
Chez Serokell, nous sommes non seulement engagés dans des projets commerciaux, mais nous nous efforçons également de changer le monde pour le mieux. Par exemple, nous travaillons à l'amélioration de l'outil principal de toutes les Haskelists - le Glasgow Haskell Compiler (GHC). Nous nous sommes concentrés sur l'expansion du système de types sous l'influence des travaux de Richard Eisenberg, "Dependent Types in Haskell: Theory and Practice" .
Dans notre blog, Vladislav a déjà expliqué pourquoi Haskell manque de types dépendants et comment nous prévoyons de les ajouter. Nous avons décidé de traduire ce post en russe afin que le plus de développeurs possible puissent utiliser des types dépendants et apporter une contribution supplémentaire au développement de Haskell en tant que langue.
Situation actuelle
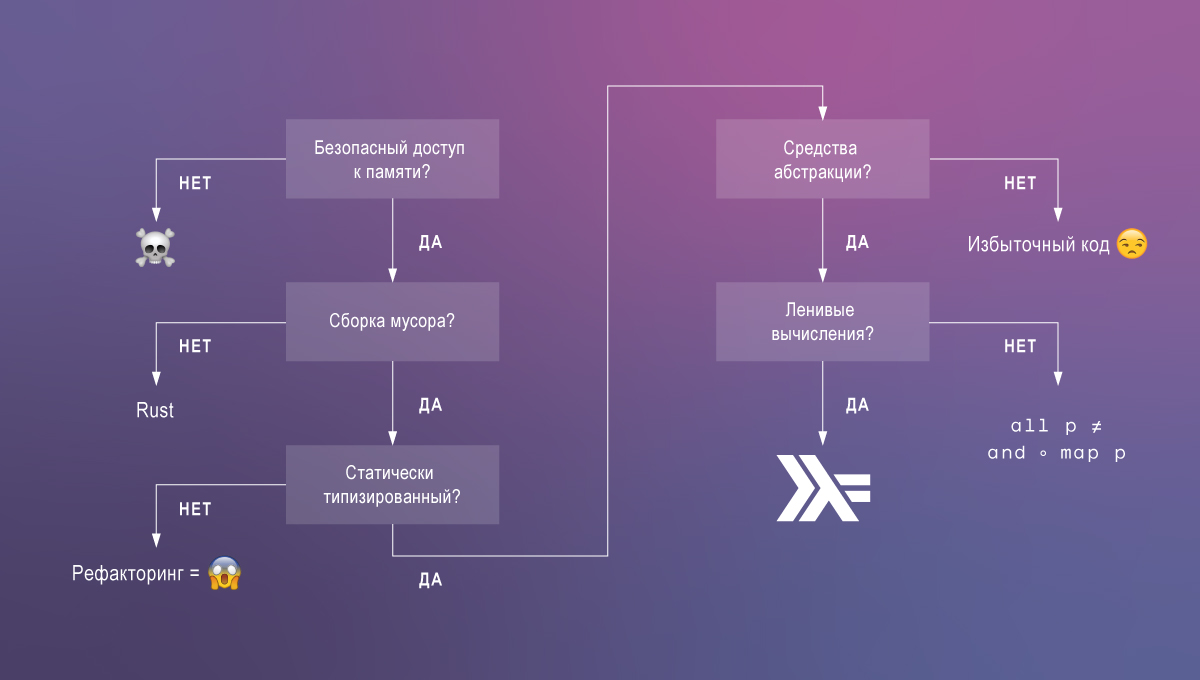
Les types dépendants sont ce qui me manque le plus à Haskell. Voyons pourquoi. Du code que nous voulons:
- performances, c'est-à-dire vitesse d'exécution et faible consommation de mémoire;
- maintenabilité et facilité de compréhension;
- exactitude garantie par la méthode de compilation.
Avec les technologies existantes, il est rarement possible d'atteindre les trois caractéristiques, mais avec la prise en charge des types dépendants de Haskell, la tâche est simplifiée.
Norme Haskell: ergonomie + performance
Haskell est basé sur un système simple: un calcul lambda polymorphe avec des calculs paresseux, des types de données algébriques et des classes de types. C'est cette combinaison de fonctionnalités linguistiques qui nous permet d'écrire du code élégant, pris en charge et en même temps productif. Pour étayer cette affirmation, nous comparons brièvement Haskell avec des langues plus populaires.
