 Voici une liste mise à jour des plus beaux "goodies" Unicode, ainsi que des packages et des ressources
Voici une liste mise à jour des plus beaux "goodies" Unicode, ainsi que des packages et des ressourcesUnicode est génial! Avant son apparition, la communication internationale était épuisante: chacune définissait son propre jeu de caractères étendu séparé dans la moitié supérieure de l'ASCII (les soi-disant pages de codes). Cela a créé un conflit. Pensez simplement que les Allemands ont dû négocier avec les Coréens, où se trouve la page de codes. Heureusement, Unicode est apparu et a introduit une norme commune. Unicode 8.0 couvre plus de 120 000 caractères de plus de 129 scripts. À la fois moderne et ancien, et toujours pas décrypté. Unicode prend en charge le texte de gauche à droite et de droite à gauche, superpose les caractères et comprend une variété de symboles et d'émojis culturels, politiques, religieux. Unicode est incroyablement humain et ses capacités sont largement sous-estimées.
Table des matières
Brève introduction
Quels caractères sont inclus dans Unicode Standard?
La norme Unicode définit les codes des caractères dans les principales langues modernes. Ce sont des scripts alphabétiques européens, des scripts du Moyen-Orient de droite à gauche et de nombreux scripts asiatiques.
La norme contient également des signes de ponctuation, des signes diacritiques, des symboles mathématiques, des symboles techniques, des flèches, des dingbats, des emojis, etc. Elle fournit des codes pour les signes diacritiques qui changent les signes de caractères, tels que les tildes (~). Ils sont utilisés en combinaison avec ceux de base pour représenter des caractères accentués (par exemple, ñ). En général, la version 9.0 d'Unicode fournit des codes pour 128 172 caractères des alphabets du monde, des jeux d'idéogrammes et des collections de caractères.
Les caractères les plus courants sont placés dans les premiers 64K points de code, une zone de l'espace de code appelée le plan multilingue principal, ou BMP pour faire court. Il y a seize autres plans supplémentaires disponibles pour encoder d'autres caractères, avec plus de 850 000 points de code inutilisés. Ils peuvent être utiles pour ajouter de nouveaux personnages aux futures versions de la norme.
La norme Unicode réserve également des points de code pour un usage privé. Les fournisseurs ou les utilisateurs finaux peuvent les désigner dans leurs propres systèmes pour leurs personnages ou les utiliser avec des polices spécialisées. Le BMP a 6400 points de code pour un usage privé et 131 068 points de code supplémentaires pour un usage privé, si 6400 n'est pas suffisant pour des applications spécifiques.
Encodages de caractères Unicode
Les normes de codage de caractères déterminent non seulement l'identité de chaque caractère et sa valeur numérique ou point de code, mais également la façon dont cette valeur est représentée en bits.
La norme Unicode définit trois formes de codage qui permettent la transmission des mêmes données: un octet, un mot et un double mot (c'est-à-dire 8, 16 ou 32 bits par unité de code). Les trois formulaires codent le même jeu de caractères commun et peuvent être efficacement convertis les uns aux autres sans perte de données. Le consortium Unicode approuve pleinement l'utilisation de l'une de ces formes de codage comme moyen convenu de mettre en œuvre la norme Unicode.
UTF-8 est populaire pour le HTML et les protocoles similaires. UTF-8 est un moyen de convertir tous les caractères Unicode en un codage à longueur d'octet variable. Son avantage est que les caractères Unicode qui correspondent à l'ensemble ASCII familier ont les mêmes valeurs d'octet que ASCII, et les caractères Unicode convertis en UTF-8 peuvent être utilisés avec de nombreux logiciels existants sans modifications majeures du logiciel.
UTF-16 est populaire dans de nombreux environnements où il est nécessaire d'équilibrer un accès efficace aux caractères avec un stockage économique. Il est assez compact et tous les caractères fréquemment utilisés sont placés dans un bloc de code 16 bits, tandis que tous les autres caractères sont disponibles via des paires de blocs de code 16 bits.
UTF-32 est utile lorsque la quantité de mémoire n'est pas un problème, mais nécessite l'accès aux caractères dans un seul code à largeur fixe. Ici, chaque caractère Unicode est codé dans un seul bloc de code 32 bits.
Les trois formes de codage ne nécessitent pas plus de 4 octets (ou 32 bits) pour chaque caractère.
Parlez de chiffres
Le jeu de caractères Unicode est divisé en 17 segments principaux (plans), qui sont ensuite divisés en blocs. Dans chaque avion, il y a une place pour 65 536 (2
16 ) points de code, ce qui crée un total de 1 114 112 points de code. Il existe deux «avions à usage privé» (n ° 16 et n ° 17) qui sont attribués à la discrétion des entreprises / utilisateurs. Ils ont 131 072 points de code.
