Bonjour à tous ceux qui ont choisi la voie du ML-Samurai!
Présentation:
Dans cet article, nous considérons la méthode de la machine à vecteurs de support ( Eng. SVM, Support Vector Machine ) pour le problème de classification. L'idée principale de l'algorithme sera présentée, le résultat de la définition de ses poids et une simple implémentation DIY seront analysés. Sur l'exemple d'un jeu de données Iris le fonctionnement de l'algorithme écrit avec des données séparables / inséparables linéairement dans l'espace sera démontré R2 et visualisation de l'entraînement / pronostic. De plus, les avantages et les inconvénients de l'algorithme, ses modifications seront annoncées.

Figure 1. Photo open source d'une fleur d'iris
Le problème à résoudre:
Nous allons résoudre le problème de la classification binaire (quand il n'y a que deux classes). Premièrement, l'algorithme s'entraîne sur des objets de l'ensemble d'apprentissage, pour lesquels les étiquettes de classe sont connues à l'avance. En outre, l'algorithme déjà formé prédit l'étiquette de classe pour chaque objet à partir de l'échantillon différé / test. Les étiquettes de classe peuvent prendre des valeurs Y = \ {- 1, +1 \}Y = \ {- 1, +1 \} . Objet - vecteur avec N signes x=(x1,x2,...,xn) dans l'espace Rn . Lors de l'apprentissage, l'algorithme doit créer une fonction F(x)=y qui prend un argument x - un objet de l'espace Rn et donne l'étiquette de classe y .
Mots généraux sur l'algorithme:
La tâche de classification concerne l'enseignement avec un enseignant. SVM est un algorithme d'apprentissage avec un enseignant. Visuellement, de nombreux algorithmes d'apprentissage automatique peuvent être trouvés dans cet article de premier ordre (voir la section «Carte du monde de l'apprentissage automatique»). Il convient d'ajouter que SVM peut également être utilisé pour les problèmes de régression, mais le classificateur SVM sera analysé dans cet article.
L'objectif principal de SVM en tant que classificateur est de trouver l'équation d'un hyperplan de séparation
w1x1+w2x2+...+wnxn+w0=0 dans l'espace Rn , ce qui diviserait les deux classes de manière optimale. Vue générale de la transformation F installation x au libellé de classe Y : F(x)=signe(wTx−b) . Nous nous souviendrons que nous avons désigné w=(w1,w2,...,wn),b=−w0 . Après avoir configuré les pondérations de l'algorithme w et b (formation), tous les objets tombant d'un côté de l'hyperplan construit seront prédits comme la première classe, et les objets tombant de l'autre côté - la deuxième classe.
Fonction intérieure signe() il y a une combinaison linéaire de caractéristiques de l'objet avec les poids d'algorithme, c'est pourquoi SVM fait référence à des algorithmes linéaires. Un hyperplan diviseur peut être construit de différentes manières, mais en poids SVM w et b sont configurés de telle sorte que les objets de classe se trouvent le plus loin possible de l'hyperplan de séparation. En d'autres termes, l'algorithme maximise l'écart ( marge anglaise ) entre l'hyperplan et les objets de classe qui en sont les plus proches. Ces objets sont appelés vecteurs de support (voir Fig. 2). D'où le nom de l'algorithme.

