Salut, Khabrovsk. Comme nous l'avons déjà écrit, janvier est riche en nouveaux lancements et aujourd'hui nous annonçons un ensemble pour un nouveau cours d'OTUS - "Game Developer for Unity" . En prévision du début du cours, nous partageons avec vous la traduction de matériel intéressant.

Nous reconstruisons le noyau Unity avec notre pile technologique orientée données . Comme de nombreux studios de jeux, nous voyons également de grands avantages à utiliser l'Entity Component System (ECS), le système de tâches C # (C # Job System) et Burst Compiler. À Unite Copenhagen, nous avons eu l'occasion de discuter avec Far North Entertainment et de découvrir comment ils implémentent cette fonctionnalité DOTS dans les projets Unity traditionnels.
Far North Entertainment est un studio suédois appartenant à cinq amis ingénieurs. Depuis la sortie de Down to Dungeon pour Gear VR au début de 2018, la société travaille sur un jeu qui appartient au genre classique des jeux PC, à savoir un jeu post-apocalyptique en mode de survie zombie. Ce qui distingue le projet des autres, c'est le nombre de zombies qui vous poursuivent. La vision de l'équipe à cet égard a attiré des milliers de zombies affamés vous suivant dans d'énormes hordes.
Cependant, ils ont rapidement rencontré de nombreux problèmes de performances au stade du prototypage. La création, la mort, le renouvellement et l'animation de tout ce nombre d'ennemis sont restés le principal goulot d'étranglement, même après que l'équipe ait essayé de résoudre le problème avec la
mise en commun oblique et une
instanciation de nimation .
Cela a forcé le directeur technique du studio Andres Ericsson à tourner son attention vers DOTS et à changer l'état d'esprit orienté objet vers orienté données. "L'idée clé qui a contribué à provoquer ce changement était que vous deviez arrêter de penser aux objets et aux hiérarchies d'objets et commencer à penser aux données, comment elles sont transformées et comment y accéder", at-il déclaré. . Ses mots signifient qu'il n'est pas nécessaire de construire une architecture de code avec un œil sur les objets de la vie réelle de telle manière qu'elle résout le problème le plus général et abstrait. Il a de nombreux conseils pour ceux qui, comme lui, sont confrontés à un changement de vision du monde:
«Demandez-vous quel est le véritable problème que vous essayez de résoudre et quelles données sont importantes pour obtenir une solution. Allez-vous convertir le même ensemble de données de la même manière encore et encore? Combien de données utiles pouvez-vous tenir dans une ligne du cache du processeur? Si vous apportez des modifications au code existant, évaluez la quantité de données indésirables que vous ajoutez à la ligne de cache. Est-il possible de diviser les calculs en plusieurs threads ou dois-je utiliser un seul flux de commandes? "L'équipe a compris que les entités du système de composants Unity ne sont que des identifiants de recherche dans les flux de composants. Les composants ne sont que des données, tandis que les systèmes contiennent toute la logique et filtrent les entités avec une signature spécifique, appelées archétypes. «Je pense que l'une des informations qui nous a aidés à visualiser nos idées a été d'introduire ECS en tant que base de données SQL. Chaque archétype est une table dans laquelle chaque colonne est un composant et chaque ligne est une entité unique. En gros, vous utilisez des systèmes pour créer des requêtes pour ces tables d'archétype et effectuer des opérations sur des entités », explique Anders.
Présentation de DOTS
Pour arriver à cette compréhension, il a étudié la documentation du système
Entity Component , des exemples
ECS et
un exemple que nous avons fait avec Nordeus et présenté à Unite Austin. Des informations générales sur l'architecture orientée données ont également été très utiles à l'équipe. «Le rapport de
Mike Acton sur l'architecture orientée données avec CppCon 2014 est exactement ce qui nous a ouvert les yeux sur ce mode de programmation.»
L'équipe de Far North a publié ce qu'elle a appris sur son
blog Dev , en septembre de cette année, elle est venue à Copenhague pour parler de ses expériences avec la transition vers une approche orientée données dans Unity.
Cet article est basé sur un rapport, il explique plus en détail les spécificités de leur implémentation d'ECS, du système de tâches C # et du compilateur Burst. Far North a également aimablement partagé de nombreux exemples de code de leur projet.
