Nous continuons à traiter du travail de GraalVM, et cette fois nous avons une traduction de l'article d'Aleksandar Prokopec «Sous le capot des optimisations GraalVM JIT», initialement publié sur le blog de Medium . L'article contient des liens intéressants, nous essaierons ensuite de traduire ces articles également.

La dernière fois à Medium, nous avons examiné les problèmes de performances de l'API Java Streams sur GraalVM par rapport à Java HotSpot VM. GraalVM se caractérise par des performances élevées, et dans ces expériences, nous avons atteint une accélération de 1,7 à 5 fois. Bien sûr, les valeurs spécifiques du gain de performances dépendront toujours du code que vous exécutez et des données de chargement, donc avant de tirer des conclusions, vous devez essayer d'exécuter votre code sur GraalVM vous-même.
Dans cet article, nous approfondirons l'intérieur de GraalVM et verrons comment se déroule la compilation JIT.
Optimisations JIT dans GraalVM
Jetons un coup d'œil à un certain nombre d'optimisations de haut niveau que le compilateur GraalVM utilise. Dans cet article, nous n'aborderons que les optimisations les plus intéressantes ainsi que des exemples spécifiques de leur travail. Si vous voulez approfondir, une bonne vue d'ensemble des optimisations du compilateur GraalVM est dans le travail intitulé «Optimiser les opérations de collecte avec une compilation JIT agressive» .
Inlining
Si vous ne touchez pas l'assemblage à l'avance, la plupart des compilateurs JIT des machines virtuelles modernes effectuent une analyse en interne. Cela signifie qu'à chaque instant, il y a une analyse d'une méthode. Pour cette raison, l'analyse intraprocédurale est beaucoup plus rapide que l'analyse interprocédurale de l'ensemble du programme, qui n'a généralement pas le temps de terminer dans le temps alloué pour le travail du compilateur JIT. Dans un compilateur qui utilise des optimisations intra-procédurales (par exemple, l'optimisation d'une méthode à la fois), l'une des optimisations fondamentales les plus importantes est l'inline. L'inclusion est importante car elle augmente efficacement la méthode, ce qui signifie que le compilateur peut voir plus d'opportunités pour optimiser simultanément plusieurs morceaux de code utilisés dans des méthodes apparemment sans rapport.
Prenons, par exemple, la méthode volleyballStars d'un article précédent:
@Benchmark public double volleyballStars() { return Arrays.stream(people) .map(p -> new Person(p.hair, p.age + 1, p.height)) .filter(p -> p.height > 198) .filter(p -> p.age >= 18 && p.age <= 21) .mapToInt(p -> p.age) .average().getAsDouble(); }
Dans ce diagramme, nous voyons des parties de la représentation intermédiaire (IR) de cette méthode dans GraalVM, au moment qui suit immédiatement l'analyse du bytecode Java correspondant.

Vous pouvez considérer cet IR comme une sorte d' arbre de syntaxe abstraite sur les stéroïdes - grâce à lui, certaines optimisations sont plus faciles à effectuer. Peu importe le fonctionnement de cet IR, mais si vous souhaitez comprendre ce sujet plus en profondeur, vous pouvez consulter un document intitulé «Graal IR: une représentation intermédiaire déclarative extensible» .
La principale conclusion ici est que le flux de contrôle de la méthode indiquée par les nœuds jaunes du graphique et les lignes rouges exécute séquentiellement les méthodes de l'interface Stream : Stream.filter , Stream.mapToInt , IntStream.average . Faute d'une connaissance précise de ce qui se trouve dans le code de ces méthodes, le compilateur n'est pas en mesure de simplifier la méthode - et ici l'inlining vient à la rescousse!
