Tout le monde parle des processus de développement et de test, de formation du personnel, de motivation croissante, mais ces processus sont rares lorsqu'une minute d'arrêt de service coûte de l'argent. Que faire lorsque vous effectuez des transactions financières dans le cadre d'un SLA strict? Comment augmenter la fiabilité et la tolérance aux pannes de vos systèmes, en décrivant le développement et les tests?

La prochaine conférence HighLoad ++ se tiendra les 6 et 7 avril 2020 à Saint-Pétersbourg. Détails et billets
ici . 9 novembre, 18h00. HighLoad ++ Moscou 2018, Delhi + Calcutta Hall. Résumés et
présentation .
Evgeny Kuzovlev (ci-après dénommée la CE): - Amis, bonjour! Je m'appelle Kuzovlev Evgeny. Je viens d'EcommPay, une division spécifique est EcommPay IT, une division informatique d'un groupe de sociétés. Et aujourd'hui, nous allons parler des temps d'arrêt - comment les éviter, comment minimiser leurs conséquences, si vous ne pouvez pas les éviter. Le thème est: "Que faire quand une minute d'arrêt coûte 100 000 $?" Pour nous, pour l'avenir, les chiffres sont comparables.
Que fait EcommPay IT?
Qui sommes nous Pourquoi suis-je debout devant toi? Pourquoi ai-je le droit de vous dire quelque chose ici? Et de quoi parlerons-nous plus en détail ici?

EcommPay Group of Companies est un acquéreur international. Nous traitons les paiements dans le monde entier - en Russie, en Europe, en Asie du Sud-Est (partout dans le monde). Nous avons 9 bureaux, 500 employés au total et environ un peu moins de la moitié d'entre eux sont des informaticiens. Tout ce que nous faisons, tout ce sur quoi nous gagnons de l'argent, nous l'avons fait nous-mêmes.
Nous avons tous nos produits (et nous en avons beaucoup - dans la gamme des grands produits informatiques, nous avons environ 16 composants différents), nous nous sommes écrits; nous nous écrivons, nous nous développons. Et en ce moment, nous effectuons environ un million de transactions par jour (des millions - il sera probablement juste de le dire). Nous sommes une entreprise assez jeune - nous n'avons que six ans environ.
Il y a 6 ans, c'était une telle startup lorsque les gars sont venus avec l'entreprise. Ils étaient unis par une idée (il n'y avait rien d'autre qu'une idée), et nous avons couru. Comme toute startup, nous avons couru plus vite ... Pour nous, la vitesse était plus importante que la qualité.
À un moment donné, nous nous sommes arrêtés: nous avons réalisé que nous ne pouvions plus vivre à cette vitesse et avec cette qualité, et nous devions en premier lieu faire de la qualité. À ce stade, nous avons décidé d'écrire une nouvelle plateforme qui sera juste, évolutive, fiable. Ils ont commencé à écrire cette plate-forme (ils ont commencé à investir, à développer le développement, les tests), mais à un moment donné, ils ont réalisé que le développement et les tests ne permettaient pas d'atteindre un nouveau niveau de qualité de service.
Vous fabriquez un nouveau produit, vous le mettez en production, mais quelque part, quelque chose ne va pas. Et aujourd'hui, nous allons parler de la façon d'atteindre un nouveau niveau qualitatif (comment nous l'avons obtenu, de notre expérience), en retirant le développement et les tests de l'image; nous allons parler de ce qui est disponible pour l'exploitation - ce que l'exploitation peut faire d'elle-même, ce qu'elle peut offrir des tests afin d'affecter la qualité.
Temps d'arrêt. Les commandements de l'exploitation.
La principale pierre angulaire, dont nous allons réellement parler aujourd'hui, est toujours les temps d'arrêt. Mot effrayant. Si nous avions un temps d'arrêt, tout va mal avec nous. Nous courons pour augmenter, les administrateurs tiennent le serveur - Dieu ne plaise, il ne tombe pas, comme dans cette chanson. C’est ce dont nous allons parler aujourd’hui.

Lorsque nous avons commencé à changer nos approches, nous avons formé 4 commandements. Ils sont présentés sur mes slides:
Ces commandements sont assez simples:

- Identifiez rapidement le problème.
- Débarrassez-vous encore plus rapidement.
- Aidez à comprendre la raison (plus tard, pour les développeurs).
- Et standardiser les approches.
J'attire votre attention sur le point numéro 2. Nous nous débarrassons du problème, mais ne le résolvons pas. Décider est la deuxième fois. La principale chose pour nous est que l'utilisateur est protégé contre ce problème. Il existera dans un certain environnement isolé, mais cet environnement n'entrera pas en contact avec lui. En fait, nous allons passer en revue ces quatre groupes de problèmes (pour certains plus en détail, pour certains moins en détail), je vais vous dire ce que nous utilisons, quel type d'expérience nous avons dans la résolution.
Dépannage: quand ils se produisent et que faire avec eux?
Mais nous allons commencer dans le désordre, nous commençons par le point numéro 2 - comment se débarrasser rapidement du problème? Il y a un problème - nous devons le résoudre. «Que devons-nous faire avec cela?» Est la question principale. Et lorsque nous avons commencé à réfléchir à la façon de résoudre le problème, nous avons développé pour nous-mêmes certaines exigences que le dépannage devrait suivre.

Pour formuler ces exigences, nous avons décidé de nous poser la question: «Et quand avons-nous des problèmes»? Et les problèmes, comme il s'est avéré, se trouvent dans quatre cas:

- Dysfonctionnement matériel.
- Défaillance des services externes.
- Changement de version logicielle (même déploiement).
- Croissance de la charge explosive.
Nous ne parlerons pas des deux premiers. Un dysfonctionnement matériel est résolu tout simplement: vous devez tout faire dupliquer. S'il s'agit de disques - les disques doivent être assemblés en RAID, s'il s'agit d'un serveur - le serveur doit être dupliqué, si vous avez une infrastructure réseau - vous devez mettre une deuxième copie de l'infrastructure réseau, c'est-à-dire que vous prenez et dupliquez. Et si quelque chose échoue, vous passez à des capacités de réserve. Il est difficile d'en dire plus ici.
Le second est l'échec des services externes. Pour la plupart, le système n'est pas du tout un problème, mais pas pour nous. Étant donné que nous traitons les paiements, nous sommes un tel agrégateur qui se situe entre l'utilisateur (qui saisit les détails de sa carte) et les banques, les systèmes de paiement ("Visa", "MasterCard", "World" du même). Nos services externes (systèmes de paiement, banques) ont tendance à échouer. Ni nous ni vous (si vous avez de tels services) ne pouvons influencer cela.
Que faire alors? Il y a deux options. Tout d'abord, si vous le pouvez, vous devez dupliquer ce service d'une manière ou d'une autre. Par exemple, si nous le pouvons, nous transférons le trafic d'un service à un autre: nous traitons, par exemple, les cartes via Sberbank, Sberbank a des problèmes - nous transférons le trafic [conditionnellement] vers Raiffeisen. La deuxième chose que nous pouvons faire est de constater rapidement l'échec des services externes, et nous parlerons donc de la vitesse de réaction dans la prochaine partie du rapport.
En fait, de ces quatre, nous pouvons spécifiquement affecter le changement de versions logicielles - pour prendre des mesures qui mèneront à une amélioration dans le contexte des déploiements et dans le contexte de la croissance de la charge explosive. En fait, nous l'avons fait. Ici encore, une petite remarque ...
Sur ces quatre problèmes, plusieurs sont résolus immédiatement si vous disposez d'un cloud. Si vous êtes dans les nuages Microsoft Azhur, Ozone, utilisez nos nuages, de Yandex ou Mail, alors au moins un dysfonctionnement matériel devient leur problème et tout devient immédiatement correct dans le contexte d'un dysfonctionnement matériel.
Nous sommes une petite entreprise non standard. Ici, tout le monde parle de Kubernets, de nuages - nous n'avons ni Kubernets, ni nuages. Mais nous avons des racks avec du fer dans de nombreux centres de données, et nous sommes obligés de vivre avec ce fer, nous sommes obligés de répondre de tout. Par conséquent, dans ce contexte, nous parlerons. Alors, sur les problèmes. Les deux premiers sont hors crochets.
Changer la version du logiciel. Bases
Nos développeurs n'ont pas accès à la production. Pourquoi Mais nous sommes simplement certifiés par PCI DSS, et nos développeurs n'ont tout simplement pas le droit de grimper dans le "prod". Voilà, point final. Absolument. Par conséquent, la responsabilité du développement se termine exactement au moment où le développement a transmis la version à la version.

Notre deuxième base, que nous avons, qui nous aide également beaucoup, est le manque de connaissances uniques et sans papiers. J'espère que vous en ferez de même. Parce que si ce n'est pas le cas, vous aurez des problèmes. Des problèmes surgiront lorsque cette connaissance unique et non documentée n'est pas présente au bon moment au bon endroit. Supposons que vous ayez une personne qui sache déployer un composant spécifique - il n'y a personne, il est en vacances ou est tombé malade - c'est tout, vous avez des problèmes.
Et la troisième base à laquelle nous sommes arrivés. Nous sommes venus à lui à travers la douleur, le sang, les larmes - nous sommes arrivés à la conclusion que n'importe quelle de nos versions contient des erreurs, même si elle est sans erreurs. Nous avons décidé cela par nous-mêmes: lorsque nous déployons quelque chose, lorsque nous roulons quelque chose dans la prod - nous avons une construction avec des erreurs. Nous avons formé les exigences que notre système doit satisfaire.
Exigences de changement de version du logiciel
Il existe trois de ces exigences:

