 De nombreux programmeurs pensent que le tri rapide est l'algorithme le plus rapide de tous. C'est en partie vrai. Mais cela ne fonctionne vraiment bien que si l'élément de support est correctement sélectionné ( alors la complexité est O (n log n) ). Sinon, le comportement asymptotique sera approximativement le même que celui de la bulle ( c'est-à-dire O (n 2 ) ).
De nombreux programmeurs pensent que le tri rapide est l'algorithme le plus rapide de tous. C'est en partie vrai. Mais cela ne fonctionne vraiment bien que si l'élément de support est correctement sélectionné ( alors la complexité est O (n log n) ). Sinon, le comportement asymptotique sera approximativement le même que celui de la bulle ( c'est-à-dire O (n 2 ) ).
Dans le même temps, si le tableau est déjà trié, l'algorithme ne fonctionnera toujours pas plus vite que O (n log n)
Sur cette base, j'ai décidé d'écrire mon propre algorithme pour trier un tableau qui fonctionnerait mieux que quick_sort. Et si le tableau est déjà trié, ne l'exécutez pas plusieurs fois, comme c'est le cas avec de nombreux algorithmes.
«C'était le soir, il n'y avait rien à faire», - Sergei Mikhalkov.
Prérequis:
- Meilleur cas O (n)
- Le cas moyen d' O (n log n)
- Pire cas O (n log n)
- En moyenne plus rapide que le tri rapide
Pour comprendre le sujet, vous devez savoir: Maintenant, mettons tout en ordre
Pour que notre algorithme fonctionne toujours rapidement, il est nécessaire que dans le cas moyen le comportement asymptotique soit au moins O (n log n), et au mieux O (n). Nous savons tous très bien que, au mieux, le tri par insertion fonctionne en une seule fois. Mais au pire, elle devra faire le tour du tableau autant de fois qu'il y aura d'éléments.
Informations préliminaires
La fonction de fusion de deux tableauxint* glue(int* a, int lenA, int* b, int lenB) { int lenC = lenA + lenB; int* c = new int[lenC];
La fonction de fusion de deux tableaux, enregistre le résultat dans le spécifié. void glueDelete(int*& arr, int*& a, int lenA, int*& b, int lenB) { if (lenA == 0) {
Une fonction qui rend le tri par insertions entre lo et hi void insertionSort(int*& arr, int lo, int hi) { for (int i = lo + 1; i <= hi; ++i) for (int j = i; j > 0 && arr[j - 1] > arr[j]; --j) swap(arr[j - 1], arr[j]); }
L'idée principale de l'algorithme est la soi-disant recherche de maximum (et minimum). À chaque itération, sélectionnez un élément dans le tableau. S'il est supérieur au maximum précédent, ajoutez cet élément à la fin de la sélection. Sinon, s'il est inférieur au minimum précédent, nous ajoutons cet élément au début. Sinon, placez-les dans un tableau séparé.
La fonction d'entrée prend un tableau et le nombre d'éléments dans ce tableau
void FirstNewGeneratingSort(int*& arr, int len)
Pour stocker un échantillon du tableau (nos hauts et bas) et d'autres éléments, nous allouons de la mémoire
int* selection = new int[len << 1];
Comme vous pouvez le voir, nous avons alloué 2 fois plus de mémoire pour stocker l'échantillon que notre tableau d'origine. Cela se fait dans le cas où nous avons un tableau trié et chaque élément suivant sera un nouveau maximum. Ensuite, seule la deuxième partie du tableau d'échantillons sera occupée. Ou vice versa (si triés par ordre décroissant).
Pour échantillonner, vous avez d'abord besoin du minimum et du maximum initiaux. Sélectionnez simplement les premier et deuxième éléments
if (arr[0] > arr[1]) swap(arr[0], arr[1]); selection[left--] = arr[0]; selection[right++] = arr[1];
L'échantillonnage lui-même
for (int i = 2; i < len; ++i) { if (selection[right - 1] <= arr[i])
Nous avons maintenant un ensemble d'éléments triés et les éléments «restants» que nous devons encore trier. Mais vous devez d'abord faire quelques manipulations de mémoire.