Le premier avion est appelé le principal avion multilingue ou BMP. Il contient des points de code de U + 0000 à U + FFFF, c'est-à-dire les caractères les plus couramment utilisés. Les seize plans restants (U + 010000 → U + 10FFFF) sont appelés supplémentaires ou astraux.
Paires de substitution UTF-16
Les symboles en dehors du plan principal, comme un tétragramme qui signifie le centre (U + 1D306), peuvent être encodés en UTF-16 avec seulement deux unités de code 16 bits: 0xD834 0xDF06. C'est ce qu'on appelle une paire de substitution. Veuillez noter qu'une paire de substitution ne représente qu'un seul caractère.
La première unité de code d'une paire de substitution se situe toujours dans la plage de 0xD800 à 0xDBFF et est appelée la partie supérieure de la paire.
La deuxième unité de code de la paire de substitution se situe toujours dans la plage de 0xDC00 à 0xDFFF et est appelée le bas de la paire.
Matthias Binens
Paire de substitution: représentation d'un symbole abstrait, consistant en une séquence de deux unités de code de 16 bits, où la première valeur de la paire est l'unité de code de substitution supérieure et la seconde est l'unité de code de substitution inférieure. Les paires de substitution ne sont utilisées qu'en UTF-16.
Unicode 8.0 Chapitre 3.8 - Surrogates
Calcul des paires de substitution
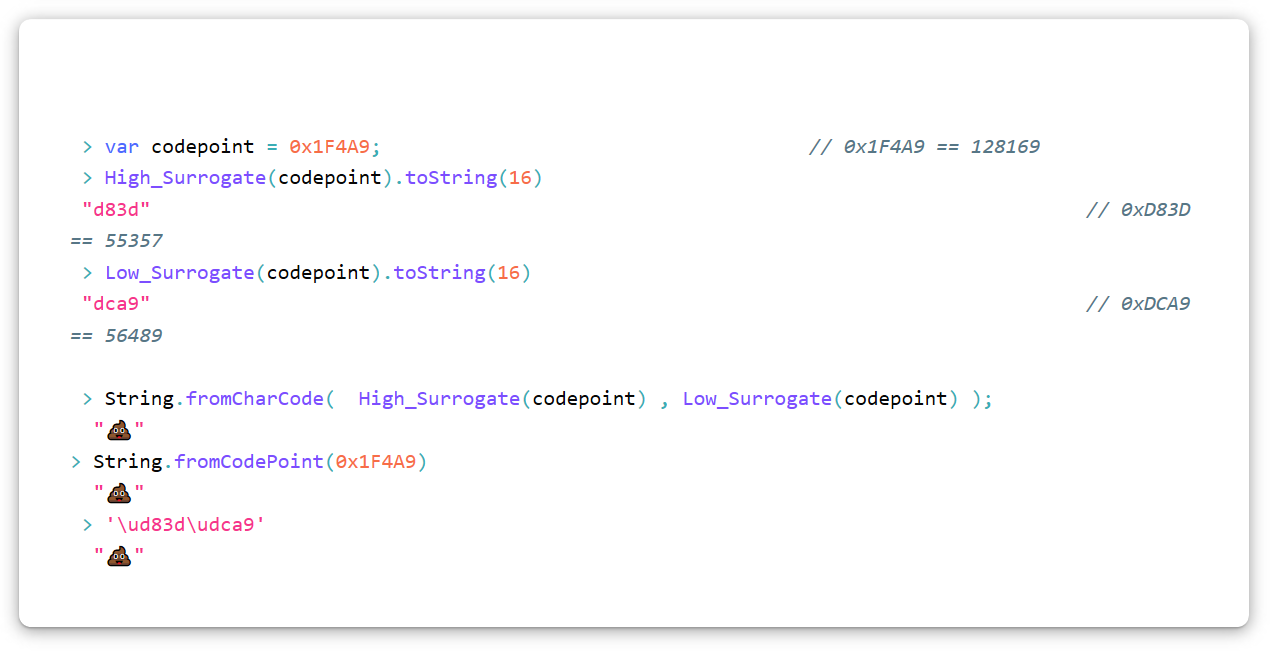
Le caractère Unicode «Pile of shit» (U + 1F4A9) dans UTF-16 devra être codé comme une paire de substitution, c'est-à-dire deux substituts. Pour convertir n'importe quel point de code en une paire de substitution, utilisez cet algorithme (en JavaScript). Gardez à l'esprit que nous utilisons la notation hexadécimale.
