un choix simple fonctionne très lentement (en moyenne O (
n 2 )), mais dans cette classe il y a un
tri difficile
par tas (aka
tri pyramidal ), qui a une complexité temporelle de O (
n log
n ) - et, ce qui est très précieux, Il n'y a pas de cas dégénérés de ce tri, quelles que soient les données entrantes. Soit dit en passant, ce tri n'a pas non plus les meilleurs cas pour les données entrantes.
Fusionner les tris
Les zones triées sont prises dans le tableau et elles sont fusionnées, c'est-à-dire que les sous-réseaux triés plus petits sont combinés en un sous-tableau trié plus grand.
Si deux sous-réseaux sont triés, leur combinaison est une opération facile à mettre en œuvre et rapide. Le revers de la médaille est que la fusion nécessite presque toujours le coût de la mémoire supplémentaire O (
n ) - bien qu'il existe très peu d'options très sophistiquées pour trier avec la fusion, où le coût de la mémoire est O (1).
Trier par distribution
Les éléments du tableau sont distribués et redistribués en classes jusqu'à ce que le tableau accepte un état trié.
Les éléments sont dispersés en groupes soit en fonction de leur valeur (les soi-disant
triages de comptage ) soit en fonction de la valeur des chiffres individuels (ce sont déjà
des triages au niveau du bit ).
Le tri par
seau appartient également à cette classe.
Une caractéristique du tri par distribution est qu'ils n'utilisent pas de comparaisons par paire d'éléments entre eux, ou que de telles comparaisons sont présentes dans une faible mesure. Par conséquent, le tri par distribution est souvent en avance sur la vitesse, par exemple, le tri rapide. D'un autre côté, le tri par distribution nécessite souvent beaucoup de mémoire supplémentaire, car les groupes d'éléments constamment redistribués doivent être stockés quelque part.
Les différends concernant le tri
le plus efficace sont très fréquents, mais le fait est qu'il n'y a pas et ne peut pas être un algorithme idéal pour toutes les occasions. Par exemple, le tri rapide est vraiment très rapide (mais pas le plus rapide) dans la plupart des situations, mais il rencontre également des cas dégénérés dans lesquels un crash se produit. Le tri par insertions simples est lent, mais pour les tableaux presque ordonnés, il contournera facilement les autres algorithmes. Le tri de tas fonctionne assez rapidement avec toutes les données entrantes, mais pas aussi rapidement que d'autres tri dans certaines conditions et il n'y a aucun moyen d'accélérer la pyramide. Le tri par fusion est plus lent que le tri rapide, mais s'il existe des sous-tableaux triés dans le tableau, il est plus rapide de les fusionner que le tri par tri rapide. Si le tableau contient de nombreux éléments répétitifs ou si nous trions les lignes, le tri par distribution est probablement la meilleure option. Chaque méthode est particulièrement bonne dans sa situation la plus favorable.
Néanmoins, les programmeurs continuent d'inventer les tris les plus rapides au monde, synthétisant les méthodes les plus efficaces de différentes classes. Voyons à quel point c'est réussi pour eux.
Étant donné que de nombreux algorithmes non triviaux sont mentionnés dans l'article, je ne couvre que brièvement les principes de base de leur travail, sans surcharger l'article d'animations et d'explications détaillées. À l'avenir, il y aura des articles séparés, où il y aura des dessins animés pour chaque algorithme et des nuances subtiles détaillées.
Insérer + fusionner
Une conclusion purement empirique est que la fusion et / ou l'insertion sont le plus souvent utilisées dans les hybrides. Dans la plupart des tri, on trouve l'une ou l'autre méthode, ou les deux ensemble. Et il y a une explication logique à cela.
Les inventeurs de tri s'efforcent souvent de créer des algorithmes parallèles qui ordonnent simultanément différentes parties d'un tableau. La meilleure façon de traiter plusieurs sous-réseaux triés est de les fusionner - ce sera le plus rapide.
Les algorithmes modernes utilisent souvent la récursivité. Lors d'une descente récursive, le réseau est généralement divisé en deux parties; au niveau le plus bas, le réseau est ordonné. Lorsque l'on revient à des niveaux de récursivité supérieurs, la question se pose de combiner des sous-réseaux triés à des niveaux inférieurs.
En ce qui concerne les insertions, dans des algorithmes hybrides à certaines étapes, on obtient souvent des sous-réseaux approximativement ordonnés, qui sont mieux conduits à la commande finale à l'aide d'inserts.
Ce groupe contient des tris hybrides, dans lesquels il y a une fusion et une insertion, et ces méthodes sont utilisées très différemment.
Tri par fusion-insertion
Algorithme Ford Johnson :: Algorithme Ford-Johnson
Fusionner + Insérer

Une manière très ancienne, déjà en 1959. Il est décrit en détail dans le travail immortel de Donald Knuth, «The Art of Programming», Volume 3, «Sorting and Searching», Chapter 5, «Sorting», Section 5.3, «Optimal Sorting», sous-section, «Sorting with a minimum number of comparisons», and part «Sorting by Inserts and Merging». .