Figure 2. SVM (la base de la figure d'ici )
Une sortie détaillée des règles d'ajustement d'échelle SVM:
Afin de maintenir l'hyperplan de division aussi loin que possible des points d'échantillonnage, la largeur de bande doit être maximale. Vecteur w Est le vecteur directeur de l'hyperplan diviseur. Ci-après, nous désignons le produit scalaire de deux vecteurs comme langlea,b rangle ou aTb .Trouvons la projection du vecteur dont les extrémités seront les vecteurs supports de différentes classes sur le vecteur direction de l'hyperplan. Cette projection montrera la largeur de la bande de séparation (voir Fig.3):

Figure 3. La sortie des règles de réglage des échelles (la base de la figure d'ici )
langle(x+−x−),w/ Arrowvertw Arrowvert rangle=( langlex+,w rangle− langlex−,w rangle)/ Arrowvertw Arrowvert=((b+1)−(b−1))/ Arrowvertw Arrowvert=2/ Arrowvertw Arrowvert
2/ Arrowvertw Arrowvert rightarrowmax
Arrowvertw Arrowvert rightarrowmin
(wTw)/2 rightarrowmin
La marge de l' objet x à partir de la limite de classe est la valeur M=y(wTx−b) . L'algorithme fait une erreur sur l'objet si et seulement si le retrait M négatif (quand y et (wTx−b) différents caractères). Si M∈(0,1) , puis l'objet tombe à l'intérieur de la bande de séparation. Si M>1 , alors l'objet x est correctement classé et est situé à une certaine distance de la bande de séparation. Nous écrivons cette connexion:
y(wTx−b) geqslant1
Le système résultant est le paramètre SVM par défaut avec un espace dur ( SVM à marge dure ), quand aucun objet n'est autorisé à entrer dans la bande de séparation. Il est résolu analytiquement par le théorème de Kuhn-Tucker. Le problème qui en résulte est équivalent au double problème de trouver le point de selle de la fonction Lagrange.
$$ afficher $$ \ left \ {\ begin {array} {ll} (w ^ Tw) / 2 \ rightarrow min & \ textrm {} \\ y (w ^ Tx-b) \ geqslant 1 & \ textrm {} \ end {array} \ right. $$ afficher $$
Tout cela est bon tant que nos classes sont linéairement séparables. Pour que l'algorithme puisse fonctionner avec des données linéairement inséparables, transformons un peu notre système. Laissez l'algorithme faire des erreurs sur les objets d'apprentissage, mais en même temps, essayez de conserver moins d'erreurs. Nous introduisons un ensemble de variables supplémentaires xii>0 caractériser l'ampleur de l'erreur sur chaque objet xi . Nous introduisons une pénalité pour l'erreur totale dans la fonction minimisée:
$$ afficher $$ \ left \ {\ begin {array} {ll} (w ^ Tw) / 2 + \ alpha \ sum \ xi _i \ rightarrow min & \ textrm {} \\ y (w ^ Tx_i-b) \ geqslant 1 - \ xi _i & \ textrm {} \\ \ xi _i \ geqslant0 & \ textrm {} \ end {array} \ right. $$ afficher $$
Nous considérerons le nombre d'erreurs d'algorithme (lorsque M <0). Appelez ça une pénalité . Ensuite, la pénalité pour tous les objets sera égale au montant des amendes pour chaque objet xi où [Mi<0] - fonction de seuil (voir Fig.4):
Pénalité= sum[Mi<0]
$$ afficher $$ [M_i <0] = \ left \ {\ begin {array} {ll} 1 & \ textrm {if} M_i <0 \\ 0 & \ textrm {if} M_i \ geqslant 0 \ end {tableau} \ droite. $$ afficher $$
Ensuite, nous rendons la pénalité sensible à l'ampleur de l'erreur et introduisons en même temps une pénalité pour l'approche de l'objet à la limite de classe:
Pénalité= sum[Mi<0] leqslant sum(1−Mi)+= summax(0,1−Mi)
Lors de l'ajout à l'expression de pénalité, le terme alpha(wTw)/2 nous obtenons la fonction de perte SVM classique avec un espace doux ( SVM à marge douce ) pour un objet:
Q=max(0,1−Mi)+ alpha(wTw)/2
Q=max(0,1−ywTx)+ alpha(wTw)/2
Q - fonction de perte, c'est aussi une fonction de perte. C'est ce que nous allons minimiser à l'aide de la descente de gradient dans la mise en place des mains. Nous dérivons les règles de changement de poids, où eta - étape de descente:
w=w− eta bigtriangledownQ
$$ afficher $$ \ bigtriangledown Q = \ left \ {\ begin {array} {ll} \ alpha w-yx & \ textrm {if} yw ^ Tx <1 \\ \ alpha w & \ textrm {if} yw ^ Tx \ geqslant 1 \ end {array} \ droite. $$ afficher $$
Questions possibles lors des entretiens (basées sur des événements réels):
Après des questions générales sur SVM: Pourquoi Hinge_loss maximise-t-il le jeu? - d'abord, rappelez-vous qu'un hyperplan change de position lorsque les poids changent w et b . Les poids de l'algorithme commencent à changer lorsque les gradients de la fonction de perte ne sont pas égaux à zéro (ils disent généralement: «les gradients s'écoulent»). Par conséquent, nous avons spécialement sélectionné une telle fonction de perte, dans laquelle les gradients commencent à couler au bon moment. Pertedecharnière ressemble à ceci: H=max(0,1−y(wTx)) . N'oubliez pas que le dégagement m=y(wTx) . Quand l'écart m assez grand ( 1 ou plus) expression (1m) devient inférieur à zéro et H=0 (par conséquent, les gradients ne coulent pas et le poids de l'algorithme ne change en aucune façon). Si l'écart m est suffisamment petit (par exemple, lorsqu'un objet tombe dans la bande de séparation et / ou est négatif (si la prévision de classification est incorrecte), alors Hinge_loss devient positif ( H>0 ), les gradients commencent à couler et les poids des algorithmes changent. En résumé: les gradients s'écoulent dans deux cas: lorsque l'objet échantillon est tombé à l'intérieur de la bande de séparation et lorsque l'objet est mal classé.
Pour vérifier le niveau d'une langue étrangère, des questions similaires sont possibles: Quelles sont les similitudes et les différences entre LogisticRegression et SVM? - tout d'abord, nous parlerons de similitudes: les deux algorithmes sont des algorithmes de classification linéaire en apprentissage supervisé. Certaines similitudes se trouvent dans leurs arguments concernant les fonctions de perte: log(1+exp(−y(wTx))) pour logreg et max(0,1−y(wTx)) pour SVM (regardez l'image 4). Les deux algorithmes que nous pouvons configurer en utilisant la descente de gradient. Parlons maintenant des différences: SVM renvoie l'étiquette de classe de l'objet contrairement à LogReg, qui renvoie la probabilité d'appartenance à la classe. SVM ne peut pas fonctionner avec les étiquettes de classe \ {0,1 \}\ {0,1 \} (sans renommer les classes) contrairement à LogReg (fonction de perte LogReg pour \ {0,1 \}\ {0,1 \} : −ylog(p)−(1−y)log(1−p) , où y - véritable étiquette de classe, p - retour de l'algorithme, probabilité d'appartenance à l'objet x en classe \ {1 \}\ {1 \} ) Plus que cela, nous pouvons résoudre le problème SVM à marge dure sans descente de gradient. La tâche de recherche de vecteurs de support est réduite au point de selle de recherche dans la fonction Lagrange - cette tâche se réfère uniquement à la programmation quadratique.
Code de la fonction de perte:import numpy as np import matplotlib.pyplot as plt %matplotlib inline xx = np.linspace(-4,3,100000) plt.plot(xx, [(x<0).astype(int) for x in xx], linewidth=2, label='1 if M<0, else 0') plt.plot(xx, [np.log2(1+2.76**(-x)) for x in xx], linewidth=4, label='logistic = log(1+e^-M)') plt.plot(xx, [np.max(np.array([0,1-x])) for x in xx], linewidth=4, label='hinge = max(0,1-M)') plt.title('Loss = F(Margin)') plt.grid() plt.legend(prop={'size': 14});

Figure 4. Fonctions de perte
Implémentation simple du SVM classique à marge souple:
Attention! Vous trouverez un lien vers le code complet à la fin de l'article. Vous trouverez ci-dessous des blocs de code sortis de leur contexte. Certains blocs ne peuvent être démarrés qu'après avoir travaillé sur les blocs précédents. Sous de nombreux blocs, des images seront montrées qui montrent comment le code placé au-dessus de cela a fonctionné.
Tout d'abord, nous allons couper les bibliothèques requises et la fonction de tracé de ligne: import numpy as np import warnings warnings.filterwarnings('ignore') import matplotlib.pyplot as plt import matplotlib.lines as mlines plt.rcParams['figure.figsize'] = (8,6) %matplotlib inline from sklearn.datasets import load_iris from sklearn.decomposition import PCA from sklearn.model_selection import train_test_split def newline(p1, p2, color=None):
Code d'implémentation Python pour SVM à marge douce: def add_bias_feature(a): a_extended = np.zeros((a.shape[0],a.shape[1]+1)) a_extended[:,:-1] = a a_extended[:,-1] = int(1) return a_extended class CustomSVM(object): __class__ = "CustomSVM" __doc__ = """ This is an implementation of the SVM classification algorithm Note that it works only for binary classification ############################################################# ###################### PARAMETERS ###################### ############################################################# etha: float(default - 0.01) Learning rate, gradient step alpha: float, (default - 0.1) Regularization parameter in 0.5*alpha*||w||^2 epochs: int, (default - 200) Number of epochs of training ############################################################# ############################################################# ############################################################# """ def __init__(self, etha=0.01, alpha=0.1, epochs=200): self._epochs = epochs self._etha = etha self._alpha = alpha self._w = None self.history_w = [] self.train_errors = None self.val_errors = None self.train_loss = None self.val_loss = None def fit(self, X_train, Y_train, X_val, Y_val, verbose=False):
Nous considérons en détail le fonctionnement de chaque bloc de lignes:
1) créer une fonction add_bias_feature (a) , qui étend automatiquement le vecteur des objets, en ajoutant le nombre 1 à la fin de chaque vecteur, ce qui est nécessaire pour «oublier» le terme libre b. Expression wTx−b équivalent à l'expression w1x1+w2x2+...+wnxn+w0∗1 . Nous supposons conditionnellement que l'unité est la dernière composante du vecteur pour tous les vecteurs x, et w0=−b . Maintenant, régler les poids w et w0 Nous produirons en même temps.
Code de fonction d'extension de vecteur de fonction: def add_bias_feature(a): a_extended = np.zeros((a.shape[0],a.shape[1]+1)) a_extended[:,:-1] = a a_extended[:,-1] = int(1) return a_extended
2) nous décrirons ensuite le classificateur lui-même. Il a pour fonctions d'initialiser init () , d'apprendre fit () , de prédire predire () , de trouver la perte de la fonction hinge_loss () et de trouver la perte totale de la fonction de l'algorithme classique avec un soft gap soft_margin_loss () .
3) lors de l'initialisation, 3 hyperparamètres sont introduits: _etha - étape de descente de gradient ( eta ), _alpha - coefficient de vitesse de réduction de poids proportionnelle (avant le terme quadratique dans la fonction de perte alpha ), _epochs - le nombre d'époques d'entraînement.
Code de fonction d'initialisation: def __init__(self, etha=0.01, alpha=0.1, epochs=200): self._epochs = epochs self._etha = etha self._alpha = alpha self._w = None self.history_w = [] self.train_errors = None self.val_errors = None self.train_loss = None self.val_loss = None
4) pendant l'entraînement pour chaque époque de l'échantillon d'apprentissage (X_train, Y_train) nous prendrons un élément de l'échantillon, calculons l'écart entre cet élément et la position de l'hyperplan à un instant donné. De plus, en fonction de la taille de cet écart, nous changerons le poids de l'algorithme en utilisant le gradient de la fonction de perte Q . Dans le même temps, nous calculerons la valeur de cette fonction pour chaque époque et combien de fois nous changerons de poids par époque. Avant de commencer la formation, nous nous assurerons que pas plus de deux étiquettes de classe différentes ne sont vraiment entrées dans la fonction d'apprentissage. Avant de configurer la balance, elle est initialisée en utilisant la distribution normale.
