
Depuis trois ans, nous organisons le forum RAIF (Russian Artificial Intelligence Forum) où des intervenants du monde des affaires et de la science parlent de leur travail. Nous avons décidé de partager les rapports les plus intéressants. Dans ce billet, Andrey Filchenkov, chef du ITMO Machine Learning Lab, raconte toute la vérité sur AutoML.
Dans le cadre du forum RAIF 2019 tenu à Skolkovo, organisé par Jet Infosystems, j'ai fait une présentation dans laquelle j'ai parlé d'AutoML et des perspectives de son utilisation. Comme je suis scientifique, je n'ai pas à parler très souvent lors de tels événements: je participe généralement à des conférences scientifiques.
L'un des principaux domaines que nous traitons est AutoML. De plus, je suis le CTO de deux petites startups. L'une d'elles - les technologies Statanly - crée des services AutoML et se consacre à l'analyse des données. En fait, je suis la personne qui invente les algorithmes, les met en œuvre et les utilise. Je suppose que je suis la seule personne à pouvoir parler d'AutoML à partir des trois positions possibles.
Qu'est-ce qu'AutoML?
Au cours de la dernière année, cette direction a été d'un grand intérêt, et maintenant elle peut être comparée à la concentration de l'attention sur l'apprentissage profond populaire en son temps. L'avènement de l'apprentissage automatique peut remonter à 1976. Il y avait une petite communauté ML, et en 2017, elle a commencé à gagner en popularité, après un an au-delà des limites de l'apprentissage automatique lui-même. Maintenant, ils parlent de lui dans les affaires, l'industrie et dans divers autres domaines. Certes, en Russie, malheureusement, tous les gens, même de la communauté ML, n'imaginent pas ce qu'est l'apprentissage automatique. Pourquoi est-ce arrivé?
La réponse est simple: la demande de scientifiques des données augmente beaucoup plus rapidement qu'ils ne parviennent à obtenir leur diplôme universitaire et à suivre des cours. Dans le même temps, ils passent la plupart du temps (jusqu'à 80%) à choisir un modèle, à le configurer et à attendre que tout soit calculé. En effet, aucun algorithme idéal n'existe - malheureusement, aucun d'entre eux n'a une portée limitée, et les spécialistes de l'analyse des données doivent sélectionner l'algorithme optimal pour chaque tâche spécifique, puis le configurer. Ici, beaucoup dépend déjà de la qualification de l'analyste: plus il en sait sur le sujet et comprend les algorithmes, plus la solution peut être optimale pendant un certain temps. C'est là qu'AutoML aide. En fait, AutoML vous permet d'automatiser et d'accélérer la sélection de solutions et de tâches d'apprentissage automatique.
Décidons immédiatement: il y a deux directions liées, mais différentes l'une de l'autre.
Premièrement: les données sont présentées dans le tableau, il y a des étiquettes, et lorsque nous devons les classer, nous sélectionnons un objet dans une grande liste et configurons ses hyper paramètres, et en même temps nous pouvons traiter les données.
Le deuxième scénario est plus complexe. Par exemple, des images, des séquences et des zones où l'apprentissage en profondeur est désormais la norme - ici, la tâche devient un peu plus intéressante, car vous pouvez proposer de nouvelles architectures: elles ne sont pas si faciles à trier. Ainsi, «Rechercher des architectures neuronales», est engagé dans le fait qu'il sélectionne le réseau optimal et met en place des hyper-paramètres qui permettent de résoudre l'un ou l'autre problème. Dans le même temps, AutoML ne prend pas en compte la sémantique des données. Il existe également des méthodes qui vous permettent de «retirer» les descriptions de données et de les utiliser pour les prévisions, mais cela ne fait qu’accroître l’applicabilité universelle d’AutoML. Peu importe d'où viennent les données: que vous soyez gasman, marchand de glaces ou autre - les méthodes sont universelles. Dans le même temps, AutoML vous permet de construire les solutions les plus efficaces d'une part, en choisissant des solutions complexes et non les plus évidentes même pour un spécialiste de l'analyse des données structurelles, et d'autre part, de rechercher et d'optimiser ces solutions plus rapidement. Et encore une chose non évidente - AutoML permet d'accélérer l'écriture de code. Ici, par exemple:

A droite, le code est écrit en Keras pour la reconnaissance MNIST, et à gauche se trouve le code pour Auto-Keras dans la bibliothèque d'automatisation écrite sous Keras. La différence est visible, tandis que le temps d'écriture est enregistré.
