Pour maîtriser pleinement Kubernetes, vous devez connaître les différentes façons de faire
évoluer les ressources du cluster: selon
les développeurs du système , c'est l'une des principales tâches de Kubernetes. Nous avons préparé un examen de haut niveau des mécanismes de mise à l'échelle automatique horizontale et verticale et de redimensionnement de cluster, ainsi que des recommandations sur la façon de les utiliser efficacement.
Un article de
Kubernetes Autoscaling 101: Cluster Autoscaler, Horizontal Autoscaler et Vertical Pod Autoscaler a été traduit par une équipe qui a implémenté l'
autoscaling dans
Kubernetes aaS à partir de Mail.ru.Pourquoi est-il important de penser à la mise à l'échelle
Kubernetes est un outil de gestion et d'orchestration des ressources. Bien sûr, il est agréable de bricoler avec des fonctions de déploiement, de surveillance et de gestion des pods sympas (le module pod est un groupe de conteneurs qui sont lancés en réponse à une demande).
Cependant, vous devriez penser à ces problèmes:
- Comment faire évoluer les modules et les applications?
- Comment maintenir les conteneurs opérationnels et efficaces?
- Comment répondre aux changements constants du code et des charges de travail des utilisateurs?
La configuration des clusters Kubernetes pour équilibrer les ressources et les performances peut être difficile; cela nécessite une connaissance approfondie des composants internes de Kubernetes. La charge de travail de votre application ou de vos services peut varier au cours de la journée, voire d'une heure, l'équilibrage est donc mieux représenté comme un processus continu.
Niveaux de mise à l'échelle automatique de Kubernetes
Une mise à l'échelle automatique efficace nécessite une coordination entre deux niveaux:
- Niveau du pod, y compris horizontal (horizontal Pod Autoscaler, HPA) et vertical auto-scaling (Vertical Pod Autoscaler, VPA). Cela met à l'échelle les ressources disponibles pour vos conteneurs.
- Le niveau de cluster, contrôlé par le système Cluster Autoscaler (CA), augmente ou diminue le nombre de nœuds au sein du cluster.
Module de mise à l'échelle automatique horizontale (HPA)
Comme son nom l'indique, HPA met à l'échelle le nombre de répliques de pod. Comme déclencheur pour changer le nombre de répliques, la plupart des devops utilisent le CPU et la charge mémoire. Cependant, vous pouvez faire évoluer le système en fonction de
métriques personnalisées , de leur
combinaison ou même
de métriques externes .
Flux de travail HPA de haut niveau:
- HPA vérifie en permanence les valeurs métriques spécifiées lors de l'installation avec un intervalle par défaut de 30 secondes.
- HPA essaie d'augmenter le nombre de modules si le seuil spécifié est atteint.
- HPA met à jour le nombre de répliques dans le contrôleur de déploiement / réplication.
- Le contrôleur de déploiement / réplication déploie ensuite tous les modules complémentaires requis.