Les langues avec un accès mémoire non sécurisé, comme C, entraînent les erreurs et les vulnérabilités les plus graves (par exemple, les dépassements de mémoire tampon, les fuites de mémoire). Parfois, ces langues sont nécessaires, mais le plus souvent, leur utilisation est une idée comme telle.
Les langages d'accès sécurisé à la mémoire forment deux groupes: ceux qui dépendent du garbage collector et Rust. La rouille semble être unique en ce qu'elle offre un accès sécurisé à la mémoire sans récupération de place . Il n'y a également plus de cyclone et d'autres langages de recherche pris en charge dans ce groupe. Mais contrairement à eux, Rust est en voie de devenir populaire. L'inconvénient est que malgré la sécurité, la gestion de la mémoire de Rust n'est pas anodine et manuelle. Dans les applications qui peuvent se permettre d'utiliser le garbage collector, il est préférable de consacrer du temps aux développeurs sur d'autres tâches.
Il y a des langues qui restent avec les récupérateurs, que nous allons diviser en deux catégories en fonction de leur système de types.
Les langages typés dynamiquement (ou plutôt monotypés ), tels que JavaScript ou Clojure, ne fournissent pas d'analyse statique et ne peuvent donc pas fournir le même niveau de confiance dans l'exactitude du code (et non, les tests ne peuvent pas remplacer les types - vous avez besoin des deux) !).
Les langages typés statiquement comme Java ou Go ont souvent un système de types très limité. Cela oblige les programmeurs à écrire du code redondant et à mettre des fonctionnalités de langage non sécurisées. Par exemple, le manque de types génériques dans Go vous oblige à utiliser l' interface {} et le cast lors de l'exécution . Il n'y a pas non plus de séparation entre les calculs avec effets secondaires (entrée, sortie) et les calculs purs.
Enfin, parmi les langues avec accès sécurisé à la mémoire, un garbage collector et un système de type puissant, Haskell se distingue par la paresse. L'informatique paresseuse est extrêmement utile pour écrire du code modulaire composable. Ils permettent de décomposer en définitions auxiliaires toutes les parties d'expressions, y compris les constructions définissant un flux de contrôle.
Haskell semble être un langage presque parfait jusqu'à ce que vous réalisiez à quel point il est loin de libérer son plein potentiel en termes de vérification statique par rapport aux outils de preuve de théorème comme Agda .
Comme exemple simple de cas où le système de type Haskell n'est pas assez puissant, considérons l'opérateur d' indexation de liste de Prelude (ou l' indexation d'un tableau à partir d'un package primitive ):
(!!) :: [a] -> Int -> a indexArray :: Array a -> Int -> a
Rien dans ces signatures de type ne reflète l'exigence que l'index soit non négatif et inférieur à la longueur de la collection. Pour les logiciels ayant des exigences de fiabilité élevées, cela est inacceptable.
Agda: ergonomie + justesse
Les moyens de preuve de théorèmes (par exemple, Coq ) sont des outils logiciels qui permettent d'utiliser un ordinateur pour développer des preuves formelles de théorèmes mathématiques. Pour un mathématicien, utiliser de tels outils, c'est comme écrire des preuves sur papier. La différence dans la rigueur sans précédent requise par un ordinateur pour établir la validité de ces preuves.
Pour le programmeur, cependant, les moyens de prouver les théorèmes ne sont pas si différents du compilateur pour le langage de programmation ésotérique avec un système de type incroyable (et éventuellement un environnement de développement intégré), et médiocre (ou même absent) tout le reste. Un moyen de prouver les théorèmes est, en fait, les langages de programmation, dont les auteurs ont passé tout leur temps à développer un système de typage et ont oublié que les programmes doivent encore être exécutés.
Le rêve chéri des développeurs de logiciels vérifiés est un moyen de prouver les théorèmes, ce qui serait un bon langage de programmation avec un générateur de code et un runtime de haute qualité. Dans ce sens, notamment les créateurs d' Idris ont expérimenté. Mais c'est un langage avec des calculs (énergétiques) stricts, et sa mise en œuvre pour le moment n'est pas stable.
