Si vous êtes intéressé par l'apprentissage automatique, vous avez probablement entendu parler du BERT et des transformateurs.
BERT est un modèle de langage de Google, montrant les résultats de pointe par une large marge sur un certain nombre de tâches. Le BERT, et généralement les transformateurs, sont devenus une toute nouvelle étape dans le développement d'algorithmes de traitement du langage naturel (NLP). L'article à leur sujet et les «classements» de divers repères peuvent être consultés sur le site Web Papers With Code .
Il y a un problème avec BERT: il est problématique d'utiliser dans les systèmes industriels. BERT-base contient 110M paramètres, BERT-large - 340M. En raison d'un si grand nombre de paramètres, ce modèle est difficile à télécharger sur des appareils aux ressources limitées, tels que les téléphones mobiles. De plus, le long temps d'inférence rend ce modèle inadapté lorsque la vitesse de réponse est critique. Par conséquent, trouver des moyens d'accélérer le BERT est un sujet très brûlant.
À Avito, nous devons souvent résoudre des problèmes de classification de texte. Il s'agit d'une tâche typique d'apprentissage automatique appliqué qui a été bien étudiée. Mais il y a toujours la tentation d'essayer quelque chose de nouveau. Cet article est né d'une tentative d'appliquer le BERT dans les tâches quotidiennes d'apprentissage automatique. Dans ce document, je vais montrer comment vous pouvez améliorer considérablement la qualité d'un modèle existant en utilisant BERT sans ajouter de nouvelles données ou compliquer le modèle.

La distillation des connaissances comme méthode d'accélération des réseaux de neurones
Il existe plusieurs façons d'accélérer / d'alléger les réseaux de neurones. La revue la plus détaillée que j'ai rencontrée est publiée sur le blog Intento sur le Medium .
Les méthodes peuvent être grossièrement divisées en trois groupes:
- Changement d'architecture réseau.
- Compression du modèle (quantification, élagage).
- Distillation des connaissances.
Si les deux premières méthodes sont relativement bien connues et compréhensibles, la troisième est moins courante. Pour la première fois, l'idée de distillation a été proposée par Rich Caruana dans l'article «Model Compression» . Son essence est simple: vous pouvez former un modèle léger qui imitera le comportement d'un modèle enseignant ou même d'un ensemble de modèles. Dans notre cas, l'enseignant sera BERT, et l'élève sera n'importe quel modèle léger.
Défi
Analysons la distillation en utilisant la classification binaire comme exemple. Prenez l'ensemble de données SST-2 ouvert de l'ensemble standard de tâches qui testent les modèles pour la PNL.
Cet ensemble de données est une collection de critiques de films avec IMDb ventilées par couleur émotionnelle - positive ou négative. La métrique de cet ensemble de données est la précision.
Former des modèles basés sur le BERT ou «enseignants»
Tout d'abord, vous devez former le «grand» modèle basé sur le BERT, qui deviendra un enseignant. La façon la plus simple de le faire est de prendre les incorporations de BERT et de former le classificateur par-dessus, en ajoutant une couche au réseau.
Grâce à la bibliothèque tranformers, cela est assez facile, car il existe une classe prête à l'emploi pour le modèle BertForSequenceClassification. À mon avis, le tutoriel le plus détaillé et le plus compréhensible pour enseigner ce modèle a été publié par Towards Data Science .
Imaginons que nous ayons un modèle BertForSequenceClassification formé. Dans notre cas, num_labels = 2, car nous avons une classification binaire. Nous utiliserons ce modèle comme un «enseignant».
Apprendre "étudiant"
Vous pouvez prendre n'importe quelle architecture en tant qu'étudiant: un réseau de neurones, un modèle linéaire, un arbre de décision. Essayons d'enseigner BiLSTM pour une meilleure visualisation. Pour commencer, nous enseignerons BiLSTM sans BERT.
Pour soumettre du texte à l'entrée d'un réseau de neurones, vous devez le présenter comme un vecteur. L'une des façons les plus simples consiste à mapper chaque mot à son index dans le dictionnaire. Le dictionnaire sera composé des n premiers mots les plus populaires de notre ensemble de données, plus deux mots de service: «pad» - «mot factice» afin que toutes les séquences soient de la même longueur et «unk» - pour les mots en dehors du dictionnaire. Nous allons construire le dictionnaire en utilisant l'ensemble standard d'outils de torchtext. Par souci de simplicité, je n'ai pas utilisé d'imbrication de mots pré-formés.