Une transformation appelée inlining est une chose très compréhensible: elle cherche juste des endroits pour appeler des méthodes et les remplace par le corps de la méthode inline correspondante, les incorpore à l'intérieur. Jetons un coup d'œil à l'IR de la méthode volleyballStars après avoir intégré une partie des méthodes. Seule la partie qui suit l'appel IntStream.average est IntStream.average :

Le diagramme montre que l'appel à getAsDouble (noeud numéro 71) a disparu de l'IR. Notez que la méthode getAsDouble de l'objet getAsDouble renvoyé par IntStream.average (le dernier appel de la méthode volleyballStars ) est définie dans le JDK comme suit:
public double getAsDouble() { if (!isPresent) { throw new NoSuchElementException("No value present"); } return value; }
Ici, nous pouvons trouver le chargement du champ isPresent (numéro de nœud 190, LoadField ) et lire le champ de value . Toutefois, il ne reste aucune trace de l'exception NoSuchElementException et il n'y a plus de code qui la NoSuchElementException .
C'est parce que le compilateur GraalVM suppose: la méthode volleyballStars ne lèvera jamais d'exception. Cette connaissance n'est généralement pas disponible lors de la compilation de getAsDouble - elle peut être appelée depuis de nombreux endroits différents dans le programme, et dans certains autres cas, l'exception fonctionnera toujours. Cependant, dans une méthode particulière de volleyballStars , il est peu probable qu'une exception se produise car l'ensemble des stars potentielles du volleyball n'est jamais vide. Pour cette raison, GraalVM supprime la branche et insère FixedGuard - un nœud qui FixedGuard le code en cas de violation de notre hypothèse. Il s'agit d'un exemple assez minimaliste, et dans la vie réelle, il existe des cas beaucoup plus compliqués de la façon dont l'inclusion aide d'autres optimisations.
Nous savons que l'arborescence des appels de programme est généralement très profonde, voire infinie. Par conséquent, l'incrustation à un moment donné doit être arrêtée - elle a des restrictions très spécifiques sur le temps de fonctionnement et la taille de la mémoire. Sachant cela, il devient clair: déterminer quoi et quand s'aligner est très difficile.
Doublure polymorphe
L'inclusion ne fonctionne que si le compilateur peut déterminer la méthode spécifique à laquelle l'opération d'appel de méthode est destinée. Mais en Java, il existe généralement de nombreux appels indirects pour les méthodes dont les implémentations sont inconnues en statique, qui sont recherchées lors de l'exécution à l'aide de la répartition virtuelle.
Par exemple, prenez la méthode IntStream.average . Son implémentation typique ressemble à ceci:
@Override public final OptionalDouble average() { long[] avg = collect( () -> new long[2], (ll, i) -> { ll[0]++; ll[1] += i; }, (ll, rr) -> { ll[0] += rr[0]; ll[1] += rr[1]; }); return avg[0] > 0 ? OptionalDouble.of((double) avg[1] / avg[0]) : OptionalDouble.empty(); }
Ne laissez pas l'apparente simplicité du code vous tromper! Cette méthode est définie en termes d'appels à collect , et la magie opère ici. L'arborescence des appels de cette méthode (par exemple, la hiérarchie des appels) se développe rapidement à mesure que nous approfondissons la collect . Jetez un œil à ce diagramme:
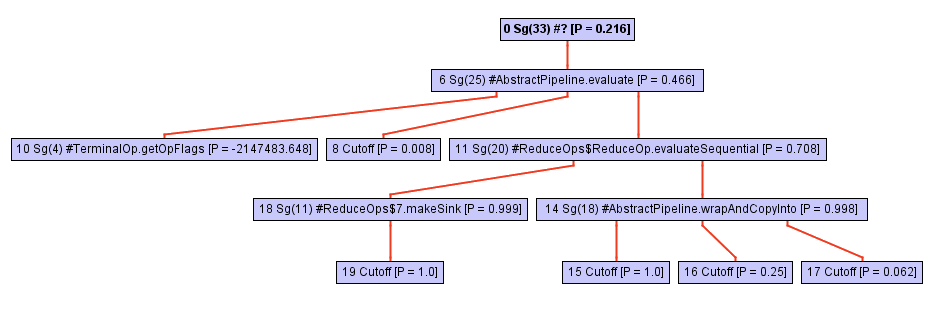
À partir d'un certain point du processus de traversée de l'arborescence des appels, l'inliner repose contre l'appel opWrapSink du framework de opWrapSink Java, qui est une méthode abstraite:

abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
Habituellement, un inliner n'ira pas plus loin, car il s'agit d'un appel indirect. La détermination d'une méthode spécifique ne se produira que pendant l'exécution du programme, et maintenant l'incrustateur ne sait tout simplement pas sur quoi il continuera de travailler.
