Il y a des moments où vous devez restreindre l'accès des utilisateurs à certaines données du cube. Il semblerait qu'il n'y ait rien de compliqué: installez les filtres de ligne dans les rôles et vous avez terminé, mais il y a un problème - le filtre coupe les données dans le tableau et il s'avère que vous ne pouvez voir la vitesse que par les lignes disponibles, et nous avons besoin de toute la vitesse, mais les détails ne doivent être disponibles que pour certains d'entre eux.
Par exemple, l'utilisateur doit voir le chiffre d'affaires de tous les produits, avec la possibilité de tous les détails, mais en même temps, les clients ne doivent pas afficher tous, mais seulement certains ou tous les clients, mais avec des données partiellement masquées dans certains attributs (champs).
Afin d'empêcher l'utilisateur de voir le chiffre d'affaires des clients, vous pouvez le battre dans les formules en mesures et afficher une valeur vide si l'utilisateur essaie de voir le chiffre d'affaires d'un client spécifique, l'une de ces options est décrite
ici . Mais ce n'est pas le cas. Lorsque quelques dizaines de mesures, écrivez une formule dans chacune d'elles ... et si vous oubliez? Mais vous l’oublierez sûrement un jour ... Et si l’utilisateur a besoin des données d’une carte client spécifique, rien ne l’empêchera de le voir sans choisir une mesure de filtrage. Que faire?
Nous avions besoin de réaliser cet affichage:
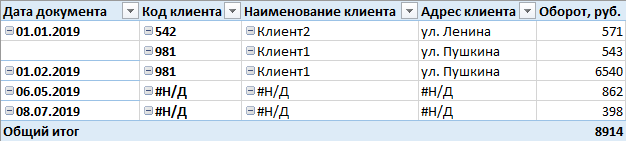
Tout le principe qui vous permet d'obtenir un résultat similaire repose sur une petite astuce, et il consiste à ajouter des lignes synthétiques à la table (clients, dans ce cas) afin que l'enregistrement sur la même entité soit dupliqué au moins une fois - le premier contiendra des informations complètes, et la deuxième de la plupart des colonnes est remplie par une fiche de type
# N / A , mais les identificateurs sont les mêmes pour les deux enregistrements. De plus, en utilisant le filtre dans les rôles et une colonne spéciale par laquelle le filtrage est effectué, nous laissons certaines lignes à la disposition de l'utilisateur - soit une ligne avec des champs complètement remplis ou avec des talons. Et depuis Étant donné que le cube a la caractéristique de "réduire" les données répétitives et que l'utilisateur ne peut accéder à aucun autre attribut qui donne des valeurs uniques, alors dans la table résultante, tous les clients avec le code
# N / A se transformeront en une seule ligne. Je pense qu'à ce stade tout est déjà très clair, vous ne pouvez plus lire. Le résultat est dans le titre de l'article.
Mais si quelqu'un a besoin de détails - je les ai.
