Si vous écrivez
des requêtes SQL sans analyser l'algorithme qu'elles doivent implémenter, cela ne mène généralement à rien de bon en termes de performances.
De telles demandes
aiment «consommer» du temps processeur et lire activement les données presque à l'improviste. De plus, ce n'est pas nécessairement une sorte de requête complexe, au contraire - plus elle est simple, plus les chances de problèmes sont grandes. Et si l'opérateur JOIN entre en jeu ...
En soi, joindre des tables n'est ni nuisible ni utile - c'est juste un outil, mais vous devez pouvoir l'utiliser.
Groupement de surveillance
Prenons d'abord un exemple très simple.
Il existe un «dictionnaire» de 100 entrées (par exemple, il s'agit des régions de la Fédération de Russie):
CREATE TABLE tbl_dict AS SELECT generate_series(0, 100) k; ALTER TABLE tbl_dict ADD PRIMARY KEY(k);
... et y est attaché un tableau des «faits» connexes pour 100 000 entrées:
CREATE TABLE tbl_fact AS SELECT (random() * 100)::integer k , (random() * 1000)::integer v FROM generate_series(1, 100000); CREATE INDEX ON tbl_fact(k);
Essayons maintenant de calculer la somme des valeurs pour chaque "région".
Comme on l'entend, il est écrit
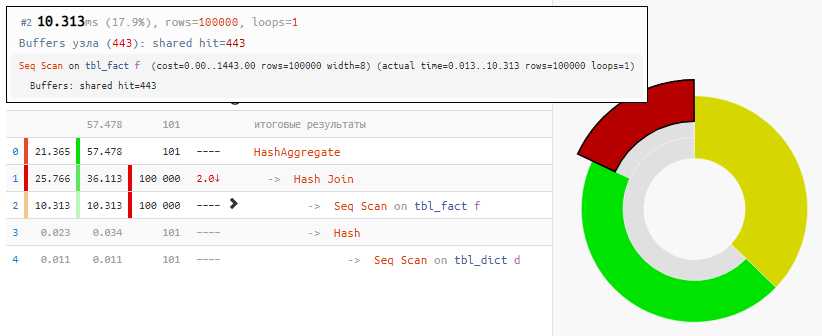
SELECT dk , sum(fv) FROM tbl_fact f NATURAL JOIN tbl_dict d GROUP BY 1;
La lecture des données elles-mêmes ne prenait que 18% du temps, le reste était en cours de traitement:
 [regardez expliquez.tensor.ru]
[regardez expliquez.tensor.ru]Et tout cela parce que Hash Join et Hash Aggregate ont dû traiter 100 000 enregistrements chacun en raison de notre désir de
regrouper par champ de la table liée .
Nous utilisons l'ingéniosité
Mais la valeur de ce champ est égale à la valeur du champ dans la table agrégée! Autrement dit, personne ne nous dérange pour
regrouper d'abord les «faits», et ensuite seulement établir un lien :
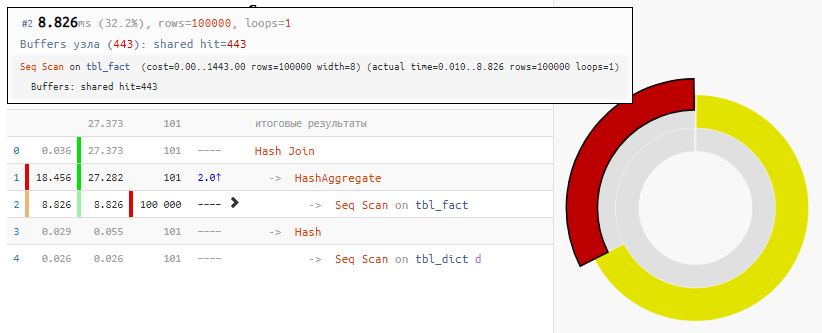
SELECT dk , f.sum FROM ( SELECT k , sum(v) FROM tbl_fact GROUP BY 1 ) f NATURAL JOIN tbl_dict d;
 [regardez expliquez.tensor.ru]
[regardez expliquez.tensor.ru]Bien sûr, la méthode n'est pas universelle, mais pour notre cas de la "jointure habituelle"
, le gain de temps est 2 fois avec une modification minimale de la demande - simplement en raison de la jointure de hachage "annulée", qui n'a reçu que 100 entrées au lieu de 100K entrées.