Libérez de la mémoire inutilisée
int selectionLen = right - left - 1;
Faire un appel de tri récursif pour les éléments restants et les fusionner avec la sélection
FirstNewGeneratingSort(restElements, restLen); glueDelete(arr, selection, selectionLen, restElements, restLen);
Tous les codes d'algorithme (version non optimale) void FirstNewGeneratingSort(int*& arr, int len) { if (len < 2) return; int* selection = new int[len << 1]; int left = len - 1; int right = len; int* restElements = new int[len]; int restLen = 0; if (arr[0] > arr[1]) swap(arr[0], arr[1]); selection[left--] = arr[0]; selection[right++] = arr[1]; for (int i = 2; i < len; ++i) { if (selection[right - 1] <= arr[i])
Vérifions la vitesse de l'algorithme par rapport au tri rapide
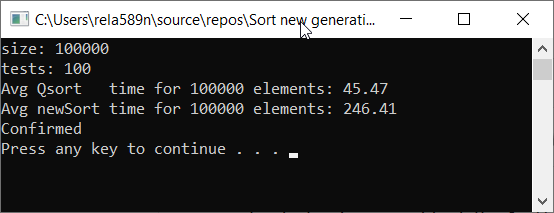
Comme vous pouvez le voir, ce n'est pas du tout ce que nous voulions. Presque 6 fois plus longtemps que QuickSort! Mais les temps dans ce contexte sont inappropriés à utiliser, car ici c'est l'asymptotique qui compte. Dans cette implémentation de l'algorithme, dans le pire des cas, les premier et deuxième éléments seront minimum et maximum. Et le reste sera copié dans un tableau séparé.
Complexité de l'algorithme:
- Pire cas: O (n 2 )
- Cas du milieu: O (n 2 )
- Meilleur cas: O (n)
Hmm, ce n'est pas mieux que le même tri par inserts. Oui, en effet, nous pouvons trouver l'élément maximum (minimum) très rapidement, et le reste ne tombera tout simplement pas dans la sélection.
Nous pouvons essayer d'optimiser le tri par fusion. Tout d'abord, vérifiez la vitesse du tri de fusion habituel:
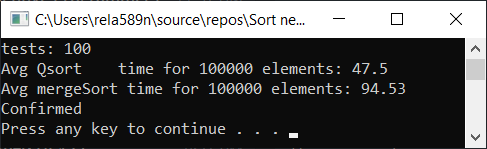
Fusionner le tri avec l'optimisation: void newGenerationMergeSort(int* a, int lo, int hi, int& minPortion) { if (hi <= lo) return; int mid = lo + (hi - lo) / 2; if (hi - lo <= minPortion) {
Une sorte d'emballage est nécessaire pour faciliter l'utilisation.
void newMergeSort(int *arr, int length) { int portion = log2(length);
Résultat du test:
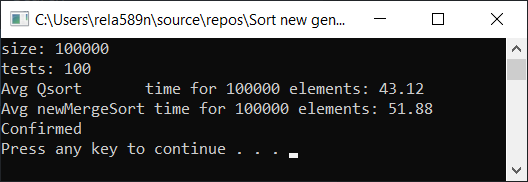
Oui, une augmentation de la vitesse est observée, mais néanmoins, cette fonction ne fonctionne pas aussi vite que le tri rapide. De plus, on ne peut pas parler d'O (n) sur des tableaux triés. Par conséquent, cette option est également ignorée.
Options d'optimisation pour la première option
Afin de garantir que la complexité n'est pas O (n 2 ), nous pouvons ajouter des éléments qui ne sont pas tombés dans l'échantillon pas dans 1 tableau comme auparavant, mais les étendre en 2 tableaux. Après cela, il ne reste plus qu'à trier ces deux parties, et à les fusionner avec notre échantillon. En conséquence, nous obtenons une complexité égale à O (n log n)
Comme nous l'avons déjà remarqué, l'élément absolument maximum (minimum) dans le tableau trié peut être trouvé assez rapidement, et ce n'est pas très efficace. C'est là que le tri par insertion intervient pour nous aider. À chaque itération de la sélection, nous vérifierons si nous pouvons insérer l'élément de flux dans un ensemble des derniers, par exemple, huit insérés.
Si ce n'est pas clair maintenant, ne vous inquiétez pas. Il devrait en être ainsi. Maintenant, tout deviendra clair sur le code et les questions disparaîtront.
La signature est la même que dans la version précédente
void newGenerationSort(int*& arr, int len)
Mais il faut noter que cette option suppose un pointeur sur le premier paramètre sur lequel l'opération delete [] peut être appelée (pourquoi - nous verrons plus tard). Autrement dit, lorsque nous avons alloué de la mémoire, nous avons attribué l'adresse du début du tableau pour ce pointeur.
Préparation préliminaire
Dans cet exemple, le soi-disant «coefficient de rattrapage» est juste une constante avec une valeur de 8. Il montre combien d'éléments maximum nous essayons de traverser pour insérer un nouveau «sous-maximum» ou «sous-minimum» à sa place.
int localCatchUp = min(catchUp, len);
Pour stocker l'échantillon, créez un tableau
Si quelque chose n'est pas clair, voir l'explication dans la version initiale
int* selection = new int[len << 1];
Remplissez les premiers éléments du tableau de sélection
selection[left--] = arr[0]; for (int i = 1; i < localCatchUp; ++i) { selection[right++] = arr[i]; }
Permettez-moi de vous rappeler que de nouveaux graves vont à gauche du centre du tableau d'échantillons et que de nouveaux hauts vont à droite
Créer des tableaux pour stocker des éléments non sélectionnés
int restLen = len >> 1;
Maintenant, la chose la plus importante est la sélection correcte des éléments du tableau source
Le cycle commence par localCatchUp (car les éléments précédents ont déjà entré notre échantillon comme valeurs à partir desquelles nous allons commencer). Et ça va jusqu'au bout. Donc après, à la fin, tous les éléments seront distribués soit dans le tableau de sélection, soit dans l'un des tableaux de sous-sélection.
Pour vérifier si nous pouvons insérer un élément dans la sélection, nous vérifierons simplement s'il est plus (ou égal) aux 8 positions de l'élément à gauche (droite - localCatchUp). Si tel est le cas, nous l'insérons simplement dans la position souhaitée en un seul passage à travers ces éléments. C'était pour le côté droit, c'est-à-dire pour le maximum d'éléments. De la même manière, nous faisons l'inverse pour les minimes. Si vous ne pouviez pas l’insérer de l’un ou l’autre côté de la sélection, nous le jetons dans l’un des autres tableaux.
La boucle ressemblera à ceci:
for (int i = localCatchUp; i < len; ++i) { if (selection[right - localCatchUp] <= arr[i]) { selection[right] = arr[i]; for (int j = right; selection[j - 1] > selection[j]; --j) swap(selection[j - 1], selection[j]); ++right; continue; } if (selection[left + localCatchUp] >= arr[i]) { selection[left] = arr[i]; for (int j = left; selection[j] > selection[j + 1]; ++j) swap(selection[j], selection[j + 1]); --left; continue; } if (i & 1) {
Encore une fois, que se passe-t-il ici? Nous essayons d'abord de pousser l'élément vers le haut. Ça ne marche pas? - Si possible, jetez-le au plus bas. S'il est impossible de le faire aussi - mettez-le dans restFirst ou restSecond.
La partie la plus difficile est terminée. Maintenant, après la boucle, nous avons un tableau trié avec une sélection (les éléments commencent à l'index [gauche + 1] et se terminent à [droite - 1] ), ainsi que les tableaux restFirst et restSecond de longueur restFirstLen et restSecondLen, respectivement.
Comme dans l'exemple précédent, avant l'appel récursif, nous libérons la mémoire du tableau principal (nous avons déjà enregistré tous ses éléments)
delete[] arr;
Notre tableau de sélection peut contenir de nombreuses cellules de mémoire inutilisée. Avant un appel récursif, vous devez le libérer.
Libérez de la mémoire inutilisée
int selectionLen = right - left - 1;
Exécutez maintenant notre fonction de tri de manière récursive pour les tableaux restFirst et restSecond
Pour comprendre comment cela fonctionne, vous devez d'abord regarder le code à la fin. Pour l'instant, il vous suffit de croire qu'après des appels récursifs, les tableaux restFirst et restSecond seront triés.
newGenerationSort(restFirst, restFirstLen); newGenerationSort(restSecond, restSecondLen);
Et enfin, nous devons fusionner 3 tableaux dans celui qui en résulte et l'affecter au pointeur arr.
Vous pouvez d'abord fusionner restFirst + restSecond dans un tableau restFull , puis fusionner selection + restFull . Mais cet algorithme a une telle propriété que le tableau de sélection contiendra probablement beaucoup moins d'éléments que les autres tableaux. Supposons que la sélection contient 100 éléments, restFirst contient 990 et restSecond contient 1010. Ensuite, pour créer un tableau restFull , vous devez effectuer 990 + 1010 = 2000 opérations de copie. Puis pour la fusion avec la sélection - encore 2000 + 100 copies. Total avec cette approche, la copie totale sera de 2000 + 2100 = 4100.
Appliquons l'optimisation ici. Fusionnez d'abord la sélection et restFirst dans le tableau de sélection . Opérations de copie: 100 + 990 = 1090. Ensuite, fusionnez la sélection et les tableaux restSecond et dépensez encore 1090 + 1010 = 2100 copies. Au total, 2100 + 1090 = 3190 seront publiés, soit près d'un quart de moins qu'avec l'approche précédente.
La fusion finale des tableaux
int* part2; int part2Len; if (selectionLen < restFirstLen) { glueDelete(selection, restFirst, restFirstLen, selection, selectionLen);
Comme vous pouvez le voir, s'il est plus rentable pour nous de fusionner la sélection avec restFirst , nous le faisons. Sinon, nous fusionnons comme dans "restFull"
Le code final de l'algorithme: Maintenant, testons le temps
Le code principal dans Source.cpp: #include <iostream> #include <ctime> #include <vector> #include <algorithm> #include "time_utilities.h" #include "sort_utilities.h" using namespace std; using namespace rela589n; void printArr(int* arr, int len) { for (int i = 0; i < len; ++i) { cout << arr[i] << " "; } cout << endl; } bool arraysEqual(int* arr1, int* arr2, int len) { for (int i = 0; i < len; ++i) { if (arr1[i] != arr2[i]) { return false; } } return true; } int* createArray(int length) { int* a1 = new int[length]; for (int i = 0; i < length; i++) { a1[i] = rand(); //a1[i] = (i + 1) % (length / 4); } return a1; } int* array_copy(int* arr, int length) { int* a2 = new int[length]; for (int i = 0; i < length; i++) { a2[i] = arr[i]; } return a2; } void tester(int tests, int length) { double t1, t2; int** arrays1 = new int* [tests]; int** arrays2 = new int* [tests]; for (int t = 0; t < tests; ++t) { // int* arr1 = createArray(length); arrays1[t] = arr1; arrays2[t] = array_copy(arr1, length); } t1 = getCPUTime(); for (int t = 0; t < tests; ++t) { quickSort(arrays1[t], 0, length - 1); } t2 = getCPUTime(); cout << "Avg Qsort time for " << length << " elements: " << (t2 - t1) * 1000 / tests << endl; int portion = catchUp = 8; t1 = getCPUTime(); for (int t = 0; t < tests; ++t) { newGenerationSort(arrays2[t], length); } t2 = getCPUTime(); cout << "Avg newGenSort time for " << length << " elements: " << (t2 - t1) * 1000 / tests //<< " Catch up coef: "<< portion << endl; bool confirmed = true; // for (int t = 0; t < tests; ++t) { if (!arraysEqual(arrays1[t], arrays2[t], length)) { confirmed = false; break; } } if (confirmed) { cout << "Confirmed" << endl; } else { cout << "Review your code! Something wrong..." << endl; } } int main() { srand(time(NULL)); int length; double t1, t2; cout << "size: "; cin >> length; int t; cout << "tests: "; cin >> t; tester(t, length); system("pause"); return 0; }
L'implémentation de tri rapide qui a été utilisée pour la comparaison lors des tests:Une petite remarque: j'ai utilisé cette implémentation particulière de quickSort pour que tout soit honnête. Bien que le tri standard de la bibliothèque d'algorithmes soit universel, il fonctionne 2 fois plus lentement que celui présenté ci-dessous.
getCPUTime - Mesure du temps CPU: #pragma once #if defined(_WIN32) #include <Windows.h> #elif defined(__unix__) || defined(__unix) || defined(unix) || (defined(__APPLE__) && defined(__MACH__)) #include <unistd.h> #include <sys/resource.h> #include <sys/times.h> #include <time.h> #else #error "Unable to define getCPUTime( ) for an unknown OS." #endif /** * Returns the amount of CPU time used by the current process, * in seconds, or -1.0 if an error occurred. */ double getCPUTime() { #if defined(_WIN32) /* Windows -------------------------------------------------- */ FILETIME createTime; FILETIME exitTime; FILETIME kernelTime; FILETIME userTime; if (GetProcessTimes(GetCurrentProcess(), &create;Time, &exit;Time, &kernel;Time, &user;Time) != -1) { SYSTEMTIME userSystemTime; if (FileTimeToSystemTime(&user;Time, &user;SystemTime) != -1) return (double)userSystemTime.wHour * 3600.0 + (double)userSystemTime.wMinute * 60.0 + (double)userSystemTime.wSecond + (double)userSystemTime.wMilliseconds / 1000.0; } #elif defined(__unix__) || defined(__unix) || defined(unix) || (defined(__APPLE__) && defined(__MACH__)) /* AIX, BSD, Cygwin, HP-UX, Linux, OSX, and Solaris --------- */ #if defined(_POSIX_TIMERS) && (_POSIX_TIMERS > 0) /* Prefer high-res POSIX timers, when available. */ { clockid_t id; struct timespec ts; #if _POSIX_CPUTIME > 0 /* Clock ids vary by OS. Query the id, if possible. */ if (clock_getcpuclockid(0, &id;) == -1) #endif #if defined(CLOCK_PROCESS_CPUTIME_ID) /* Use known clock id for AIX, Linux, or Solaris. */ id = CLOCK_PROCESS_CPUTIME_ID; #elif defined(CLOCK_VIRTUAL) /* Use known clock id for BSD or HP-UX. */ id = CLOCK_VIRTUAL; #else id = (clockid_t)-1; #endif if (id != (clockid_t)-1 && clock_gettime(id, &ts;) != -1) return (double)ts.tv_sec + (double)ts.tv_nsec / 1000000000.0; } #endif #if defined(RUSAGE_SELF) { struct rusage rusage; if (getrusage(RUSAGE_SELF, &rusage;) != -1) return (double)rusage.ru_utime.tv_sec + (double)rusage.ru_utime.tv_usec / 1000000.0; } #endif #if defined(_SC_CLK_TCK) { const double ticks = (double)sysconf(_SC_CLK_TCK); struct tms tms; if (times(&tms;) != (clock_t)-1) return (double)tms.tms_utime / ticks; } #endif #if defined(CLOCKS_PER_SEC) { clock_t cl = clock(); if (cl != (clock_t)-1) return (double)cl / (double)CLOCKS_PER_SEC; } #endif #endif return -1; /* Failed. */ }
Tous les tests ont été effectués sur la machine à un pourcentage. Intel core i3 7100u et 8 Go de RAM
Tableau complètement aléatoire Réseau partiellement ordonné a1[i] = (i + 1) % (length / 4);


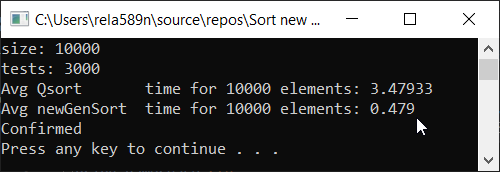
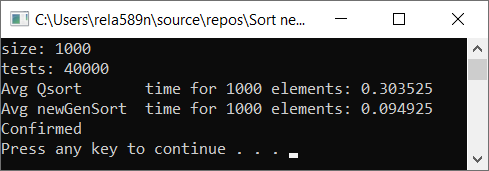
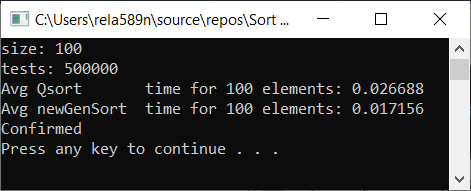
Conclusions
Comme vous pouvez le voir, l'algorithme fonctionne et fonctionne bien. Au moins, tout ce que nous voulions a été réalisé. Au détriment de la stabilité, je ne suis pas sûr de ne pas avoir vérifié. Vous pouvez le vérifier vous-même. Mais en théorie, cela devrait être réalisé très facilement. À certains endroits, au lieu du signe>, mettez ≥ ou quelque chose.