Parmi tous les moyens de prouver les théorèmes, les Agda Haskellists aiment surtout. À bien des égards, il est similaire à Haskell, mais avec un système de type plus puissant. Chez Serokell, nous l'utilisons pour prouver les différentes propriétés de nos programmes. Ma collègue Dania Rogozin a écrit une série d'articles à ce sujet.
Voici un type de fonction de recherche similaire à l'opérateur Haskell (!!) :
lookup : ∀ (xs : List A) → Fin (length xs) → A
Le premier paramètre ici est de type List A , ce qui correspond à [a] dans Haskell. Cependant, nous lui donnons le nom xs pour lui faire référence pour le reste de la signature de type. Dans Haskell, nous pouvons accéder aux arguments de fonction uniquement dans le corps de la fonction au niveau du terme:
(!!) :: [a] -> Int -> a
Mais dans Agda, nous pouvons faire référence à cette valeur xs au niveau du type, ce que nous faisons dans le deuxième paramètre de lookup , Fin (length xs) . Une fonction qui fait référence à son paramètre au niveau du type est appelée fonction dépendante et est un exemple de types dépendants.
Le deuxième paramètre dans la lookup est de type Fin n pour n ~ length xs . Une valeur de type Fin n correspond à un nombre dans la plage [0, n) , donc Fin (length xs) est un nombre non négatif inférieur à la longueur de la liste d'entrée. C'est exactement ce dont nous avons besoin pour présenter un index valide d'un élément de liste. En gros, la lookup ["x","y","z"] 2 passera la vérification de type, mais la lookup ["x","y","z"] 42 échouera.
Quand il s'agit d'exécuter des programmes Agda, nous pouvons les compiler dans Haskell en utilisant le backend MAlonzo. Mais les performances du code généré ne seront pas satisfaisantes. Ce n'est pas la faute de MAlonzo: il doit insérer de nombreux unsafeCoerce pour que le GHC unsafeCoerce code déjà vérifié par Agda. Mais le même unsafeCoerce réduit les performances (suite à la discussion de cet article, il s'est avéré que les problèmes de performances peuvent avoir été causés par d'autres raisons - note de l'auteur) .
Cela nous place dans une position difficile: nous devons utiliser Agda pour la modélisation et la vérification formelle, puis réimplémenter la même fonctionnalité sur Haskell. Avec cette organisation des workflows, notre code Agda agit comme une spécification vérifiée par ordinateur. C'est mieux que la spécification en langage naturel, mais loin d'être idéal. Le but est que si le code est compilé, il fonctionnera conformément à la spécification.
Haskell avec extensions: exactitude + performance

Visant des garanties statiques de langues avec des types dépendants, GHC a parcouru un long chemin. Des extensions y ont été ajoutées pour augmenter l'expressivité du système de typage. J'ai commencé à utiliser Haskell lorsque GHC 7.4 était la dernière version du compilateur. Même alors, il avait les principales extensions pour la programmation avancée au niveau du type: RankNTypes , GADTs , TypeFamilies , DataKinds et PolyKinds .
Néanmoins, il n'y a toujours pas de types dépendants à part entière dans Haskell: ni fonctions dépendantes (types Π) ni paires dépendantes (types Σ). D'un autre côté, au moins nous avons un encodage pour eux!
Les pratiques actuelles sont les suivantes:
- encoder les fonctions de niveau type en tant que familles de types privées
- utiliser la fonctionnalisation pour activer les fonctions non saturées,
- combler l'écart entre les termes et les types à l'aide de types uniques.
Cela conduit à une quantité importante de code redondant, mais la bibliothèque singletons automatise sa génération via Template Haskell.