Code de la fonction d'apprentissage: def fit(self, X_train, Y_train, X_val, Y_val, verbose=False):
Vérification du fonctionnement de l'algorithme écrit:
Vérifiez que notre algorithme écrit fonctionne sur une sorte de jeu de données jouet. Prenez le jeu de données Iris. Nous préparerons les données. Désigner les classes 1 et 2 comme +1 et classe 0 as −1 . En utilisant l'algorithme PCA (explication et application ici ), nous réduisons de manière optimale l'espace de 4 attributs à 2 avec une perte de données minimale (il nous sera plus facile d'observer la formation et le résultat). Ensuite, nous nous diviserons en un échantillon de formation (train) et un échantillon retardé (validation). Nous allons nous entraîner sur l'échantillon d'entraînement, prévoir et vérifier les différés. Nous choisissons les facteurs d'apprentissage pour que la fonction de perte diminue. Au cours de la formation, nous examinerons la fonction de perte de la formation et l'échantillonnage retardé.
Bloc de préparation des données: Unité d'initialisation et de formation: 
Le bloc de visualisation de la bande de séparation résultante: d = {-1:'green', 1:'red'} plt.scatter(X_train[:,0], X_train[:,1], c=[d[y] for y in Y_train]) newline([0,-svm._w[2]/svm._w[1]],[-svm._w[2]/svm._w[0],0], 'blue')

Bloc de visualisation des prévisions: 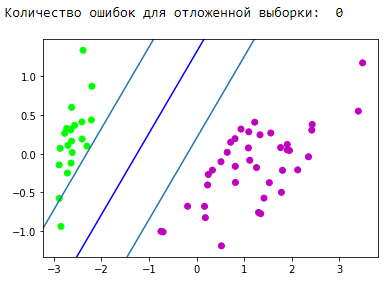
Super! Notre algorithme a traité des données linéairement séparables. Maintenant, séparez les classes 0 et 1 de la classe 2:
Bloc de préparation des données: Unité d'initialisation et de formation: 
Le bloc de visualisation de la bande de séparation résultante: d = {-1:'green', 1:'red'} plt.scatter(X_train[:,0], X_train[:,1], c=[d[y] for y in Y_train]) newline([0,-svm._w[2]/svm._w[1]],[-svm._w[2]/svm._w[0],0], 'blue')
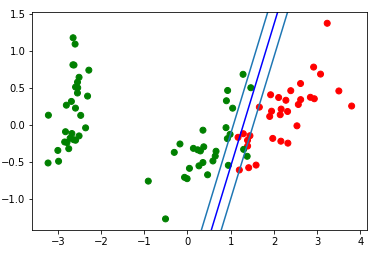
Regardons le gif, qui montrera comment la ligne de séparation a changé de position pendant l'entraînement (seulement 500 images pour changer de poids. Les 300 premières d'affilée. Les 200 pièces suivantes pour chaque 130ème image):
Code de création d'animation: import matplotlib.animation as animation from matplotlib.animation import PillowWriter def one_image(w, X, Y): axes = plt.gca() axes.set_xlim([-4,4]) axes.set_ylim([-1.5,1.5]) d1 = {-1:'green', 1:'red'} im = plt.scatter(X[:,0], X[:,1], c=[d1[y] for y in Y]) im = newline([0,-w[2]/w[1]],[-w[2]/w[0],0], 'blue')

Bloc de visualisation des prévisions: 
Redresser les espaces
Il est important de comprendre que dans les problèmes réels, il n'y aura pas de cas simple avec des données linéairement séparables. Pour travailler avec de telles données, l'idée de se déplacer vers un autre espace a été proposée, où les données seront linéairement séparables. Un tel espace est appelé rectification. La rectification des espaces et des noyaux ne sera pas affectée dans cet article. Vous pouvez trouver la théorie mathématique la plus complète dans 14,15,16 synopsis d'E. Sokolov et dans les conférences de K.V. Vorontsov .