Organisation des données Zombie
«Le problème auquel nous étions confrontés était d'interpoler les déplacements et les rotations de milliers d'objets côté client», explique Anders. Leur approche initiale orientée objet consistait à créer un script
ZombieView abstrait qui héritait de la classe parent
EntityView générique.
EntityView est un
MonoBehaviour attaché à un
GameObject . Il agit comme une représentation visuelle du modèle de jeu. Chaque
ZombieView était responsable de gérer sa propre interpolation de mouvement et de rotation dans sa fonction de
mise à jour .
Cela semble normal, jusqu'à ce que vous compreniez que chaque entité se trouve en mémoire dans un endroit arbitraire. Cela signifie que si vous accédez à des milliers d'objets, le processeur doit les retirer de la mémoire un par un, et cela se produit extrêmement lentement. Si vous placez vos données dans des blocs ordonnés disposés en série, le processeur peut mettre en cache tout un tas de données en même temps. La plupart des processeurs modernes peuvent recevoir environ 128 ou 256 bits du cache en un cycle.
L'équipe a décidé de convertir les ennemis en DOTS dans l'espoir de résoudre les problèmes de performances côté client. Le premier en ligne était la fonction de
mise à jour dans
ZombieView . L'équipe a déterminé quelles parties devaient être divisées en différents systèmes et déterminé les données nécessaires. La première chose et la plus évidente était l'interpolation des positions et des virages, car le monde du jeu est une grille à deux dimensions. Deux variables flottantes sont responsables de l'endroit où les zombies vont, et le dernier composant est la position cible, il suit la position du serveur pour l'ennemi.
[Serializable] public struct PositionData2D : IComponentData { public float2 Position; } [Serializable] public struct HeadingData2D : IComponentData { public float2 Heading; } [Serializable] public struct TargetPositionData : IComponentData { public float2 TargetPosition; }
L'étape suivante consistait à créer un archétype pour les ennemis. L'archétype est un ensemble de composants qui appartiennent à une certaine entité, en d'autres termes, c'est la signature du composant.
Le projet utilise des préfabriqués pour déterminer les archétypes, car les ennemis nécessitent plus de composants, et certains d'entre eux ont besoin de liens vers
GameObject . Cela fonctionne de sorte que vous puissiez envelopper les données de votre composant dans
ComponentDataProxy , qui le transformera en
MonoBehaviour , qui à son tour peut être attaché au préfabriqué. Lorsque vous créez une instance à l'aide d'
EntityManager et passez le préfabriqué, il crée une entité avec toutes les données des composants qui ont été attachés au préfabriqué. Toutes les données des composants sont stockées dans des blocs de mémoire de 16 kilo-octets appelés
ArchetypeChunk .