var High_Surrogate = function(Code_Point){ return Math.floor((Code_Point - 0x10000) / 0x400) + 0xD800 }; var Low_Surrogate = function(Code_Point){ return (Code_Point - 0x10000) % 0x400 + 0xDC00 };
Composition et décomposition
Unicode comprend un mécanisme pour changer la forme d'un caractère, ce qui étend considérablement l'ensemble de glyphes pris en charge. Cela s'applique aux diacritiques combinables. Ils sont insérés après le personnage principal. Plusieurs marques diacritiques peuvent être appliquées à la même marque. Unicode contient également des versions précompilées de la plupart de ces combinaisons pour une utilisation normale.
Certaines séquences de caractères peuvent également être représentées comme un seul caractère appelé caractère précomposé, alias caractère composite. Par exemple, le caractère [ü] peut être codé comme le seul point de code U + 00FC ou comme le caractère de base U + 0075 (u), suivi du caractère non autonome U + 0308 (¨). La norme Unicode code les caractères composés pour la compatibilité avec les normes établies, telles que Latin 1, qui comprend de nombreux caractères composés, tels que [ü] et [ñ].
Les caractères composés peuvent être développés pour des raisons de cohérence ou d'analyse. Par exemple, lors du tri alphabétique, le symbole [ü] peut être décomposé en [u] suivi du symbole non indépendant [¨]. Après une telle décomposition, l'algorithme est plus facile à travailler avec une séquence de caractères. Cela facilite le tri dans les langues où les modificateurs de caractères n'affectent pas l'ordre alphabétique. La norme Unicode définit l'
ordre de décomposition pour tous les caractères composites. Il définit également des formes de normalisation pour fournir des représentations uniques de personnages.
Mythes Unicode
Extrait des diapositives de la présentation de Mark Davis "Mythes of Unicode" .- Unicode n'est qu'un code 16 bits . - Certaines personnes croient à tort que Unicode est juste un code 16 bits, dans lequel chaque caractère occupe 16 bits, et donc il y a 65 536 caractères possibles. En fait, ce n'est pas entièrement vrai. C'est le mythe Unicode le plus courant, donc si vous le pensiez aussi avant, ne vous découragez pas.
- Vous pouvez prendre n'importe quel point de code qui n'est pas utilisé pour vos besoins . - Non. Un jour, cet endroit sera remplacé par un autre symbole. Au lieu de cela, utilisez des avions pour un usage privé ou des zones sans caractères dans chaque avion où il n'y aura pas de caractères par défaut.
- Chaque point de code Unicode représente un caractère . - Non. Il existe de nombreux points sans caractères (FFFE, FFFF, 1FFFE, etc.). De plus, des points de code de substitution, des points de code privés et inutilisés, ainsi que des "caractères" de contrôle / formatage (RLM, ZWNJ, etc.)
- Unicode manque d'espace . - S'il se remplissait linéairement, il se serait terminé en 2140. Mais l'endroit ne se remplit pas linéairement. Plans futurs voir ici .
- Tous les personnages sont appariés un à un . - Non. Les options sont les suivantes:
- Un à plusieurs: (β → SS)
- Compte tenu du contexte: (... Σ ← → ... ς et en même temps ... ΣΤ ... ← → ... στ ...)
- En fonction des paramètres régionaux: (I ← → ı et en même temps © ← → i)
Encodages d'application Unicode
Code source
Liste de personnages incroyables.
Le partage d'un document peut rapidement transformer l'édition en une bataille écrite de rap, menée par un arrangement de plus en plus confus de gestionnaires de U + 202a à U + 202eCaractères spéciaux
Le Consortium Unicode a publié
un diagramme de ponctuation général où vous pouvez trouver plus d'informations.
Attendez ... qu'est-ce que je viens de lire?Les identifiants variables peuvent inclure des espaces!
L'espace réservé U + 3164 Hangul s'affiche sous la forme d'un grand espace. Si le caractère n'est clairement pas
pris en charge dans le rendu , il est alors affiché comme complètement invisible (et ne prend pas d'espace, c'est-à-dire "largeur nulle"). Cela signifie que vous ne verrez jamais un caractère de remplacement de caractère laid ( ).
Je ne sais pas encore pourquoi U + 3164 est chargé de se comporter de cette façon. Fait intéressant, U + 3164 a été ajouté à Unicode dans la version 1.1 (1993) - les spécialistes du Consortium ont donc eu beaucoup de temps pour y réfléchir. Quoi qu'il en soit, voici quelques exemples.