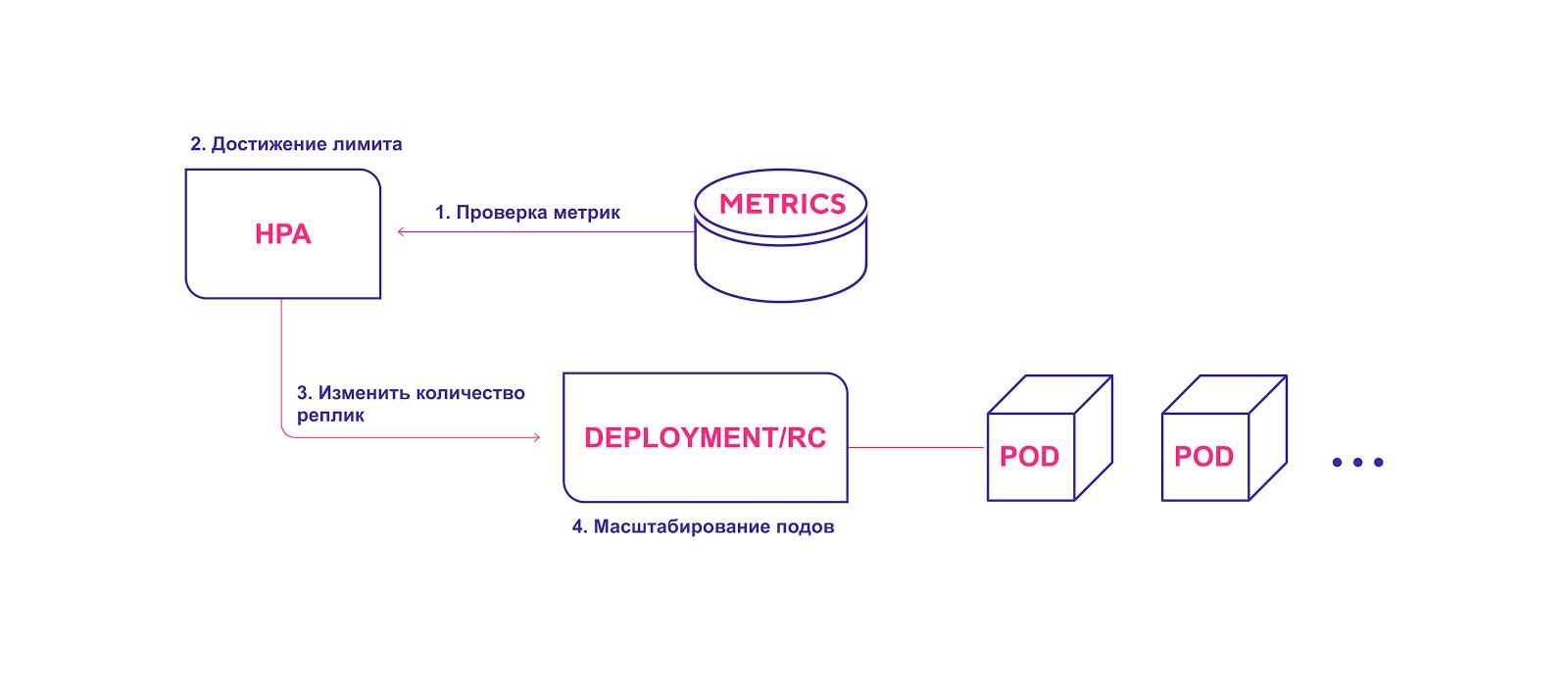 HPA lance le processus de déploiement de module lorsque le seuil de métriques est atteint
HPA lance le processus de déploiement de module lorsque le seuil de métriques est atteintLorsque vous utilisez HPA, tenez compte des éléments suivants:
- L'intervalle de validation HPA par défaut est de 30 secondes. Il est défini avec l'indicateur de période horizontale-pod-autoscaler-sync-period dans le gestionnaire de contrôleur.
- L'erreur relative par défaut est de 10%.
- Après la dernière augmentation du nombre de modules, HPA s'attend à ce que les mesures se stabilisent dans les trois minutes. Cet intervalle est défini par l'indicateur de délai horizontal-autoscaler-upscale-delay .
- Après la dernière réduction du nombre de modules, le HPA prévoit de se stabiliser pendant cinq minutes. Cet intervalle est défini avec l'indicateur de délai horizontal-autoscaler-downscale-delay .
- HPA fonctionne mieux avec les objets de déploiement, pas avec les contrôleurs de réplication. La mise à l'échelle automatique horizontale n'est pas compatible avec les mises à jour continues, qui manipulent directement les contrôleurs de réplication. Lors du déploiement, le nombre de répliques dépend directement des objets de déploiement.
Autoscaling vertical des pods
Vertical Auto Scale (VPA) alloue plus (ou moins) de temps processeur ou mémoire aux pods existants. Il convient aux pods avec ou sans état sans état, mais il est principalement destiné aux services avec état. Cependant, vous pouvez appliquer l'APV pour les modules sans état si vous devez ajuster automatiquement la quantité de ressources initialement allouées.
VPA répond également aux événements OOM (mémoire insuffisante, mémoire insuffisante). Pour modifier la durée du processeur et la taille de la mémoire, des redémarrages du pod sont nécessaires. Lors du redémarrage, l'APV respecte le
budget de distribution des pods (PDB ) pour garantir le nombre minimum de modules.
