Pendant longtemps, de nombreuses personnes ont utilisé activement ou activement le modèle de stockage et de publication de la
documentation sous forme de code , ce qui signifie appliquer les mêmes règles, outils et procédures à la documentation qu'au code de programme, par exemple, le stocker dans le référentiel, exécuter des tests, compiler et publier en CI / CD. Cette approche vous permet de maintenir la documentation à jour avec le code, la version et de suivre les modifications à l'aide d'outils de développement familiers.
Cependant, dans le même temps, de nombreuses entreprises ont également des wikis depuis des années, dans lesquels d'autres équipes et employés, par exemple des chefs de projet, ont accès à la documentation. Et si vous vouliez apporter le stockage et la publication à une seule vue, c'est-à-dire avec les quais de publication HTML dans Confluence? Dans cet article, je donnerai un aperçu des solutions pour la tâche de publication de documents à partir du référentiel dans Confluence.
J'utilise activement une solution depuis longtemps
moi -
même dans l'équipe de développement d'interface (bundle RST-Sphinx + sphinxcontribbuilder), et je présenterai les autres comme une alternative, je dirai tout de suite que je ne les ai pas essayées en pratique, je viens d'étudier la configuration.
Sphinx doc + sphinxcontribbuilder
Sphinx (à ne pas confondre avec l'index de recherche du même nom) est un générateur de documentation écrit en Python et activement utilisé par la communauté; il fonctionne également très bien dans d'autres environnements.
Nous ne nous attarderons pas sur la configuration détaillée, je ferai seulement une réserve pour que, hors de la boîte, il puisse générer du HTML statique, man, pdf et un certain nombre d'autres formats, et pour l'assemblage et la publication corrects dans le référentiel, il doit y avoir des fichiers index.rst (balisage de la page principale), conf.py (fichier de configuration) et Makefile (un fichier qui décrit le processus de génération des formats, ici il est tout à fait possible de le coudre dans docker et d'y exécuter la commande
sphinx-build ).
Prêt à l'emploi, Sphinx peut générer des quais à partir d'une disposition légère * .rst (RestructuredText), mais nous avons ajouté la possibilité d'écrire dans Markdown (version CommonMark) pour les développeurs qui sont plus à l'aise (l'extension
m2r qui convertit MD en RST nous a aidé) .
Nous avons déjà configuré l'environnement entier pour Sphinx, et l'assemblage de documentation est câblé à une étape distincte du
pipeline Jenkins, nous avons donc continué et utilisé l'extension
sphinxcontrib.confluencebuilder , qui peut collecter des quais au format natif pour Confluence, puis les publier. Confluence dans ce cas est l'un des formats de sortie de la documentation, avec HTML.

Pour que cela fonctionne, vous devez connecter les extensions dans conf.py, voici le fragment de configuration.
extensions = [ 'sphinxcontrib.confluencebuilder', 'm2r' ] templates_path = ['_templates'] source_suffix = ['.rst', '.md'] master_doc = 'index' exclude_patterns = [ u'docs/warning-plate.rst', u'FEATURE.md', u'CHANGELOG.md', u'builder/README.md' ]
Et puis configurez l'extension, elle a un ensemble de paramètres:
confluence_publish = True
Le point important est que même si la page (source en .rst) n'est pas spécifiée en toc et n'est pas ajoutée à exclude_patterns, elle sera toujours publiée, mais en dehors de la hiérarchie.
Les noms des pages dans Confluence correspondront au premier titre de la page, par exemple, si vous avez l'en-tête Exemple dans le fichier example.rst, souligné avec des signes égaux, il deviendra le nom de la page dans Confluence.
La règle d'hygiène, qui est assez évidente, mais quand même: créez un bot avec des données d'autorisation pour lesquelles vous allez publier des documents, ils peuvent être transférés en tant que variables d'environnement dans docker compose, utilisées dans les pipelines.
Bien sûr, il y a des écueils. Premièrement, toutes les syntaxes RST ne sont pas prises en charge pour la publication dans Confluence (╯ ° □ °) ╯︵ ┻━┻), ce qui n'est pas pratique si vous souhaitez collecter HTML et Confluence à partir d'une seule source. Conteneur, les directives hlist ne sont pas prises en charge, presque tous les attributs de directive, par exemple, la mise en évidence des lignes dans le code de bloc, la numérotation dans la table des matières, l'alignement et la largeur de la table de liste.
