gRPC est un framework open source pour l'appel de procédure à distance. Dans Yandex.Market, gRPC est utilisé comme une alternative plus pratique à REST. Sergey Fedoseenkov, qui dirige le service de développement d'outils pour les partenaires du marché, a partagé son expérience de l'utilisation de gRPC comme protocole pour créer des intégrations entre Java et les services C ++. À partir du rapport, vous apprendrez comment éviter les problèmes courants si vous commencez à utiliser gRPC après REST, comment renvoyer les erreurs, implémenter le traçage, déboguer les requêtes et tester les appels des clients.
À la fin, il y a un enregistrement non officiel du rapport.
- Tout d'abord, je voudrais vous présenter quelques faits sur Yandex.Market, ils seront utiles dans le cadre du rapport. Premier fait: nous écrivons des services dans différentes langues. Cela impose aux clients des exigences en matière de services.
Et si nous avons un service en Java, ce serait bien si le client était, par exemple, également un plus ou un petit.

Tous les services que nous avons sont indépendants, il n'y a pas de grandes sorties prévues de l'ensemble du marché. Les microservices seront publiés indépendamment, et la compatibilité descendante est importante pour nous ici, afin que le protocole le prenne en charge.
Le troisième fait: nous avons une intégration synchrone et asynchrone. Dans le rapport, je parlerai principalement de synchrone.
Qu'avons-nous utilisé? Maintenant, bien sûr, la base de nos intégrations est REST ou des services de type REST qui échangent XML / JSON sur HTTP 1.1. Il existe également XML-RPC - nous l'utilisons principalement lors de l'intégration avec du code Python, c'est-à-dire que Python a un serveur XML-RPC intégré. Il est suffisamment pratique pour le déployer là-bas, et nous le soutenons.
Nous avions une fois CORBA. Heureusement, nous l'avons abandonné. Désormais principalement REST et XML / JSON sur HTTP.

Les intégrations synchrones ont des problèmes avec les protocoles existants. Nous rencontrons de tels problèmes et essayons de les traiter avec gRPC. Quels sont ces problèmes? Comme je l'ai dit, je veux avoir des clients dans différentes langues. Il est conseillé de ne pas encore les rédiger par nous-mêmes. Et, en général, ce serait cool si le client pouvait être à la fois synchrone et asynchrone - selon les objectifs de l'utilisateur du service.
Je voudrais également que le protocole que nous utilisons pour prendre en charge la rétrocompatibilité soit assez bien: c'est très important avec les versions indépendantes parallèles. Toutes nos versions sont rétrocompatibles, nous ne cassons pas les commentaires. Si vous l'avez cassé, c'est un bug, et il vous suffit de le corriger le plus tôt possible.
Une approche cohérente de la gestion des erreurs est également nécessaire: tous ceux qui ont créé des services REST savent que vous ne pouvez pas simplement utiliser le statut HTTP. Ils ne permettent généralement pas une description détaillée du problème, vous devez entrer certains de leurs statuts, leurs détails. Dans les services REST, chacun introduit sa propre implémentation de ces erreurs, chaque fois que vous devez travailler différemment avec cela. Ce n'est pas toujours pratique.
J'aimerais également avoir la gestion des délais d'attente côté client. Encore une fois, ceux qui travaillent avec HTTP comprennent que si nous définissons un délai d'expiration côté client et qu'il expire, le client cessera d'attendre la fin de la demande, mais le serveur n'en saura rien et continuera à l'exécuter. De plus, au milieu, il existe plusieurs procurations qui définissent des délais globaux. Et le client peut tout simplement ne rien savoir à leur sujet et les configurer n'est pas toujours trivial.
Et enfin, le problème de la documentation. Il n'est pas toujours clair où obtenir la documentation pour les ressources REST ou pour certaines méthodes, quels paramètres ils acceptent, quel corps peut être transféré et comment communiquer cette documentation avec les consommateurs du service. Il est clair qu'il y a Swagger, mais avec lui aussi, tout n'est pas anodin.
gRPC Théorie
Je voudrais parler de la partie théorique de gRPC - ce que c'est, quelles sont les idées. Et puis nous passerons à la pratique.

En général, gRPC est une spécification abstraite. Il décrit un RPC abstrait (appel de procédure distante), c'est-à-dire un appel de procédure distante qui possède certaines propriétés. Nous allons maintenant les énumérer. La première propriété est la prise en charge des appels uniques et du streaming. Autrement dit, tous les services qui implémentent cette spécification prennent en charge les deux options. L'élément suivant est la disponibilité des métadonnées, c'est-à-dire que, avec la charge utile, vous pouvez transmettre une sorte de métadonnées - conditionnellement, les en-têtes. Et - prise en charge de l'annulation d'une demande et des délais d'attente hors de la boîte.
Il suppose également que la description des messages et des services eux-mêmes est effectuée via un certain langage de définition d'interface ou IDL. La spécification décrit également le protocole filaire sur HTTP / 2, c'est-à-dire que gRPC suppose qu'il ne fonctionne que sur HTTP / 2.

Il existe une implémentation gRPC typique qui est utilisée dans la plupart des cas. Nous l'utilisons également, et maintenant nous le verrons. Le format proto est utilisé comme IDL. Le plugin gRPC pour le compilateur proto vous permet d'obtenir les sources des services générés à partir de la description proto. Et il existe des bibliothèques d'exécution dans différents langages - Java, C ++, Python. En général, presque toutes les langues populaires sont prises en charge, des bibliothèques d'exécution existent pour elles. Et comme les messages échangés entre les services, un message proto est utilisé, des messages stylisés selon le schéma protobuf.

Je veux plonger un peu dans certaines fonctionnalités spécifiques. Les voici. Un typage fort, c'est-à-dire un message proto, est un message fortement typé. Ceux qui ont déjà travaillé avec protobuf savent que vous pouvez décrire les champs de votre message avec des types. Les types existent à la fois des tableaux d'octets primitifs et de chaîne. Ils peuvent être scalaires, vectoriels. Et, en fait, les messages peuvent, en tant que champ, contenir d'autres messages, ce qui est assez pratique, en général, n'importe quel modèle peut être représenté.

À propos de la compatibilité descendante. Je voudrais noter que proto IDL est un format dans lequel la compatibilité descendante est mise en place, c'est-à-dire qu'il a été conçu avec un arriéré de compatibilité descendante, et Google a publié une version de proto3, qui, par rapport à proto2, améliore encore plus la compatibilité descendante. Là, en plus, il y a toutes sortes de spécifications, comment et ce qui peut être changé pour que la compatibilité ascendante soit préservée dans certains cas non triviaux.
Il existe une possibilité de valeurs par défaut, vous pouvez ajouter de nouveaux champs et le consommateur n'a en fait rien à changer. Tous les champs de proto3 sont facultatifs et, par exemple, peuvent être supprimés, et l'accès au champ distant ne provoque pas d'erreurs sur le client.

Une autre fonctionnalité gRPC est que le client et le serveur sont générés à l'aide du compilateur proto et du plugin gRPC basé sur la description proto. Il est possible au moment de l'écriture du code de choisir le client à utiliser. Autrement dit, choisissez un client asynchrone ou synchrone, selon le type de code que vous écrivez. Par exemple, un client asynchrone convient très bien au code réactif. Et cette opportunité est pour n'importe quelle langue. Autrement dit, une fois que vous écrivez une proto-description, après cela, vous pouvez générer un client pour n'importe quelle langue, et vous n'avez pas besoin de les développer séparément d'une manière ou d'une autre. Vous pouvez distribuer l'interface de votre service simplement comme une proto-description. Tout consommateur peut générer un client pour lui-même.