Abondance de solutions existantes (2019)
À l'heure actuelle, il existe un grand nombre de bibliothèques et de plates-formes différentes pour l'analyse automatique des données, je n'en ai cité que certaines (en fait, il y en a beaucoup plus).
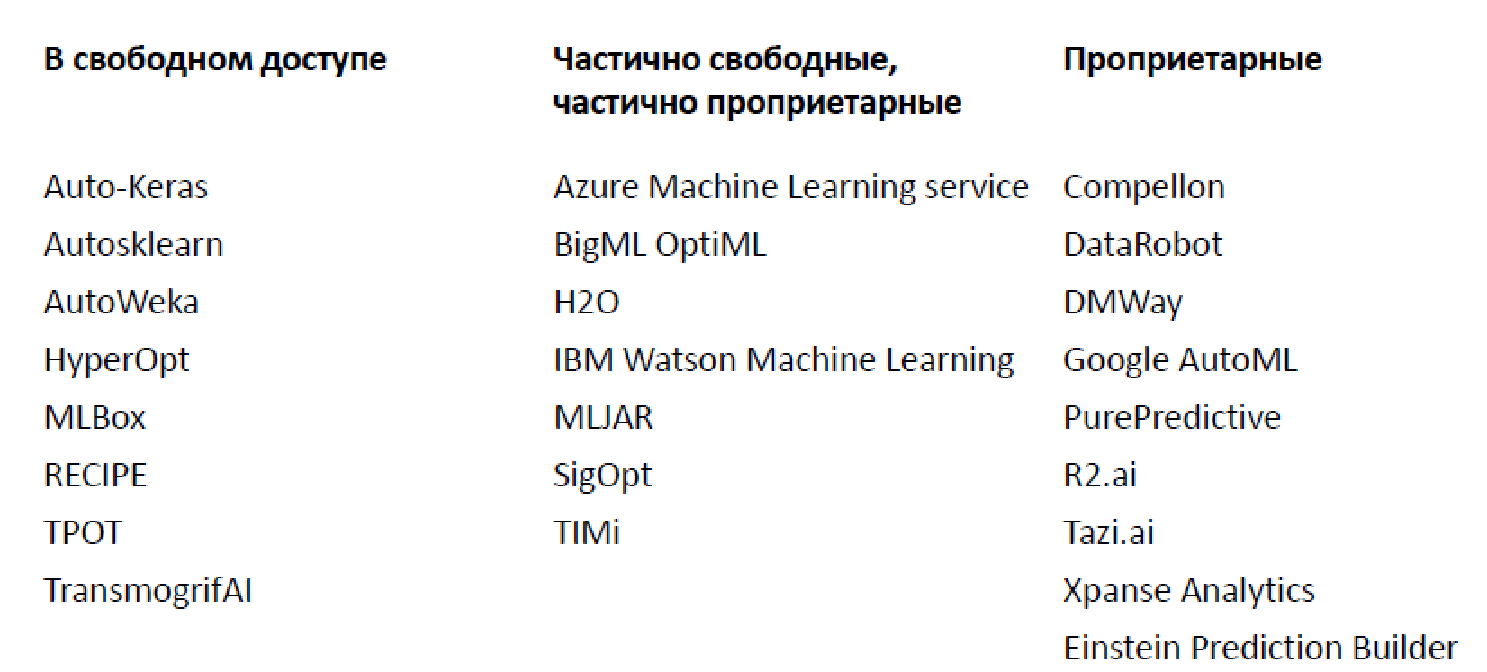
Il existe à la fois des options ouvertes qui implémentent des fonctionnalités limitées et des options propriétaires. Le plus célèbre, probablement, est Google AutoML, qui ne vous donne pas de modèle, mais le forme sur vos données, vous permettant de l'utiliser pour 20 $ par heure. De plus, il existe un grand nombre de scénarios décents lorsque les fonctionnalités de base sont fournies gratuitement, mais vous devez payer pour des composants plus avancés.
Des prévisions brillantes
La communauté elle-même fait l'éloge des perspectives d'AutoML. Par exemple, Jeff Dean, un scientifique de l'intelligence artificielle et un chercheur principal de Google, a déclaré en mars 2018 que l'expertise existante en matière d'apprentissage automatique pourrait être remplacée par une multiplication par cent de la puissance de calcul (presque tout ce qu'un scientifique des données fait -vous pouvez être automatisé). Une prévision légèrement plus restreinte, mais toujours effrayante de Gartner indique que d'ici 2020, 40% des scientifiques des données peuvent être remplacés par AutoML.
Peu de goudron
Voici à quoi ressemble la méthodologie standard CRISP DM:
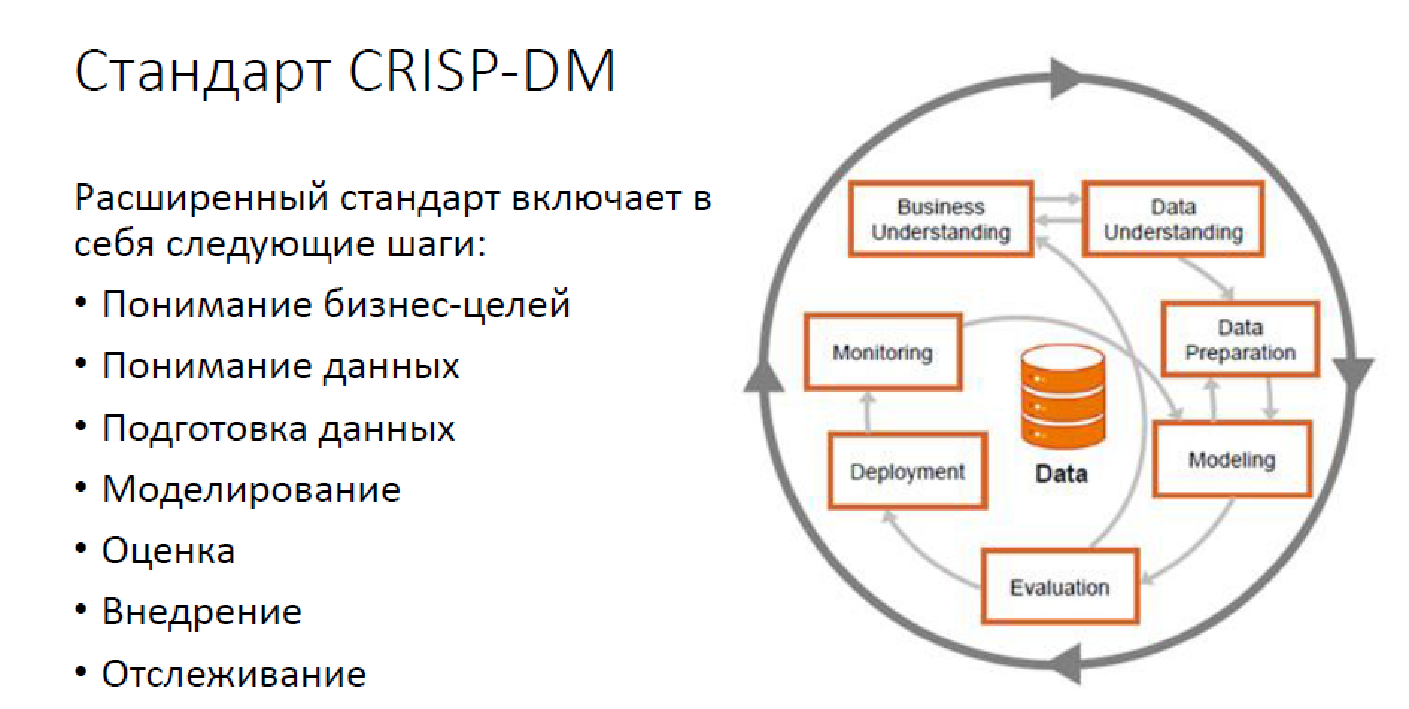
Il s'agit d'une option avancée, avec surveillance, mais néanmoins. Aujourd'hui, la résolution de problèmes d'analyse de données ne se résume pas à la construction de modèles uniquement. Nous avons un grand nombre de tâches qui doivent être résolues, et il est nécessaire de résoudre précisément par les gens.
À l'heure actuelle, dans la plupart des cas, AutoML ne représente que 2,5 piliers: choisir un modèle, le configurer et parfois, quand il s'avère, choisir des fonctionnalités de synthèse et uniquement des données.
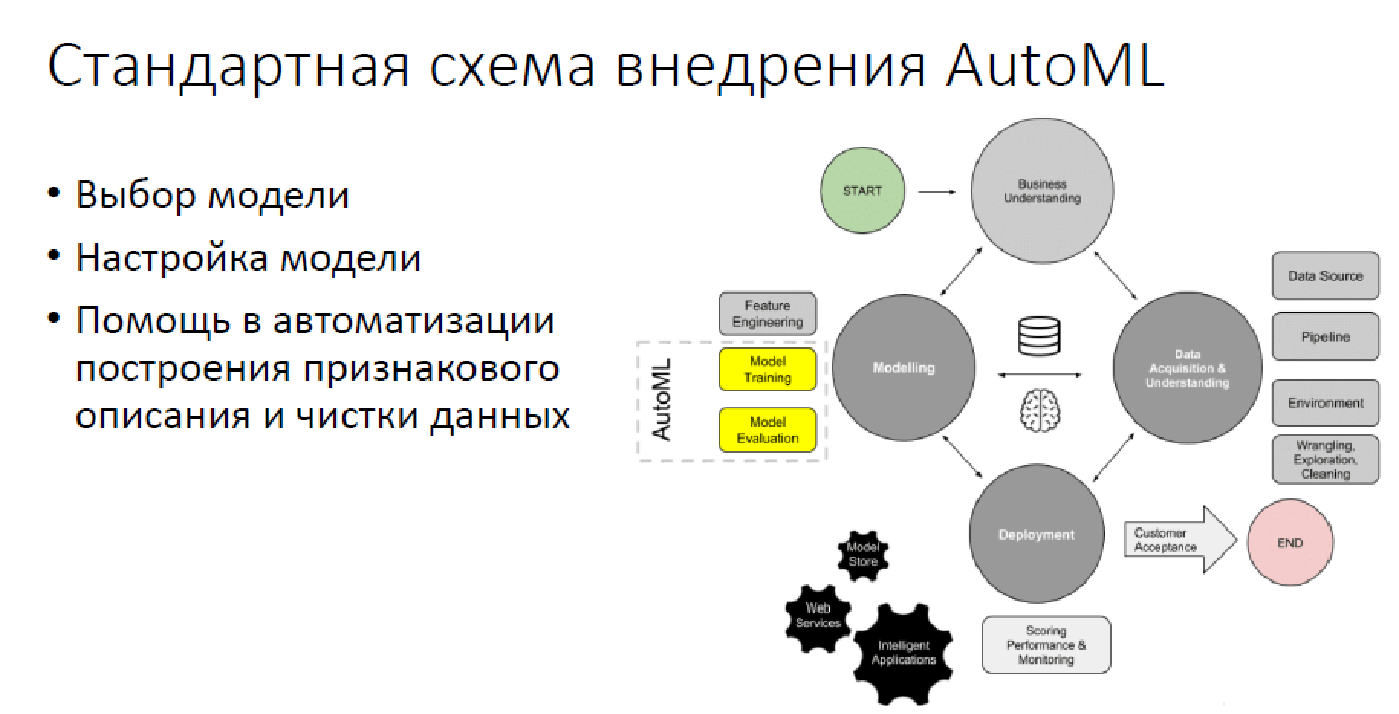
Au-delà d'AutoML
Malheureusement, un assez grand nombre d'opérations sont laissées par-dessus bord, ce qu'AutoML ne fera pas et ne pourra pas faire dans un avenir raisonnable. Naturellement, cela implique la transformation des tâches du monde réel vers le monde de l'analyse des données: "Comment projeter votre problème afin qu'il puisse être résolu par l'analyse des données?" Ce sont toutes sortes de suivi de modèle, d'évaluation de la qualité, de recherche de divers moments désagréables - tout cela pour que la solution ne se révèle, par exemple, trop intolérante à personne, car cela s'est déjà produit. Naturellement, aucun AutoML ne peut prendre en charge des solutions et communiquer avec les clients. De plus, l'interprétabilité à l'heure actuelle est hors de question.
Il s'agit donc d'un outil très pratique, mais malheureusement, pour nous, il ne résout pas loin de tous les problèmes.

On fait quoi?
Voici à quoi ressemble le circuit idéal (comme je le vois):
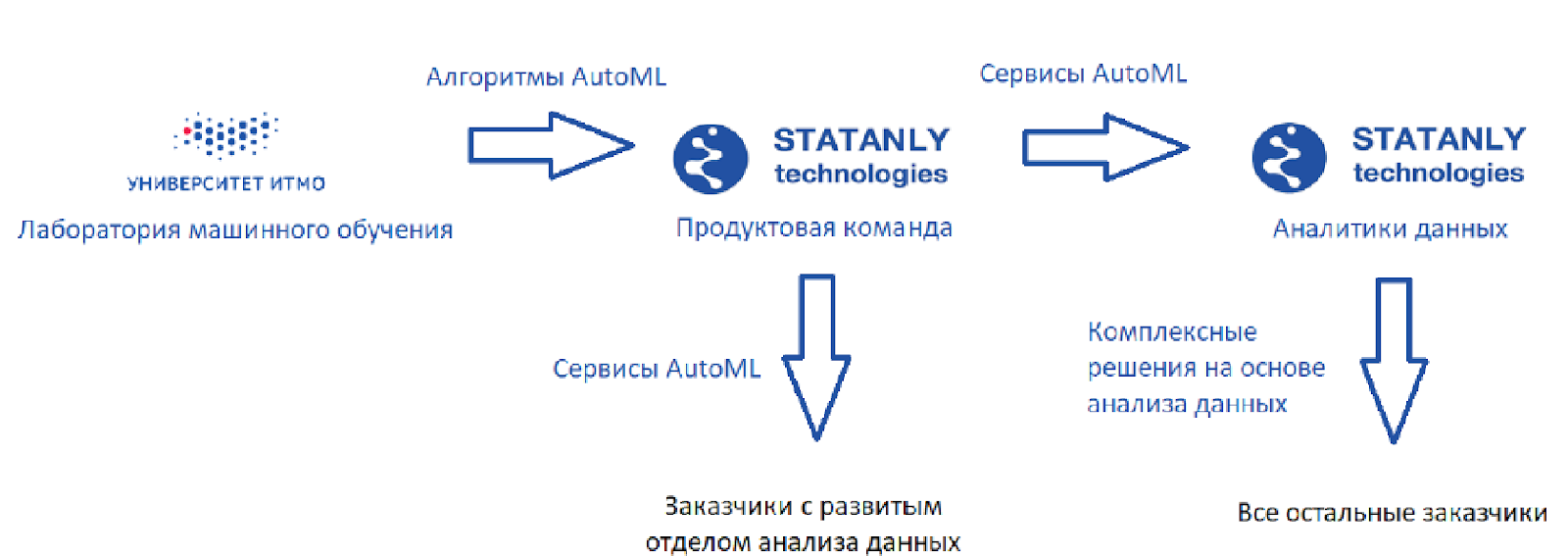
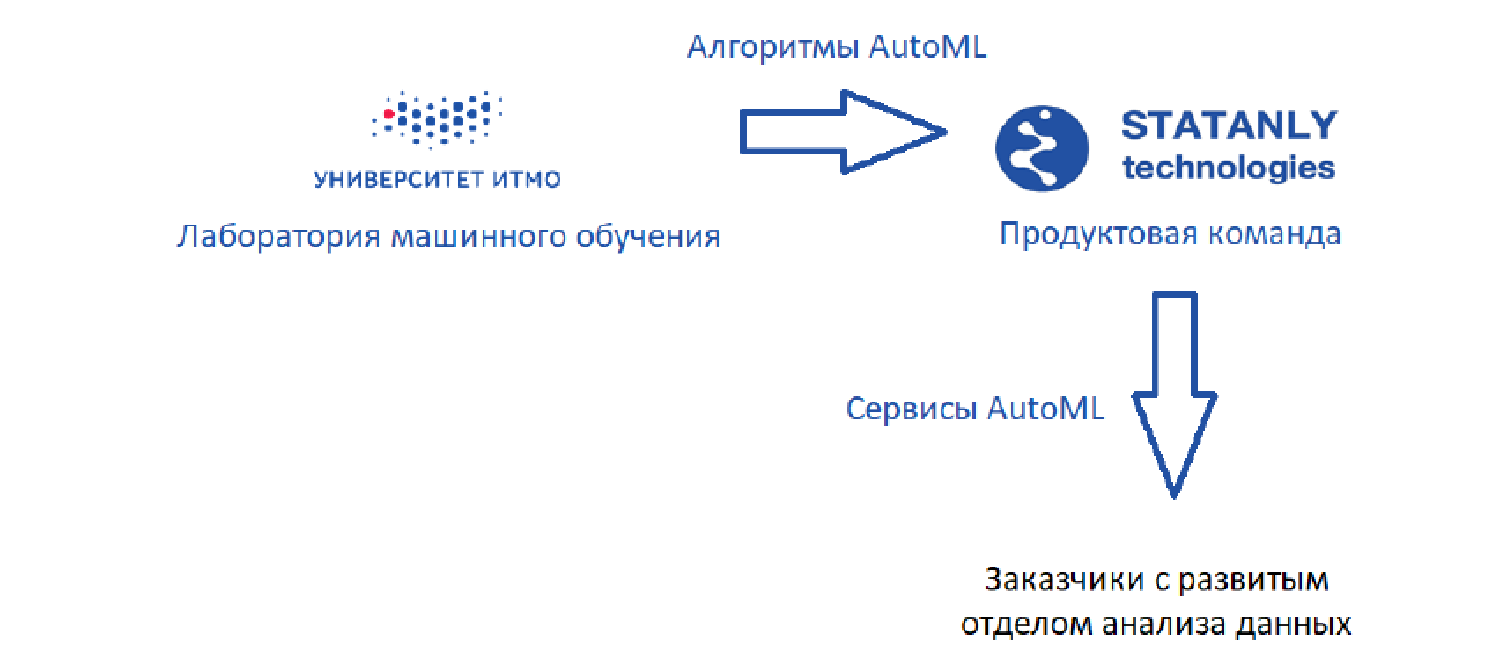
Il existe un laboratoire d'apprentissage automatique qui développe des algorithmes, ainsi que
Statanly Technologies - une équipe de produits qui implémente les services AutoML basés sur nos algorithmes. Ils travaillent pour des entreprises disposant d'un grand département de Data Science. Ces mêmes produits sont utilisés par une équipe d'analystes de données chez
Statanly Technologies elle -
même et résolvent spécifiquement les problèmes des entreprises qui n'ont pas encore développé ou même créé leur propre département d'analyse de données. Le modèle a fière allure, mais la réalité, bien sûr, est un peu plus prosaïque.
Nous avons commencé en 2017 avec le fait qu'il n'y avait pas d'analyse de données ici:
Nous voulions lancer un produit que les analystes de données utiliseraient, mais en 2017, malheureusement, nous n'avons pas pu trouver de contact avec les investisseurs - ils ne comprenaient pas ce qu'était AutoML, pourquoi il était nécessaire et qui l'utiliserait.
Pour le moment, nous ne vendons rien, en tant qu'entreprise qui développe des solutions AutoML, nous ne faisons que nous faciliter la vie, en tant qu'équipe engagée dans l'analyse des données:

Un peu sur la façon dont nous le faisons. Naturellement, nous configurons des hyper paramètres (pas de recherche dans la grille), mais en plus de les configurer, nous essayons presque toujours de construire des solutions basiques basées sur AutoML, et nous aidons parfois dans les étapes de prétraitement des données.
