Cet article présentera le projet nginx-log-collector , qui lira les journaux nginx et les enverra au cluster Clickhouse. Généralement, pour les journaux, utilisez ElasticSearch. Clickhouse nécessite moins de ressources (espace disque, RAM, CPU). Clickhouse enregistre les données plus rapidement. Clickhouse compresse les données, ce qui rend les données sur disque encore plus compactes. Les avantages de Clickhouse sont visibles dans 2 diapositives du rapport Comment VK insère des données dans ClickHouse à partir de dizaines de milliers de serveurs.


Pour afficher l'analyse des journaux, créez un tableau de bord pour Grafana.
Peu importe, bienvenue au chat.
Installez nginx, grafana de la manière standard.
Installez le cluster clickhouse en utilisant ansible-playbook par Denis Proskurin .
Création de bases de données et de tables dans Clickhouse
Ce fichier décrit les requêtes SQL pour créer des bases de données et des tables pour nginx-log-collector dans Clickhouse.
Nous faisons chaque demande tour à tour sur chaque serveur du cluster Clickhouse.
Remarque importante. Sur cette ligne, logs_cluster doit être remplacé par le nom de votre cluster à partir du fichier clickhouse_remote_servers.xml entre "remote_servers" et "shard".
ENGINE = Distributed('logs_cluster', 'nginx', 'access_log_shard', rand())
Installation et configuration de nginx-log-collector-rpm
Nginx-log-collector n'a pas de tr / min. Ici https://github.com/patsevanton/nginx-log-collector-rpm créez un rpm pour cela. Les RPM seront collectés à l' aide de Fedora Copr
Installez le package rpm nginx-log-collector-rpm
yum -y install yum-plugin-copr yum copr enable antonpatsev/nginx-log-collector-rpm yum -y install nginx-log-collector systemctl start nginx-log-collector
Modifiez la configuration /etc/nginx-log-collector/config.yaml:
....... upload: table: nginx.access_log dsn: http://ip---clickhouse:8123/ - tag: "nginx_error:" format: error # access | error buffer_size: 1048576 upload: table: nginx.error_log dsn: http://ip---clickhouse:8123/
Configuration de Nginx
Configuration générale de nginx:
user nginx; worker_processes auto;
L'hôte virtuel en est un:
vhost1.conf:
upstream backend { server ip----stub_http_server:8080; server ip----stub_http_server:8080; server ip----stub_http_server:8080; server ip----stub_http_server:8080; server ip----stub_http_server:8080; } server { listen 80; server_name vhost1; location / { proxy_pass http://backend; } }
Ajoutez des hôtes virtuels au fichier / etc / hosts:
ip----nginx vhost1
Émulateur de serveur HTTP
En tant qu'émulateur de serveur HTTP, nous utiliserons nodejs-stub-server de Maxim Ignatenko
Nodejs-stub-server n'a pas de rpm. Ici https://github.com/patsevanton/nodejs-stub-server créez un rpm pour cela. Les RPM seront collectés à l' aide de Fedora Copr
Installer le package nodejs-stub-server sur le rpm nginx en amont
yum -y install yum-plugin-copr yum copr enable antonpatsev/nodejs-stub-server yum -y install stub_http_server systemctl start stub_http_server
Test de charge
Tests effectués à l'aide du benchmark Apache.
Installez-le:
yum install -y httpd-tools
Nous commençons à tester en utilisant Apache benchmark à partir de 5 serveurs différents:
while true; do ab -H "User-Agent: 1server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 2server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 3server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 4server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 5server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done
Configuration de Grafana
Sur le site officiel de Grafana, vous ne trouverez pas de tableau de bord.
Par conséquent, nous allons le remettre.
Vous pouvez trouver mon tableau de bord enregistré ici .
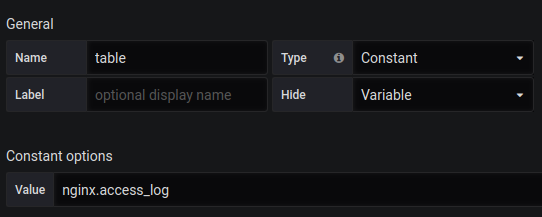
Vous devez également créer une variable de table avec le contenu de nginx.access_log .