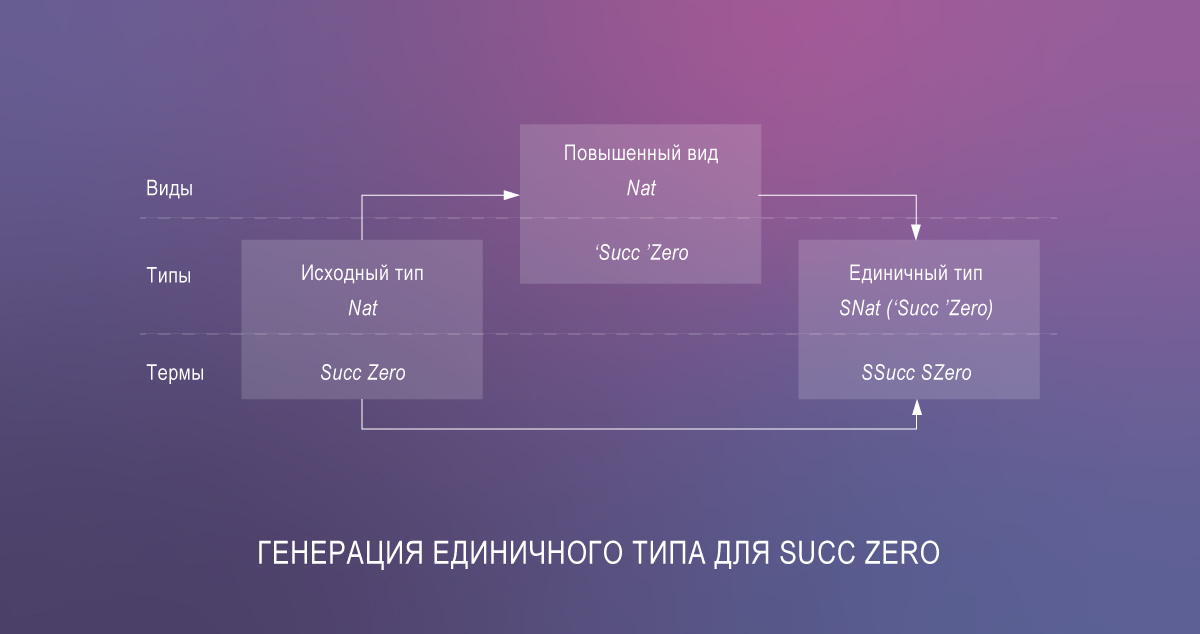
Ainsi, les plus audacieux et les plus décisifs peuvent coder des types dépendants en Haskell en ce moment. A titre de démonstration, voici une implémentation de la fonction de lookup similaire à la variante sur Agda:
{-# OPTIONS -Wall -Wno-unticked-promoted-constructors -Wno-missing-signatures #-} {-# LANGUAGE LambdaCase, DataKinds, PolyKinds, TypeFamilies, GADTs, ScopedTypeVariables, EmptyCase, UndecidableInstances, TypeSynonymInstances, FlexibleInstances, TypeApplications, TemplateHaskell #-} module ListLookup where import Data.Singletons.TH import Data.Singletons.Prelude singletons [d| data N = Z | SN len :: [a] -> N len [] = Z len (_:xs) = S (len xs) |] data Fin n where FZ :: Fin (S n) FS :: Fin n -> Fin (S n) lookupS :: SingKind a => SList (xs :: [a]) -> Fin (Len xs) -> Demote a lookupS SNil = \case{} lookupS (SCons x xs) = \case FZ -> fromSing x FS i' -> lookupS xs i'
Et voici une session GHCi montrant que lookupS rejette en effet les index trop volumineux:
GHCi, version 8.6.2: http://www.haskell.org/ghc/ :? for help [1 of 1] Compiling ListLookup ( ListLookup.hs, interpreted ) Ok, one module loaded. *ListLookup> :set -XTypeApplications -XDataKinds *ListLookup> lookupS (sing @["x", "y", "z"]) FZ "x" *ListLookup> lookupS (sing @["x", "y", "z"]) (FS FZ) "y" *ListLookup> lookupS (sing @["x", "y", "z"]) (FS (FS FZ)) "z" *ListLookup> lookupS (sing @["x", "y", "z"]) (FS (FS (FS FZ))) <interactive>:5:34: error: • Couldn't match type ''S n0' with ''Z' Expected type: Fin (Len '["x", "y", "z"]) Actual type: Fin ('S ('S ('S ('S n0)))) • In the second argument of 'lookupS', namely '(FS (FS (FS FZ)))' In the expression: lookupS (sing @["x", "y", "z"]) (FS (FS (FS FZ))) In an equation for 'it': it = lookupS (sing @["x", "y", "z"]) (FS (FS (FS FZ)))
Cet exemple montre que la faisabilité ne signifie pas pratique. Je suis heureux que Haskell ait des capacités linguistiques pour implémenter des lookupS , mais en même temps je suis préoccupé par la complexité inutile qui se pose. En dehors des projets de recherche, je ne recommanderais pas un tel style de code.
Dans ce cas particulier, nous pourrions obtenir le même résultat avec moins de complexité en utilisant des vecteurs indexés en longueur. Cependant, la traduction de code directe d'Agda révèle mieux les problèmes que vous devez rencontrer dans d'autres circonstances.
En voici quelques uns:
- La relation de typage
a :: t et la relation de destination de la forme t :: k différentes. 5 :: Integer est vrai en termes, mais pas en types. "hi" :: Symbol est vrai dans les types, mais pas dans les termes. Cela nécessite la Demote types de Demote pour mapper les vues et les types. - La bibliothèque standard utilise
Int comme représentation des index de liste (et les singletons utilisent Nat dans les définitions élevées). Int et Nat sont des types non inductifs. Bien qu'ils soient plus efficaces que le codage unaire des nombres naturels, ils ne fonctionnent pas très bien avec les définitions inductives telles que Fin ou lookupS . Pour cette raison, nous redéfinissons la length en len . - Haskell n'a pas de mécanismes intégrés pour élever les fonctions au niveau des types.
singletons codent en tant que familles de types privés et appliquent une fonctionnalisation pour contourner le manque d'utilisation partielle des familles de types. Cet encodage est compliqué. De plus, nous avons dû mettre la définition de len dans une citation de Template Haskell afin que les singletons génèrent son homologue au niveau du type, Len . - Il n'y a pas de fonctions dépendantes intégrées. Il faut utiliser des types d'unités pour combler l'écart entre les termes et les types. Au lieu de la liste habituelle, nous passons le
SList à l'entrée lookupS . Par conséquent, nous devons garder à l'esprit plusieurs définitions de listes à la fois. Cela entraîne également des frais généraux lors de l'exécution du programme. Ils résultent de la conversion entre des valeurs ordinaires et des valeurs de types d'unités ( toSing , fromSing ) et du transfert de la procédure de conversion (restriction SingKind ).
L'inconvénient est le moindre problème. Pire encore, ces fonctionnalités linguistiques ne sont pas fiables. Par exemple, j'ai signalé le problème # 12564 en 2016, et il y a aussi le # 12088 de la même année. Ces deux problèmes entravent la mise en œuvre de programmes plus avancés que les exemples de manuels (tels que les listes d'indexation). Ces bogues GHC ne sont toujours pas corrigés, et la raison, il me semble, est que les développeurs n'ont tout simplement pas assez de temps. Le nombre de personnes travaillant activement sur le GHC est étonnamment faible, donc certaines choses ne se déplacent pas.
Résumé
J'ai mentionné plus tôt que nous voulons les trois propriétés du code, voici donc un tableau illustrant l'état actuel des choses:
Un avenir radieux
Des trois options disponibles, chacune a ses inconvénients. Cependant, nous pouvons les corriger:
- Prenez le Haskell standard et ajoutez directement des types dépendants au lieu d'un codage gênant via des
singletons . (Plus facile à dire qu'à faire.) - Prenez Agda et implémentez un générateur de code efficace et RTS pour cela. (Plus facile à dire qu'à faire.)
- Prenez Haskell avec des extensions, corrigez des bugs et continuez à ajouter de nouvelles extensions pour simplifier le codage des types dépendants. (Plus facile à dire qu'à faire.)
La bonne nouvelle est que les trois options convergent à un moment donné (dans un sens). Imaginez la plus petite extension du Haskell standard qui ajoute des types dépendants et vous permet donc de garantir l'exactitude du code par la façon dont il est écrit. Le code Agda peut être compilé (transposé) dans cette langue sans unsafeCoerce . Et Haskell avec extensions est, en un sens, un prototype inachevé de ce langage. Quelque chose doit être amélioré et quelque chose doit être supprimé, mais en fin de compte, nous atteindrons le résultat souhaité.