- Nous devons rapidement annuler le déploiement.
- Nous devons minimiser l'impact d'un déploiement infructueux.
- Et nous devons pouvoir nous coincer rapidement en parallèle.
Dans cet ordre! Pourquoi? Parce que, tout d'abord, lors du déploiement de la nouvelle version, la vitesse n'a pas d'importance, mais il est important pour vous, si quelque chose ne va pas, de revenir rapidement en arrière et d'avoir un impact minimal. Mais si vous avez un ensemble de versions sur la production, pour lesquelles il s'est avéré qu'il y a une erreur (comme de la neige sur la tête, il n'y a pas eu de déploiement, mais l'erreur est contenue) - la vitesse du déploiement suivant est importante pour vous. Qu'avons-nous fait pour répondre à ces exigences? Nous avons recouru à une telle méthodologie:
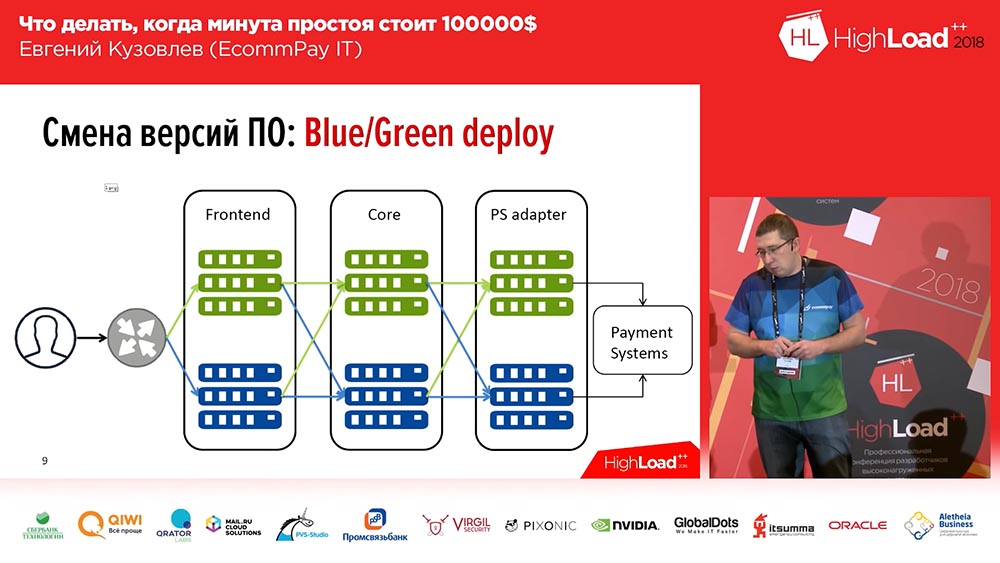
C'est bien connu, nous n'avons pas inventé une seule fois - c'est le déploiement Blue / Green. Qu'est ce que c'est Vous devez avoir une copie pour chaque groupe de serveurs sur lesquels vos applications sont installées. La copie est «chaude»: il n'y a pas de trafic dessus, mais à tout moment ce trafic peut être envoyé à cette copie. Cette copie contient la version précédente. Et au moment du déploiement, vous déployez le code sur une copie inactive. Basculez ensuite une partie du trafic (ou la totalité) vers la nouvelle version. Ainsi, pour changer le flux de trafic de l'ancienne version vers la nouvelle, vous n'avez qu'à effectuer une seule action: vous devez changer l'équilibreur en amont, changer la direction - d'une en amont à une autre. Ceci est très pratique et résout le problème de la commutation rapide, de la restauration rapide.
Ici, la solution à la deuxième question est la minimisation: vous ne pouvez mettre sur une nouvelle ligne, sur une ligne avec un nouveau code qu'une partie de votre trafic (soit, par exemple, 2%). Et ces 2% - ils ne sont pas à 100%! Si vous avez perdu 100% du trafic lors d'un déploiement infructueux - c'est effrayant, si vous avez perdu 2% du trafic - c'est désagréable, mais ce n'est pas effrayant. De plus, les utilisateurs ne le remarqueront probablement même pas, car dans certains cas (pas tous) le même utilisateur, en appuyant sur F5, il sera redirigé vers une autre version de travail.
Déploiement bleu / vert. Acheminement
De plus, tout n'est pas si simple «Blue / Green Deploy» ... Tous nos composants peuvent être divisés en trois groupes:
- Il s'agit de l'interface (pages de paiement que nos clients voient);
- noyau de traitement;
- un adaptateur pour travailler avec les systèmes de paiement (banques, MasterCard, Visa ...).
Et il y a une nuance - la nuance est le routage entre les lignes. Si vous changez simplement 100% du trafic, vous n'avez pas ces problèmes. Mais si vous voulez changer de 2%, les questions commencent: "Comment faire?" La chose la plus simple sur le front: vous pouvez sélectionner au hasard Round Robin dans nginx, et il vous reste 2%, 98% - à droite. Mais cela ne convient pas toujours.
Ici, par exemple, l'utilisateur interagit avec le système dans plus d'une demande. C'est normal: 2, 3, 4, 5 requêtes - vos systèmes peuvent être les mêmes. Et s'il est important pour vous que toutes les demandes des utilisateurs arrivent sur la même ligne que la première demande, ou (deuxième moment) toutes les demandes des utilisateurs arrivent sur une nouvelle ligne après le changement (il pourrait commencer à travailler plus tôt avec le système, avant le changement), - alors cette distribution aléatoire ne vous convient pas. Ensuite, il y a les options suivantes:

La première option, la plus simple - basée sur les paramètres de base du client (IP Hash). Vous avez une adresse IP et vous partagez de droite à gauche par IP. Ensuite, le deuxième cas décrit par moi fonctionnera pour vous lorsqu'il y a eu un déploiement, l'utilisateur peut déjà commencer à travailler avec votre système, et à partir du moment du déploiement, toutes les demandes iront sur une nouvelle ligne (sur la même, disons).
Si pour une raison quelconque, cela ne vous convient pas et que vous devez envoyer des demandes à la ligne où la demande principale et intime de l'utilisateur est arrivée, vous avez deux options ...
La première option: vous pouvez prendre nginx + payé. Il existe un mécanisme de sessions persistantes qui, à la demande initiale de l'utilisateur, expose une session à l'utilisateur et la lie à un amont en particulier. Toutes les demandes d'utilisateurs ultérieures au cours de la durée de la session iront au même en amont où la session a été définie.
Cela ne nous convenait pas, car nous avions déjà un nginx normal. Changer de nginx + n'est pas que c'est cher, c'était juste un peu pénible pour nous et pas très juste. Par exemple, «Sticks Sessions» n'a pas fonctionné pour nous pour la simple raison que «Sticks Sessions» ne donne pas la possibilité de suivre l'itinéraire sur la base de «Eli-or». Vous pouvez y spécifier ce que nous faisons «Sticky Sessions», par exemple, par IP ou par IP et par cookie ou par paramètre de publication, mais «Eli-or» est déjà plus compliqué là-bas.
Par conséquent, nous sommes arrivés à la quatrième option. Nous avons pris nginx sur les "stéroïdes" (c'est openresty) - c'est le même nginx qui supporte en outre l'inclusion des derniers scripts. Vous pouvez écrire un dernier script, glisser ce «ouvert», et ce dernier script sera exécuté quand une demande d'utilisateur arrivera.
Et nous avons écrit, en fait, un tel script, nous nous sommes mis «openrest» et dans ce script, nous trions 6 paramètres différents pour la concaténation de «Or». Selon la disponibilité de tel ou tel paramètre, on sait que l'utilisateur est venu sur une page ou sur une autre, sur une ligne ou sur une autre.
Déploiement bleu / vert. Avantages et inconvénients
Bien sûr, nous pourrions probablement le rendre un peu plus facile (utiliser les mêmes «Sticky Sessions»), mais nous avons encore une telle nuance que non seulement l'utilisateur interagit avec nous dans le cadre d'un traitement d'une transaction ... Mais les systèmes de paiement interagissent également avec nous: nous, après avoir traité la transaction (en envoyant une demande au système de paiement), nous recevons un rappel.
Et supposons que si à l'intérieur de notre circuit, nous pouvons exécuter l'adresse IP de l'utilisateur dans toutes les demandes et séparer les utilisateurs en fonction de l'adresse IP, alors nous ne dirons pas le même «Visa»: «Mec, nous sommes une telle entreprise rétro, nous sommes une sorte d'international (sur le site et dans De la Russie) ... Et s'il vous plaît donnez-nous un coup d'oeil à l'adresse IP de l'utilisateur dans un champ supplémentaire, votre protocole est standardisé! " Des affaires claires, ils ne seront pas d'accord.