Concernant l'annulation de la demande et les délais, je voudrais noter que la demande peut être annulée sur le serveur et sur le client. Si nous comprenons que tout, nous n'avons plus besoin de répondre à la demande, nous pouvons l'annuler. Il est possible de définir un délai d'attente sur demande. Dans gRPC, la plupart des bibliothèques d'exécution utilisent un délai comme concept de délai d'expiration. Mais en fait c'est la même chose. Autrement dit, c'est le moment où la demande doit se terminer.
Et la chose la plus intéressante est que le serveur peut se renseigner à la fois sur l'annulation de la demande et sur l'expiration du délai d'attente et arrêter d'exécuter la demande de son côté. C'est très cool, il me semble qu'il n'y a pas grand-chose ailleurs.
Concernant la documentation, je voulais noter que puisque le format proto est utilisé dans l'IDL pour gRPC, c'est du code normal. Vous pouvez y rédiger des commentaires, y compris des commentaires très détaillés. Et vous devez comprendre que pour s'intégrer à votre service, vos utilisateurs doivent avoir ce proto-format chez eux, et il les recevra avec des commentaires, ils ne mentiront pas ailleurs. C'est très pratique. Et vous pouvez développer cette description, c'est-à-dire que c'est une fonctionnalité si pratique que la documentation va à côté du code, tout comme elle peut se trouver à côté des méthodes sous la forme de javadoc ou de tout autre commentaire.
Appel unaire gRPC. Pratique
Passons à autre chose, regardons un peu de pratique. Et l'exemple le plus élémentaire de l'utilisation de gRPC est le soi-disant appel unaire, ou appel unique. Il s'agit d'un schéma classique - nous envoyons une demande au serveur et obtenons une réponse du serveur. Il semble que cela fonctionne en HTTP.

Prenons l'exemple du service d'écho que nous faisons. Le serveur sera écrit en plus, le client en Java. Le circuit d'équilibrage classique a été utilisé ici. Autrement dit, le client adresse l'équilibreur, puis l'équilibreur sélectionne déjà un backend spécifique pour traiter la demande.
Je voulais faire attention - puisque gRPC fonctionne sur HTTP / 2, une connexion TCP est utilisée. Et en outre, divers flux la traversent. Ici, vous pouvez voir que la connexion entre le client et l'équilibreur est établie une fois et reste persistante, puis l'équilibreur équilibre la charge sur différents backends pour chaque appel. Si vous regardez, ça se passe comme ça et comme ça si les messages sont distribués.

Voici un exemple de code pour notre fichier proto. Vous pouvez remarquer que nous décrivons d'abord le message, c'est-à-dire que nous avons EchoRequest et EchoResponse. Il n'a qu'un seul champ de chaîne qui stocke le message.
La deuxième étape, nous décrivons notre procédure. La procédure d'entrée accepte EchoRequest, renvoie EchoResponse comme résultat, tout est assez trivial. Il s'agit de la description du service gRPC et des messages qui seront poursuivis.