import torch from torchtext import data def get_vocab(X): X_split = [t.split() for t in X] text_field = data.Field() text_field.build_vocab(X_split, max_size=10000) return text_field def pad(seq, max_len): if len(seq) < max_len: seq = seq + ['<pad>'] * (max_len - len(seq)) return seq[0:max_len] def to_indexes(vocab, words): return [vocab.stoi[w] for w in words] def to_dataset(x, y, y_real): torch_x = torch.tensor(x, dtype=torch.long) torch_y = torch.tensor(y, dtype=torch.float) torch_real_y = torch.tensor(y_real, dtype=torch.long) return TensorDataset(torch_x, torch_y, torch_real_y)
Modèle BiLSTM
Le code du modèle ressemblera à ceci:
import torch from torch import nn from torch.autograd import Variable class SimpleLSTM(nn.Module): def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout, batch_size, device=None): super(SimpleLSTM, self).__init__() self.batch_size = batch_size self.hidden_dim = hidden_dim self.n_layers = n_layers self.embedding = nn.Embedding(input_dim, embedding_dim) self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout) self.fc = nn.Linear(hidden_dim * 2, output_dim) self.dropout = nn.Dropout(dropout) self.device = self.init_device(device) self.hidden = self.init_hidden() @staticmethod def init_device(device): if device is None: return torch.device('cuda') return device def init_hidden(self): return (Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device)), Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device))) def forward(self, text, text_lengths=None): self.hidden = self.init_hidden() x = self.embedding(text) x, self.hidden = self.rnn(x, self.hidden) hidden, cell = self.hidden hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1)) x = self.fc(hidden) return x
La formation
Pour ce modèle, la dimension du vecteur de sortie sera (batch_size, output_dim). Lors de la formation, nous utiliserons la perte de journal habituelle. PyTorch a une classe BCEWithLogitsLoss qui combine l'entropie sigmoïde et croisée. Ce dont vous avez besoin.
def loss(self, output, bert_prob, real_label): criterion = torch.nn.BCEWithLogitsLoss() return criterion(output, real_label.float())
Code pour une ère d'apprentissage:
def get_optimizer(model): optimizer = torch.optim.Adam(model.parameters()) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 2, gamma=0.9) return optimizer, scheduler def epoch_train_func(model, dataset, loss_func, batch_size): train_loss = 0 train_sampler = RandomSampler(dataset) data_loader = DataLoader(dataset, sampler=train_sampler, batch_size=batch_size, drop_last=True) model.train() optimizer, scheduler = get_optimizer(model) for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Train')): text, bert_prob, real_label = to_device(text, bert_prob, real_label) model.zero_grad() output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) loss.backward() optimizer.step() train_loss += loss.item() scheduler.step() return train_loss / len(data_loader)
Code de vérification après l'ère:
def epoch_evaluate_func(model, eval_dataset, loss_func, batch_size): eval_sampler = SequentialSampler(eval_dataset) data_loader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=batch_size, drop_last=True) eval_loss = 0.0 model.eval() for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Val')): text, bert_prob, real_label = to_device(text, bert_prob, real_label) output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) eval_loss += loss.item() return eval_loss / len(data_loader)
Si tout cela est mis en place, nous obtenons le code suivant pour la formation du modèle:
import os import torch from torch.utils.data import (TensorDataset, random_split, RandomSampler, DataLoader, SequentialSampler) from torchtext import data from tqdm import tqdm def device(): return torch.device("cuda" if torch.cuda.is_available() else "cpu") def to_device(text, bert_prob, real_label): text = text.to(device()) bert_prob = bert_prob.to(device()) real_label = real_label.to(device()) return text, bert_prob, real_label class LSTMBaseline(object): vocab_name = 'text_vocab.pt' weights_name = 'simple_lstm.pt' def __init__(self, settings): self.settings = settings self.criterion = torch.nn.BCEWithLogitsLoss().to(device()) def loss(self, output, bert_prob, real_label): return self.criterion(output, real_label.float()) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=1, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings['train_batch_size']) return model def train(self, X, y, y_real, output_dir): max_len = self.settings['max_seq_length'] text_field = get_vocab(X) X_split = [t.split() for t in X] X_pad = [pad(s, max_len) for s in tqdm(X_split, desc='pad')] X_index = [to_indexes(text_field.vocab, s) for s in tqdm(X_pad, desc='to index')] dataset = to_dataset(X_index, y, y_real) val_len = int(len(dataset) * 0.1) train_dataset, val_dataset = random_split(dataset, (len(dataset) - val_len, val_len)) model = self.model(text_field) model.to(device()) self.full_train(model, train_dataset, val_dataset, output_dir) torch.save(text_field, os.path.join(output_dir, self.vocab_name)) def full_train(self, model, train_dataset, val_dataset, output_dir): train_settings = self.settings num_train_epochs = train_settings['num_train_epochs'] best_eval_loss = 100000 for epoch in range(num_train_epochs): train_loss = epoch_train_func(model, train_dataset, self.loss, self.settings['train_batch_size']) eval_loss = epoch_evaluate_func(model, val_dataset, self.loss, self.settings['eval_batch_size']) if eval_loss < best_eval_loss: best_eval_loss = eval_loss torch.save(model.state_dict(), os.path.join(output_dir, self.weights_name))
Distillation
L'idée de cette méthode de distillation est tirée d'un article de chercheurs de l'Université de Waterloo . Comme je l'ai dit plus haut, «l'élève» doit apprendre à imiter le comportement de «l'enseignant». Quel est exactement le comportement? Dans notre cas, ce sont les prédictions du modèle enseignant sur l'ensemble de formation. Et l'idée clé est d'utiliser la sortie réseau avant d'appliquer la fonction d'activation. On suppose que de cette façon le modèle pourra mieux apprendre la représentation interne que dans le cas des probabilités finales.