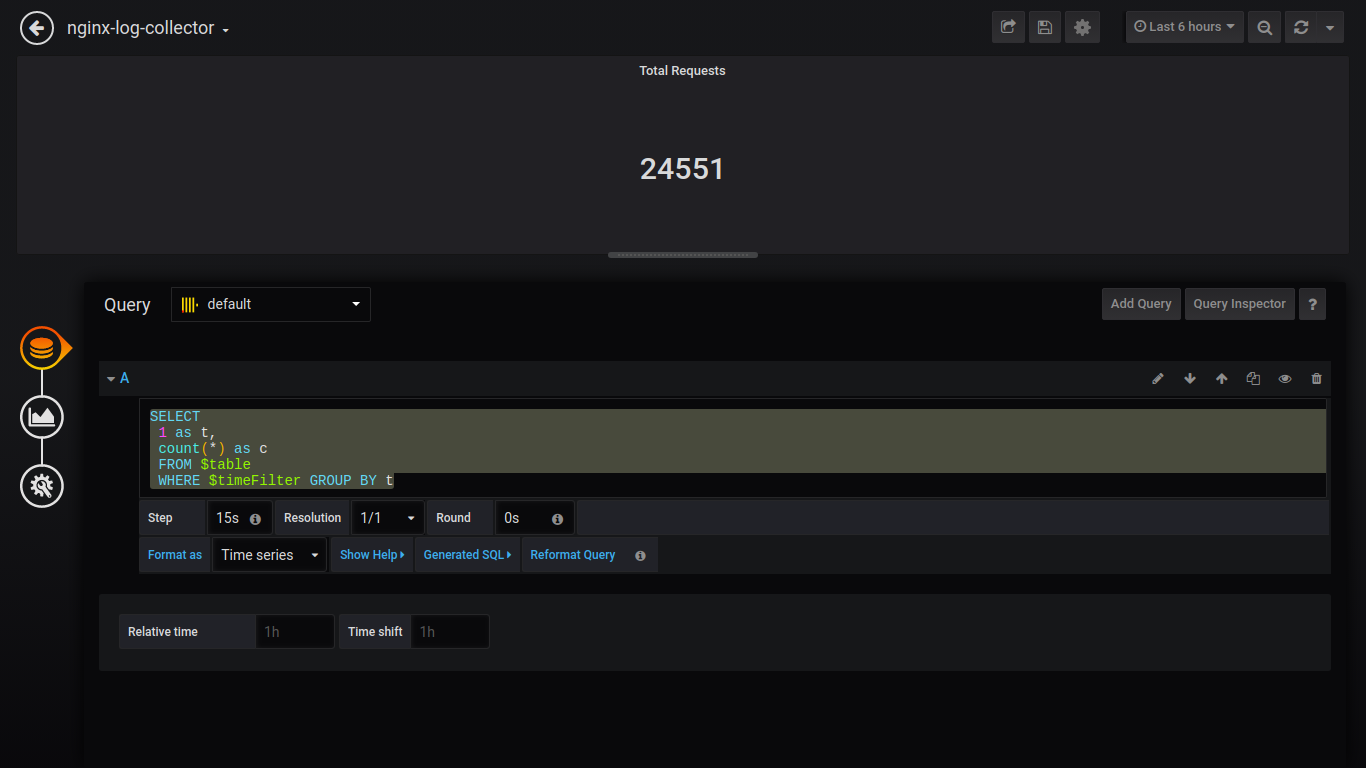
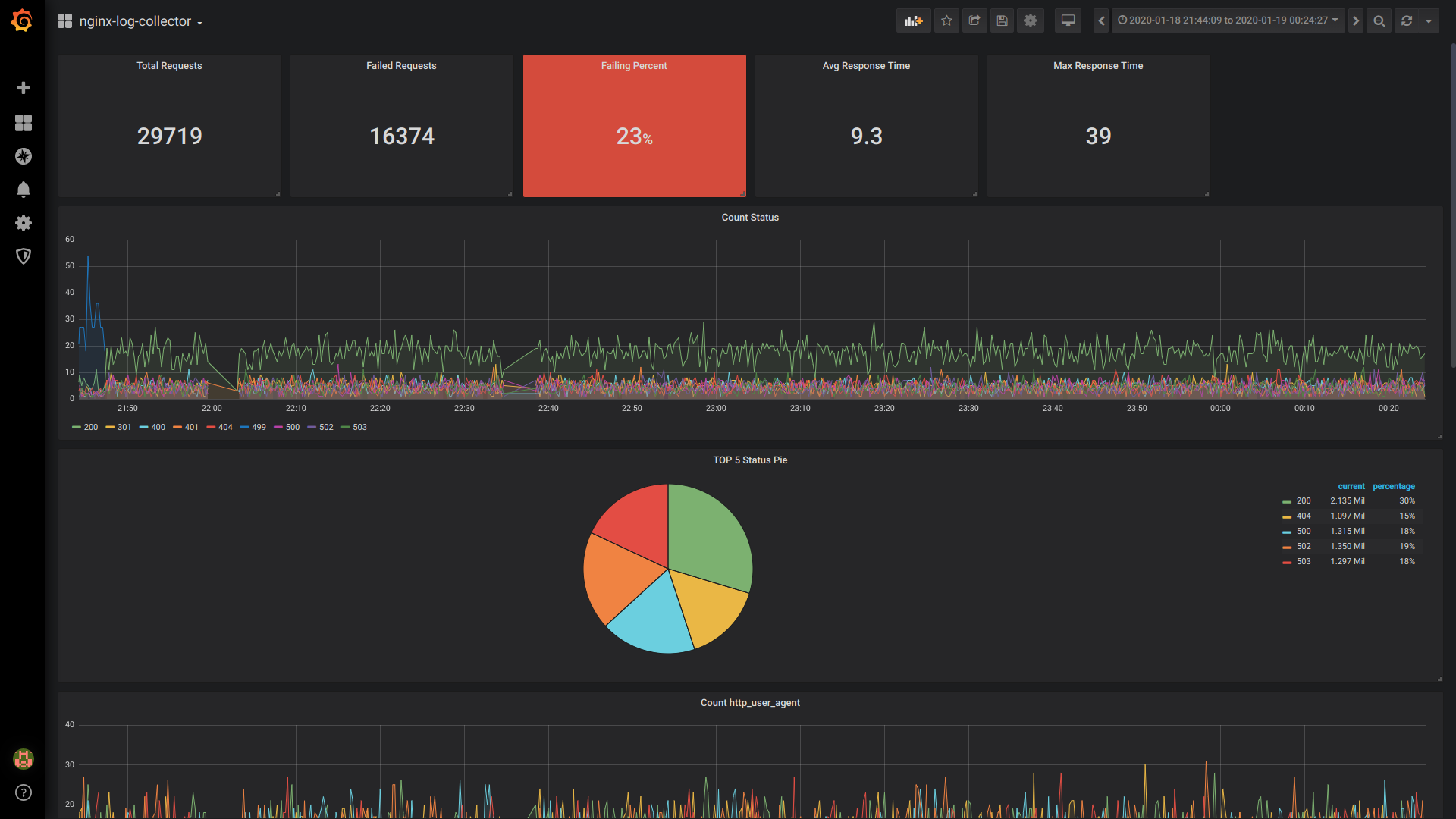
Nombre total de demandes simples:
SELECT 1 as t, count(*) as c FROM $table WHERE $timeFilter GROUP BY t
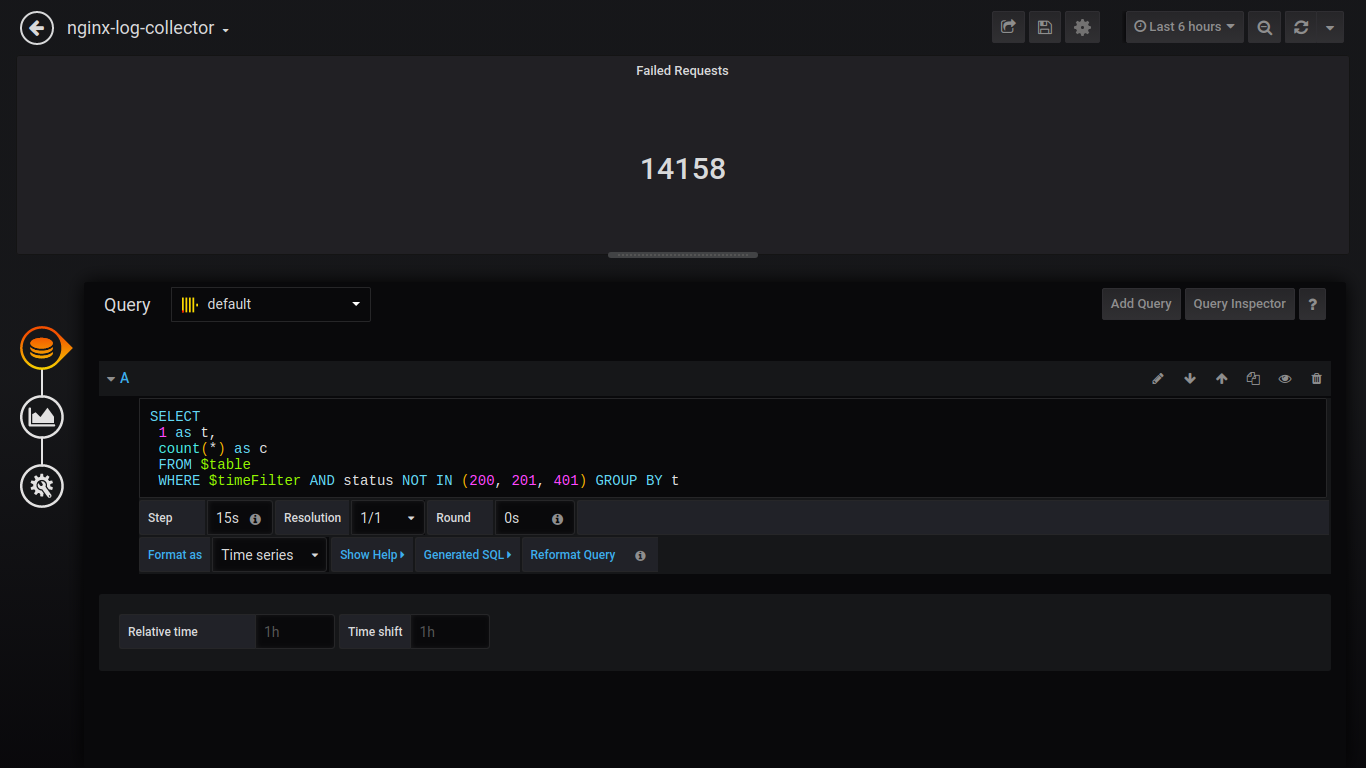