Par conséquent, pour nous, cela ne convenait pas - nous avons fait ouvertement. En conséquence, avec le routage, nous avons obtenu comme ceci:
Le Blue / Green Deploy a, respectivement, les avantages dont j'ai parlé et les inconvénients.
Inconvénient deux:
- vous devez vous soucier du routage;
- le deuxième inconvénient principal est le coût.
Vous avez besoin de deux fois plus de serveurs, vous avez besoin de deux fois plus de ressources opérationnelles, vous devez dépenser deux fois plus d'efforts pour maintenir tout ce zoo.
Soit dit en passant, parmi les avantages se trouve une autre chose que je n'ai pas mentionnée auparavant: vous avez une réserve en cas d'augmentation de la charge. Si vous avez une croissance explosive de la charge, un grand nombre d'utilisateurs vous sont tombés dessus, alors vous incluez simplement la deuxième ligne dans la distribution de 50 à 50 - et vous avez immédiatement 2 serveurs dans votre cluster jusqu'à ce que vous résolviez le problème d'avoir des serveurs.
Comment faire un déploiement rapide?
Nous avons parlé de la façon de résoudre le problème de la minimisation et de la restauration rapide, mais la question demeure: "Comment déployer rapidement?"

Voici bref et simple.
- Vous devez avoir un système de CD (livraison continue) - sans lui, nulle part. Si vous avez un serveur, vous pouvez vous retrouver avec des stylos. Nous avons environ un millier et demi de serveurs et 1 500 poignées, bien sûr - nous pouvons planter un département de la taille de cette salle, uniquement pour le déployer.
- Le déploiement doit être parallèle. Si vous avez un déploiement cohérent, alors tout va mal. Un serveur est normal, vous déploierez un millier et demi de serveurs toute la journée.
- Encore une fois, pour accélérer, ce n'est plus nécessaire, probablement. Lorsque desploey construire généralement le projet. Vous avez un projet web, il y a une partie front-end (vous faites un pack web là-bas, npm collecte quelque chose comme ça), et ce processus, en principe, est de courte durée - 5 minutes, mais ces 5 minutes peuvent être critiques. Par conséquent, par exemple, nous ne faisons pas cela: nous avons supprimé ces 5 minutes, nous déployons des artefacts.
Qu'est-ce qu'un artefact? Un artefact est une construction assemblée dans laquelle la totalité de la pièce d'assemblage est déjà terminée. Nous stockons cet artefact dans le stockage d'artefacts. Nous avons utilisé deux de ces stockages à la fois - c'était Nexus et maintenant jFrog Artifactory.) Nous avons d'abord utilisé le Nexus parce que nous avons commencé à pratiquer cette approche dans les applications java (cela lui convenait bien). Ensuite, ils y ont mis la partie des applications écrites par PHP; et le Nexus ne convenait plus, et nous avons donc choisi jFrog Artefactory, qui peut produire presque tout. Nous sommes même venus au fait que dans ce stockage d'artefacts, nous stockons nos propres packages binaires, que nous collectons pour les serveurs.
Croissance de la charge explosive
Nous avons parlé de changer la version du logiciel. La prochaine chose que nous avons est une croissance explosive de la charge. Ici, je comprends probablement que la croissance explosive de la charge n'est pas tout à fait la bonne chose ...
Nous avons écrit un nouveau système - il est orienté services, à la mode, partout, les travailleurs, partout les files d'attente, partout l'asynchronie. Et dans de tels systèmes, les données peuvent suivre un flux différent. Pour la première transaction, le 1er, 3ème, 10ème travailleur peut être impliqué, pour la deuxième transaction - 2ème, 4ème, 5ème. Et aujourd'hui, disons, le matin, vous avez un flux de données qui utilise les trois premiers travailleurs, et le soir, il change radicalement, et tout utilise les trois autres travailleurs.
Et ici, il s'avère que vous devez en quelque sorte faire évoluer les travailleurs, vous devez en quelque sorte faire évoluer vos services, mais en même temps empêcher le gonflement des ressources.

Nous avons déterminé les exigences pour nous-mêmes. : Service discovery, – , – . , , . «», «», .
? . 70 . «», «» , , . 100 «», 100 . . , – 24/7 , , , 70 , .
«», IP Scale-Nomad – ScaleNo, : . , : « ?» – , .
, , , , , – , . 3-5 – .

Comment ça marche? ! : : , – , – , – .
, . 45 – . 2 , ( – , ). – , 5-10 , .
«», , «» . , , – . . № 2 – « ».
. ?
– « ?» ! . ?

!
, , . . , . « ». :

«» «», . «» . «» «» , , – «» «», – «» «» Telegraf.
New Relic. , . , . 1,5 , , : « ». , , . «-» , 15 «-». .
, – Debugger. «», , , «». Qu'est ce que c'est , 15-30 , « » , .
, ( ) – , . , «» – , «» . – , , , .
?
? ?

- Response time / RPS – . , - .
- .
- .
- .
– «», «» . , - , . – ( ). - 5-10-15 – , ( ).
– :
– 6 , – . – RPS, RTS. – «». «» , - … , .
, – . OpenTracing – , , , ; . OpenTracing- , . , , . , , .

, 3 – . , , 20-30 .
, – .
, , , , . , .

? , : (, «»); , . , , … – -. , : « »?
… -, ( ) , . : – , , ( ). , - . ! . .
, .
, – , , , , , - . , , .

( – ), ELK Stack – . -, , ELK, , ELK. .
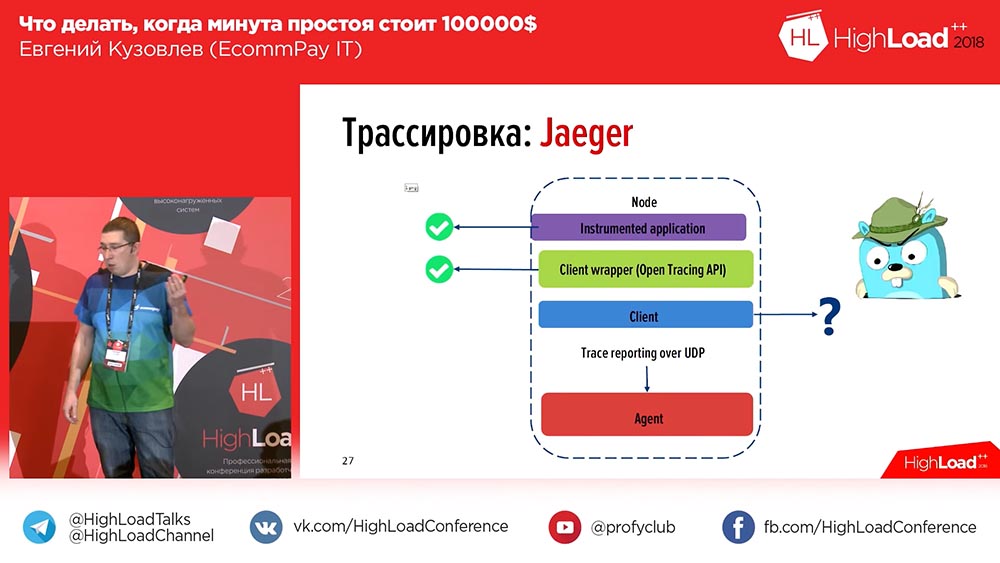
. , , , , «», id- ( ). . Pourquoi? , , . , – OpenTracing, .
, , – «» (Zipkin) «» (Jaeger). «» – , «». «» , , , , . «» .
«»: , Api ( Api PHP , , – , ), . «», – , . ? :
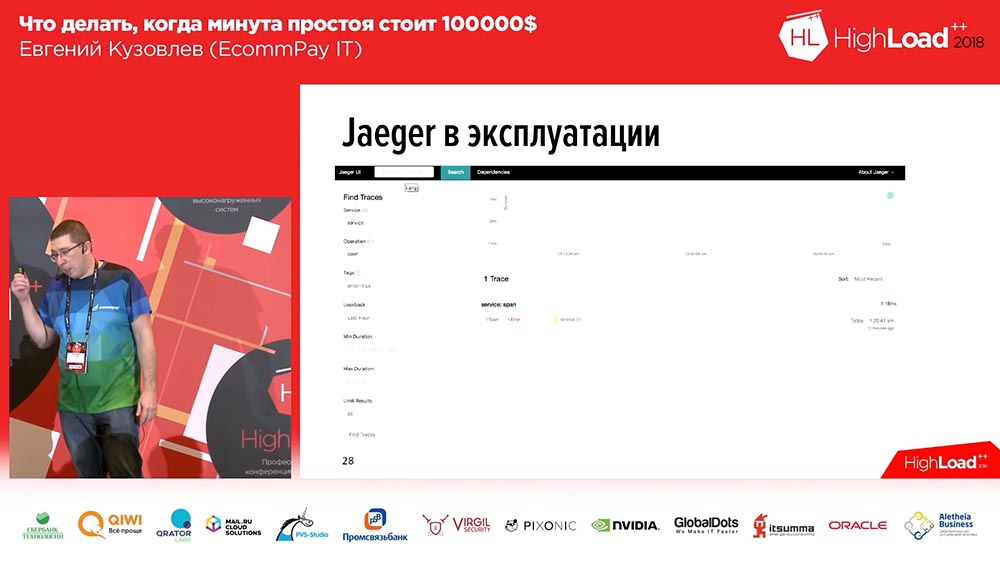
«» span'. , , (1-2-3 – , ). , . , Error. Error , . , span:

. , , . : – , , .
, . , . , «» PHP – , welcome to use, :

– OpenTracing Api, php-extention, . . , . : , extention up to you.
. – . ? :

«»? , ! «» , , , . ?