Le tri n'a plus de valeur pratique, mais il est intéressant pour ceux qui aiment la théorie des algorithmes. Le problème de trouver un moyen de trier
n éléments avec le moins de comparaisons est considéré. Une modification heuristique non triviale du tri par insertion (une telle insertion que vous ne trouverez nulle part ailleurs) utilisant des
nombres de Jacobstal est proposée afin de minimiser le nombre de comparaisons. À ce jour, il est également connu que ce n'est pas la meilleure option et vous pouvez encore plus habilement esquiver et obtenir encore moins de comparaisons. En général, le tri académique standard n'est pas d'une utilité pratique, mais pour les connaisseurs du genre, c'est un plaisir de démonter de telles astuces avec un biais algébrique.
Tim Sort :: Timsort
Insérer + fusionner
 Publié par Tim Peters il y a 15 ans et maintenant
Publié par Tim Peters il y a 15 ans et maintenantCe tri sur Habré est très souvent rappelé.
Thèse: dans un tableau, on recherche des petits sous-réseaux presque ordonnés pour lesquels le tri par insertion est utilisé. Ces sous-réseaux sont ensuite fusionnés à l'aide de la fusion.
La fusion dans TimSort est la partie la plus intéressante: la fusion ascendante classique est encore optimisée pour différentes situations. Par exemple, il est connu que la fusion est plus efficace si les sous-réseaux joints ont approximativement la même taille. Dans TimSort, si les tailles sont très différentes, après des actions supplémentaires, il y a un ajustement (nous pouvons dire qu'une partie des éléments «coulera» du plus grand sous-tableau vers un plus petit, après quoi la fusion se poursuivra en mode standard). Diverses situations insidieuses sont également fournies - par exemple, si dans un sous-tableau tous les éléments seront inférieurs à ceux d'un autre. Dans ce cas, la comparaison des éléments des deux sous-réseaux sera inactive. La procédure de fusion modifiée «remarquera» une telle évolution indésirable des événements dans le temps, et si elle est «convaincue» d'une option pessimiste utilisant la recherche binaire, elle passera à une option de traitement plus optimale.
En moyenne, ce tri fonctionne un peu plus lentement que QuickSort, cependant, si le tableau entrant contient un nombre suffisant de sous-séquences ordonnées d'éléments, alors la vitesse augmente de manière significative et ici TimSort devance les autres.
Tri par fusion de blocs :: Tri par fusion de blocs
Wiki-sort :: Wiki-sort
Holy Grail Sort :: Grailsort
Inserts + Fusionner + Godets
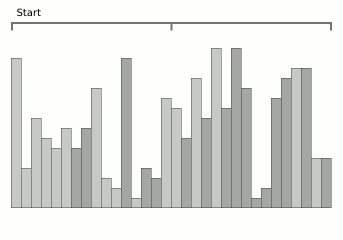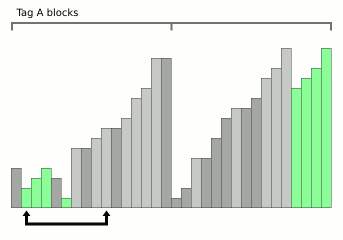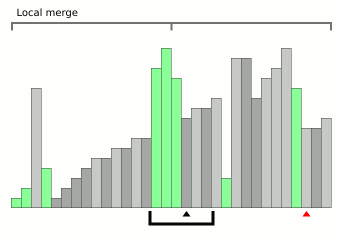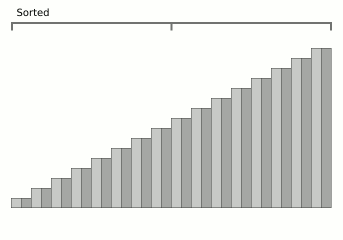 Animation de tri par fusion de blocs de Wikipedia.
Animation de tri par fusion de blocs de Wikipedia.Il s'agit d'un algorithme très récent (2008) et en même temps très prometteur. Le fait est que le problème relativement important de la fusion est le coût de la mémoire supplémentaire. Habituellement, là où la fusion est là, il y a aussi la complexité de la mémoire O (
n ).
Mais WikiSort est conçu pour que la fusion se fasse sans l'utilisation de mémoire supplémentaire - parmi les types de fusion, à cet égard, il s'agit d'un cas très rare. De plus, l'algorithme est stable. Eh bien, si le tri par fusion conventionnel a la meilleure vitesse algorithmique O (
n log
n ), alors dans le tri wiki, cet indicateur est O (
n ). Jusqu'à récemment, on pensait que fusionner le tri avec un tel ensemble de caractéristiques était en principe impossible, mais les programmeurs chinois ont surpris tout le monde.
L'algorithme est très compliqué à expliquer en quelques phrases. Mais un jour j'écrirai une habrast distincte à son sujet.
Initialement, l'algorithme était appelé sans nom Block Merge Sort, cependant, avec la main légère de Tim Peters, qui a étudié le tri en détail (pour déterminer si certaines de ses idées devraient être transférées à TimSort), le nom WikiSort y est resté.
