Pendant longtemps, j'allais écrire un article sur numba et sur la comparaison de sa vitesse avec si. Article de Haskell « Plus rapide que C ++; plus lent que PHP "poussé à l'action. Dans les commentaires de cet article, ils ont mentionné la bibliothèque numba et qu'elle peut approximativement par magie la vitesse d'exécution du code en python à la vitesse en s. Dans cet article, après une brève revue sur numba (partie 1), une analyse un peu plus détaillée de cette situation ( partie 2 ).

Le principal inconvénient d'un python est considéré comme sa vitesse. L'overclocking du python avec un succès variable a commencé presque dès les premiers jours de son existence: shedskin , psyco , à vide peu profond , perruche , theano , nuitka , pythran , cython , pypy , numba .
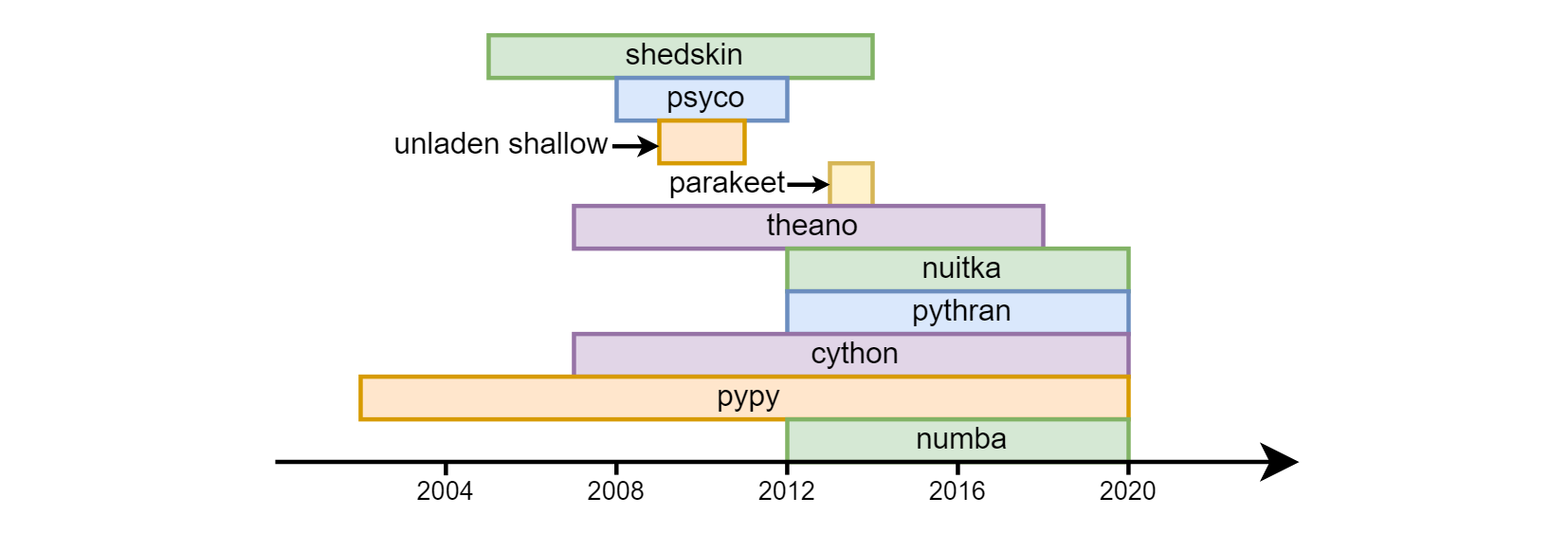
À ce jour, les trois derniers sont les plus demandés. Cython (à ne pas confondre avec cpython) - est assez différent sémantiquement du python ordinaire. En fait, c'est un langage séparé - un hybride de C et de python. Quant à pypy (une implémentation alternative du traducteur python utilisant la compilation jit) et numba (une bibliothèque pour la compilation de code en llvm), ils sont allés de différentes manières. pypy initialement déclaré la prise en charge de toutes les constructions python. En numba, ils partent du fait que cela nécessite le plus souvent une unité centrale de traitement liée - des calculs mathématiques, respectivement, ils identifient la partie du langage associée aux calculs et commencent à l'overclocker, augmentant progressivement la "couverture" (par exemple, jusqu'à récemment, il n'y avait pas de support de ligne , maintenant elle est apparue). En conséquence, pas tout le programme est overclocké dans numba , mais des fonctions séparées , cela vous permet de combiner haute vitesse et compatibilité descendante avec des bibliothèques que numba ne prend pas (encore) en charge. Numpy est pris en charge (avec des restrictions mineures) à la fois dans pypy et numba .