La liste de ce qui est pris en charge est assez bonne .
Parmi les plus agréables, les inclus sont pris en charge, cela vous permet de réutiliser des fragments de contenu entre différents documents, l'autodoc pour assembler la documentation à partir du code, les mathématiques pour les formules mathématiques, les tickets de dessin et les filtres de jira (pour cela, vous devrez également enregistrer un serveur Jira dans la configuration), des en-têtes numérotés et bien plus un autre, littéralement le 3 janvier, a lancé une
grosse mise à jour .
Soit dit en passant, la prise en charge de Jira est apparue dans le multiconvertisseur Pandoc, à partir de la
version 2.7.3 Pandoc a pris en charge le balisage wiki de confluence correspondant.
Pour les macros et les éléments Confluence qui ne sont pas pris en charge, il existe un hack sale. RST a une directive
... raw :: , et il a un attribut de confluence, il accepte le balisage conf, si vous avez vraiment besoin d'une sorte de macro - vous pouvez le copier en mode d'édition de page dans Confluence (le mode code source est disponible par l'icône <>) et collez-y son code "brut". Mais je ne vous ai pas appris cela.
.. raw:: confluence <ac:structured-macro ac:macro-id="c38bab13-b51e-4129-85ef-737eab8a1c47" ac:name="status" ac:schema-version=^_^quot quot^_^> <ac:parameter ac:name="colour">Green</ac:parameter> <ac:parameter ac:name="title">Is used</ac:parameter> </ac:structured-macro>
Le résultat est le suivant:

Pourquoi avons-nous eu besoin de configurer la publication du référentiel local vers la page de test, et pas immédiatement de "prod"? Le fait est que lorsque vous publiez toutes les pages sont republiées à chaque fois et que vous modifiez les modifications apportées manuellement ou les commentaires dans la ligne (en ligne). Par conséquent, lorsque le document est en cours, nous avons décidé de le publier sur une page distincte, comme le mode dev, afin d'ajouter des versions publiées à la révision et de recueillir des commentaires.
Dans CI, la publication est implémentée en tant qu'étape distincte dans le pipeline Jenkins, à l'intérieur de cette étape, l'image docker est lancée sur le registre distant, qui implémente sphinx-build avec la configuration souhaitée. Il est préférable de sauter immédiatement cette étape.
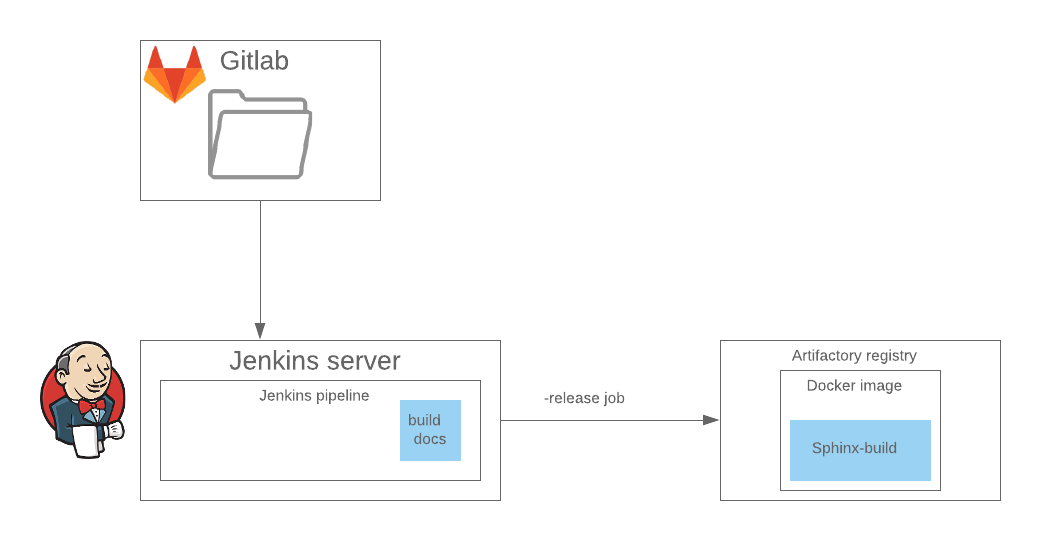
pipeline { agent { label "${AGENT_LABEL}" } stage("Documentation") { steps { ansiColor('xterm') { withCredentials([usernamePassword( credentialsId: "${DOCUMENTATION_BOT}", usernameVariable: 'CONFLUENCE_USERNAME', passwordVariable: 'CONFLUENCE_PASSWORD' )]) { sh "docker-compose -p $COMPOSE_ID run sphinx-doc confluence" } }} }
À l'intérieur de la scène, la
confluence sphinx-doc runer-compose -p release-branch-name run est réellement lancée. Jenkinsfile, à son tour, décrit les dépendances et l'environnement dans lequel l'étape sera effectuée, le processus d'assemblage et de mise à jour des informations dans la cible. À partir des tests jusqu'à présent, il n'y a qu'une vérification de la syntaxe de .md et .rst avec doc8 et markdownlinter.