Vous pouvez définir la quantité minimale et maximale de ressources pour chaque module. Ainsi, vous pouvez limiter la quantité maximale de mémoire allouée à une limite de 8 Go. Cela est utile si les nœuds actuels ne peuvent tout simplement pas allouer plus de 8 Go de mémoire par conteneur. Les spécifications détaillées et les mécanismes de fonctionnement sont décrits dans le
wiki officiel de l'APV .
De plus, VPA a une fonction de recommandation intéressante (VPA Recommender). Il suit l'utilisation des ressources et les événements OOM de tous les modules pour offrir de nouvelles valeurs de mémoire et de temps processeur basées sur un algorithme intelligent prenant en compte les métriques historiques. Il existe également une API qui prend un descripteur de module et renvoie les valeurs de ressource proposées.
Il convient de noter que VPA Recommender ne surveille pas la "limite" des ressources. Cela peut amener le module à monopoliser les ressources au sein des nœuds. Il est préférable de définir une valeur limite au niveau de l'espace de noms pour éviter un énorme gaspillage de mémoire ou de temps processeur.
Schéma de haut niveau de l'APV:
- Le VPA vérifie en continu les valeurs métriques spécifiées lors de l'installation avec un intervalle par défaut de 10 secondes.
- Si le seuil spécifié est atteint, l'APV tente de modifier la quantité allouée de ressources.
- VPA met à jour la quantité de ressources dans le contrôleur de déploiement / réplication.
- Lorsque vous redémarrez les modules, toutes les nouvelles ressources sont appliquées aux instances créées.
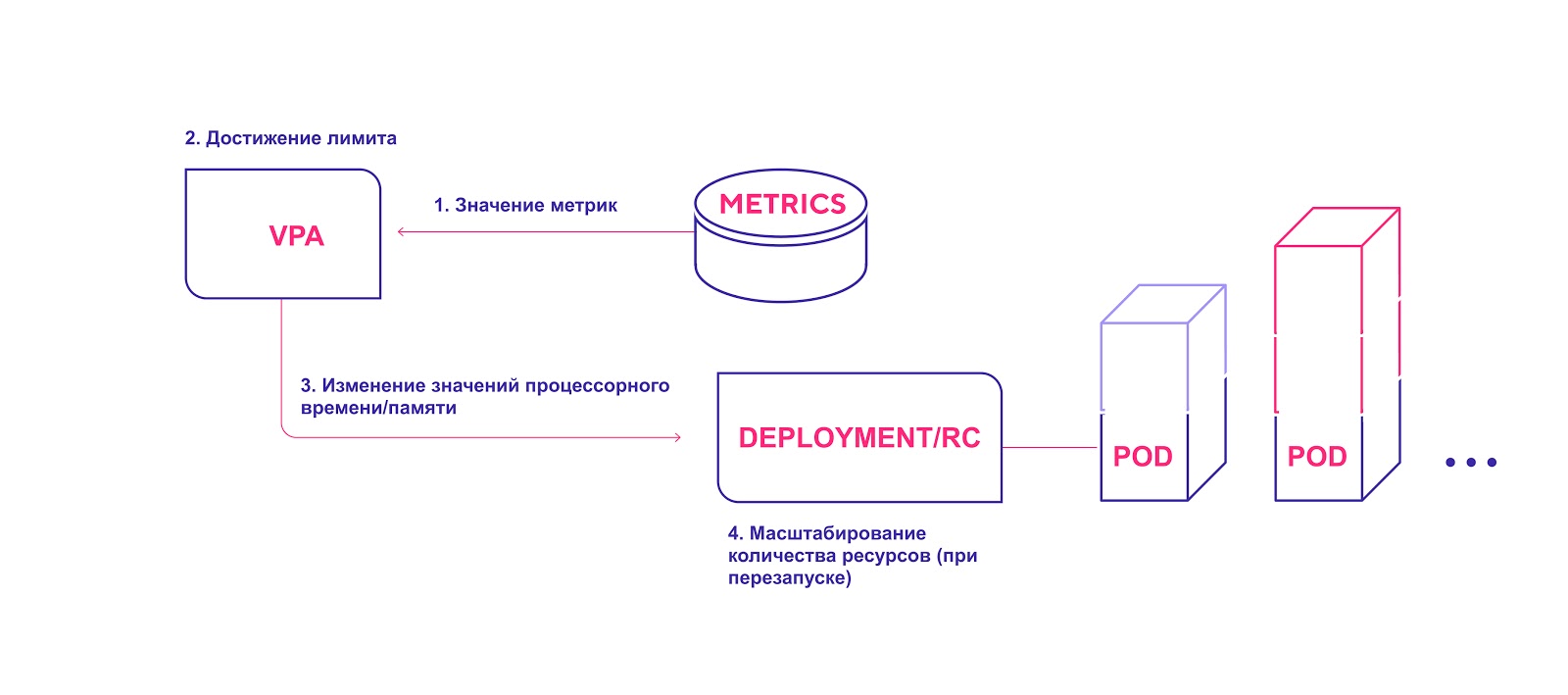 VPA ajoute la quantité requise de ressources
VPA ajoute la quantité requise de ressourcesTenez compte des points suivants lorsque vous utilisez VPA:
- La mise à l'échelle nécessite un redémarrage obligatoire du module. Cela est nécessaire pour éviter un fonctionnement instable après avoir effectué des modifications. Pour des raisons de fiabilité, les modules sont redémarrés et répartis entre les nœuds en fonction des ressources nouvellement allouées.
- VPA et HPA ne sont pas encore compatibles entre eux et ne peuvent pas fonctionner sur les mêmes pods. Si vous utilisez les deux mécanismes de mise à l'échelle dans le même cluster, assurez-vous que les paramètres ne permettront pas leur activation sur les mêmes objets.