Demandes en échec de Singlestat:
SELECT 1 as t, count(*) as c FROM $table WHERE $timeFilter AND status NOT IN (200, 201, 401) GROUP BY t
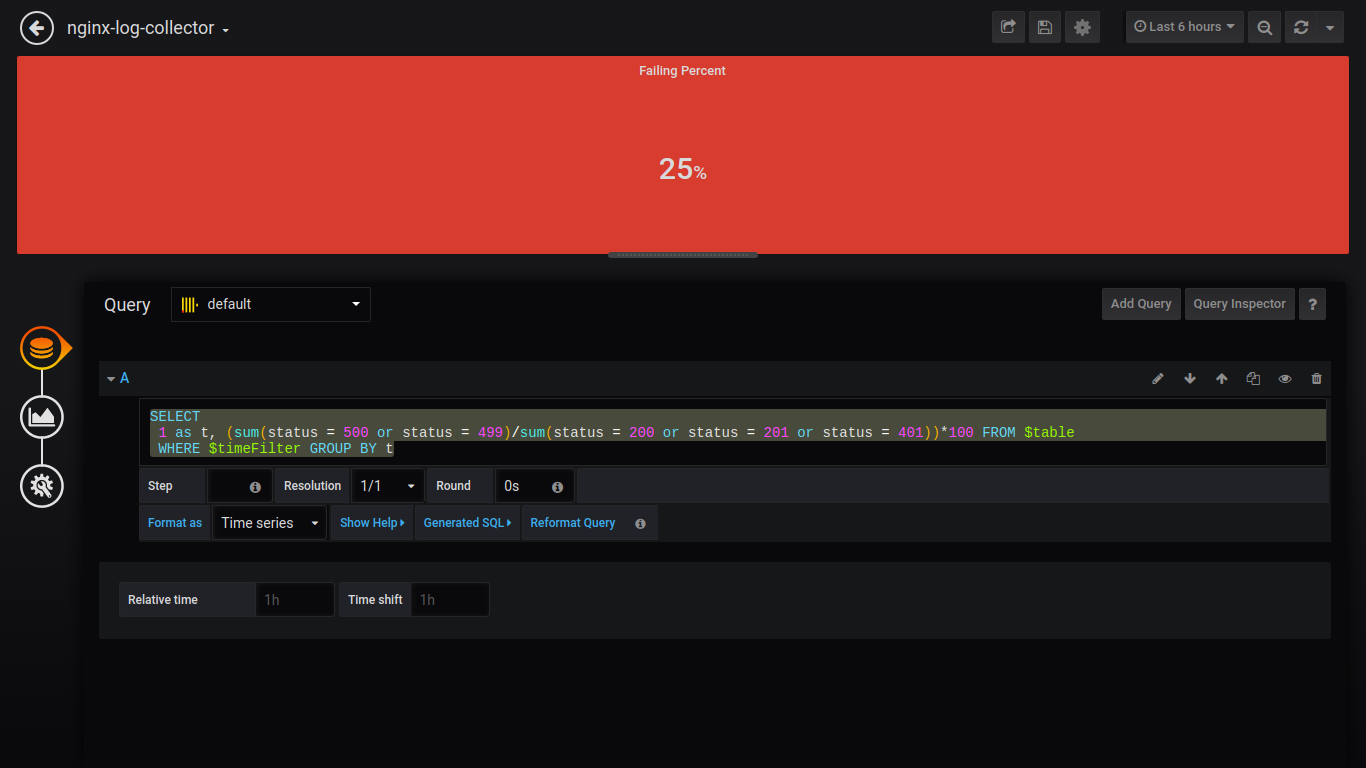
Pourcentage d'échec de singlestat:
SELECT 1 as t, (sum(status = 500 or status = 499)/sum(status = 200 or status = 201 or status = 401))*100 FROM $table WHERE $timeFilter GROUP BY t
Temps de réponse moyen de Singlestat:
SELECT 1, avg(request_time) FROM $table WHERE $timeFilter GROUP BY 1
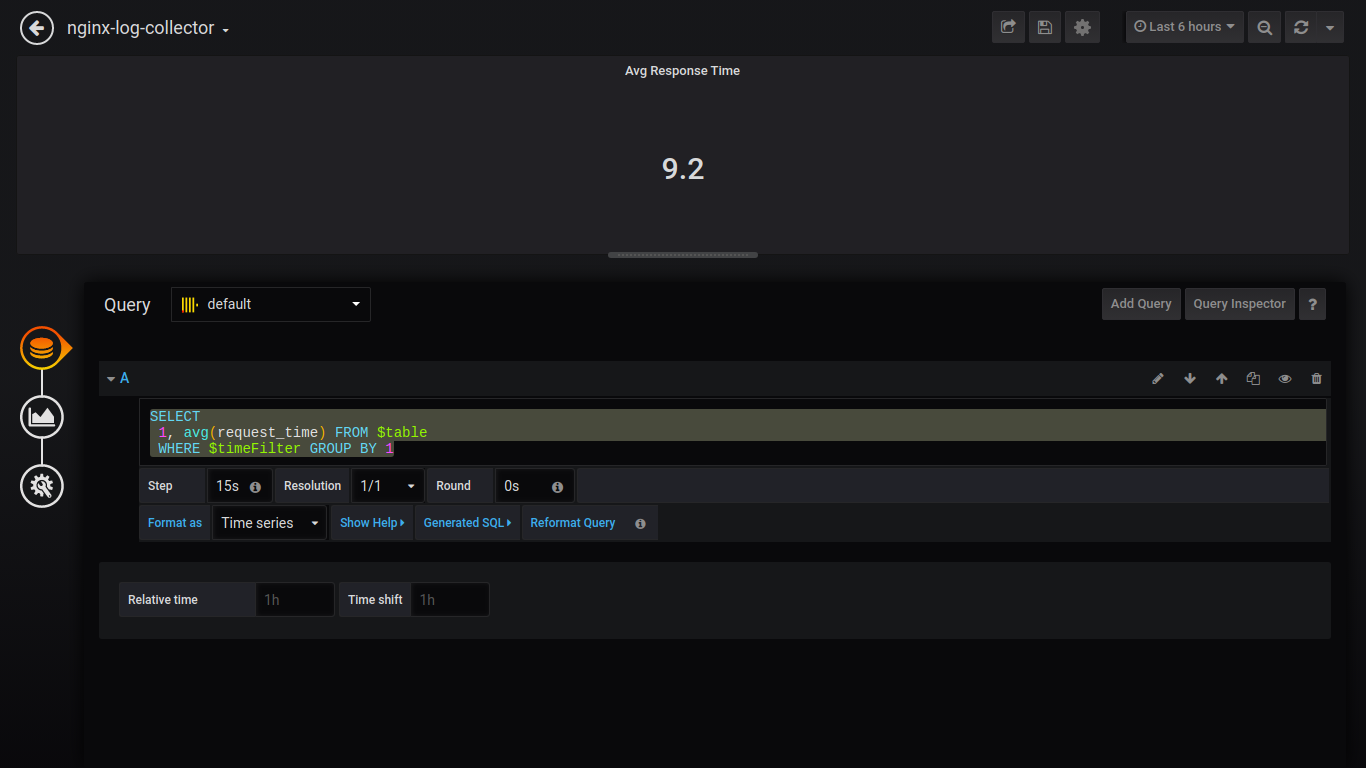
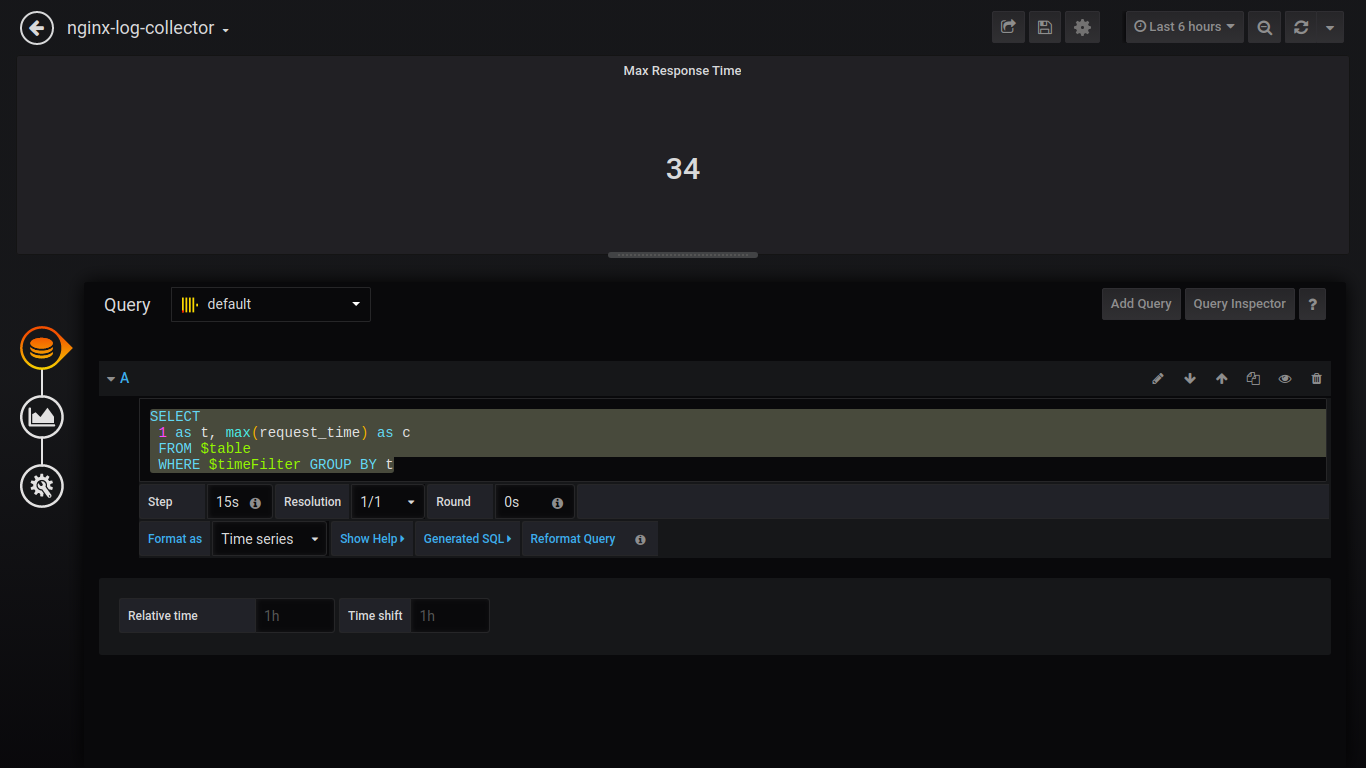
Temps de réponse maximum de Singlestat:
SELECT 1 as t, max(request_time) as c FROM $table WHERE $timeFilter GROUP BY t