L'article d'origine propose d'ajouter un terme à la fonction de perte, qui sera responsable de l'erreur "d'imitation" - MSE entre les journaux de modèle.

À ces fins, nous apportons deux petites modifications: changez le nombre de sorties réseau de 1 à 2 et corrigez la fonction de perte.
def loss(self, output, bert_prob, real_label): a = 0.5 criterion_mse = torch.nn.MSELoss() criterion_ce = torch.nn.CrossEntropyLoss() return a*criterion_ce(output, real_label) + (1-a)*criterion_mse(output, bert_prob)
Vous pouvez réutiliser tout le code que nous avons écrit en redéfinissant uniquement le modèle et la perte:
class LSTMDistilled(LSTMBaseline): vocab_name = 'distil_text_vocab.pt' weights_name = 'distil_lstm.pt' def __init__(self, settings): super(LSTMDistilled, self).__init__(settings) self.criterion_mse = torch.nn.MSELoss() self.criterion_ce = torch.nn.CrossEntropyLoss() self.a = 0.5 def loss(self, output, bert_prob, real_label): return self.a * self.criterion_ce(output, real_label) + (1 - self.a) * self.criterion_mse(output, bert_prob) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=2, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings['train_batch_size']) return model
C'est tout, maintenant notre modèle apprend à "imiter".
Comparaison de modèles
Dans l'article d'origine, les meilleurs résultats de classification pour SST-2 sont obtenus à a = 0, lorsque le modèle apprend uniquement à imiter, sans tenir compte des étiquettes réelles. La précision est toujours inférieure à BERT, mais nettement meilleure que BiLSTM standard.

J'ai essayé de répéter les résultats de l'article, mais dans mes expériences, le meilleur résultat a été obtenu à a = 0,5.
Voici à quoi ressemblent les graphiques de perte et de précision lors de l'apprentissage de LSTM de la manière habituelle. À en juger par le comportement de perte, le modèle a rapidement appris, et quelque part après la sixième ère, le recyclage a commencé.
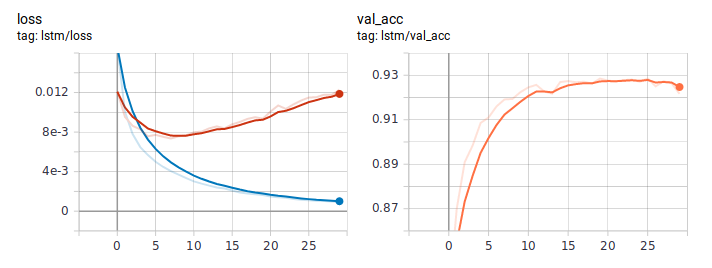
Graphiques de distillation:
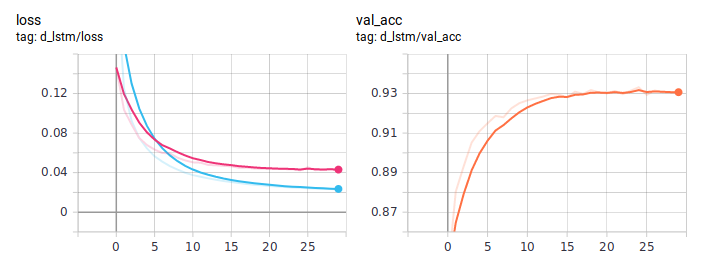
Le BiLSTM distillé est toujours meilleur que la normale. Il est important qu'ils soient absolument identiques en architecture, la seule différence est dans la manière d'enseigner. J'ai posté le code de formation complet sur GitHub .
Conclusion
Dans ce guide, j'ai essayé d'expliquer l'idée de base d'une approche de distillation. L'architecture spécifique de l'étudiant dépendra de la tâche à accomplir. Mais en général, cette approche est applicable dans toute tâche pratique. En raison de la complexité au stade de la formation du modèle, vous pouvez obtenir une augmentation significative de sa qualité, tout en conservant la simplicité originale de l'architecture.