J'ai quelques exemples inspirants et variés - pratiquement tout AutoML et moi, du simple au complexe.
Un exemple simple est la tâche chez Gazpromneft: il y a un puits, il faut prévoir le temps d'échec potentiel. Nous avons à notre disposition des données tabulaires classiques et des fonctionnalités. En conséquence, nous avons construit un modèle prédictif en utilisant AutoML, alors qu'aucun analyste n'a été blessé, mais n'a même pas participé au processus. En fait, cela s'est avéré être la meilleure solution:

Deuxième histoire: Sinara Technologies. Ici, la tâche était un peu plus compliquée, car en fait il y avait exactement deux colonnes: temps / paramètre + comment cela a changé. Il fallait prévoir la panne moteur. Ici, nous avons utilisé AutoML pour nous aider un peu avec le traitement des données - nous avons construit une base de référence, que nous avons nous-mêmes dépassée par la suite:

Troisième exemple: une tâche qui à première vue n'a rien à voir avec AutoML. Il existe un site Web pour la chaîne TVC - une base de données d'articles dans lesquels rechercher, et la recherche est sémantiquement riche. Nous aimerions trouver non seulement des expressions exactes de mots, mais également appropriées dans leur sens. Plus une grande liste d'exigences différentes qui doivent également être prises en compte.
Comment avons-nous abordé cette question?
Nous avons décidé d'indexer tous les documents en fonction de grappes flexibles de mots similaires, car l'indexation est plus pratique. De plus, il y a plus de 100 000 documents dans la base de données, et si cela n'est pas fait, la recherche sera infiniment longue. Ensuite, nous avons construit une représentation vectorielle (j'espère que tout le monde en a entendu parler) et nous avons regroupé les représentations vectorielles pour nous permettre d'être indexés.
Le deuxième problème: comment regrouper les données? Nous avons appliqué AutoML pour sélectionner des mesures pour évaluer la qualité du clustering, ainsi que pour sélectionner des algorithmes et des hyper paramètres pour le clustering:

De plus, le plus souvent, nous n'utilisons pas AutoML. Voici deux exemples très révélateurs.
Dans notre deuxième startup, Special Video Analytics, le produit est un système de reconnaissance des signes des voitures pour assurer leur accès centralisé à un territoire fermé. Le problème principal ici est la petite quantité de données. Dans ce cas, il est assez difficile d'ajuster les paramètres du modèle. Et nous sommes très limités, car souvent AutoML est utilisé sans réfléchir et essaye de régler les modèles sur les mêmes données que celles sur lesquelles ils sont testés. Cela ne peut pas être fait: selon les classiques de l'apprentissage automatique, il faut distinguer un ensemble de validation: plus la recherche est importante, plus il doit y avoir de machines. Ainsi, lorsque nous avons peu de données, nous sommes plus soucieux de trouver et de marquer ces données que de construire un modèle plus complexe.
Un autre exemple est notre développement conjoint avec Huawei. Nous avons fait un projet pour qu'ils reconnaissent le texte sur les images. Il semble que vous pouvez utiliser AutoML ici, car il existe déjà trois mesures pouvant être optimisées: la qualité de la reconnaissance, le temps de reconnaissance et le paramètre du modèle (car tout cela était censé être implémenté dans les appareils mobiles). Mais maintenant, personne n'a suffisamment d'expertise pour mettre en œuvre de manière optimale les trois aspects.
Par conséquent, la puissance de calcul était insuffisante: nous étions limités dans le temps et ne disposions pas d'un nombre suffisant de serveurs. Si nous l'avions commencé à la maison (et nous aurions dû être à LICE), nous n'aurions tout simplement pas le temps. Comme le traitement prend cinq heures, cela ne nous coûte que nos compétences.
Conclusion
En général, AutoML est une chose très utile, mais plutôt étroite dans son application. Naturellement, il ne pourra pas proposer de solutions pour les savoirs traditionnels. AutoML n'est actuellement utile que pour les analystes de données. Peut-être qu'un jour il les remplacera, mais évidemment pas au cours des cinq prochaines années.
Publié par Andrey Filchenkov, chef du laboratoire d'apprentissage automatique, ITMO