- VPA configure les requêtes de conteneur pour les ressources en fonction uniquement de l'utilisation passée et actuelle. Il ne fixe pas de limites à l'utilisation des ressources. Il peut y avoir des problèmes avec un fonctionnement incorrect des applications qui commenceront à saisir de plus en plus de ressources, cela entraînera la désactivation de ce pod par Kubernetes.
- L'APV est encore à un stade précoce de développement. Soyez prêt à ce que, dans un proche avenir, le système puisse subir quelques modifications. Vous pouvez en savoir plus sur les limitations connues et les plans de développement . Ainsi, dans les plans de mise en œuvre du travail conjoint de VPA et HPA, ainsi que le déploiement de modules ainsi qu'une politique de mise à l'échelle verticale pour eux (par exemple, une étiquette spéciale `` nécessite VPA '').
Mise à l'échelle automatique du cluster Kubernetes
Cluster Autoscaler (CA) modifie le nombre de nœuds en fonction du nombre de pods en attente. Le système vérifie périodiquement les modules en attente - et augmente la taille du cluster si davantage de ressources sont nécessaires et si le cluster ne dépasse pas les limites établies. L'autorité de certification interagit avec le fournisseur de services cloud, lui demande des nœuds supplémentaires ou libère les nœuds inactifs. La première version publique de CA a été introduite dans Kubernetes 1.8.
Schéma de fonctionnement de haut niveau CA:
- L'autorité de certification recherche les modules en état de veille avec un intervalle par défaut de 10 secondes.
- Si un ou plusieurs modules sont en état de veille en raison des ressources insuffisantes disponibles dans le cluster pour leur distribution, il essaie de préparer un ou plusieurs nœuds supplémentaires.
- Lorsque le fournisseur de services cloud alloue le nœud requis, il rejoint le cluster et est prêt à servir les modules pod.
- Kubernetes Scheduler distribue les modules en attente à un nouvel hôte. Si après cela, certains modules restent toujours en état de veille, le processus se répète et de nouveaux nœuds sont ajoutés au cluster.