Autre nuance: chaque fois que vous publiez un sous-réseau de pages, Sphinx met à jour l'arborescence entière, chaque page. Autrement dit, même si le contenu n'a pas changé, un changement est créé, si vous avez des notifications configurées dans le canal, alors il sera obstrué par de nombreuses notifications.
Quelques façons de plus
Foliant avec Confluence comme backend
Outil de documentation Foliant avec Mkdocs et de nombreux préprocesseurs sous le capot et le backend sous forme de Confluence. Vous
pouvez en savoir plus ici , mais en bref, il utilise pandoc pour convertir md en HTML, puis le publie dans Confluence. Il vous suffit de configurer le backend et d'installer pandoc dans l'environnement en tant que dépendance.
Différences favorables par rapport à la première solution: il peut restaurer les commentaires en ligne aux mêmes endroits qu'ils étaient avant la publication de la page, vous permet de créer des pages en les définissant dans la configuration, de modifier leurs noms et également d'insérer du contenu dans une page existante, pour cela, vous devez définir manuellement ancre foliant sur la page en confluence.
Cela ne fonctionne qu'avec la source sur Markdown.
Métro
Un multitool qui publie une grande variété de formats source dans Confluence, de Google Docs à Salesforce Quip, et dans Markdown, aussi.
Pour publier, vous devez placer le fichier manifest.json dans le dossier où se trouvent vos fichiers .md, spécifier le dossier qu'il contient, le fichier que vous souhaitez publier, pour chaque fichier, spécifiez l'ID de la page de confluence. Le titre de la page sera le premier en-tête du fichier (#). Cet outil a quelques perversions avec le balisage Markdown, alors surveillez les
quais . Les pièces jointes et les images doivent être placées dans le même dossier, et l'outil vous permet de spécifier l'utilisation de la table des matières directement dans la configuration.
Gem md2conf
Ruby gem
md2conf , il convertit Markdown en natif pour Confluence XHTML. Ensuite, vous pouvez écrire la tâche Rake, qui à son tour peut être appelée via Gitlab CI / Jenkins pour pousser vers le maître, puis tirer l'API Confluence pour publier la page. Afin de ne pas apporter l'environnement Ruby à lui-même, enveloppez les dépendances de cette gemme dans un conteneur.
La manière d'envoyer des demandes à l'API Confluence est décrite
ici .
Cela ne fonctionne qu'avec la source sur Markdown.
Trouvé sur Github
En fait, un certain nombre de ces scripts ou outils cli ont déjà été réalisés dans la communauté, mais je n'ai expérimenté que md2conf, ils sont tous divisés en deux groupes.
Ceux qui ne font que convertir des formats (md, asciidoc, rst -> confluence / xhtml):Le plus réfléchi d'entre eux que j'ai vu est celui-ci (https://github.com/rogerwelin/markdown2confluence-server), l'auteur a immédiatement écrit Dockerfile, qui lève l'outil cli en tant que serveur REST, vous pouvez alors lui envoyer un paquet de demandes de conversion .
Et ceux qui implémentent immédiatement en eux-mêmes les requêtes à l'API Confluence , il suffit de spécifier la clé API dans la configuration:
Choisissez l'une des options (en fonction de votre langage de balisage et de votre pile) et collectez votre pipeline en fonction des tâches auxquelles vous êtes confronté.
PS Si vous partagez dans les commentaires d'autres solutions trouvées au problème, je vous en serai très reconnaissant.
Et si vous voulez parler plus de ces sujets avec moi, venez à KnowledgeConf 2020 le 18 mai.