Voyons comment cela se passe dans le cas des avantages, par exemple. Il est assemblé en trois étapes. Dans un premier temps, notre tâche est de générer des sources de messages. Ici, nous le faisons avec cette équipe. Nous appelons le compilateur de proto, passons le proto-fichier à l'entrée, indiquons où placer les fichiers de sortie.
La deuxième équipe. Nous générons également des services de la même manière. La seule différence avec la commande précédente est que nous passons le plugin, et sur la base de la description, qui est au format proto, il génère des services.
La troisième étape - nous collectons tout cela en un seul binaire afin que notre serveur puisse être lancé.
Un indicateur supplémentaire est passé à l'éditeur de liens, il est appelé réflexion grpc ++ _. Je veux noter - le serveur gRPC a une telle fonctionnalité, la réflexion du serveur. Il vous permet d'explorer le type de services, d'appels RPC et de messages du service. Par défaut, il est désactivé et vous ne pouvez accéder au service que si vous disposez d'un proto-format. Mais, par exemple, pour le débogage, c'est très pratique, sans le proto-format à portée de main, allumez simplement le serveur avec la fonction de réflexion et recevez immédiatement les informations.
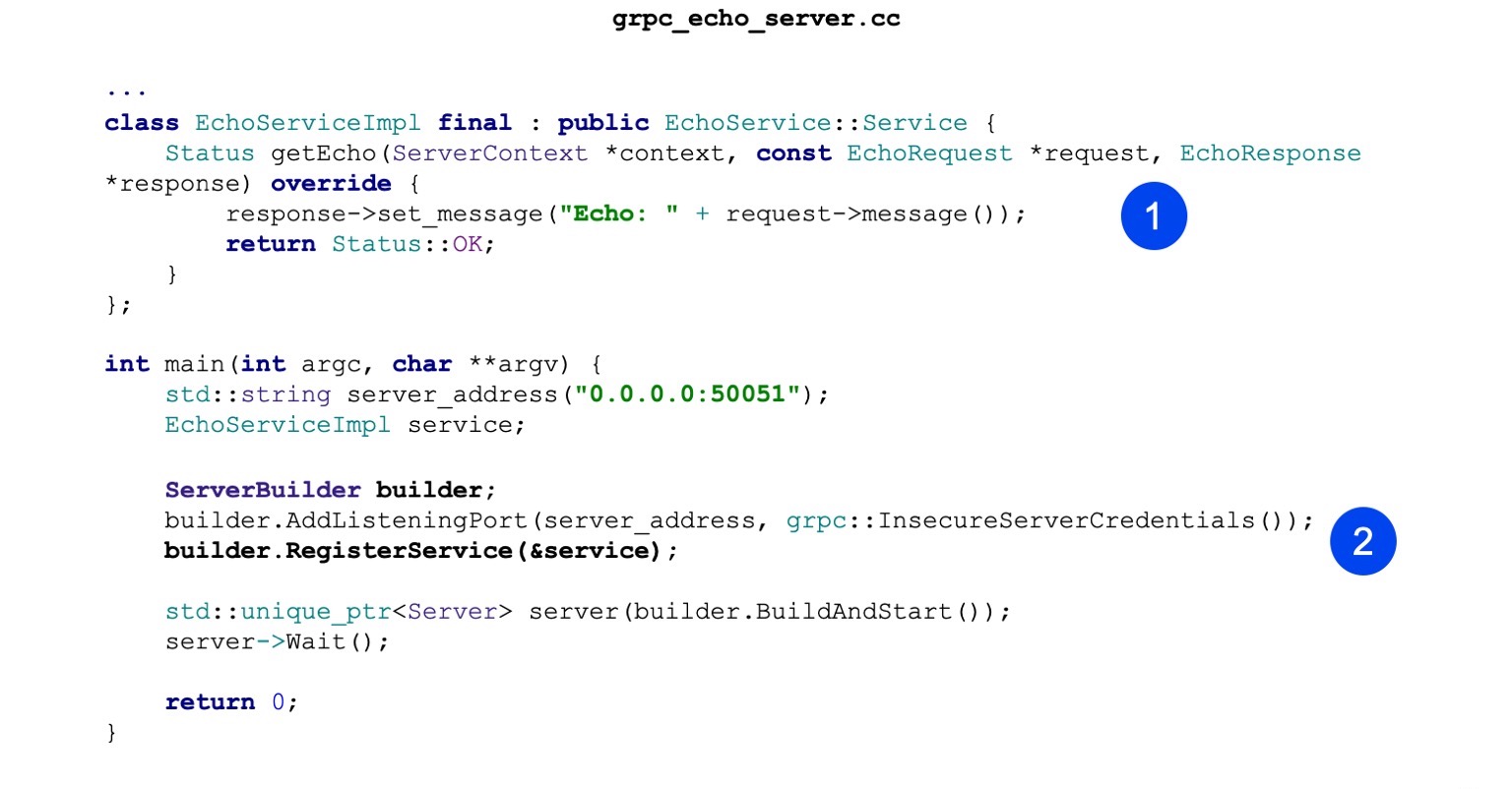
Voyons maintenant l'implémentation. La mise en œuvre est également minimaliste. Autrement dit, notre tâche principale est de mettre en œuvre le service d'écho généré. Il a une méthode getEcho. Il génère simplement des messages et les renvoie. État OK - état de réussite.
Ensuite, nous créons ServerBuilder, y enregistrons notre service, que nous avons construit un peu plus haut.

Maintenant, nous commençons et attendons les demandes entrantes.