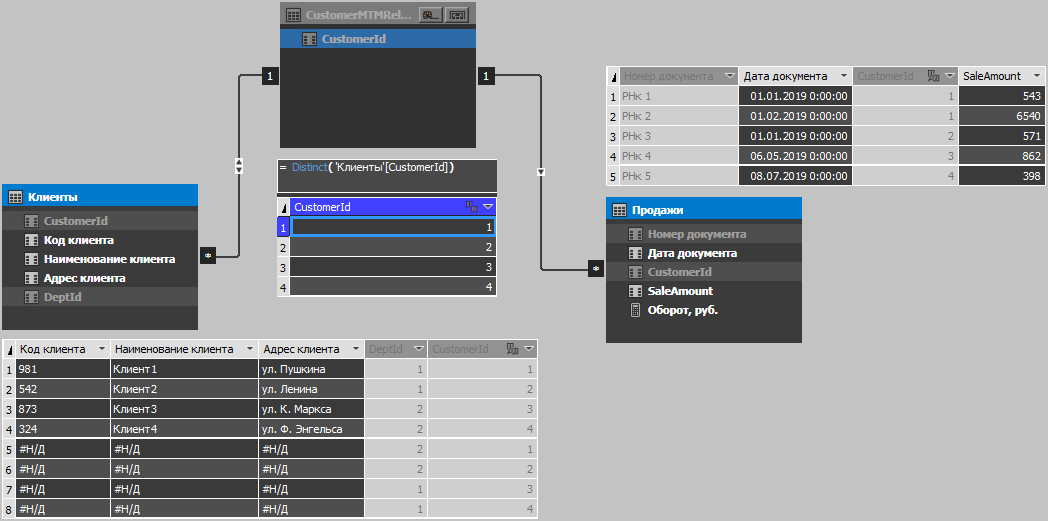
Les modèles tabulaires jusqu'à la version 1400 (SQL 2017 inclus) ne permettent pas de créer des relations plusieurs-à-plusieurs, mais dans le cas de doublons, nous avons besoin d'une telle relation, nous allons donc la créer via une table intermédiaire contenant une seule colonne avec des identifiants client uniques. Le tableau est initialement incompressible car il ne contient que des valeurs uniques, vous pouvez donc le calculer, car dans ce cas, nous ne gagnerons rien si nous le remplissons via t-sql (rappelez-vous le principe de traitement et l'ordre de compression de la table?). Tout simplement en raison de la capacité du moteur à compresser les données en double, la quantité de données dans le cube augmentera légèrement, et en raison du filtrage à travers le rôle, la session utilisateur a un jeu d'enregistrements réduit, c'est-à-dire le nombre final d'enregistrements après filtrage de l'ensemble restera tel qu'il était sans doublons. Par conséquent, ne vous inquiétez pas, même si la table est initialement suffisamment grande, l'ajout de doublons n'affectera pas les performances et le volume de manière significative (bien sûr, les cas sont différents, mais dans la plupart d'entre eux, tout sera juste cela).
La figure suivante montre le modèle de cube et le contenu de la table:
Par exemple, ajoutez un filtre simple:

C’est tout.
Je voudrais mettre en garde contre une caractéristique de l'utilisation de cette approche. Les utilisateurs qui sont administrateurs sur le serveur SSAS, par défaut, vont dans le cube en contournant toutes sortes de rôles, même si leurs noms sont spécifiés dans ces rôles. Cela conduit au fait que les filtres de rôle ne fonctionnent pas et que, sous l'administrateur, tous les doublons sont visibles. Mais ne désespérez pas, il suffit dans la chaîne de connexion d'indiquer explicitement quel rôle utiliser et tout se met en place, de plus, lors des tests, vous devrez basculer entre les rôles plus d'une fois.
Comme vous le comprenez, vous pouvez faire plusieurs combinaisons du même enregistrement avec différents degrés de remplissage des colonnes avec des données réelles. Vous pouvez également créer une table masquée distincte dans le cube, qui sera remplie de comptes via ADSI, et répartir les utilisateurs entre les différents groupes de domaines, et remplir ce tableau en fonction des combinaisons d'appartenance des utilisateurs dans certains groupes. Nous écrivons les liens dans les filtres de rôle ligne par ligne dans ce tableau, ce qui nous permettra de contrôler les mesures et nous pouvons également y faire référence dans les mesures, de sorte que, si nécessaire, certaines mesures montrent le vide. Avec une telle organisation, un réglage fin des droits d'accès aux données est obtenu et tout est stocké en un seul endroit. Mais il y a une nuance avec les mesures: si un utilisateur avancé écrit lui-même des requêtes dans le cube, alors rien ne l'empêche d'utiliser sa mesure, sans signets, à condition qu'il connaisse les noms des colonnes de base et la formule ... Bien que, si vous le souhaitez, vous pouvez le faire ici restriction, mais c'est un autre sujet.