Voici une visualisation de la façon dont les flux de composants seront organisés dans notre bloc d'archétype:
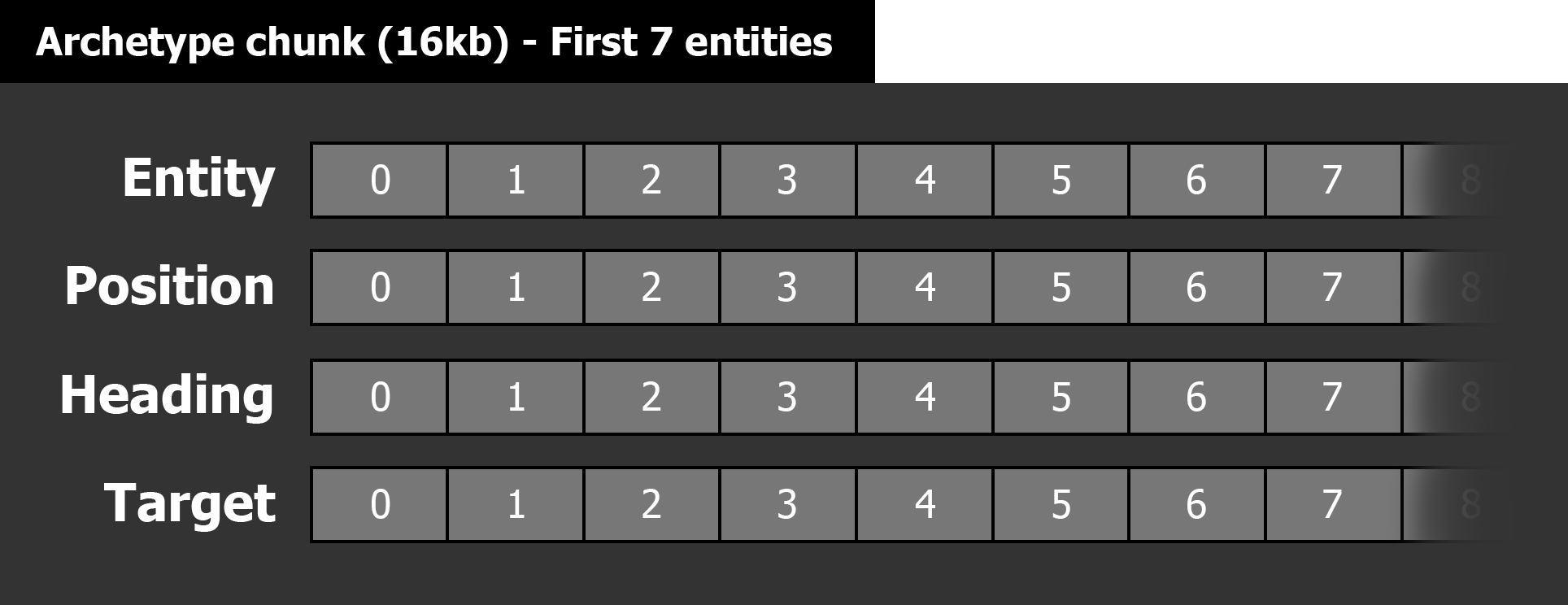 «L'un des principaux avantages des blocs d'archétype est que vous n'avez pas souvent besoin de réaffecter un groupe lors de la création de nouveaux objets, car la mémoire a déjà été allouée à l'avance. Cela signifie que la création d'entités consiste à écrire des données à la fin des flux de composants à l'intérieur de blocs d'archétype. Le seul cas où il est nécessaire d'effectuer à nouveau l'allocation de segments est lors de la création d'une entité qui ne rentre pas dans les bordures du bloc. Dans ce cas, soit l'allocation d'un nouveau morceau d'un archétype de 16 Ko sera lancée, soit s'il existe un fragment vide du même archétype, il peut être réutilisé. Ensuite, les données des nouveaux objets seront enregistrées dans les flux de composants du nouveau morceau »,
«L'un des principaux avantages des blocs d'archétype est que vous n'avez pas souvent besoin de réaffecter un groupe lors de la création de nouveaux objets, car la mémoire a déjà été allouée à l'avance. Cela signifie que la création d'entités consiste à écrire des données à la fin des flux de composants à l'intérieur de blocs d'archétype. Le seul cas où il est nécessaire d'effectuer à nouveau l'allocation de segments est lors de la création d'une entité qui ne rentre pas dans les bordures du bloc. Dans ce cas, soit l'allocation d'un nouveau morceau d'un archétype de 16 Ko sera lancée, soit s'il existe un fragment vide du même archétype, il peut être réutilisé. Ensuite, les données des nouveaux objets seront enregistrées dans les flux de composants du nouveau morceau », explique Anders.
Le multithreading de vos zombies
Maintenant que les données étaient densément compressées et placées en mémoire de manière pratique pour la mise en cache, l'équipe pouvait facilement utiliser le système de tâches C # pour exécuter son code sur plusieurs cœurs de processeur en parallèle.
L'étape suivante consistait à créer un système qui filtrait toutes les entités de tous les blocs d'archétype
contenant des composants PositionData2D ,
HeadingData2D et
TargetPositionData .
Pour ce faire, Anders et son équipe ont créé
JobComponentSystem et construit leur demande dans la fonction
OnCreate . Cela ressemble à ceci:
private EntityQuery m_Group; protected override void OnCreate() { base.OnCreate(); var query = new EntityQueryDesc { All = new [] { ComponentType.ReadWrite<PositionData2D>(), ComponentType.ReadWrite<HeadingData2D>(), ComponentType.ReadOnly<TargetPositionData>() }, }; m_Group = GetEntityQuery(query); }
Le code annonce une demande qui filtre tous les objets du monde qui ont une position, une direction et un but. Ensuite, ils voulaient planifier des tâches pour chaque trame à l'aide du système de tâches C # pour distribuer les calculs sur plusieurs workflows.