Débarrassé des singletons
Un bon indicateur de progrès est la simplification de la bibliothèque singletons . Comme les types dépendants sont implémentés dans Haskell, les solutions de contournement et la gestion spéciale des cas spéciaux implémentés dans les singletons ne sont plus nécessaires. En fin de compte, la nécessité de ce package disparaîtra complètement. Par exemple, en 2016, en utilisant l'extension -XTypeInType j'ai supprimé KProxy de SingKind et SomeSing . Ce changement a été rendu possible grâce à l'union des types et des types. Comparez les anciennes et les nouvelles définitions:
class (kparam ~ 'KProxy) => SingKind (kparam :: KProxy k) where type DemoteRep kparam :: * fromSing :: SingKind (a :: k) -> DemoteRep kparam toSing :: DemoteRep kparam -> SomeSing kparam type Demote (a :: k) = DemoteRep ('KProxy :: KProxy k) data SomeSing (kproxy :: KProxy k) where SomeSing :: Sing (a :: k) -> SomeSing ('KProxy :: KProxy k)
Dans les anciennes définitions, k apparaît exclusivement dans les positions de vue, à droite des annotations de la forme t :: k . Nous utilisons kparam :: KProxy k pour transférer k vers les types.
class SingKind k where type DemoteRep k :: * fromSing :: SingKind (a :: k) -> DemoteRep k toSing :: DemoteRep k -> SomeSing k type Demote (a :: k) = DemoteRep k data SomeSing k where SomeSing :: Sing (a :: k) -> SomeSing k
Dans les nouvelles définitions, k se déplace librement entre les positions de vue et de type, nous n'avons donc plus besoin de KProxy . La raison en est qu'à partir de GHC 8.0, les types et les types entrent dans la même catégorie syntaxique.
Il existe trois mondes complètement séparés dans Haskell standard: termes, types et vues. Si vous regardez le code source de GHC 7.10, vous pouvez voir un analyseur distinct pour les vues et une vérification distincte. GHC 8.0 n'en a plus: l' analyseur et la validation des types et des vues sont courants.
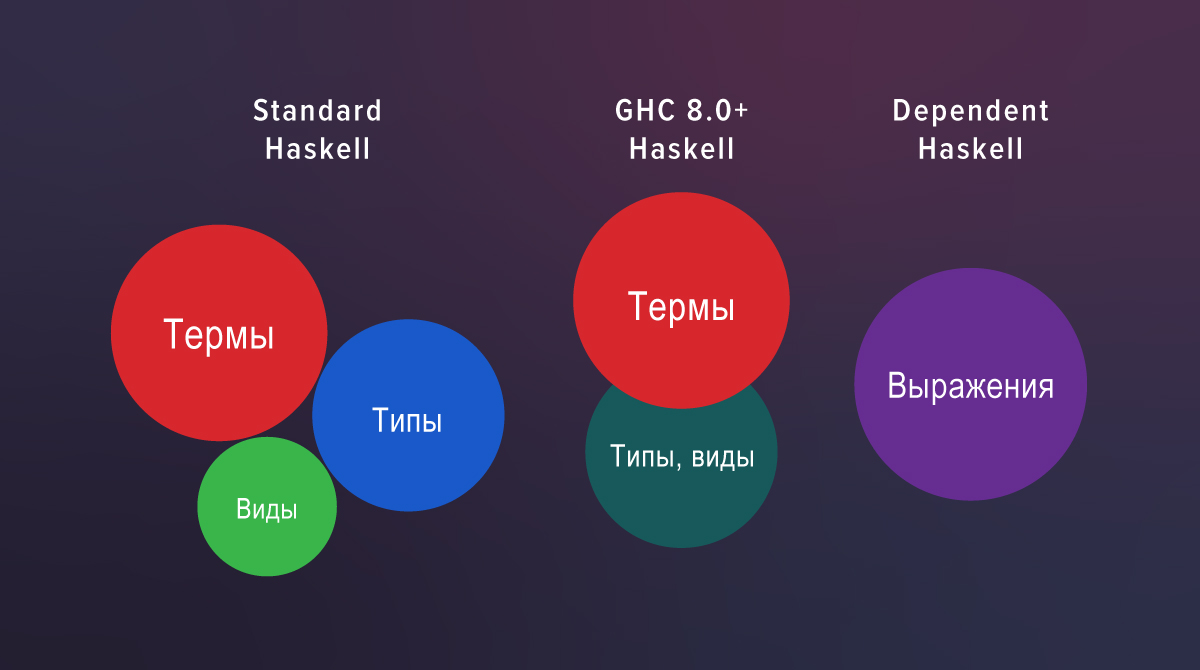
Dans Haskell avec extensions, la vue est juste le rôle dans lequel le type est:
f :: T z -> ...
