Ceci est la deuxième partie de l'article sur numba. Le premier était une introduction historique et un bref manuel d'instructions numba. Ici, je présente un code de tâche légèrement modifié de l'article de Haskell « Plus rapide que C ++; plus lent que PHP »(il compare les performances des implémentations d'un algorithme dans différents langages / compilateurs) avec des repères, des graphiques et des explications plus détaillés. Je dirai tout de suite que j'ai vu l'article Oh, ce lent C / C ++ et, très probablement, si vous apportez ces modifications au code C, l'image changera quelque peu, mais même dans ce cas, le python est capable de dépasser la vitesse de C même dans cette version est en soi remarquable.

Remplacement de la liste Python par un tableau numpy (et, par conséquent, v0[:] par v0.copy() , car dans numpy, a[:] renvoie la view au lieu de la copier).
Pour comprendre la nature du comportement de performance, j'ai fait un «scan» par le nombre d'éléments dans le tableau.
Dans le code Python, j'ai remplacé time.monotonic par time.perf_counter , car il est plus précis (1us contre 1ms pour monotone).
Puisque numba utilise la compilation jit, cette même compilation devrait un jour avoir lieu. Par défaut, cela se produit lorsque la fonction est appelée pour la première fois et affecte inévitablement les résultats des tests de performance (bien que si vous prenez le temps de trois lancements, vous ne le remarquerez peut-être pas), et cela se ressent également dans la pratique. Il existe plusieurs façons de faire face à ce phénomène:
1) Cachez les résultats de la compilation sur le disque:
@njit(cache=True) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:
alors la compilation se fera au premier appel du programme, et aux appels suivants seront extraits du disque.
2) indiquer la signature
La compilation aura lieu au moment où python analyse la définition de la fonction, et le premier démarrage sera déjà rapide.
La chaîne d'origine est transmise (plus précisément, octets), mais la prise en charge des chaînes a été ajoutée récemment, de sorte que la signature est assez monstrueuse (voir ci-dessous). Les signatures sont généralement écrites plus simplement:
@njit(nb.int64(nb.uint8[:], nb.uint8[:])) def lev_dist(s1, s2):
mais ensuite vous devez convertir les octets en un tableau numpy à l'avance:
s1_py = [int(x) for x in b"a" * 15000] s1 = np.array(s1_py, dtype=np.uint8)
ou
s1 = np.full(15000, ord('a'), dtype=np.uint8)
Et vous pouvez laisser les octets tels quels et spécifier la signature sous cette forme:
@njit(nb.int64(nb.bytes(nb.uint8, nb.1d, nb.C), nb.bytes(nb.uint8, nb.1d, nb.C))) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:
La vitesse d'exécution des octets et du tableau numpy de uint8 (dans ce cas) est la même.
3) préchauffer le cache
s1 = b"a" * 15
La compilation se fera alors au premier appel, et le second sera déjà rapide.
Code C (clang -O3 -march = native) #include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h> static long lev_dist (const char *s1, unsigned long m, const char *s2, unsigned long n) { // unsigned long m, n; unsigned long i, j; long *v0, *v1; long ret, *temp; /* Edge cases. */ if (m == 0) { return n; } else if (n == 0) { return m; } v0 = malloc (sizeof (long) * (n + 1)); v1 = malloc (sizeof (long) * (n + 1)); if (v0 == NULL || v1 == NULL) { fprintf (stderr, "failed to allocate memory\n"); exit (-1); } for (i = 0; i <= n; ++i) { v0[i] = i; } memcpy (v1, v0, sizeof(long) * (n + 1)); for (i = 0; i < m; ++i) { v1[0] = i + 1; for (j = 0; j < n; ++j) { const long subst_cost = (s1[i] == s2[j]) ? v0[j] : (v0[j] + 1); const long del_cost = v0[j + 1] + 1; const long ins_cost = v1[j] + 1; #if !defined(__GNUC__) || defined(__llvm__) if (subst_cost < del_cost) { v1[j + 1] = subst_cost; } else { v1[j + 1] = del_cost; } #else v1[j + 1] = (subst_cost < del_cost) ? subst_cost : del_cost; #endif if (ins_cost < v1[j + 1]) { v1[j + 1] = ins_cost; } } temp = v0; v0 = v1; v1 = temp; } ret = v0[n]; free (v0); free (v1); return ret; } int main () { char s1[25001], s2[25001], s3[25001]; int lengths[] = {1000, 2000, 5000, 10000, 15000, 20000, 25000}; FILE *fout; fopen_s(&fout, "c.txt", "w"); for(int j = 0; j < sizeof(lengths)/sizeof(lengths[0]); j++){ int len = lengths[j]; int i; clock_t start_time, exec_time; for (i = 0; i < len; ++i) { s1[i] = 'a'; s2[i] = 'a'; s3[i] = 'b'; } s1[len] = s2[len] = s3[len] = '\0'; start_time = clock (); printf ("%ld\n", lev_dist (s1, len, s2, len)); printf ("%ld\n", lev_dist (s1, len, s3, len)); exec_time = clock () - start_time; fprintf(fout, "%d %.6f\n", len, ((double) exec_time) / CLOCKS_PER_SEC); fprintf (stderr, "Finished in %.3fs\n", ((double) exec_time) / CLOCKS_PER_SEC); } return 0; }
La comparaison a été effectuée sous windows (windows 10 x64, python 3.7.3, numba 0.45.1, clang 9.0.0, intel m5-6y54 skylake): et sous linux (debian 4.9.30, python 3.7.4, numba 0.45.1, clang 9.0.0).