"La chose la plus intéressante à propos du système de tâches C # est qu'il s'agit du même système que Unity utilise dans son code, nous n'avons donc pas eu à nous soucier que les threads exécutables se bloquent les uns les autres, nécessitant les mêmes cœurs de processeur et provoquant des problèmes de performances. ", Dit Anders.
L'équipe a décidé d'utiliser
IJobChunk , car des milliers d'ennemis impliquaient la présence d'un grand nombre de morceaux d'archétype qui devraient correspondre à la demande au moment de l'exécution.
IJobChunk distribue les bons morceaux sur différents workflows.
Chaque image, une nouvelle tâche
UpdatePositionAndHeadingJob, est chargée de gérer l'interpolation des positions et des tours des ennemis dans le jeu.
Le code de planification des tâches est le suivant:
protected override JobHandle OnUpdate(JobHandle inputDeps) { var positionDataType = GetArchetypeChunkComponentType<PositionData2D>(); var headingDataType = GetArchetypeChunkComponentType<HeadingData2D>(); var targetPositionDataType = GetArchetypeChunkComponentType<TargetPositionData>(true); var updatePosAndHeadingJob = new UpdatePositionAndHeadingJob { PositionDataType = positionDataType, HeadingDataType = headingDataType, TargetPositionDataType = targetPositionDataType, DeltaTime = Time.deltaTime, RotationLerpSpeed = 2.0f, MovementLerpSpeed = 4.0f, }; return updatePosAndHeadingJob.Schedule(m_Group, inputDeps); }
Voici à quoi ressemble la tâche:
public struct UpdatePositionAndHeadingJob : IJobChunk { public ArchetypeChunkComponentType<PositionData2D> PositionDataType; public ArchetypeChunkComponentType<HeadingData2D> HeadingDataType; [ReadOnly] public ArchetypeChunkComponentType<TargetPositionData> TargetPositionDataType; [ReadOnly] public float DeltaTime; [ReadOnly] public float RotationLerpSpeed; [ReadOnly] public float MovementLerpSpeed; }
Lorsqu'un thread de travail récupère une tâche de sa file d'attente, il appelle le cœur de la tâche.
Voici à quoi ressemble le noyau d'exécution:
public void Execute(ArchetypeChunk chunk, int chunkIndex, int firstEntityIndex) { var chunkPositionData = chunk.GetNativeArray(PositionDataType); var chunkHeadingData = chunk.GetNativeArray(HeadingDataType); var chunkTargetPositionData = chunk.GetNativeArray(TargetPositionDataType); for (int i = 0; i < chunk.Count; i++) { var target = chunkTargetPositionData[i]; var positionData = chunkPositionData[i]; var headingData = chunkHeadingData[i]; float2 toTarget = target.TargetPosition - positionData.Position; float distance = math.length(toTarget); headingData.Heading = math.select( headingData.Heading, math.lerp(headingData.Heading, math.normalize(toTarget), math.mul(DeltaTime, RotationLerpSpeed)), distance > 0.008 ); positionData.Position = math.select( target.TargetPosition, math.lerp( positionData.Position, target.TargetPosition, math.mul(DeltaTime, MovementLerpSpeed)), distance <= 1 ); chunkPositionData[i] = positionData; chunkHeadingData[i] = headingData; } }
«Vous remarquerez peut-être que nous utilisons select au lieu de branchement, cela nous permet de nous débarrasser de l'effet appelé prédiction de branchement incorrecte. La fonction select évaluera les deux expressions et sélectionnera celle qui correspond à la condition, et si vos expressions ne sont pas si difficiles à calculer, je recommanderais d'utiliser select, car c'est souvent moins cher que d'attendre que le CPU se rétablisse d'une prédiction de branche incorrecte. " Anders.
Augmentez la productivité avec Burst
La dernière étape de la conversion de DOTS en position ennemie et interpolation de cap consiste à activer le compilateur Burst. La tâche semblait assez simple pour Anders: «Puisque les données sont situées dans des tableaux adjacents et que nous utilisons la nouvelle bibliothèque de mathématiques d'Unity, tout ce que nous avions à faire était d'ajouter l'attribut
BurstCompile à notre tâche.»