Voyons maintenant le client en Java. Nous collectons gradle. Notre tâche consiste à connecter le plugin protobuf en premier.
Il existe un ensemble de dépendances de base que nous devons faire glisser pour notre service, elles sont nécessaires au stade de la compilation.
Je tiens également à noter qu'il existe une bibliothèque d'exécution. Pour Java, il utilise netty comme serveur et client, il prend en charge HTTP / 2, il est assez pratique et performant.
Ensuite, nous configurons le compilateur de prototypes. Le compilateur lui-même n'a pas besoin d'être installé localement pour Java; il peut être extrait d'artefacts.
Même chose avec les plugins. Localement pour Java, ce n'est pas nécessaire. Vous pouvez faire glisser un artefact. Et il est important de simplement le configurer de sorte que pour tous les shuffles, il soit également appelé, afin que les stubs soient générés.
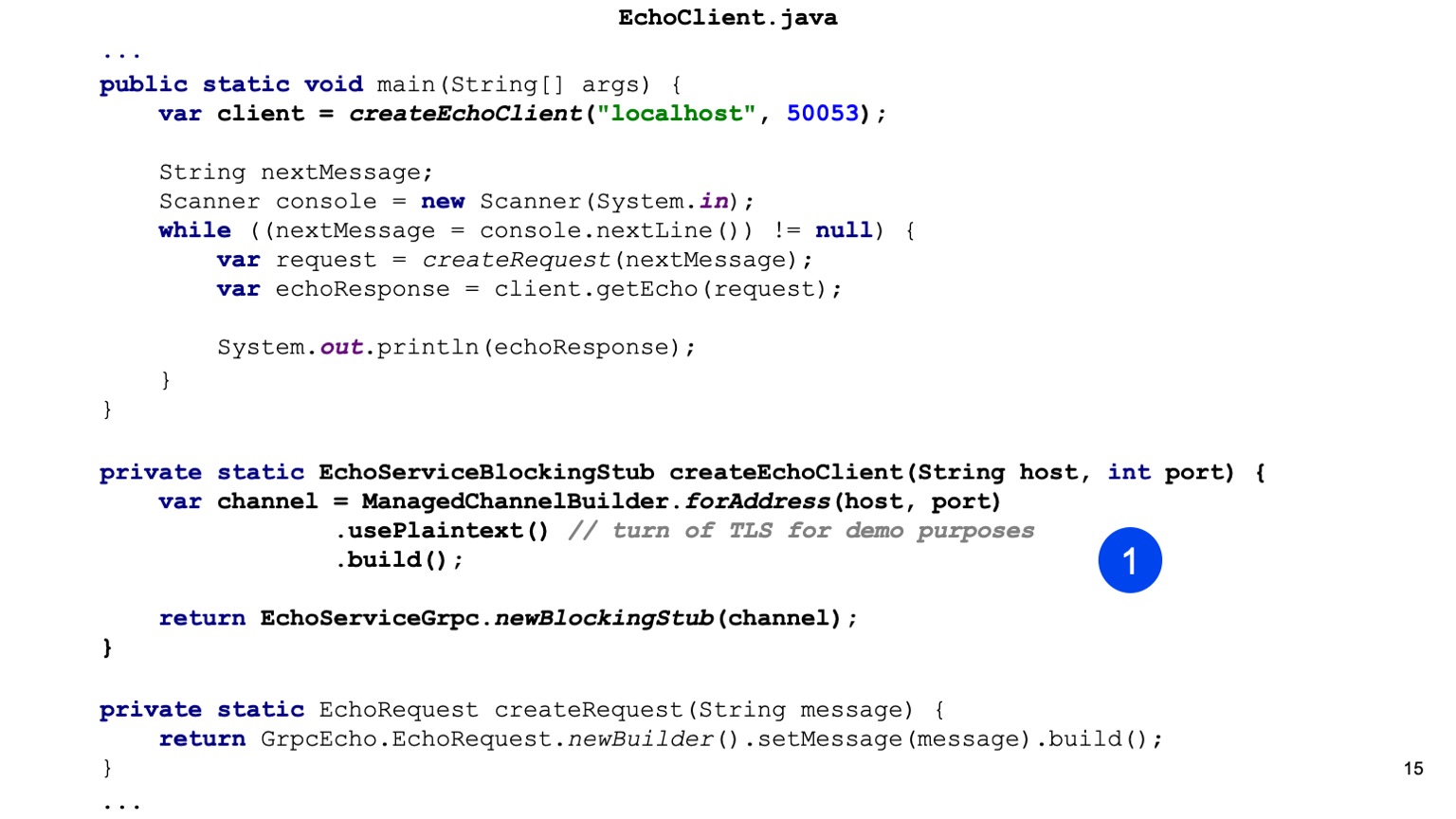