X est la taille du tableau, y est le temps en secondes.
Échelle linéaire Windows:
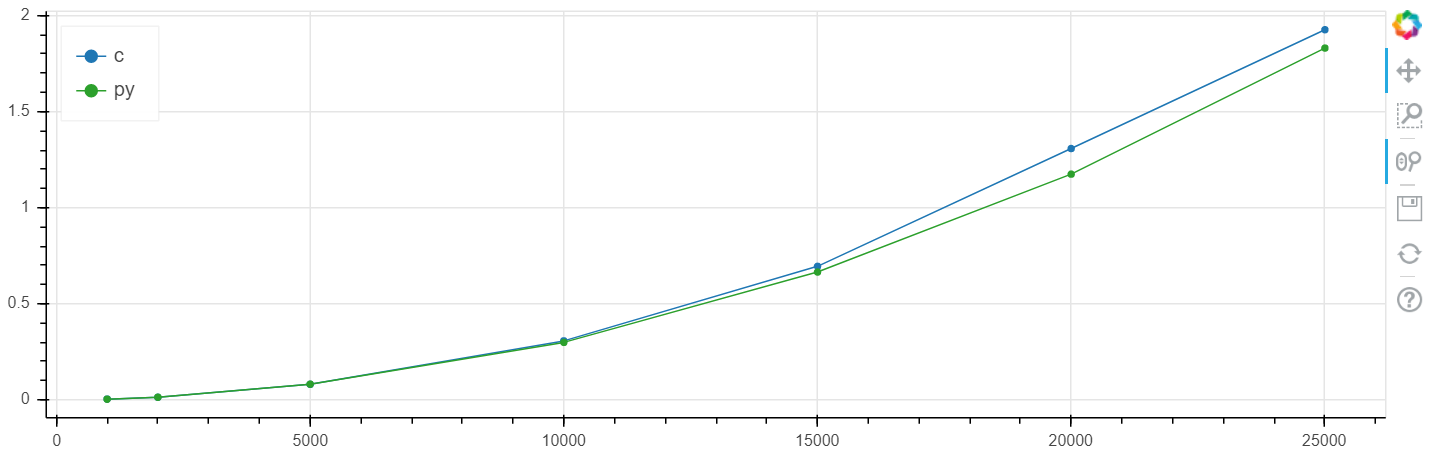
Échelle logarithmique Windows:
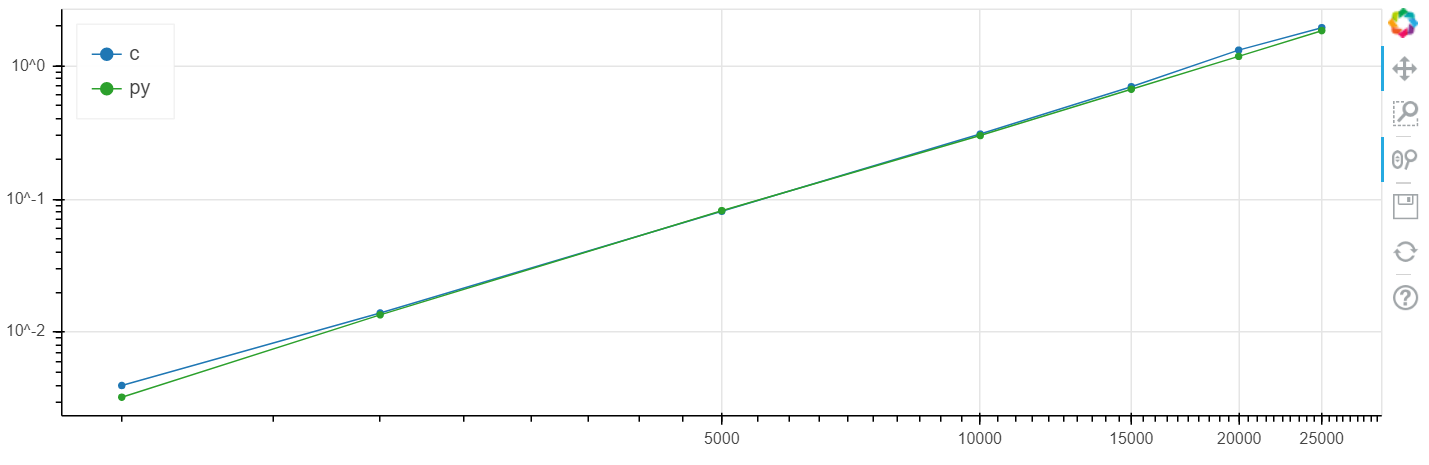
Échelle linéaire Linux:

Échelle logarithmique Linux
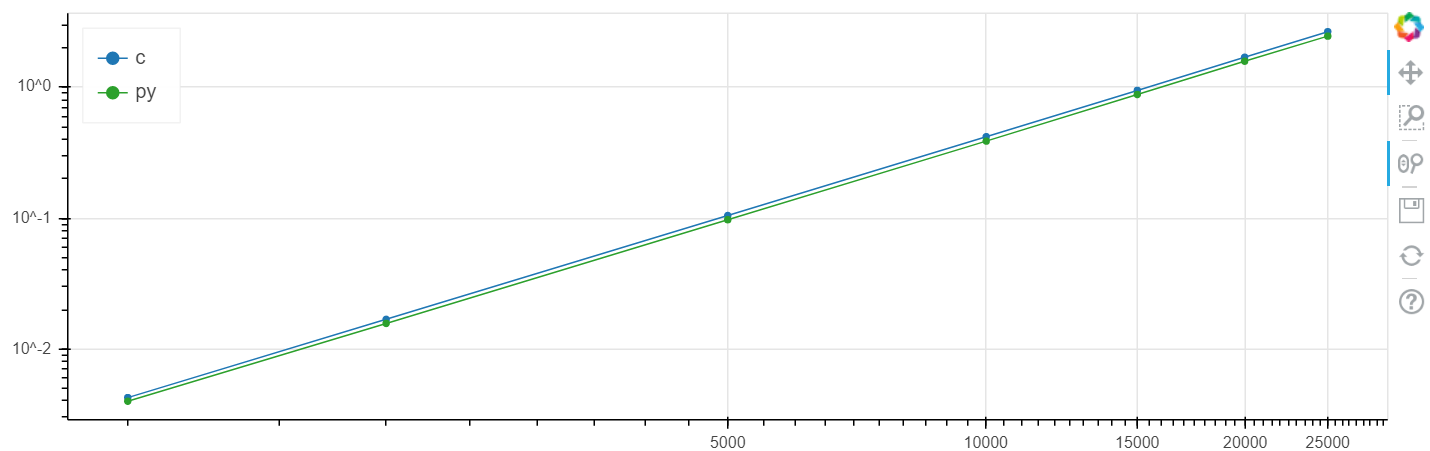
Dans ce problème, une augmentation de la vitesse a été obtenue par rapport au clang au niveau de plusieurs pour cent, ce qui est généralement supérieur à l'erreur statistique.
J'ai fait à plusieurs reprises cette comparaison sur différentes tâches et, en règle générale, si numba peut accélérer quelque chose, il l'accélère à une vitesse dans la marge d'erreur coïncidant avec la vitesse C (sans utiliser d'inserts d'assembleur).
Je répète que si vous apportez des modifications au code en C de Oh, cette situation lente C / C ++ peut changer.
Je serai heureux d'entendre des questions et des suggestions dans les commentaires.
PS Lorsque vous spécifiez la signature des tableaux, il est préférable de définir explicitement le mode d'alternance des lignes / colonnes:
de sorte que numba ne pense pas à «C» (si) ceci ou à «A» (reconnaissance automatique si / fortran) - pour une raison quelconque, cela affecte les performances même pour les tableaux unidimensionnels, pour cela il existe une telle syntaxe originale: uint8[:,:] this ' A '(détection automatique), nb.uint8[:, ::1] est' C '(si), np.uint8[::1, :] est' F '(fortran).
@njit(nb.int64(nb.uint8[::1], nb.uint8[::1])) def lev_dist(s1, s2):