Conditions inégales
Maintenant, compliquons la tâche: nous avons 3 tables reliées par un identifiant - la principale et deux tables auxiliaires avec des données d'application, par lesquelles nous filtrerons.
Une petite remarque mais très importante: même si sur la base d'une connaissance «appliquée» de la tâche cible, nous savons déjà que les conditions seront remplies
sur la première table - presque toujours (pour la précision - 3: 4), et
sur la seconde - très rarement (1: 8 )
Nous voulons sélectionner dans les tables principale et première auxiliaire les
100 premiers enregistrements par identifiant avec des valeurs d'identifiant pair pour lesquelles les
conditions sur toutes les tables sont remplies . Tous les enregistrements dans les tableaux, revenons à 100K.
Générateur de scripts CREATE TABLE base( id integer PRIMARY KEY , val integer ); INSERT INTO base SELECT id , (random() * 1000)::integer FROM generate_series(1, 100000) id; CREATE TABLE ext1( id integer PRIMARY KEY , conda boolean ); INSERT INTO ext1 SELECT id , (random() * 4)::integer <> 0
Comme on l'entend, il est écrit
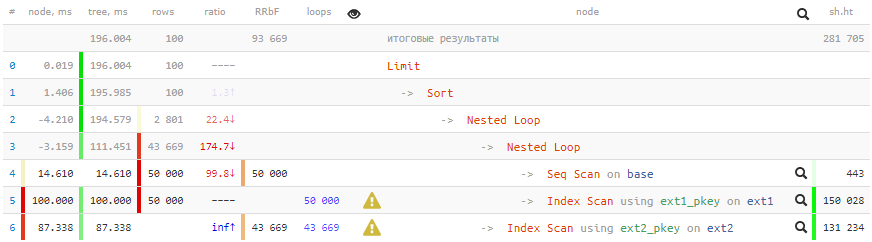
SELECT base.* , ext1.* FROM base NATURAL JOIN ext1 NATURAL JOIN ext2 WHERE id % 2 = 0 AND conda AND condb ORDER BY base.id LIMIT 100;
 [regardez expliquez.tensor.ru]
[regardez expliquez.tensor.ru]Temps négatifs en termesTant de cycles ont traversé certains nœuds que les erreurs d'arrondi de certains ont même été transformées en inconvénients. À peu près des artefacts similaires dans les plans, je parlerai de
PGConf.Russia .
200 ms et plus 2 Go de données pompés - pas très bon pour 100 enregistrements!
Nous utilisons l'ingéniosité
Nous utilisons les approches suivantes pour réaliser l'accélération:
- Pour commencer, nous comprenons qu'il est logique pour nous de vérifier toutes les conditions pour les tables liées uniquement si les conditions pour la table principale sont remplies (pour l'id pair).
- La sortie doit être triée par base.id, et pour cela, la clé primaire de cette table est parfaite pour nous!
- Nous n'avons pas besoin de données d'ext2 et ne sommes utilisés que pour vérifier la condition. Cela signifie que tout travail avec cette table peut être supprimé en toute sécurité de la jointure à la partie WHERE . Et utilisez EXISTS pour vérifier, sinon que faire s'il n'y a aucun enregistrement de ce type?
- Nous devons récupérer au moins certaines données de ext1 uniquement si les vérifications restantes sur base et ext2 sont réussies . Autrement dit, la connexion avec ext1 devrait aller après toutes les actions avec base / ext2, qui peuvent être réalisées en utilisant LATERAL.
- Pour que le planificateur de requêtes n'essaye pas de transformer la vérification imbriquée sur ext2 en JOIN, la sous- requête "masquer sous CASE" .
SELECT base.* , ext1.* FROM base , LATERAL(
 [regardez expliquez.tensor.ru]
[regardez expliquez.tensor.ru]La demande, bien sûr, est devenue plus compliquée, mais
gagner 13 fois dans le temps et 350 en "gourmandise" en vaut la peine!
Permettez-moi de vous rappeler à nouveau que toutes les méthodes ne sont pas utilisées et pas toujours, mais savoir ne sera pas superflu.Ce sera également intéressant: