Bonjour, Habr! Je m'appelle Denis Kopyrin et aujourd'hui je veux parler de la manière dont nous avons résolu le problème de la sauvegarde à la demande sur macOS. En fait, une tâche intéressante que j'ai rencontrée à l'institut est finalement devenue un grand projet de recherche sur l'utilisation du système de fichiers. Tous les détails sont sous la coupe.

Je ne partirai pas de loin, je peux seulement dire que tout a commencé avec un projet à l'Institut de physique et de technologie de Moscou, que j'ai développé avec mon superviseur au département de base d'Acronis. Nous étions confrontés à la tâche d'organiser le stockage de fichiers à distance, ou plutôt de maintenir l'état actuel de leurs sauvegardes.
Pour garantir la sécurité des données, nous utilisons l'extension du noyau macOS, qui collecte des informations sur les événements du système. KPI pour les développeurs dispose d'une API KAUTH, qui vous permet de recevoir des notifications sur l'ouverture et la fermeture d'un fichier - c'est tout. Si vous utilisez KAUTH, vous devez enregistrer complètement le fichier lors de son ouverture pour l'écriture, car les événements d'écriture dans le fichier ne sont pas disponibles pour les développeurs. Ces informations n'étaient pas suffisantes pour nos tâches. En effet, afin de compléter en permanence une copie de sauvegarde des données, vous devez comprendre exactement où l'utilisateur (ou le malware :) a écrit les nouvelles données dans le fichier.
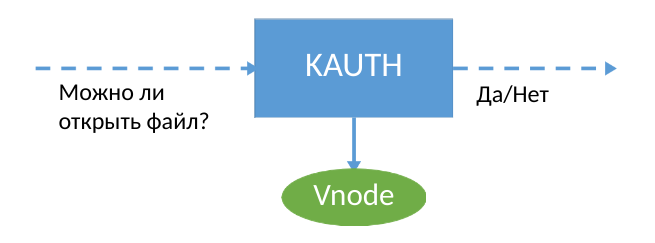
Mais lequel des développeurs a été effrayé par les restrictions du système d'exploitation? Si l'API du noyau ne vous permet pas d'obtenir des informations sur les opérations d'écriture, vous devez trouver votre propre façon d'intercepter via d'autres outils du noyau.
Au début, nous ne voulions pas patcher le cœur et ses structures. Au lieu de cela, ils ont essayé de créer un volume virtuel entier qui nous permettrait d'intercepter toutes les demandes de lecture et d'écriture qui le traversaient. Mais il s'est avéré une caractéristique désagréable de macOS: le système d'exploitation pense qu'il n'a pas 1, mais 2 lecteurs flash USB, deux disques, etc. Et du fait que le second volume change lorsque vous travaillez avec le premier, macOS commence à ne pas fonctionner correctement avec les lecteurs. Il y avait tellement de problèmes avec cette méthode que j'ai dû l'abandonner.
Rechercher une autre solution
Malgré les limites de KAUTH, ce KPI vous permet d'être averti de l'utilisation d'un fichier pour l'enregistrement avant toutes les opérations. Les développeurs ont accès à l'abstraction du fichier BSD dans le noyau - vnode. Curieusement, il s'est avéré que l'application de correctifs à vnode est plus facile que l'utilisation du filtrage de volume. La structure vnode a une table de fonctions qui permettent de travailler avec de vrais fichiers. Par conséquent, nous avons eu l'idée de remplacer ce tableau.
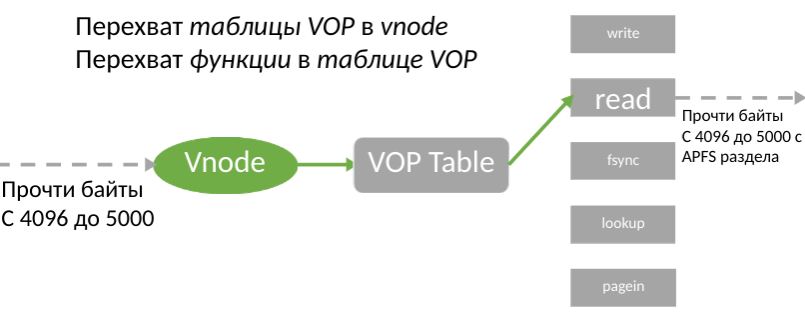
L'idée a été immédiatement considérée comme une bonne idée, mais pour sa mise en œuvre, il a fallu trouver la table elle-même dans la structure vnode, car Apple ne documente son emplacement nulle part. Pour ce faire, il a fallu étudier le code machine du noyau, et aussi déterminer s'il est possible d'écrire à cette adresse pour que le système ne meure pas après.
Si la table est trouvée, nous la copions simplement en mémoire, remplaçons le pointeur et collons le lien vers la nouvelle table dans le vnode existant. Grâce à cela, toutes les opérations avec des fichiers passeront par notre pilote, et nous pourrons enregistrer toutes les demandes des utilisateurs, y compris en lecture et en écriture. Par conséquent, la recherche de la table précieuse est devenue notre objectif principal.
Étant donné qu'Apple ne le veut pas vraiment, pour résoudre le problème, vous devez essayer de «deviner» l'emplacement de la table à l'aide d'une heuristique pour l'emplacement relatif des champs, ou prendre une fonction déjà connue, la démonter et rechercher un décalage à partir de ces informations.
Comment rechercher un décalage: un moyen simpleLe moyen le plus simple de trouver des décalages de table dans vnode est une heuristique basée sur l'emplacement des champs dans une structure (
lien vers Github ).
struct vnode { ... int (**v_op)(void *); mount_t v_mount; ... }
Nous utiliserons l'hypothèse que le champ v_op dont nous avons besoin est exactement 8 octets supprimés de v_mount. La valeur de ce dernier peut être obtenue en utilisant un KPI public (
lien vers Github ):
mount_t vnode_mount(vnode_t vp);
Connaissant la valeur de v_mount, nous commencerons à chercher une «aiguille dans la botte de foin» - nous percevrons la valeur du pointeur vers vnode 'vp' comme uintptr_t *, la valeur de vnode_mount (vp) comme uintptr_t. Ceci est suivi d'itérations jusqu'à la valeur «raisonnable» de i, jusqu'à ce que la condition «meule de foin [i] == aiguille» soit remplie. Et si l'hypothèse concernant l'emplacement des champs est correcte, le décalage v_op est i-1.
void* getVOPPtr(vnode_t vp) { auto haystack = (uintptr_t*) vp; auto needle = (uintptr_t) vnode_mount(vp); for (int i = 0; i < ATTEMPTCOUNT; i++) { if (haystack[i] == needle) { return haystack + (i - 1); } } return nullptr; }
Comment rechercher un décalage: démontageMalgré sa simplicité, la première méthode présente un inconvénient important. Si Apple modifie l'ordre des champs dans la structure vnode, la méthode simple sera interrompue. Une méthode plus universelle, mais moins triviale, consiste à démonter dynamiquement le noyau.
Par exemple, considérons la fonction de noyau démontée VNOP_CREATE (
lien vers Github ) sur macOS 10.14.6. Les instructions qui nous intéressent sont signalées par une flèche ->.
_VNOP_CREATE:
1 push rbp
2 mov rbp, rsp
3 push r15
4 push r14
5 push r13
6 push r12
7 push rbx
8 sub rsp, 0x48
9 mov r15, r8
10 mov r12, rdx
11 mov r13, rsi
-> 12 mov rbx, rdi
13 lea rax, qword [___stack_chk_guard]
14 mov rax, qword [rax]
15 mov qword [rbp+-48], rax
-> 16 lea rax, qword [_vnop_create_desc] ; _vnop_create_desc
17 mov qword [rbp+-112], rax
18 mov qword [rbp+-104], rdi
19 mov qword [rbp+-96], rsi
20 mov qword [rbp+-88], rdx
21 mov qword [rbp+-80], rcx
22 mov qword [rbp+-72], r8
-> 23 mov rax, qword [rdi+0xd0]
-> 24 movsxd rcx, dword [_vnop_create_desc]
25 lea rdi, qword [rbp+-112]
-> 26 call qword [rax+rcx*8]
27 mov r14d, eax
28 test eax, eax
…. errno_t VNOP_CREATE(vnode_t dvp, vnode_t * vpp, struct componentname * cnp, struct vnode_attr * vap, vfs_context_t ctx) { int _err; struct vnop_create_args a; a.a_desc = &vnop;_create_desc; a.a_dvp = dvp; a.a_vpp = vpp; a.a_cnp = cnp; a.a_vap = vap; a.a_context = ctx; _err = (*dvp->v_op[vnop_create_desc.vdesc_offset])(&a;); …
Nous allons scanner les instructions de l'assembleur pour trouver le décalage dans le dvp vnode. Le «but» du code assembleur est d'appeler une fonction à partir de la table v_op. Pour ce faire, le processeur doit suivre ces étapes:
- Téléchargez dvp pour vous inscrire
- Déréférencer pour obtenir v_op (ligne 23)
- Obtenez vnop_create_desc.vdesc_offset (ligne 24)
- Appeler une fonction (ligne 26)
Si tout est clair avec les étapes 2 à 4, alors des difficultés surviennent avec la première étape. Comment comprendre dans quel registre dvp a été chargé? Pour ce faire, nous avons utilisé une méthode d'émulation d'une fonction qui surveille les mouvements du pointeur souhaité. Selon la convention d'appel System V x86_64, le premier argument est passé dans le registre rdi. Par conséquent, nous avons décidé de garder une trace de tous les registres contenant rdi. Dans mon exemple, ce sont les registres rbx et rdi. En outre, une copie du registre peut être enregistrée sur la pile, qui se trouve dans la version de débogage du noyau.
Sachant que les registres rbx et rdi stockent dvp, nous découvrons que la ligne 23 a déréférencé vnode pour obtenir v_op. Nous obtenons donc l'hypothèse que le déplacement dans la structure est 0xd0. Pour confirmer la bonne décision, nous continuons à scanner et à nous assurer que la fonction est appelée correctement (lignes 24 et 26).
Cette méthode est plus sûre, mais malheureusement, elle présente également des inconvénients. Nous devons compter sur le fait que le modèle de la fonction (à savoir les 4 étapes dont nous avons parlé ci-dessus) sera le même. Cependant, la probabilité de changer le motif de la fonction est d'un ordre de grandeur inférieur à la probabilité de changer l'ordre des champs. Nous avons donc décidé de nous arrêter sur la deuxième méthode.
Remplacer les pointeurs dans le tableau
Après avoir trouvé v_op, la question se pose, comment utiliser ce pointeur? Il existe deux façons différentes: remplacer la fonction dans le tableau (troisième flèche dans l'image) ou remplacer le tableau dans vnode (deuxième flèche dans l'image).
Au début, il semble que la première option soit plus rentable, car il suffit de remplacer un pointeur. Cependant, cette approche présente 2 inconvénients importants. Tout d'abord, la table v_op est la même pour tous les vnode d'un système de fichiers donné (v_op pour HFS +, v_op pour APFS, ...), donc le filtrage par vnode est requis, ce qui peut être très coûteux - vous devrez filtrer le vnode supplémentaire à chaque opération d'écriture. Deuxièmement, le tableau est écrit sur la page en lecture seule. Cette limitation peut être contournée si vous utilisez l'enregistrement via IOMappedWrite64, en contournant les vérifications du système. De plus, si kext avec le pilote du système de fichiers est livré, il sera difficile de comprendre comment supprimer le correctif.
La deuxième option s'avère plus ciblée et plus sûre - l'intercepteur ne sera appelé que pour le vnode nécessaire, et la mémoire vnode permet initialement des opérations de lecture-écriture. La table entière étant en cours de remplacement, il est nécessaire d'allouer un peu plus de mémoire (80 fonctions au lieu d'une). Et comme le nombre de tables est généralement égal au nombre de systèmes de fichiers, la limite de mémoire est complètement négligeable.
C'est pourquoi kext utilise la deuxième méthode, bien que, je le répète, à première vue, il semble que cette option soit pire.
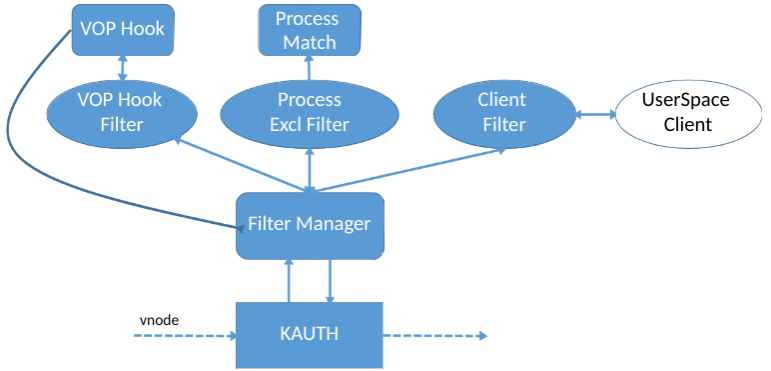
En conséquence, notre pilote fonctionne comme suit:
- L'API KAUTH fournit vnode
- Nous remplaçons la table vnode. Si nécessaire, nous n'interceptons les opérations que pour les noeuds virtuels «intéressants», par exemple, les documents utilisateur
- Lors de l'interception, nous vérifions quel processus enregistre, nous filtrons «notre»
- Nous envoyons une demande synchronisée UserSpace au client, qui décide exactement ce qui doit être enregistré.
Qu'est-il arrivé?
Aujourd'hui, nous avons un module expérimental, qui est une extension du noyau macOS et prend en compte toute modification du système de fichiers au niveau granulaire. Il convient de noter que dans macOS 10.15, Apple a introduit un nouveau cadre (
lien vers EndpointSecurity ) pour recevoir des notifications de modifications du système de fichiers, qui est prévu pour une utilisation dans Active Protection, par conséquent, la solution décrite dans l'article a été déclarée obsolète.