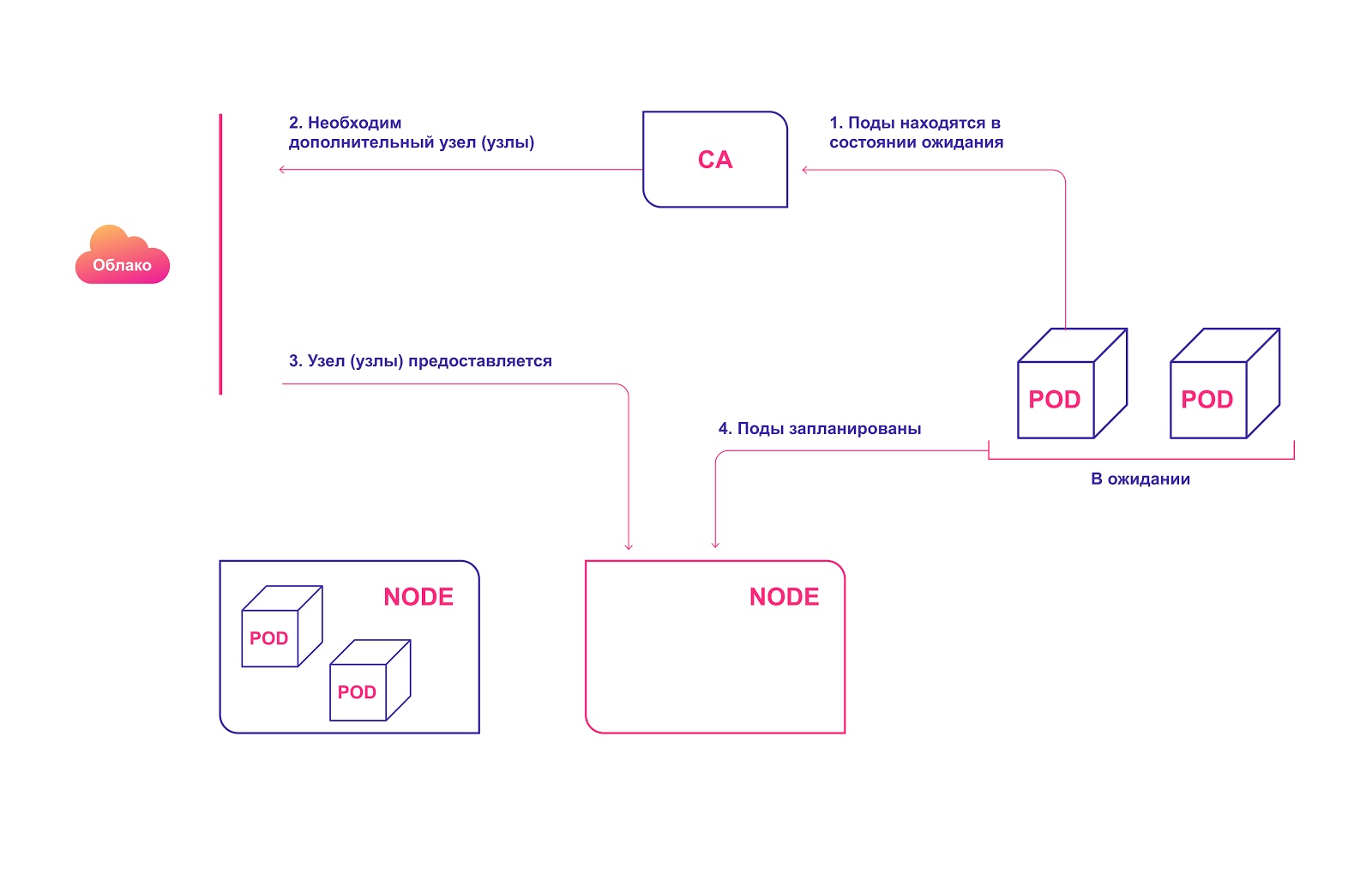 Allocation automatique des nœuds de cluster dans le cloud
Allocation automatique des nœuds de cluster dans le cloudTenez compte des éléments suivants lorsque vous utilisez CA:
- CA garantit que tous les modules du cluster ont un emplacement pour s'exécuter, quelle que soit la charge du processeur. De plus, il essaie de s'assurer qu'il n'y a pas de nœuds inutiles dans le cluster.
- L'AC enregistre le besoin de mise à l'échelle après environ 30 secondes.
- Une fois que le nœud est devenu inutile, CA attend par défaut 10 minutes avant de mettre le système à l'échelle.