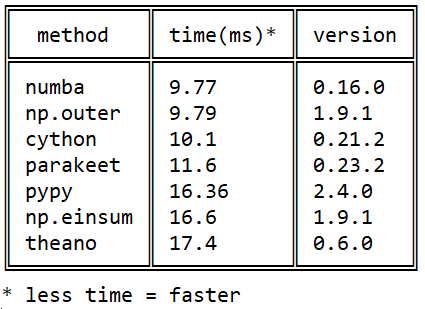 Ma connaissance de Numba a commencé en 2015 avec cette question sur stackoverflow sur la vitesse de multiplication matricielle en python: Produit externe efficace en python
Ma connaissance de Numba a commencé en 2015 avec cette question sur stackoverflow sur la vitesse de multiplication matricielle en python: Produit externe efficace en python
Depuis lors, de nombreux événements se sont produits dans chacune des bibliothèques, mais l'image en ce qui concerne numba / cython / pypy pas changé numba : numba dépasse cython grâce à l'utilisation d'instructions de processeur natif ( cython ne peut pas jit) et pypy raison d'une exécution plus efficace du bytecode llvm .
Numba est pratique pour moi au travail (traitement d'images hyperspectrales) et dans l'enseignement (intégration numérique, résolution d'équations différentielles).
comment régler
Il y a quelques années, il y avait des problèmes avec l'installation, maintenant tout a été résolu: il s'installe aussi bien via pip install numba que via conda install numba . llvm est serré et installé automatiquement.
comment accélérer
Pour accélérer une fonction, vous devez entrer le décorateur njit avant de le définir:
from numba import njit @njit def f(n): s = 0. for i in range(n): s += sqrt(i) return s
Accélération de 40 fois.
La racine est nécessaire, car sinon numba reconnaîtra la somme de la progression arithmétique (!) Et la calculera en temps constant.
jit vs njit
Auparavant, @jit mode @jit (et non @njit ) était pertinent. Le fait est que dans ce mode, vous pouvez utiliser des opérations non prises en charge par numba: le numba à haute vitesse atteint la première opération de ce type, puis il ralentit, et jusqu'à la fin de l'exécution de la fonction continue à la vitesse Python habituelle, même si rien de plus "interdit" n'est rencontré dans la fonction ( le soi-disant mode objet), ce qui est évidemment irrationnel. Maintenant, @jit abandonnent progressivement @jit , il est toujours recommandé d'utiliser @njit (ou en pleine forme @jit(nopython=True) ): dans ce mode, le numba jure avec des exceptions à de tels endroits - il est préférable de les réécrire pour ne pas perdre de la vitesse.
ce qui peut accélérer
Dans les fonctions overclockées, seule une partie des fonctionnalités python et numba peut être utilisée. Tous les opérateurs, fonctions et classes sont divisés en deux parties en ce qui concerne le numba: ceux que le numba "comprend" et ceux qu'il "ne comprend pas".
Il existe deux listes de ce type dans la documentation numba (avec des exemples):
- un sous-ensemble de la fonctionnalité python familière à numbe et
- un sous-ensemble de la fonction numpy familière à numbe.
Parmi les remarquables dans ces listes:
- un numba «comprend» les listes Python avec un ajout rapide (amorti O (1)) à la fin que numpy «ne comprend pas» (bien que seulement homogènes à partir d'éléments du même type),
- les tableaux de numpy qui ne sont pas dans le python de base. Comprend aussi
- tuples: ils peuvent, comme un python normal, contenir des éléments de différents types.
- dictionnaires: numba a sa propre implémentation d'un dictionnaire typé. Toutes les clés doivent être du même type, exactement comme les valeurs. Le dict python ne peut pas être passé à numba, mais le numba
numba.typed.Dict peut être créé en python et transféré vers / depuis numba (tandis qu'en python cela fonctionne un peu plus lentement que python). - récemment str et octets, cependant, uniquement car les paramètres d'entrée ne peuvent pas être créés (encore?).
Elle ne comprend aucune autre bibliothèque (en particulier, scipy et pandas).
Mais même ce sous-ensemble du langage qu'elle comprend suffit pour overclocker la plupart du code pour les applications scientifiques sur lesquelles numba se concentre principalement.
important!
Parmi les fonctions overclockées, seules les fonctions overclockées et non overclockées peuvent être appelées.
(bien que les fonctions overclockées puissent être appelées depuis overclocked et non overclocké).
globales
Dans les fonctions overclockées, les variables globales deviennent des constantes: leur valeur est fixe au moment de la compilation de la fonction ( exemple ). => N'utilisez pas de variables globales dans les fonctions overclockées (sauf pour les constantes).
signatures
Dans le nombre de chaque fonction, un ou plusieurs types d'arguments d'entrée et de sortie sont mappés, c'est-à-dire signatures. Lorsque la fonction est appelée pour la première fois, la signature est générée et le code de fonction binaire correspondant est compilé automatiquement. Lorsqu'il est lancé avec d'autres types d'arguments, de nouvelles signatures et de nouveaux binaires seront créés (les anciens sont conservés). Ainsi, la "sortie en mode" en termes de vitesse d'exécution pour chaque signature se produit, à partir de la deuxième exécution avec ces types d'arguments. Donc soit
- «Réchauffez le cache» en lançant avec de petites tailles de tableaux d'entrée, ou
- spécifiez l'argument
@jit(cache=True) pour enregistrer le code compilé sur le disque avec son chargement automatique lors des lancements de programmes ultérieurs (bien qu'en pratique ce premier lancement soit encore un peu plus lent que les suivants, mais plus rapide que sans cache=True ) .