Dans GHC 8.0–8.4, il y avait encore quelques différences entre la résolution de noms dans les types et les types. Mais je les ai réduits à GHC 8.6: j'ai créé l'extension StarIsType et introduit la fonctionnalité PolyKinds dans PolyKinds . Les différences restantes, j'ai fait un avertissement à GHC 8.8, et complètement éliminé dans GHC 8.10
Quelle est la prochaine étape? Jetons un coup d'œil à SingKind dans la dernière version de singletons :
class SingKind k where type Demote k = (r :: Type) | r -> k fromSing :: Sing (a :: k) -> Demote k toSing :: Demote k -> SomeSing k
La Demote types Demote nécessaire pour tenir compte des écarts entre la relation de typage a :: t et la relation de destination de la forme t :: k . Le plus souvent (pour les types de données algébriques), Demote est un mappage d'identité:
type Demote Bool = Booltype Demote [a] = [Demote a]type Demote (Either ab) = Either (Demote a) (Demote b)
Par conséquent, Demote (Either [Bool] Bool) = Either [Bool] Bool . Cette observation nous invite à faire la simplification suivante:
class SingKind k where fromSing :: Sing (a :: k) -> k toSing :: k -> SomeSing k
Demote pas nécessaire! Et, en fait, cela fonctionnerait à la fois avec le Either [Bool] Bool ou d'autres types de données algébriques. En pratique, cependant, nous avons affaire à des types de données non algébriques: Integer, Natural , caractère, Text , etc. S'ils sont utilisés comme espèces, ils ne sont pas peuplés: 1 :: Natural est vrai au niveau des termes, mais pas au niveau des types. Pour cette raison, nous avons affaire à de telles définitions:
type Demote Nat = Natural type Demote Symbol = Text
La solution à ce problème est d'élever des types primitifs. Par exemple, le Text défini comme ceci:
Si nous élevons correctement ByteArray# et Int# au niveau des types, nous pouvons utiliser Text au lieu de Symbol . En faisant de même avec Natural et éventuellement quelques autres types, vous pouvez vous débarrasser de Demote , non?
Hélas, non. Dans ce qui précède, j'ai fermé les yeux sur le type de données le plus important: les fonctions. Ils ont également une instance spéciale de Demote :
type Demote (k1 ~> k2) = Demote k1 -> Demote k2 type a ~> b = TyFun ab -> Type data TyFun :: Type -> Type -> Type
~> il s'agit d'un type avec lequel les fonctions de niveau type sont codées en singletons en fonction des familles de types privés et de la fonctionnalisation .
Au début, cela peut sembler une bonne idée de combiner ~> et -> , car les deux signifient le type (type) de la fonction. Le problème est que -> en position de type et -> en position d'affichage signifient des choses différentes. Au niveau du terme, toutes les fonctions de a à b sont de type a -> b . Au niveau du type, seuls les constructeurs de a à b sont de type a -> b , mais ils ne sont pas synonymes de types et pas de familles de types. Afin de déduire les types, GHC suppose que f ~ g et a ~ b découlent de fa ~ gb , ce qui est vrai pour les constructeurs, mais pas pour les fonctions - c'est pourquoi il y a une limitation.
Par conséquent, afin d'élever les fonctions au niveau des types, mais pour préserver l'inférence de type, nous devrons déplacer les constructeurs vers un type distinct. Nous l'appelons a :-> b , car il sera vraiment vrai que f ~ g et a ~ b découlent de fa ~ gb . Les autres fonctions seront toujours de type a -> b . Par exemple, Just :: a :-> Maybe a , mais en même temps isJust :: Maybe a -> Bool .