> var ᅟ = 'foo'; undefined > ᅟ 'foo' > var ㅤ= alert; undefined > var foo = 'bar' undefined > if ( foo ===ㅤ`baz` ){}
** Remarque: ** J'ai testé le rendu U + 3164 sur Ubuntu et OS X avec les paramètres suivants: `node`,` php`, `ruby`,` python3.5`, `scala`,` vim`, `cat` , `chrome` +` gistub gist '. Atom est le seul système qui échoue en affichant (incorrectement) des champs vides. Je n'ai pas encore vérifié le code dans Emacs et Sublime. Si je comprends bien, le consortium Unicode ne réaffectera pas ou ne renommera pas les caractères ou les points de code, mais il peut être persuadé de modifier les propriétés de caractères tels que ID_Start et ID_Continue.Modificateurs
Zero Width Combiner (ZWJ) est un caractère non imprimable dans un ensemble informatique de certaines polices complexes, telles que l'arabe ou toute police indienne. Lorsqu'il est placé entre deux caractères qui autrement ne seraient pas connectés, ZWJ les force à imprimer sous une forme combinée.
Le Zero Width Disconnector (ZWNJ) est un caractère non imprimable dans les ensembles d'écriture informatisés avec ligatures. Lorsqu'il est placé entre deux caractères qui autrement seraient combinés en une ligature, ZWNJ les oblige à imprimer dans leurs formes finale et originale, respectivement. Agit comme un espace, mais est utilisé lorsqu'il est souhaitable de garder des mots proches les uns des autres ou de combiner un mot avec son morphème.
> 'a' "a" > 'a\u{0308}' "ä" > 'a\u{20DE}\u{0308}' "a⃞̈" > 'a\u{20DE}\u{0308}\u{20DD}' "a⃞̈⃝"
Collisions de transformées en majuscules
Collisions de conversion en minuscules
Quirks et dépannage
- La longueur de ligne est généralement déterminée par le nombre de points de code . Cela signifie que les paires de substitution seront considérées comme deux caractères. Plusieurs diacritiques peuvent être superposés à un symbole:
a + ̈ == ̈a . Cela augmente la longueur de la chaîne, ne produisant qu'un seul caractère.
- De même, l'inversion de chaîne devient souvent une tâche non triviale . Encore une fois, les paires de substitution et les diacritiques doivent être inversés ensemble. ES Reverser offre une assez bonne solution.
- Les comparaisons majuscules et minuscules ne correspondent pas toujours . Ils peuvent s'exprimer dans de telles relations:
- Un à plusieurs: (ß → SS)
- Compte tenu du contexte: (... Σ ← → ... ς et ... ΣΤ ... ← → ... στ ...)
- En fonction des paramètres régionaux: (I ← → ı et İ ← → i)
Une à plusieurs comparaisons
La plupart des caractères ci-dessous expriment leurs correspondances un-à-plusieurs en majuscules et d'autres en minuscules. En principe, la liste peut être divisée en deux parties.
Grands packages et bibliothèques
- PhantomScript -: ghost :: flashlight: Exécution de JavaScript invisible et d'ingénierie sociale
- ESReverser - Gestion des chaînes JavaScript basées sur Unicode .
- mimic - Utilisation abusive d'Unicode
- python-ftfy - Tente de créer la représentation maximale correcte et complète du texte reçu en Unicode.
- vim-troll-stopper - Protégez votre code des trolls unicode.
Emoji
Unicode (diversity), . .
, , . — . :
, .
8.0 ( 2015 ) - . , ( , FitzpatrickSkinType.pdf). .
Unicode
, \u{1F466}\u{1F3FE} .

+

→


JavaScript (ES6)
, ID_START , . , ID_CONTINUE , .
CSS .
<!-- place this within the document head --> <meta charset="UTF-8" /> <div class="ಠ_ಠ">You do not have access to this page.</div> <div class="">Your changes have been saved successfully!</div>
.ಠ_ಠ { border: 1px solid #f00; } . { background: lightgreen; }
HTML
HTML- , , .
, HTML .
:
function testBegin(str){ try{ eval(`document.createElement( '${str}' );`) return true; } catch(e){ return false; } } function testContinue(str){ try{ eval(`document.createElement( 'a${str}' );`) return true; } catch(e){ return false; } }
:
TrueType OpenType UTF-8, 65 535 . 1,1 UTF-8, .
256 .

, () (CJK). , , « ».
. 17- .
:
- — - .
- — , .
- — .
- — , . .
- , — , . , .
- — , . , [Ä] [A] [¨].
- — .
- — , , . .
- — , .
- — .
: c codepoints.net .