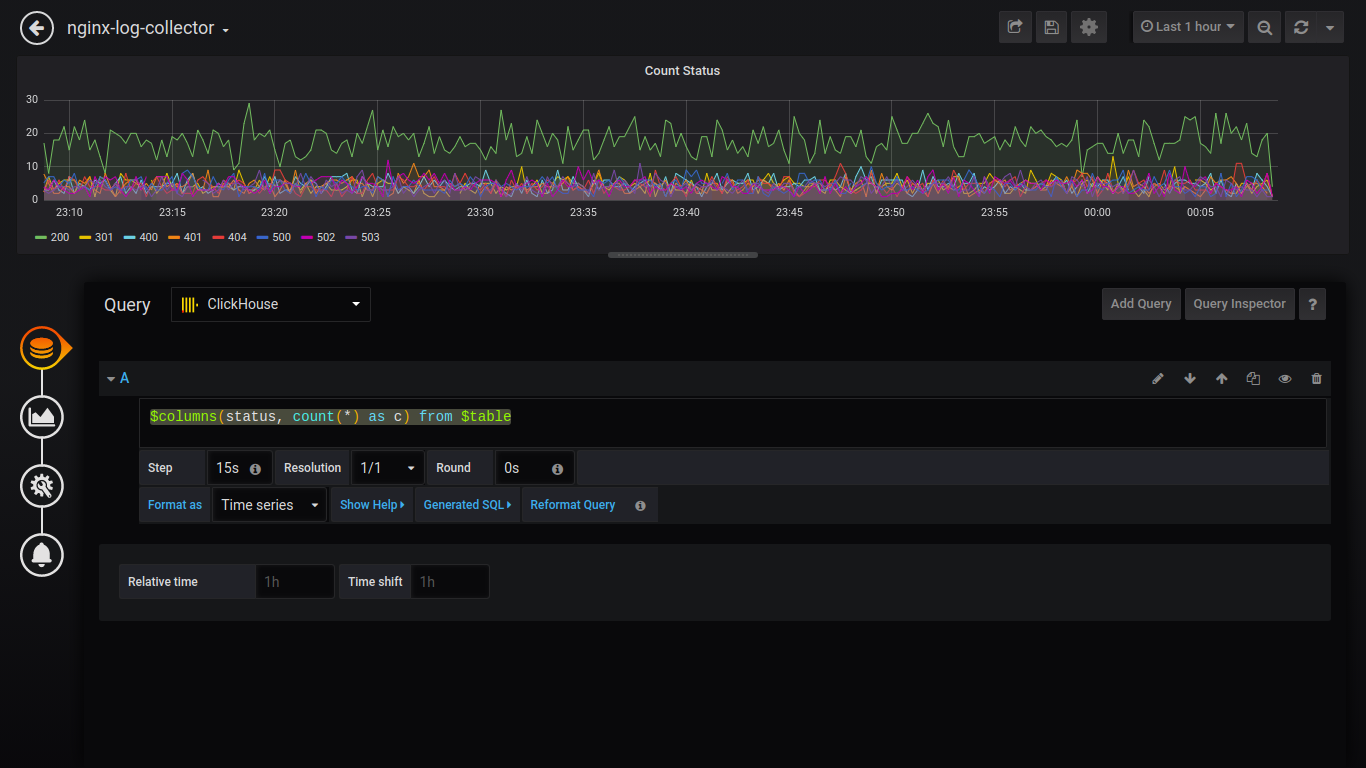
Statut du décompte:
$columns(status, count(*) as c) from $table
Pour sortir les données sous forme de tarte, vous devez installer le plugin et redémarrer grafana.