Dans le cas de GraalVM, quelque chose d'autre se produit: il enregistre un profil du type de la méthode cible pour chaque point d'appel indirect. Ce profil est essentiellement juste un tableau qui indique à quelle fréquence chacune des implémentations de wrapSink été wrapSink . Dans notre cas, le profil connaît trois implémentations différentes dans les classes anonymes: ReferencePipeline$2 , ReferencePipeline$3 , ReferencePipeline$4 . Ces implémentations sont appelées avec une probabilité de 50%, 25% et 25%, respectivement.
0.500000: Ljava/util/stream/ReferencePipeline$2; 0.250000: Ljava/util/stream/ReferencePipeline$4; 0.250000: Ljava/util/stream/ReferencePipeline$3; notRecorded: 0.000000
Ces informations fournissent une assistance inestimable au compilateur, vous permettant de générer typeswitch - une courte switch qui vérifie le type de la méthode lors de l'exécution, puis appelle une méthode spécifique pour chacun des cas ci-dessus. L'image ci-dessous montre une partie de la vue intermédiaire montrant un commutateur de type (trois if nœuds) avec une vérification pour voir si le type de destinataire est quelqu'un de ReferencePipeline$2 , ReferencePipeline$3 ou ReferencePipeline$4 . Chaque appel direct dans le branchement réussi de chacune des vérifications InstanceOf peut maintenant être en ligne ou y connecter des optimisations supplémentaires. Si aucun des types ne réussit le test, le code est désoptimisé dans le nœud Deopt (comme alternative, vous pouvez exécuter la répartition virtuelle).

Si vous voulez mieux comprendre l'incrustation polymorphe, je recommande le travail classique sur ce sujet, «Inlining of Virtual Methods» .
Analyse d'échappement partielle
Revenons à notre exemple de volleyball. Notez Person objets Person alloués à l'intérieur du lambda passé à la fonction map n'échappe à la portée de la méthode volleyballStars . En d'autres termes, au moment où la méthode volleyballStars se termine, il n'y a pas une telle zone de mémoire qui pointerait vers des objets de type Person . En particulier, l'enregistrement de la valeur getHeight est en outre utilisé uniquement pour le filtrage de la hauteur.
À un moment donné lors de la compilation de la méthode volleyballStars , nous arrivons à l'IR montré dans le diagramme ci-dessous. Le bloc commençant par le nœud Begin -1621 commence par l'allocation de l'objet Person (dans le nœud Alloc ), qui est initialisé à la fois avec la valeur du champ age avec un incrément de 1 et la valeur précédente du champ height . Le champ de height est précédemment lu dans le nœud LoadField -1539. Le résultat de l'allocation est encapsulé dans AllocatedObject -2137 et envoyé à l'appel de méthode accept -1625. Le compilateur ne peut rien faire de plus en ce moment - de son point de vue, l'objet s'est échappé de la méthode volleyballStars . ( Note du traducteur: «fuir un objet» est appelé «échapper» en anglais, d'où le nom de l'optimisation est «analyse d'échappement» ).