Lorsque la Demote est terminée, la dernière étape consiste à se débarrasser de Sing lui-même. Pour ce faire, nous avons besoin d'un nouveau quantificateur, un hybride entre forall et -> . Examinons de plus près la fonction isJust:
isJust :: forall a. Maybe a -> Bool isJust = \x -> case x of Nothing -> False Just _ -> True
La fonction isJust paramétrée avec le type a puis avec la valeur x :: Maybe a . Ces deux paramètres ont des propriétés différentes:
- Explicitness. Dans l'
isJust (Just "hello") , nous passons explicitement x = Just "hello" et a = String est implicitement émis par le compilateur. Dans Haskell moderne, nous pouvons également forcer le passage explicite des deux paramètres: isJust @String (Just "hello") . - Pertinence La valeur passée à l'entrée à
isJust dans le code sera transmise lors de l'exécution du programme: nous effectuons une comparaison avec l'exemple en utilisant case pour vérifier s'il s'agit de Nothing ou Just . Par conséquent, la valeur est considérée comme pertinente. Mais son type est effacé et ne peut être comparé au motif: la fonction gère Maybe Int , Maybe String , Maybe Bool , etc. Par conséquent, il est considéré comme non pertinent. Cette propriété est également appelée paramétricité. - Dépendance. En tout
forall a. t forall a. t , le type t peut faire référence à a , et par conséquent, dépendre du particulier passé a . Par exemple, isJust @String est de type Maybe String -> Bool et isJust @Int est de type Maybe Int -> Bool . Cela signifie que forall est un quantificateur dépendant. Remarquez la différence avec le paramètre value: peu importe que nous isJust Nothing ou isJust (Just …) , le type de résultat est toujours Bool . Par conséquent, -> est un quantificateur indépendant.
Pour supprimer Sing , nous avons besoin d'un quantificateur explicite et pertinent, comme a -> b , et en même temps dépendant, comme forall (a :: k). t forall (a :: k). t . Notons-le comme foreach (a :: k) -> t . Pour supprimer SingI , nous introduisons également un quantificateur dépendant pertinent implicite, foreach (a :: k). t foreach (a :: k). t . En conséquence, les singletons ne seront pas nécessaires car nous venons d'ajouter des fonctions dépendantes au langage.
Un bref aperçu de Haskell avec les types dépendants
Avec l'augmentation des fonctions au niveau des types et du quantificateur foreach , nous pouvons réécrire les lookupS comme suit:
data N = Z | SN len :: [a] -> N len [] = Z len (_:xs) = S (len xs) data Fin n where FZ :: Fin (S n) FS :: Fin n -> Fin (S n) lookupS :: foreach (xs :: [a]) -> Fin (len xs) -> a lookupS [] = \case{} lookupS (x:xs) = \case FZ -> x FS i' -> lookupS xs i'
En bref, le code ne fonctionne pas, mais les singletons assez bons pour masquer le code redondant. Cependant, le nouveau code est beaucoup plus simple: il n'y a plus Demote , SingKind , SList , SNil , SCons , fromSing . Il n'y a pas d'utilisation de TemplateHaskell , puisque maintenant nous pouvons appeler la fonction len directement au lieu de créer la famille de type Len . Les performances seront également meilleures, car vous n'avez plus besoin de convertir depuis le fromSing .
Nous devons encore redéfinir la length en len pour renvoyer un N défini par induction au lieu de Int . Ce problème ne doit peut-être pas être considéré comme faisant partie de l'ajout de types dépendants à Haskell, car Agda utilise également un N défini par induction dans la fonction de lookup .
À certains égards, Haskell avec des types dépendants est encore plus simple que Haskell standard. Pourtant, en lui-même, les types et les types sont combinés en une seule langue uniforme. Je peux facilement imaginer écrire du code dans ce style dans un projet commercial pour prouver formellement l'exactitude des composants clés des applications. De nombreuses bibliothèques Haskell peuvent fournir des interfaces plus sécurisées sans la complexité des singletons .
Ce ne sera pas facile à réaliser. Nous sommes confrontés à de nombreux problèmes d'ingénierie affectant tous les composants du GHC: un analyseur, la résolution de noms, la vérification de type et même le langage Core. Tout devra être modifié, voire complètement repensé.
Thésaurus