Bonjour à tous! Je suis développeur backend, j'écris des microservices en Java + Spring. Je travaille dans l'une des équipes internes de développement de produits Tinkoff.

Notre équipe pose souvent la question de l'optimisation des requêtes dans le SGBD. Vous voulez toujours un peu plus rapide, mais vous ne pouvez pas toujours vous en tirer avec des index bien conçus - vous devez rechercher des solutions de contournement. Au cours d'une de ces errances sur le net à la recherche d'optimisations raisonnables lors de l'utilisation de la base de données, j'ai trouvé le blog infiniment utile de Marcus Vinand , auteur de SQL Performance Explained. C'est le type de blog très rare où vous pouvez lire tous les articles d'affilée.
Je veux traduire pour vous un court article de Marcus. Il peut être appelé, dans une certaine mesure, un manifeste qui cherche à attirer l'attention sur le problème ancien mais toujours pertinent des performances de l'opération de décalage selon la norme SQL.
Dans certains endroits, je compléterai l'auteur par des explications et des remarques. Je désignerai tous ces endroits par "environ" pour plus de clarté.
Petite introduction
Je pense que beaucoup de gens savent à quel point il est problématique et inhibiteur de travailler avec des sélections paginales par décalage. Mais saviez-vous qu'il peut être tout simplement remplacé par un design plus productif?
Ainsi, le mot clé offset indique à la base de données d'ignorer les n premières entrées de la demande. Cependant, la base de données doit encore lire ces n premiers enregistrements à partir du disque, et dans l'ordre spécifié (remarque: appliquer le tri si un est spécifié), et seulement après cela, il sera possible de renvoyer des enregistrements à partir de n + 1. La chose la plus intéressante est que le problème n'est pas dans l'implémentation concrète dans le SGBD, mais dans la définition initiale selon la norme:
... les lignes sont d'abord triées en fonction de la <clause order by> puis limitées en supprimant le nombre de lignes spécifié dans la <clause offset résultat> depuis le début ...
-SQL: 2016, partie 2, 4.15.3 Tables dérivées (note: maintenant la norme la plus utilisée)
Le point clé ici est que l'offset prend un seul paramètre - le nombre d'enregistrements à ignorer, et c'est tout. Suivant cette définition, un SGBD ne peut obtenir que tous les enregistrements, puis éliminer ceux qui ne sont pas nécessaires. De toute évidence, une telle définition de l'offset vous oblige à faire un travail supplémentaire. Et peu importe qu'il s'agisse de SQL ou de NoSQL.
Un peu plus de douleur
Les problèmes de compensation ne s'arrêtent pas là, et voici pourquoi. Si une autre opération insère un nouvel enregistrement entre la lecture de deux pages de données du disque, que se passera-t-il dans ce cas?
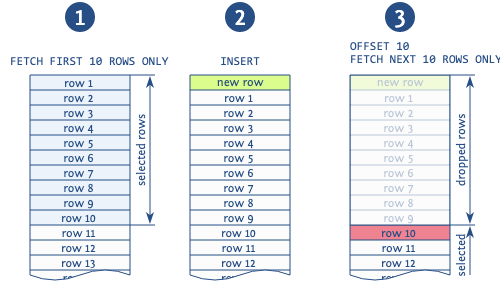
Lorsque l'offset est utilisé pour ignorer les enregistrements des pages précédentes, dans le cas de l'ajout d'un nouvel enregistrement entre les opérations de lecture de différentes pages, vous obtiendrez probablement des doublons (remarque: cela est possible lorsque nous lisons page par page en utilisant la commande par construction, puis au milieu de notre sortie peut obtenir un nouveau record).
La figure illustre clairement une telle situation. La base lit les 10 premiers enregistrements, après quoi un nouvel enregistrement est inséré, ce qui décale tous les enregistrements lus de 1. Ensuite, la base prend une nouvelle page à partir des 10 enregistrements suivants et commence non pas à partir du 11 comme il se doit, mais à partir du 10, en dupliquant cet enregistrement. Il existe d'autres anomalies associées à l'utilisation de cette expression, mais c'est la plus courante.
Comme nous l'avons déjà découvert, ce ne sont pas des problèmes d'un SGBD particulier ou de leur implémentation. Le problème est la définition de la pagination selon la norme SQL. Nous indiquons au SGBD la page à obtenir ou le nombre d'enregistrements à ignorer. La base n'est tout simplement pas en mesure d'optimiser une telle demande, car il y a trop peu d'informations pour cela.
Il convient également de préciser qu'il ne s'agit pas d'un problème de mot clé spécifique, mais plutôt de la sémantique des requêtes. Il existe plusieurs syntaxes identiques en termes de problématique:
- Le mot clé offset, comme mentionné précédemment.
- La construction des deux mots clés limit [offset] (bien que la limite elle-même ne soit pas si mauvaise).