Le habruiser partant prématurément
Mrrl a travaillé indépendamment pendant plusieurs années sur le tri par fusion, qui serait simultanément rapide avec toutes les données entrantes, économique en mémoire et stable.
Ses recherches créatives ont été couronnées de succès et il a appelé plus tard l'algorithme développé un tri du Saint Graal (car il répond à toutes les exigences élevées du «tri parfait»). La plupart des idées de cet algorithme sont similaires à celles implémentées dans WikiSort, bien que ces sortes ne soient pas identiques et soient développées indépendamment les unes des autres.
Tri de table de hachage :: Tri de table de hachage
Distribution + Insertion + Fusion
Le tableau est récursivement divisé en deux, jusqu'à ce que le nombre d'éléments dans les sous-réseaux résultants atteigne une certaine valeur de seuil. Au niveau de récursivité le plus bas, une distribution approximative se produit (à l'aide d'une table de hachage) et le sous-tableau est trié par insertions. Ensuite, il y a un retour récursif à des niveaux supérieurs, les moitiés triées sont combinées par fusion.
J'ai
parlé un peu plus de cet algorithme il y a un
mois .
Tri rapide comme principal
Après la fusion et l'insertion, la troisième place du hit-parade hybride est fermement détenue par le tri rapide préféré de tous.
Il s'agit d'un algorithme très efficace, mais il existe également des cas dégénérés. Certains inventeurs tentent de rendre QuickSort complètement invulnérable à toute mauvaise donnée entrante et suggèrent de la compléter avec des idées fortes d'autres types.
Tri introspectif :: Introsort, tri introspectif, std :: sort
Inserts rapides + tas +
Le tri par tas fonctionne un peu plus lentement que le tri rapide, mais en même temps, contrairement à QuickSort, il n'a pas de cas dégénérés - la complexité temporelle algorithmique moyenne, meilleure et pire est O (
n log
n ).
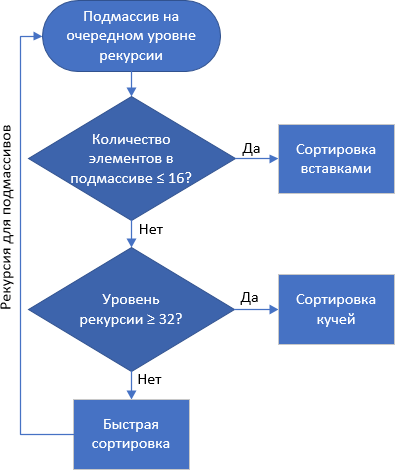
Par conséquent, David Musser a proposé d'être sûr lors du tri rapide - s'il y a un niveau d'imbrication trop élevé, cela est considéré comme une attaque contre le système, qui a glissé un "mauvais" tableau. Le passage au tri par segment de mémoire se produit, ce qui n'est pas mégaoctet, mais pas non plus lent pour faire face
aux données entrantes.
C ++ possède un algorithme appelé std :: sort, qui est une implémentation du tri introspectif. Un petit ajout - si au niveau de récursivité suivant le
nombre d'éléments du sous-tableau est ≤ 16 , alors le tri par insertion est appliqué au sous-tableau.
Tri multi-points :: Tri multi-points
Tri rapide au niveau du bit :: Tri rapide Radix
Fast + rangs
Tri rapide, seules les valeurs des éléments du tableau sont comparées, mais leurs chiffres individuels (d'abord, nous organisons les chiffres les plus élevés de cette manière, nous passons des plus jeunes à eux).
Ou alors - c'est un tri au niveau du bit par ordre élevé, l'ordre à l'intérieur du bit suivant est effectué selon l'algorithme de tri rapide.
Tri par dispersion :: Spreadsort
Rapide + fusion + seaux + décharges
Gestalt à partir du tri rapide, du tri par fusion, du tri par compartiment et du tri au niveau du bit.
En un mot, ne l'expliquez pas. Nous analyserons cet algorithme en détail dans l'un des articles suivants.
Autres hybrides
Tri par comptage d'arbres
Comptage + arbre
L'algorithme
proposé par l' utilisateur
AlexanderUsatov . En comptant le tri, le nombre de clés comptées est stocké dans une arborescence équilibrée.
J-sort :: J-sort
Tas + inserts
J'ai
déjà écrit sur ce tri
il y a 5 ans . Tout est assez simple - d'abord dans le tableau, vous devez créer une fois un tas non croissant, puis faire exactement le contraire - construire une fois non décroissant. À la suite de la première opération, le minimum sera à la première place du tableau et les petits éléments dans leur ensemble se déplaceront de manière significative au début. Dans le second cas, le maximum sera à la dernière place et les gros éléments migreront vers la fin du tableau. En général, nous obtenons un tableau presque trié avec lequel nous faisons quoi? C'est vrai - triez les inserts.
Les références
 Fusion-insertion
Fusion-insertion ,
Bloc-fusion ,
Tim ,
Introspective ,
Spread ,
Multikey Graal
Graal Graal
Graal ,
table de hachage ,
comte / arbre ,
JArticles de série:
De tous les tri qui sont présentés ici, dans l'application Excel AlgoLab, seule l'animation Jsort est actuellement implémentée.