Il y a une troisième voie. Les signatures peuvent être définies manuellement:
from numba import int16, int32 @njit(int32(int16, int16)) def f(x, y): return x + y >>> f.signatures [(int16, int16)]
Lorsque vous exécutez une fonction avec la signature spécifiée dans le décorateur, la première exécution sera rapide: la compilation aura lieu au moment où le python voit la définition de la fonction, et non au premier démarrage. Il peut y avoir plusieurs signatures, l'ordre de leur séquence est important.
Attention: cette dernière méthode n'est pas pérenne. Les auteurs de numba avertissent que la syntaxe pour spécifier les types pourrait changer à l'avenir, @jit / @njit sans signatures est une option plus sûre à cet égard.
f.signatures signatures ne commencent à afficher les signatures que lorsque le python les découvre, c'est-à-dire après le premier appel de fonction, ou si elles sont définies manuellement.
En plus des signatures f.signatures signatures peuvent être visualisées via f.inspect_types() - en plus des types de paramètres d'entrée, cette fonction affichera les types de paramètres de sortie ainsi que les types de toutes les variables locales.
En plus des types de paramètres d'entrée et de sortie, il est possible de spécifier manuellement les types de variables locales:
from numba import int16, int32 @njit(int32(int16, int16), locals={'z': int32}) def f(x, y): z = y + 10 return x + z
int
En numba, les entiers n'ont pas d'arithmétique longue comme en python "simple", mais il existe des types standard de différentes largeurs de int8 à int64 ( table de types dans la documentation). Il existe également des types int_ (ainsi que float_ ), qui permettent au numba de choisir la largeur de champ optimale (de son point de vue).
cours
Il y a généralement un support pour les classes (@jitclass), mais jusqu'à présent, il est expérimental, il est donc préférable d'éviter de les utiliser pour l'instant (pour le moment, selon mon expérience, c'est beaucoup plus lent avec elles que sans elles).
dtypes personnalisés
Numba prend en charge une certaine alternative aux classes de tableaux structurés numpy, ou, en d'autres termes, de types personnalisés. Ils fonctionnent à la même vitesse que les tableaux numpy ordinaires, ils sont légèrement plus pratiques à indexer (par exemple, a['y2'] plus lisible qu'un a[3] ). Fait intéressant, dans numba, contrairement à numpy, un a.y2 plus concis a.y2 autorisé avec la syntaxe habituelle a['y2'] . Mais en général, leur soutien en numba laisse beaucoup à désirer, et certaines opérations, même évidentes en numpy, avec elles dans le numba sont enregistrées de manière assez non triviale.
GPU
Il est capable d'exécuter du code overclocké sur le GPU, et contrairement au même, par exemple, pycuda ou pytorch, non seulement sur nvidia, mais aussi sur les cartes amd'shnyh. Avec cela, jusqu'ici peu a été traité. Voici un article sur la comparaison Habre 2016 des performances des calculs GPU en Python et C. Là, une vitesse comparable à C a été obtenue.
compilation à l'avance
Il y a un mode de compilation ( documentation ) normal (c'est-à-dire pas jit) dans le numba, mais ce mode n'est pas le principal, je ne l'ai pas compris.
parallélisation automatique
Certaines tâches (par exemple, multiplier une matrice par un nombre) sont parallélisées naturellement. Mais il y a des tâches dont la mise en œuvre ne peut pas être parallélisée. Avec le décorateur @njit(parallel=True) numba analyse le code de la fonction overclockée, trouve de telles sections, chacune ne pouvant pas être parallélisée par elle-même, et les exécute simultanément sur différents cœurs de CPU ( documentation ). Auparavant, vous ne pouviez paralléliser les fonctions que manuellement à l'aide de @vectorize ( documentation ), qui nécessitait des modifications de code.
En pratique, cela ressemble à ceci: ajouter parallel=True , mesurer la vitesse, si nous avons de la chance et cela s'est avéré plus rapide - nous le laissons, plus lentement - nous le supprimons. (** Mise à jour Comme indiqué dans le commentaire de la deuxième partie de l'article, ce drapeau a de nombreux bugs ouverts)
Sortie de GIL
Les fonctions décorées avec @jit(nogil=True) et exécutées dans différents threads peuvent être exécutées en parallèle. Pour éviter les conditions de concurrence, vous devez utiliser la synchronisation des threads.
la documentation
Numbe manque toujours de documentation raisonnable. Elle l'est, mais tout n'est pas en elle.
optimisation
Il y a une certaine imprévisibilité lors de l'optimisation manuelle du code: le code non pythonique s'exécute souvent plus vite que pythonique.
Pour ceux qui s'intéressent au sujet, je peux recommander une vidéo d'une master class numba de la conférence scipy 2017 (il y a des codes source sur le github). Il est vraiment long et partiellement obsolète (par exemple, les chaînes sont déjà prises en charge), mais il aide à se faire une idée générale: il contient notamment des informations sur pythonic / unpythonic, jit (parallel = True), etc.
Dans la deuxième partie, nous considérerons l'utilisation de numba en utilisant le code de l'article mentionné au début de l'article.