[BurstCompile] public struct UpdatePositionAndHeadingJob : IJobChunk { public ArchetypeChunkComponentType<PositionData2D> PositionDataType; public ArchetypeChunkComponentType<HeadingData2D> HeadingDataType; [ReadOnly] public ArchetypeChunkComponentType<TargetPositionData> TargetPositionDataType; [ReadOnly] public float DeltaTime; [ReadOnly] public float RotationLerpSpeed; [ReadOnly] public float MovementLerpSpeed; }
Le compilateur Burst nous donne des données multiples à instruction unique (SIMD); des instructions machine qui peuvent fonctionner avec plusieurs ensembles de données d'entrée et créer plusieurs ensembles de données de sortie avec une seule instruction. Cela nous aide à remplir plus de places sur le bus de cache 128 bits avec les données correctes. Le compilateur Burst, combiné à une composition de données compatible avec le cache et à un système de travail, a permis à l'équipe d'augmenter considérablement sa productivité. Voici le tableau qu'ils ont compilé en mesurant les performances après chaque étape de conversion.

Cela signifie que Far North s'est complètement débarrassé des problèmes liés à l'interpolation de la position côté client et de la direction des zombies. Leurs données sont désormais stockées sous une forme pratique pour la mise en cache et les lignes de cache ne sont remplies que de données utiles. La charge est répartie sur tous les cœurs de CPU et le compilateur Burst produit un code machine hautement optimisé avec des instructions SIMD.
Far North Entertainment DOTS Trucs et astuces
- Commencez à penser en termes de flux de données, car dans ECS, les entités sont simplement des index de recherche dans des flux de données de composants parallèles.
- Imaginez ECS comme une base de données relationnelle dans laquelle les archétypes sont des tables, les composants sont des colonnes et les entités sont des indices dans une table (ligne).
- Organisez vos données en tableaux séquentiels pour utiliser le cache du processeur et la prélecture du matériel.
- Oubliez de vouloir créer des hiérarchies d'objets et d'essayer de trouver une solution commune avant de comprendre le vrai problème que vous essayez de résoudre.
- Pensez à la collecte des ordures. Évitez de surallouer des tas dans les zones critiques pour les performances. Utilisez plutôt les nouveaux conteneurs Unity natifs. Mais attention, vous devez vous occuper du nettoyage manuel.
- Reconnaissez la valeur de vos abstractions, méfiez-vous des frais généraux liés à l'invocation de fonctions virtuelles.
- Utilisez tous les cœurs de processeur avec le système de tâches C #.
- Analysez le niveau matériel. Le compilateur Burst génère-t-il réellement des instructions SIMD? Utilisez l'inspecteur de rafale pour l'analyse.
- Arrêtez de gaspiller les lignes de cache en vide. Considérez le regroupement des données dans des lignes de cache comme le regroupement des données dans des paquets UDP.
Le principal conseil que Anders Ericsson souhaite partager est un conseil plus général pour ceux dont le projet est déjà en développement:
«Essayez d'identifier les zones spécifiques de votre jeu où vous avez des problèmes de performances et voyez si vous pouvez appliquer DOTS spécifiquement dans cette zone isolée. Vous n'avez pas besoin de changer toute la base de code! »Plans futurs
«Nous voulons utiliser DOTS dans d'autres domaines de notre jeu, et nous avons été ravis des annonces sur Unite concernant les animations DOTS, Unity Physics et Live Link. Nous aimerions apprendre à convertir davantage d'objets de jeu en objets ECS, et il semble que Unity ait fait des progrès significatifs dans la mise en œuvre de cela », conclut Anders.
Si vous avez des questions supplémentaires pour l'équipe du Grand Nord, nous vous recommandons de rejoindre leur
Discord !
Consultez la liste de lecture
DOTS Unite Copenhagen pour découvrir comment d'autres studios de jeux modernes utilisent DOTS pour créer de superbes jeux haute performance et comment les composants basés sur DOTS comme DOTS Physics, le nouveau Conversion Workflow et le compilateur Burst fonctionnent ensemble.
La traduction est terminée et nous
vous invitons à assister à un webinaire gratuit , dans lequel nous vous expliquerons comment créer votre propre jeu de tir zombie dans une heure .