- Filtrage de limite inférieure basé sur la numérotation des lignes (par exemple row_number (), rownum, etc.).
Toutes ces expressions indiquent simplement le nombre de lignes à ignorer, pas d'informations supplémentaires ni de contexte.
Plus loin dans cet article, le mot clé offset est utilisé comme généralisation de toutes ces options.
La vie sans compensation
Imaginez maintenant à quoi ressemblerait notre monde sans tous ces problèmes. Il s'avère que la vie sans décalage n'est pas si compliquée: vous pouvez sélectionner uniquement les lignes que nous n'avons pas vues (remarque: c'est-à-dire celles qui n'étaient pas sur la dernière page) en utilisant la condition dans où.
Dans ce cas, nous nous appuyons sur le fait que les sélections sont exécutées sur un ensemble ordonné (bon ancien ordre par). Puisque nous avons un ensemble ordonné, nous pouvons utiliser un filtre assez simple pour obtenir uniquement les données qui se trouvent derrière le dernier enregistrement de la page précédente:
SELECT ... FROM ... WHERE ... AND id < ?last_seen_id ORDER BY id DESC FETCH FIRST 10 ROWS ONLY
C'est tout le principe de cette approche. Bien sûr, lors du tri par plusieurs colonnes, tout devient plus amusant, mais l'idée est la même. Il est important de noter que cette construction est applicable à de nombreuses solutions N o S Q L.
Cette approche est appelée méthode de recherche ou pagination par jeu de clés. Il résout le problème avec un résultat flottant (note: la situation avec l'écriture entre les lectures de page, décrite plus haut) et, bien sûr, que nous aimons tous, fonctionne plus rapidement et plus stable que l'offset classique. La stabilité réside dans le fait que le temps de traitement des requêtes n'augmente pas proportionnellement au nombre de la table demandée (remarque: si vous souhaitez en savoir plus sur le travail des différentes approches de la pagination, vous pouvez parcourir la présentation de l'auteur . Vous pouvez également trouver des benchmarks comparatifs en utilisant différentes méthodes).
Une des diapositives indique que la pagination des touches n'est bien sûr pas omnipotente - elle a ses propres limites. Plus important - elle n'a pas la capacité de lire des pages au hasard (remarque: incohérente). Cependant, à l'ère du défilement sans fin (note: sur le front end), ce n'est pas un tel problème. La spécification du numéro de page pour un clic est en tout cas une mauvaise décision lors du développement d'une interface utilisateur (note: avis de l'auteur de l'article).
Et les outils?
La pagination des touches n'est souvent pas appropriée en raison du manque de support instrumental pour cette méthode. La plupart des outils de développement, y compris divers cadres, ne donnent pas le choix de la manière dont la pagination sera effectuée.
La situation est aggravée par le fait que la méthode décrite nécessite une prise en charge de bout en bout des technologies utilisées - du SGBD à l'exécution de la requête AJAX dans le navigateur avec un défilement sans fin. Au lieu de spécifier uniquement le numéro de page, vous devez maintenant spécifier un ensemble de clés pour toutes les pages à la fois.
Cependant, le nombre de cadres prenant en charge la pagination clé augmente progressivement. Voici ce qui est en ce moment:
(Remarque: certains liens ont été supprimés car, au moment de la traduction, certaines bibliothèques n'étaient pas mises à jour de 2017 à 2018. Si vous êtes intéressé, vous pouvez consulter la source.)
C'est à ce moment que votre aide est nécessaire. Si vous développez ou prenez en charge un cadre qui utilise en quelque sorte la pagination, alors je demande, je vous exhorte, je vous prie de faire un support natif pour la pagination clé. Si vous avez des questions ou avez besoin d'aide, je serai heureux de vous aider ( forum , Twitter , formulaire de contact ) (remarque: d'après mon expérience avec Marcus, je peux dire qu'il est vraiment enthousiaste à l'idée de diffuser ce sujet).
Si vous utilisez des solutions prêtes à l'emploi qui, selon vous, méritent d'être prises en charge pour la pagination des clés, créez une demande ou même proposez une solution toute faite, si possible. Vous pouvez également spécifier cet article dans le lien.
Conclusion
La raison pour laquelle une approche aussi simple et utile que la pagination des clés n'est pas répandue n'est pas qu'elle est difficile à mettre en œuvre sur le plan technique ou qu'elle nécessite de gros efforts. La raison principale est que beaucoup sont habitués à voir et à travailler avec l'offset - cette approche est dictée par la norme elle-même.
En conséquence, peu de gens pensent à changer l'approche de la pagination, et à cause de cela, le soutien instrumental des frameworks et des bibliothèques se développe mal. Par conséquent, si vous êtes proche de l'idée et de l'objectif de la pagination sans tracas, contribuez à la diffuser!
Source: https://use-the-index-luke.com/no-offset
Publié par: Markus Winand