- . , . 60 , . , , – , .
- . , , RnD-. , (, ) , , .
- , – , . .
- Nous avons des tolérances. Par exemple, nous ne considérons pas les temps d'arrêt si nous avons perdu 2% du trafic en deux minutes. Cela, en principe, ne rentre pas dans nos statistiques. Si plus en pourcentage ou en temps, on compte déjà.
- Et nous écrivons toujours post-mortem. Quoi qu'il nous arrive, toute situation où elle se comporte de manière inappropriée sur le site de production se reflétera dans le potsortem. Un post-mortem est un document dans lequel vous écrivez ce qui vous est arrivé, le calendrier détaillé de ce que vous avez fait pour le réparer et (c'est un bloc obligatoire!) Ce que vous ferez pour éviter que cela ne se reproduise à l'avenir. Cela est nécessaire, nécessaire pour une analyse ultérieure.
Que considérer les temps d'arrêt?

À quoi tout cela a-t-il conduit?
Cela a conduit au fait que (nous avons eu certains problèmes de stabilité, cela ne nous convenait ni aux clients ni à nous) au cours des 6 derniers mois, notre indicateur de stabilité s'est élevé à 99,97. On peut dire que ce n'est pas beaucoup. Oui, nous avons quelque chose à rechercher. Environ la moitié de cet indicateur est la stabilité, pour ainsi dire, pas la nôtre, mais notre pare-feu d'application Web, qui se tient devant nous et est utilisé comme service, mais cela n'a pas d'importance pour les clients.
Nous avons appris à dormir la nuit. Enfin! Il y a six mois, nous ne savions pas comment. Et sur cette note avec les résultats, je veux faire une remarque. Hier soir, il y a eu un merveilleux rapport sur un système de contrôle de réacteur nucléaire. Si les personnes qui ont écrit ce système m'entendent, veuillez oublier ce que j'ai dit à propos de «2% n'est pas un temps d'arrêt». Pour vous, 2% est un temps d'arrêt, même si cela dure deux minutes "!
C’est tout! Vos questions.

À propos des équilibreurs et de la migration de base de données
Question du public (ci-après - B): - Bonsoir. Merci beaucoup pour un tel rapport administrateur! La question est courte au sujet de vos équilibreurs. Vous avez mentionné que vous avez WAF, c'est-à-dire, si je comprends bien, vous utilisez une sorte d'équilibreur externe ...
: - Non, nous utilisons nos services comme équilibreur. Dans ce cas, WAF est pour nous uniquement un outil de protection DDoS.
Q: - Pourriez-vous dire quelques mots sur les équilibreurs?
EK: - Comme je l'ai dit, c'est un groupe de serveurs en openresty. Nous avons maintenant 5 groupes de serveurs redondants qui répondent exclusivement ... c'est-à-dire, un serveur sur lequel est exclusivement ouvert, il ne fait que proxy du trafic. Par conséquent, pour comprendre combien nous détenons: nous avons maintenant un flux de trafic régulier - c'est plusieurs centaines de mégabits. Ils se débrouillent, ils se sentent bien, ils ne se fatiguent même pas.
Q: - Aussi une question simple. Il y a un déploiement bleu / vert. Et que faites-vous, par exemple, avec les migrations à partir de la base de données?
EK: - Bonne question! Regardez, nous dans le déploiement bleu / vert avons des lignes distinctes pour chaque ligne. Autrement dit, si nous parlons des lignes d'événements qui sont transmises du travailleur au travailleur, il existe des lignes distinctes pour la ligne bleue et la ligne verte. Si nous parlons de la base de données elle-même, nous l'avons délibérément réduite, car nous pourrions tout mettre presque en ligne, nous n'avons qu'une pile de transactions dans la base de données. Et nous avons une seule pile de transactions pour toutes les lignes. Avec une base de données dans ce contexte: nous ne la partageons pas avec le bleu et le vert, car les deux versions du code devraient savoir ce qui se passe avec la transaction.
Mes amis, j'ai encore un si petit prix pour vous stimuler - un livre. Et je dois lui donner la meilleure question.
Q: - Bonjour. Merci pour le rapport. La question est la suivante. Vous surveillez les paiements, vous surveillez les services avec lesquels vous communiquez ... Mais comment surveillez-vous pour qu'une personne vienne d'une manière ou d'une autre sur votre page de paiement, effectue un paiement et que le projet lui attribue de l'argent? Autrement dit, comment contrôlez-vous que le marchant est disponible et avez accepté votre rappel?
: - «Marchand» pour nous dans ce cas est exactement le même service externe que le système de paiement. Nous surveillons la vitesse de réponse du "marchand".
À propos du chiffrement de la base de données
Q: - Bonjour. J'ai une petite question. Vous disposez de données PCI DSS sensibles. Je voulais savoir comment vous stockez des PAN dans des files d'attente dans lesquelles vous devez placer? Utilisez-vous un cryptage? Et à partir de là, la deuxième question suivante se pose: sur PCI DSS, il est nécessaire de rechiffrer périodiquement la base de données en cas de changements (licenciement des administrateurs, etc.) - comment cela se produit-il avec l'accessibilité?