Utilisation de SVM depuis sklearn:
En fait, presque tous les algorithmes classiques d'apprentissage automatique sont écrits pour vous. Donnons un exemple du code, nous prendrons l'algorithme de la bibliothèque sklearn .
Exemple de code from sklearn import svm from sklearn.metrics import recall_score C = 1.0
Avantages et inconvénients du SVM classique:
Avantages:
- fonctionne bien avec un grand espace de fonctionnalités;
- fonctionne bien avec de petites données;
- Ainsi, l'algorithme trouve maximise la bande de division, ce qui, comme un airbag, peut réduire le nombre d'erreurs de classification;
- puisque l'algorithme se réduit à résoudre le problème de programmation quadratique dans un domaine convexe, un tel problème a toujours une solution unique (l'hyperplan de séparation avec certains hyperparamètres de l'algorithme est toujours le même).
Inconvénients:
- longue durée de formation (pour les grands ensembles de données);
- instabilité du bruit: les valeurs aberrantes dans les données d'entraînement deviennent des objets intrus de référence et affectent directement la construction d'un hyperplan de séparation;
- les méthodes générales de construction de noyaux et de rectification d'espaces les plus adaptées à un problème spécifique en cas d'inséparabilité linéaire des classes ne sont pas décrites. La sélection de transformations de données utiles est un art.
Application SVM:
Le choix de l'un ou l'autre algorithme d'apprentissage automatique dépend directement des informations obtenues lors de l'exploration de données. Mais en termes généraux, les tâches suivantes peuvent être distinguées:
- tâches avec un petit ensemble de données;
- tâches de classification de texte. SVM donne une bonne base de référence ([prétraitement] + [TF-iDF] + [SVM]), la précision des prévisions obtenue se révèle être au niveau de certains réseaux de neurones convolutionnels / récurrents (je recommande d'essayer cette méthode vous-même pour consolider le matériel). Un excellent exemple est donné ici, "Partie 3. Un exemple de l'une des astuces que nous enseignons" ;
- pour de nombreuses tâches avec des données structurées, le lien [ingénierie des fonctionnalités] + [SVM] + [noyau] "still cake";
- comme la perte de charnière est considérée comme assez rapide, elle peut être trouvée dans Vowpal Wabbit (par défaut).
Modifications de l'algorithme:
Il existe divers ajouts et modifications à la méthode du vecteur de support, visant à éliminer certains inconvénients:
- Machine à vecteur de pertinence (RVM)
- SVM 1 norme (LASSO SVM)
- SVM doublement régularisé (ElasticNet SVM)
- Fonctions de support Machine (SFM)
- Pertinence Caractéristiques Machine (RFM)
Sources supplémentaires sur SVM:
- Conférences textuelles par K.V. Vorontsov
- Résumés d'E. Sokolov - 14.15.16
- Source cool par Alexandre Kowalczyk
- Sur un habr il y a 2 articles consacrés à svm:
- Sur le github, je peux mettre en évidence 2 implémentations SVM sympas aux liens suivants:
Conclusion:
Merci beaucoup pour votre attention! Je serais reconnaissant pour tout commentaire, rétroaction et conseils.
Vous trouverez le code complet de cet article sur mon github .
ps Merci yorko pour des conseils sur le lissage des coins. Merci à Aleksey Sizykh - un département de physique et de technologie qui a partiellement investi dans le code.