grafana-cli plugins install grafana-piechart-panel service grafana-server restart
Pie TOP 5 Statut:
SELECT 1, status, sum(status) AS Reqs FROM $table WHERE $timeFilter GROUP BY status ORDER BY Reqs desc LIMIT 5
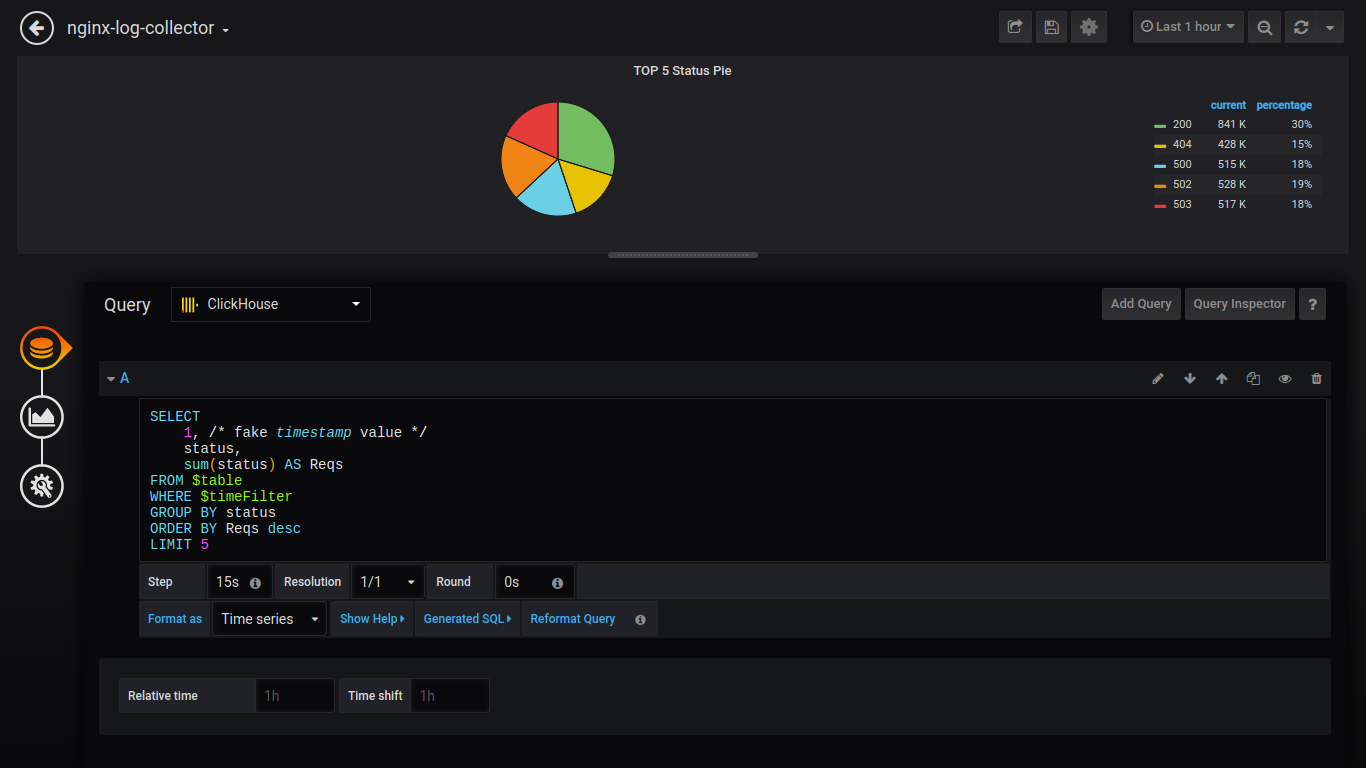
De plus, je donnerai des demandes sans captures d'écran:
Comptez http_user_agent:
$columns(http_user_agent, count(*) c) FROM $table
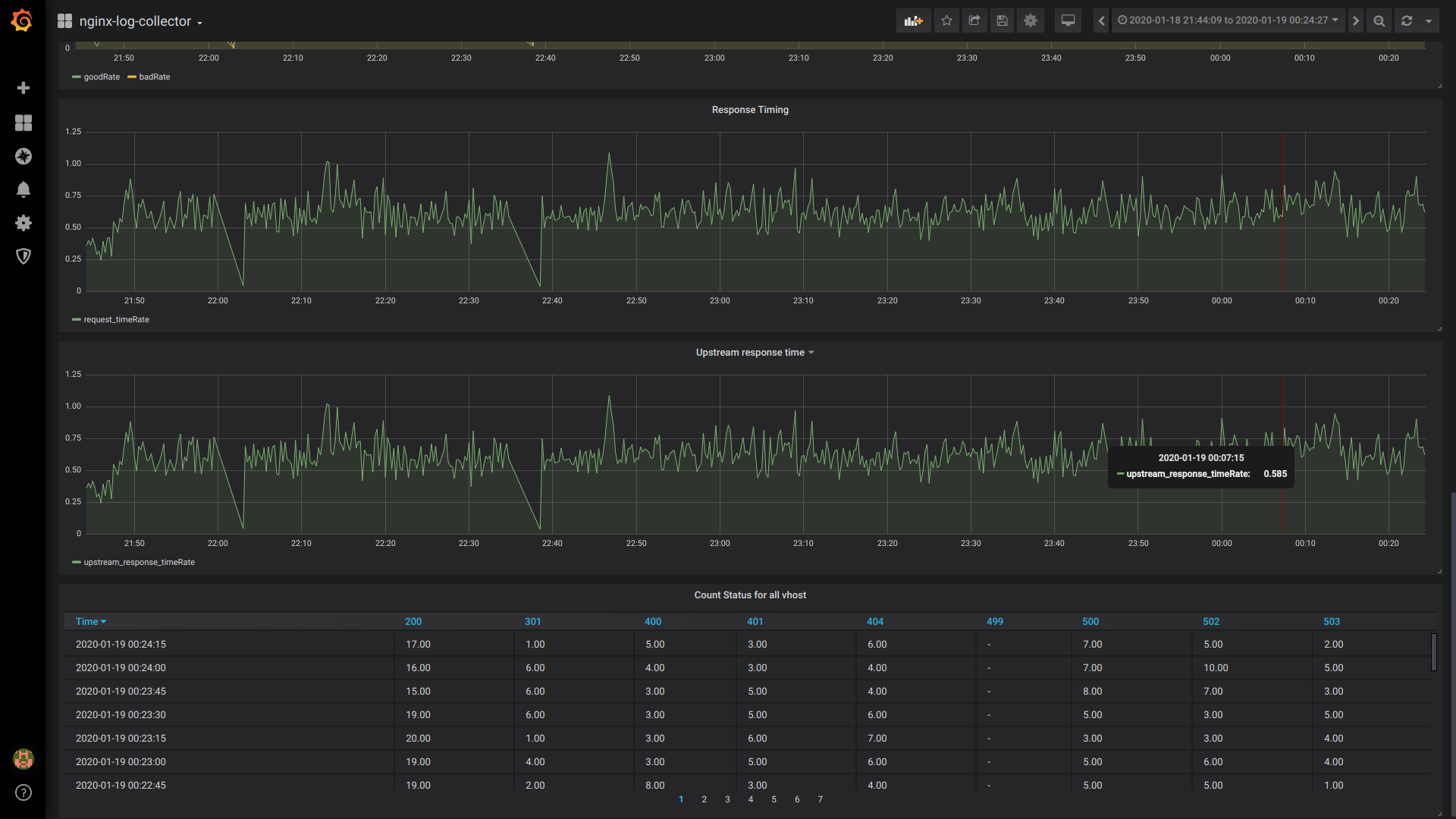
GoodRate / BadRate:
$rate(countIf(status = 200) AS good, countIf(status != 200) AS bad) FROM $table
Délai de réponse:
$rate(avg(request_time) as request_time) FROM $table
Temps de réponse en amont (temps de réponse du 1er en amont):
$rate(avg(arrayElement(upstream_response_time,1)) as upstream_response_time) FROM $table
État du nombre de tables pour tous les vhost:
$columns(status, count(*) as c) from $table
Vue générale du tableau de bord

Comparaison de avg () et quantile ()
avg ()

quantile ()

Conclusion:
J'espère que la communauté s'impliquera dans le développement / test et l'utilisation de nginx-log-collector.
Et quelqu'un, quand il implémentera nginx-log-collector, vous dira combien il a économisé le disque, la RAM, le CPU.
Chaînes de télégramme:
Millisecondes:
Pour qui les millisecondes sont importantes, écrivez ou votez, s'il vous plaît, dans ce numéro .