EK: - Magnifique question! Premièrement, nous ne stockons pas de PAN dans les files d'attente. Nous n'avons pas le droit de stocker PAN n'importe où en clair, donc en principe, nous utilisons un service spécial (nous l'appelons "Kademon") - c'est un service qui ne fait qu'une chose: il reçoit un message et envoie un message crypté. Et nous stockons tout avec ce message crypté. En conséquence, la longueur clé pour nous est inférieure à kilo-octets, de sorte qu'elle soit directe sérieusement et fiable.
Q: - Avez-vous besoin de 2 kilo-octets maintenant?
EK: - On dirait qu'hier c'était 256 ... Eh bien, où d'autre?!
C'est donc le premier. Et deuxièmement, la solution qui existe, elle prend en charge la procédure de recryptage - il y a deux paires de «gâteaux» (clés) qui donnent des «decks» qui cryptent (les clés sont des clés, dek sont des dérivés des clés qui cryptent). Et dans le cas de l'initiation de la procédure (elle a lieu régulièrement, de 3 mois à ± certains), nous téléchargeons une nouvelle paire de «gâteaux», et nous faisons rechiffrer les données. Nous avons des services séparés qui arrachent toutes les données, les cryptent d'une nouvelle manière; les données sont stockées à côté de l'identifiant de clé avec lequel elles sont cryptées. En conséquence, dès que nos données sont cryptées avec de nouvelles clés, nous supprimons l'ancienne clé.
Parfois, vous devez effectuer des paiements manuellement ...
Q: - Autrement dit, si un retour est venu pour une opération, alors le déchiffrer avec l'ancienne clé?
CE: - Oui.
Q: - Puis une autre petite question. En cas d'échec, de chute, d'incident, il est nécessaire de pousser la transaction en mode manuel. Il y a une telle situation.
EK: - Oui, c'est vrai.
Q: - Où obtenez-vous ces données? Ou allez-vous vous-même avec des stylos dans ce magasin?
EK: - Non, bien sûr - nous avons une sorte de système de back-office qui contient une interface pour notre support. Si nous ne savons pas dans quel état se trouve la transaction (par exemple, alors que le système de paiement n'a pas répondu avec un délai), nous ne savons pas a priori, c'est-à-dire que nous attribuons le statut final uniquement en toute confiance. Dans ce cas, nous transférons la transaction dans un statut spécial pour le traitement manuel. Le matin, le lendemain, dès que le support reçoit des informations indiquant que de telles transactions restent dans le système de paiement, il les traite manuellement dans cette interface.

Q: - J'ai quelques questions. L'un d'eux est la continuation de la zone PCI DSS: comment obtenir leurs journaux de boucle? Une telle question car le développeur pourrait mettre n'importe quoi dans les journaux! Deuxième question: comment déployer les correctifs? Les stylos dans la base de données sont une option, mais il peut y avoir des correctifs logiciels gratuits - quelle est la procédure là-bas? Et la troisième question est probablement liée à RTO, RPO. Votre disponibilité était de 99,97, presque quatre neuf, mais si je comprends bien, vous avez un deuxième centre de données, un troisième centre de données et un cinquième centre de données ... Comment gérez-vous leur synchronisation, leur réplication, tout le reste?
EK: - Commençons par le premier. La première question sur les journaux était? Lorsque nous écrivons des journaux, nous avons une couche qui masque toutes les données sensibles. Elle regarde le masque et les champs supplémentaires. En conséquence, nos journaux contiennent des données déjà masquées et une boucle PCI DSS. C'est l'une des tâches régulières assignées au département de test. Ils sont obligés de vérifier chaque tâche, y compris les journaux qu'ils écrivent, et c'est l'une des tâches régulières de la revue de code, afin de contrôler que le développeur n'a pas écrit quelque chose. Une vérification ultérieure est effectuée régulièrement par le service de la sécurité de l'information environ une fois par semaine: les journaux sont pris de manière sélective pour le dernier jour, et ils sont exécutés à travers un analyseur-scanner spécial à partir de serveurs de test pour vérifier tout cela.
À propos des correctifs. Cela est inclus dans notre calendrier de déploiement. Nous avons un élément distinct sur les correctifs. Nous pensons que nous déployons des correctifs 24h / 24 lorsque nous en avons besoin. Dès que la version est assemblée, dès qu'elle est exécutée, dès que nous avons l'artefact, nous obtenons l'administrateur système sur appel du support, et il le déploiera au moment où cela sera nécessaire.
À propos des «quatre neuf». Le nombre que nous avons maintenant, il a vraiment été atteint, et nous l'avons cherché dans un autre centre de données. Nous avons maintenant un deuxième centre de données, et nous commençons à faire le trajet entre eux, et la question du centre de réplication inter-données est vraiment une question non triviale. Nous avons essayé de le résoudre en temps voulu par différents moyens: nous avons essayé d'utiliser la même "Tarentule" - cela n'a pas fonctionné pour nous, je dis tout de suite. Par conséquent, nous sommes arrivés au fait que nous faisons manuellement l'ordre de la "sensation". Nous avons en effet toutes les applications en mode asynchrone des synchronisations nécessaires "change - done" entre les centres de données.
Q: - Si vous en avez un deuxième, alors pourquoi pas un troisième? Parce que personne n'a encore le cerveau divisé ...
: - Et nous n'avons pas de cerveau divisé. Étant donné que chaque application pilote un multimaître, peu importe le centre auquel la demande est adressée. Nous sommes prêts pour le fait que, dans le cas où un centre de données tombe en panne (nous sommes sur lui) et au milieu de la demande d'un utilisateur transféré vers un deuxième centre de données, nous sommes prêts à perdre cet utilisateur, vraiment; mais ce seront des unités, des unités absolues.
Q: - Bonsoir. Merci pour le rapport. Vous avez parlé de votre débogueur, qui entraîne certaines transactions de test en production. Mais parlez-nous des transactions de test! Jusqu'où va-t-il?
EC: - Il passe par le cycle complet de l'ensemble du composant. Il n'y a aucune différence entre la transaction de test et celle de combat pour le composant. Et du point de vue de la logique, ce n'est qu'un projet distinct dans le système, sur lequel seules les transactions de test sont poursuivies.
Q: - Et où le coupez-vous? Alors Core a envoyé ...
: - Nous sommes derrière "Kor" dans ce cas pour les transactions de test ... Nous avons une chose telle que le routage: "Kor" sait à quel système de paiement envoyer - nous envoyons à un faux système de paiement, qui donne simplement une réponse http et c'est tout .
Q: - Dites-moi s'il vous plaît, avez-vous écrit l'application dans un énorme monolithe, ou l'avez-vous coupé à certains services ou même microservices?
: - Nous n'avons pas de monolithe, bien sûr, nous avons une application orientée services. Nous avons une blague que nous avons un service de monolithes - ils sont vraiment assez grands. Appeler des microservices dans ce langage ne dérive pas du tout du mot, mais ce sont les services au sein desquels travaillent les travailleurs de machines distribuées.
Si le service sur le serveur est compromis ...
Q: - Alors j'ai la question suivante. Même s'il s'agissait d'un monolithe, vous avez quand même dit que vous avez beaucoup de ces serveurs instantanés, ils traitent tous les données en principe, et la question est: «Si l'un des serveurs instantanés ou de l'application, n'importe quel lien particulier est compromis Ont-ils un contrôle d'accès? Lequel d'entre eux peut faire quoi? Qui contacter, pour quelles données?