- Dans le système de mise à l'échelle automatique, il y a le concept d'agrandisseurs. Ce sont différentes stratégies pour choisir un groupe de nœuds auxquels de nouveaux seront ajoutés.
- Utilisez de manière responsable l'option cluster-autoscaler.kubernetes.io/safe-to-evict (true) . Si vous installez plusieurs pods ou si beaucoup d'entre eux sont dispersés sur tous les nœuds, vous perdrez considérablement la possibilité de réduire la taille du cluster.
- Utilisez PodDisruptionBudgets pour empêcher la suppression des pods, car la partie de votre application peut échouer complètement.
Comment les systèmes de mise à l'échelle automatique de Kubernetes interagissent
Pour une harmonie parfaite, la mise à l'échelle automatique doit être appliquée à la fois au niveau du pod (HPA / VPA) et au niveau du cluster. Ils interagissent relativement simplement les uns avec les autres:
- HPA ou VPA met à jour les répliques de pods ou les ressources allouées aux pods existants.
- S'il n'y a pas suffisamment de nœuds pour la mise à l'échelle planifiée, l'autorité de certification constate la présence de pods à l'état inactif.
- CA alloue de nouveaux nœuds.
- Les modules sont distribués à de nouveaux nœuds.
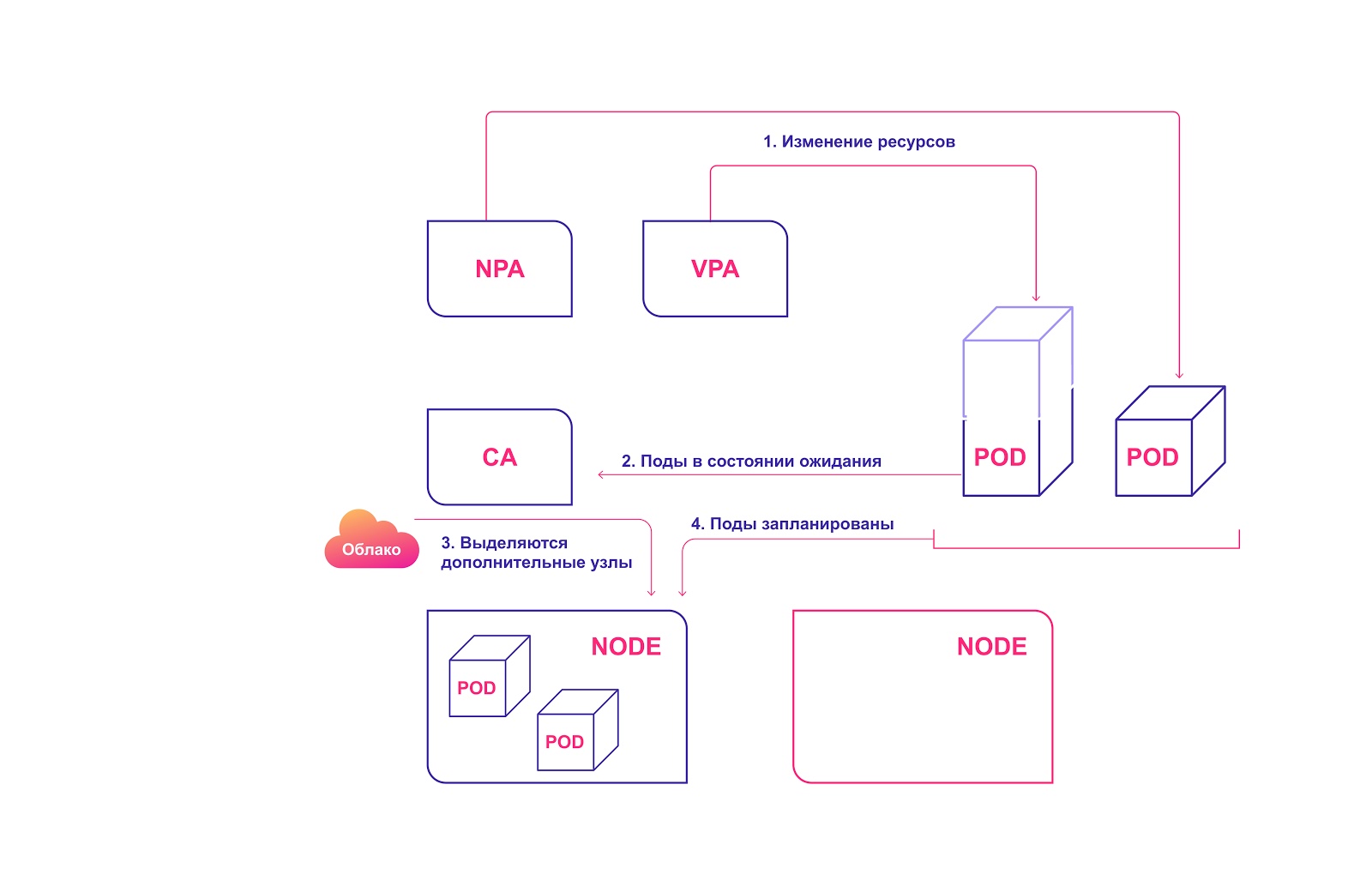 Système de mise à l'échelle collaborative Kubernetes
Système de mise à l'échelle collaborative KubernetesErreurs courantes de mise à l'échelle automatique de Kubernetes
Les développeurs rencontrent plusieurs problèmes typiques lorsqu'ils essaient d'appliquer la mise à l'échelle automatique.
HPA et VPA dépendent des métriques et de certaines données historiques. Si des ressources insuffisantes sont allouées, les modules seront réduits et ne pourront pas générer de métriques. Dans ce cas, la mise à l'échelle automatique n'aura jamais lieu.
L'opération de mise à l'échelle elle-même est sensible au temps. Nous voulons que les modules et le cluster évoluent rapidement - avant que les utilisateurs ne remarquent des problèmes ou des échecs. Par conséquent, le temps de mise à l'échelle moyen des modules et du cluster doit être pris en compte.
Scénario idéal - 4 minutes:
- 30 secondes Mise à jour des mesures cibles: 30 à 60 secondes.
- 30 secondes HPA vérifie les valeurs métriques: 30 secondes.
- Moins de 2 secondes. Les modules pod sont créés et passent en état de veille: 1 seconde.
- Moins de 2 secondes. L'autorité de certification voit les modules en attente et envoie des appels pour préparer les nœuds: 1 seconde.
- 3 minutes Le fournisseur de cloud alloue des nœuds. Les K8 attendent jusqu'à ce qu'ils soient prêts: jusqu'à 10 minutes (dépend de plusieurs facteurs).
Pire (plus réaliste) scénario - 12 minutes:
- 30 secondes Mise à jour des métriques cibles.
- 30 secondes HPA valide les valeurs métriques.
- Moins de 2 secondes. Les modules pod sont créés et passent en état de veille.
- Moins de 2 secondes. CA voit les modules en attente et envoie des appels pour préparer les nœuds.
- 10 minutes Le fournisseur de cloud alloue des nœuds. Les K8 attendent jusqu'à ce qu'ils soient prêts. Le temps d'attente dépend de plusieurs facteurs, comme le retard du fournisseur, le retard de l'OS, le travail des outils auxiliaires.
Ne confondez pas les mécanismes de mise à l'échelle des fournisseurs de cloud avec notre autorité de certification. Ce dernier fonctionne à l'intérieur du cluster Kubernetes, tandis que le mécanisme du fournisseur de cloud fonctionne sur la base de l'allocation des nœuds. Il ne sait pas ce qui se passe avec vos pods ou votre application. Ces systèmes fonctionnent en parallèle.
Comment gérer la mise à l'échelle dans Kubernetes
- Kubernetes est un outil de gestion et d'orchestration des ressources. Les opérations de pod de cluster et de gestion des ressources sont une étape clé dans le développement de Kubernetes.
- Découvrez la logique d'évolutivité des pods pour HPA et VPA.
- L'AC ne doit être utilisé que si vous comprenez bien les besoins de vos dosettes et conteneurs.
- Pour une configuration de cluster optimale, vous devez comprendre comment les différents systèmes de mise à l'échelle fonctionnent ensemble.
- Lors de l'évaluation des temps de mise à l'échelle, gardez à l'esprit les pires et les meilleurs scénarios.