Passons au code Java. Ici, nous sommes les premiers à créer le talon de notre service. C'est notre tâche pour Java de fournir Channel. Il y a un ChannelBuilder dans la bibliothèque d'exécution avec lequel nous pouvons construire ce canal. Ici, nous avons activé manuellement le texte brut pour plus de simplicité, mais HTTP2 et gRPC chiffrent tout par défaut et utilisent TLS.
Nous avons un talon de notre client, un client synchrone est généré ici. De la même manière, vous pouvez générer un client asynchrone, il existe d'autres options.
Ensuite, nous créons notre requête protobuff, c'est-à-dire que nous construisons un message protobuff.
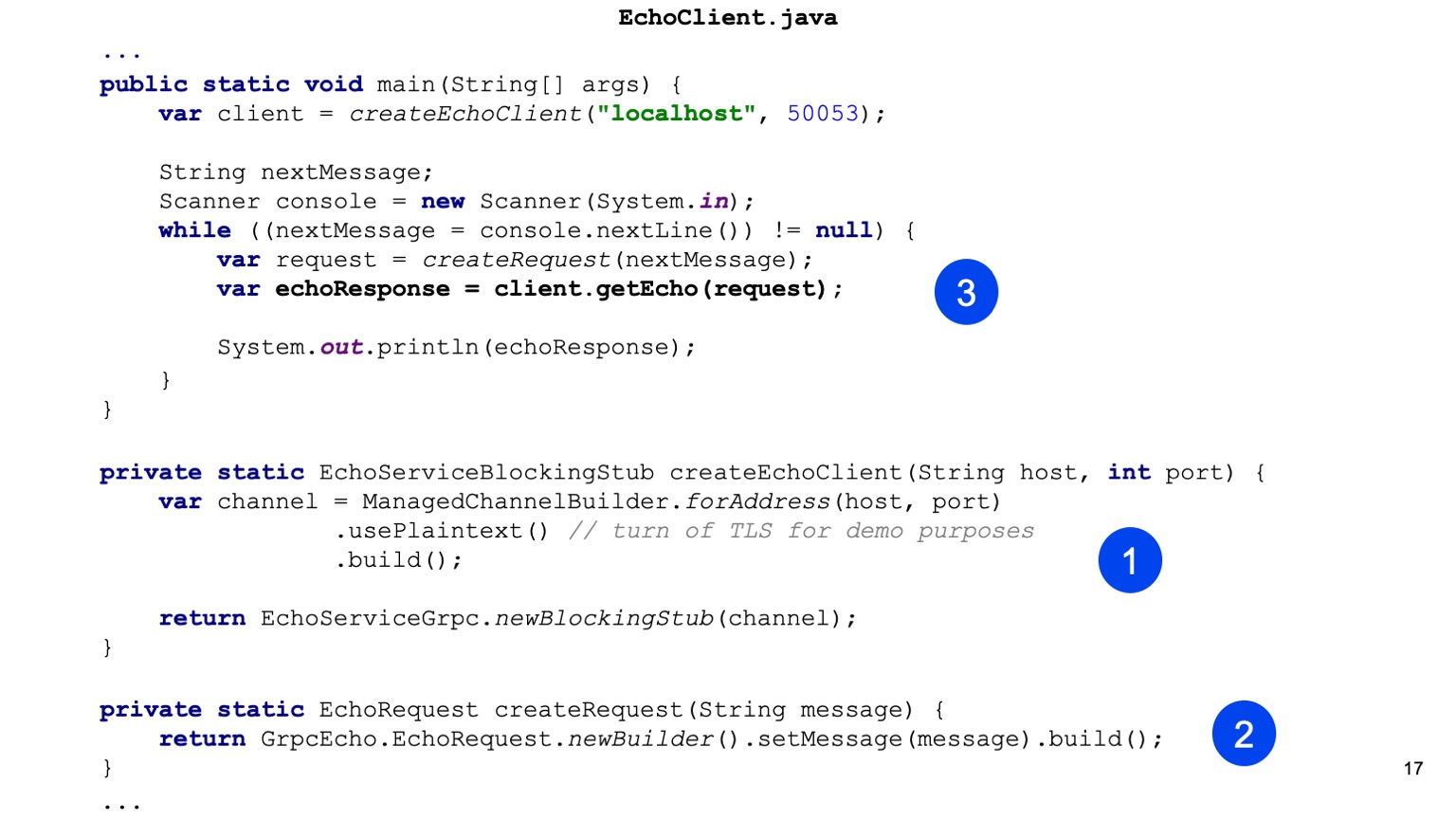
C'est tout, envoyez-le, sur notre client, nous appelons getEcho et imprimons le résultat. Tout est simple. Comme vous pouvez le voir, un peu de code est nécessaire et l'intégration est construite.
Streaming gRPC. Pratique
Voyons maintenant une chose plus avancée, c'est le streaming. Je vais vous expliquer comment cela fonctionne et plus tard, je vais vous expliquer comment l'utiliser.

Le client-serveur en streaming a une architecture similaire. Autrement dit, nous avons une connexion persistante entre le client et l'équilibreur. Alors les différences commencent. L'essence du streaming est que le client est attaché à un backend final et que la connexion est enregistrée. Autrement dit, cela continue comme ça. Et ainsi. Ici, je voudrais noter séparément que l'utilisation d'un équilibreur n'est pas typique pour le streaming, c'est-à-dire que vous devez comprendre que les requêtes de streaming peuvent être assez longues. Autrement dit, vous pouvez les ouvrir et échanger des messages pendant longtemps. Et ces messages passeront par l'équilibreur, mais, en fait, iront toujours au même backend. Et on ne sait pas très bien pourquoi cela est nécessaire.
Une pratique courante est lorsqu'un service, par exemple, est purement en streaming, ou principalement en streaming, alors la découverte de service est utilisée. GRPC a un point d'extension où la découverte de service peut être intégrée.

De quoi avons-nous besoin pour mettre en œuvre des services de streaming? Nous avons le même format de proto. Nous ajoutons un autre RPC, et ici vous pouvez remarquer que nous avons ajouté deux mots clés avant la demande et avant la réponse. Ainsi, nous déclarons les flux EchoRequest et EchoResponse.

Le plus intéressant commence. Notre compilation ne change en aucune façon pour que les services de streaming puissent le faire. Notre prochaine tâche consiste à remplacer notre nouvelle méthode dans notre service Echo, qui fonctionnera avec les flux. Dans le cas du serveur, tout cela est un peu plus facile. Autrement dit, nous pouvons constamment lire dans le flux et répondre à quelque chose. Nous pouvons répondre de manière asynchrone. Autrement dit, ils sont indépendants, stream pour écrire et stream pour lire, et ici tout est simple pour un scénario simple.

Voici la lecture maintenant, voici l'enregistrement.

Dans les clients Java, les choses sont un peu plus compliquées. Là, vous ne pouvez pas utiliser d'API synchrone, c'est-à-dire qu'elle ne fonctionne tout simplement pas avec les flux. Et là, l'API asynchrone est utilisée. Autrement dit, notre tâche consiste à implémenter le modèle Observer. Il y a une interface StreamObserver là-bas. Il contient trois méthodes: onNext, onCompleted et onError. Ici, pour plus de simplicité, j'ai implémenté uniquement onNext. Il ne tremble que lorsque la réponse nous vient du serveur.

Ici, je viens de mettre dans une file d'attente pour la messagerie entre les threads.

Quelle est la différence? Au lieu de blockingStub, nous créons simplement newStub. Il s'agit d'une implémentation asynchrone qui peut fonctionner uniquement avec Observer. En fait, vous pouvez faire des appels unaires sur Observer, mais pas si pratique. Nous, au moins, nous l'utilisons moins activement.
Ensuite, nous construisons notre Observateur.
Et nous faisons notre appel RPC. Nous passons ResponseObserver à l'entrée et à la sortie, il nous envoie RequestObserver. De plus, nous pouvons effectuer des appels sur RequestObserver, transmettant ainsi des messages au serveur. Et notre ResponseObserver va contracter et traiter les messages.
Voici un exemple. Nous faisons juste un appel. Appelez ensuite, passez la demande là-bas.
Plus loin de la file d'attente, nous attendons que le serveur réponde et s'imprime.

Je veux attirer l'attention sur le fait que notre tâche ici, en tant que personnes responsables de la mise en œuvre du streaming, est de gérer correctement la fermeture de ce RequestObserver. Autrement dit, en cas d'erreur, nous devons y appeler la méthode onError, et en cas de réussite, lorsque nous pensons que le flux peut être fermé, nous devons appeler la méthode onCompleted.

Nous continuons. Quelles sont les applications de streaming? C'est une chose plus avancée, pas le fait qu'elle soit directement utile à tout le monde, mais est parfois utilisée. Autrement dit, la première consiste à télécharger et à télécharger de grandes quantités de données. Le serveur ou le client peut produire des données dans certaines parties. Ces portions peuvent déjà en quelque sorte être regroupées sur le client ou sur le serveur. Autrement dit, vous pouvez déjà effectuer des optimisations supplémentaires ici.
En outre, le schéma de streaming est bien adapté pour la poussée du serveur. Vous devez comprendre que j'ai considéré l'option la plus extrême lorsque nous avons un streaming bidirectionnel. Et peut-être en streaming dans une seule direction. Par exemple, du client au serveur ou du serveur au client. Dans le cas d'un serveur à un client, nous pouvons nous connecter à un serveur, et il nous enverra des pushies, et pour cela, nous n'aurons pas besoin d'interroger régulièrement.
Le prochain avantage du streaming est lié à une seule machine. Comme je l'ai déjà dit, une connexion de bout en bout sera établie pour tous les messages à l'intérieur du flux, et cette connexion sera liée à une machine, et elle ne basculera certainement nulle part. Par conséquent, il est possible, premièrement, de simplifier quelque chose, une sorte de synchronisation interserveur, et en plus, vous pouvez faire des choses transactionnelles.
Et le streaming bidirectionnel, juste un exemple que j'ai montré, est la possibilité de créer certains de mes propres protocoles. Chose assez intéressante. Nous avons des files d'attente internes dans Yandex qui utilisent simplement le streaming bidirectionnel. Et si soudain quelqu'un a de telles tâches, alors une bonne occasion de l'utiliser.
Je veux aussi faire attention, j'ai parlé des métadonnées plus tôt. . . , - , , . . gRPC .
, gRPC.

, . - . gRPC . , , , , , . , runtime- . , . , OK, runtime- .
, Java . . google.rpc.Status 3 : , . , . , . — , , .
error details, , . : , , , stack traces, . , .
— , HTTP , ? . BadRequest . , , error details, .
. , , BadRequest - ( ), - error detail. , , , - . , .

. . , , , . - - , - - , , . . , , Zipkin. , HTTP , — metadata. .
, . , - , , , .
runtime-, - , . Java ClientInterceptor ServerInterceptor. , , . , , , , , - . , - API - . , , , , - . , gRPC, , - . , , - , , , .

- . -. Java . , , - . - , .

. gRPC — . HTTP/2 . - , ? : , . . , gRPC grpc_cli, curl. , . , -, . , gRPC , .
, evans. , CLI: , , , . , . - , , , , , .
- UI — , Postman, — BloomRPC. Postman . Postman, , , . , BloomRPC , .
- , . , , grpc_cli. . , . , , . , . , - - . — .

, , gRPC. . - , - , . Swagger. , HTTP/1 . OpenAPI , . . , HTTP/2, Swagger — .
WSDL — , . . Swagger, , . . -.
, , , , JAX-RS, Java . .
Twirp. Qu'est ce que c'est Go, . . , , Go , gRPC Twirp. ? , gRPC — , , , IDL . proto- , gRPC-. protoc, , .
Twirp . proto- , HTTP/1.1 , JSON. , Twirp Go. , , Java Jetty. , .

? gRPC — REST . , , , , HTTP/2 balancer. service discovery, . gRPC , . .
gRPC — , . CLI, UI. , .
, gRPC. inter-process-. , sidecar pattern. , . , . , -. - , , -. . , , , , - .
, . gRPC . , . , unary-. , .
:
—
C gRPC — , . , , , .
—
Awesome gRPC — GitHub . , , , . . — , .
Vous pouvez trouver de nombreuses autres ressources sur Internet, sur quelques diapositives. Mais c'est ce que j'ai le plus aimé. Le code légèrement modifié de la présentation est ici . Je vous remercie!
Enregistrement de rapport informel