EK: - Oui, bien sûr. Les exigences de sécurité sont assez sérieuses. Premièrement, nous avons un trafic de données ouvert, et les ports ne sont que ceux sur lesquels nous anticipons le trafic à l'avance. Si le composant communique avec la base de données (par exemple, «Muskul») sur 5-4-3-2, seuls 5-4-3-2 et d'autres ports seront ouverts pour lui, les autres directions de trafic ne seront pas disponibles. De plus, nous devons comprendre qu'en production, nous avons environ 10 boucles de sécurité différentes. Et même si l'application a été compromise d'une manière ou d'une autre, Dieu ne plaise, un attaquant ne pourra pas accéder à la console de gestion du serveur, car il s'agit d'une autre zone de sécurité réseau.
Q: - Et dans ce contexte, je suis plus intéressé par le moment où vous avez des contrats avec des services - que peuvent-ils faire, par quelles «actions» ils peuvent se contacter ... Et dans le flux normal, certains services spécifiques demandent quels une série, une liste "d'action" sur une autre. Ils ne semblent pas se tourner vers les autres dans une situation normale, et ils ont d'autres domaines de responsabilité. Si l'un d'entre eux est compromis, pourra-t-il tirer "l'action" de ce service? ..
EK: - Je comprends. Si dans une situation normale avec un autre serveur, la communication était généralement autorisée, alors oui. Dans le cadre du contrat SLA, nous ne contrôlons pas que vous n'êtes autorisé que les 3 premières «actions», et 4 «actions» ne vous sont pas autorisées. C'est probablement redondant pour nous, car nous avons en principe un système de protection à 4 niveaux pour les circuits. Nous préférons défendre avec des contours plutôt qu'au niveau de l'intérieur.
Comment fonctionnent Visa, MasterCard et Sberbank
Q: - Je veux clarifier un instant sur le passage d'un utilisateur d'un centre de données à un autre. Pour autant que je sache, "Visa" et "MasterCard" fonctionnent sur le protocole synchrone binaire 8583, il existe des mixages. Et je voulais savoir, maintenant je veux dire passer - est-ce directement «Visa» et «MasterCard» ou vers des systèmes de paiement, vers des traitements?
EK: - C'est aux mixes. Mélanges que nous avons dans un centre de données.
Q: - En gros, avez-vous un point de connexion?
: - "Vise" et "MasterCard" - oui. Tout simplement parce que «Visa» et «MasterCard» nécessitent des investissements assez importants dans les infrastructures pour conclure des contrats séparés pour recevoir une deuxième paire de mixages, par exemple. Ils sont réservés dans le cadre d'un centre de données, mais si, à Dieu ne plaise, le centre de données où les mélanges pour se connecter au "Visa" et "MasterCard" sont morts, alors nous aurons une connexion avec le "Visa" et "MasterCard" perdu ...
Q: - Comment peuvent-ils être réservés? Je sais que "Visa" ne permet en principe qu'une seule connexion!
EK: - Ils fournissent eux-mêmes du matériel. Dans tous les cas, nous avons reçu des équipements redondants en interne.
Q: - Autrement dit, le rack de leur Connects Orange? ..
CE: - Oui.
Q: - Mais comme dans ce cas: si votre centre de données disparaît, devez-vous l'utiliser davantage? Ou s'agit-il simplement d'un arrêt du trafic?
CE: - Non. Dans ce cas, nous transférons simplement le trafic vers un autre canal, qui, bien sûr, sera plus cher pour nous, plus cher pour les clients. Mais le trafic ne passera pas par notre connexion directe à la "Visa", "MasterCard", mais par la "Sberbank" conventionnelle (très exagérée).
Je suis extrêmement désolé si j'ai blessé des employés de Sberbank. Mais selon nos statistiques, la Sberbank tombe le plus souvent des banques russes. En moins d'un mois, quelque chose n'est pas tombé chez Sberbank.

Un peu de publicité :)
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en recommandant à vos amis des VPS basés sur le cloud pour les développeurs à partir de 4,99 $ , un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur les VPS (KVM) E5-2697 v3 (6 cœurs) 10 Go DDR4 480 Go SSD 1 Gbit / s à partir de 19 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher au centre de données Equinix Tier IV à Amsterdam? Nous avons seulement 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99 $! Pour en savoir plus sur la création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?