Après cela, le compilateur décide d'insérer l'appel d' accept - cela semble raisonnable. En conséquence, nous arrivons à l'IR suivant:
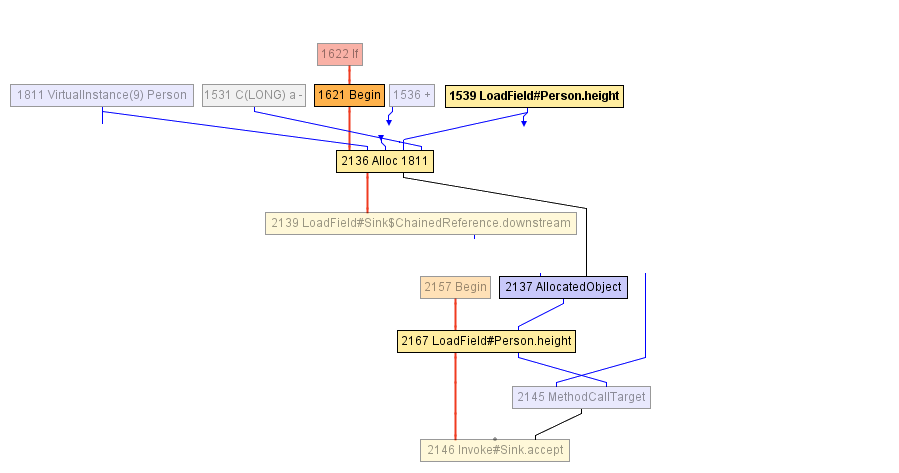
Et ici, le compilateur JIT commence une analyse d'échappement partielle: il remarque que AllocatedObject utilisé que pour lire le champ height (rappel, la height utilisée que dans la condition de filtrage, vérifiez que la hauteur est supérieure à 198). Par conséquent, le compilateur peut réaffecter la lecture du champ height -2167 afin de travailler directement avec le nœud qui est précédemment écrit dans l'objet Person (nœud Alloc -2136), et c'est notre LoadField -1539. De plus, le nœud Alloc ci-après ne va pas à l'entrée d'un autre nœud, vous pouvez donc simplement le supprimer - c'est du code mort!
Cette optimisation est, en fait, la principale raison pour laquelle l'exemple volleyballStars connu une accélération quintuple après le passage à GraalVM. Même si tous les objets Person ne sont pas nécessaires et sont supprimés immédiatement après leur création, ils doivent toujours être alloués sur le tas, leur mémoire doit encore être initialisée. L'analyse d'échappement partielle vous permet d'éliminer les allocations ou de les reporter en les déplaçant vers les branches de code où les objets s'enfuient vraiment et qui se produisent beaucoup moins souvent.
Vous pouvez obtenir une compréhension plus approfondie de l'analyse d'échappement partielle dans un article intitulé Analyse d'échappement partielle et remplacement scalaire pour Java .
Résumé
Dans cet article, nous avons examiné trois optimisations GraalVM: l'incrustation, l'incrustation polymorphe et l'analyse d'échappement partielle. Il existe de nombreuses autres optimisations différentes: promotion et fractionnement des cycles, duplication des chemins, numérotation des valeurs globales, convolution des constantes, suppression du code mort, exécution spéculative, etc.
Si vous souhaitez en savoir plus sur le fonctionnement de GraalVM, n'hésitez pas à ouvrir la page de publication . Si vous voulez vous assurer que GraalVM peut accélérer votre code, vous pouvez télécharger les binaires et l'essayer vous-même.
Du traducteur: matériel supplémentaire
Lors de conférences, JPoint et Joker parlent souvent de GraalVM. Par exemple, au dernier JPoint 2019, Thomas Wuerthinger (directeur de recherche chez Oracle Labs, responsable de GraalVM) et Oleg Shelaev, l'un des deux évangélistes technologiques officiels, nous ont rendu visite.
Vous pouvez regarder ces vidéos et d'autres sur notre chaîne YouTube:
Nous vous rappelons que le prochain JPoint se tiendra du 15 au 16 mai 2020 à Moscou, et les billets peuvent déjà être achetés sur le site officiel .