NeurIPS (
Neural Information Processing Systems ) est la plus grande conférence au monde sur l'apprentissage automatique et l'intelligence artificielle et le principal événement dans le monde de l'apprentissage en profondeur.
Au cours de la nouvelle décennie, les ingénieurs DS maîtriseront-ils également la biologie, la linguistique et la psychologie? Nous le dirons dans notre revue.

Cette année, la conférence a réuni plus de 13 500 personnes de 80 pays à Vancouver (Canada). Ce n'est pas la première année que Sberbank représente la Russie à la conférence - l'équipe DS a parlé de l'introduction du ML dans les processus bancaires, de la concurrence ML et des capacités de la plateforme Sberbank DS. Quelles étaient les principales tendances de 2019 dans la communauté ML? Les participants à la conférence racontent:
Andrey Chertok et
Tatyana Shavrina .
Cette année, plus de 1400 articles ont été acceptés à NeurIPS - algorithmes, nouveaux modèles et nouvelles applications pour de nouvelles données.
Lien vers tous les matériauxContenu:
- Les tendances
- Interprétabilité du modèle
- Multidisciplinarité
- Raisonnement
- RL
- Gan
- Conférences clés invitées
- «Intelligence sociale», Blaise Aguera y Arcas (Google)
- «Science des données véridiques», Bin Yu (Berkeley)
- «Modélisation du comportement humain avec l'apprentissage automatique: opportunités et défis», Nuria M Oliver, Albert Ali Salah
- «Du système 1 au système 2 Deep Learning», Yoshua Bengio
Tendances 2019
1. Interprétabilité du modèle et nouvelle méthodologie MLLe thème principal de la conférence est l'interprétation et la preuve de la raison pour laquelle nous obtenons tel ou tel résultat. Vous pouvez parler longtemps de l’importance philosophique de l’interprétation de la «boîte noire», mais il y avait des méthodes et des développements techniques plus réels dans ce domaine.
La méthodologie de la reproductibilité des modèles et de l'extraction des connaissances à partir d'eux est une nouvelle boîte à outils de la science. Les modèles peuvent servir d'outil pour acquérir de nouvelles connaissances et les tester, et chaque étape du prétraitement, de la formation et de l'application du modèle doit être reproductible.
Une part importante des publications est consacrée non pas à la construction de modèles et d'outils, mais aux problèmes de sécurité, de transparence et de vérifiabilité des résultats. En particulier, un flux distinct est apparu sur les attaques contre le modèle (attaques contradictoires), et les options pour les attaques sur la formation et les attaques sur les applications sont envisagées.
Articles:
- Veridical Data Science est un article de fond sur la méthodologie de vérification des modèles. Il comprend un aperçu des outils modernes pour interpréter les modèles, en particulier l'utilisation de l'attention et l'obtention de l'importance des fonctionnalités en raison de la "distillation" du réseau neuronal par des modèles linéaires.
- Cela ressemble à ça: l'apprentissage en profondeur pour la reconnaissance d'images interprétables Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, Jonathan K. Su
- Une référence pour les méthodes d'interprétabilité dans les réseaux de neurones profonds Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, Been Kim
- Vers un apprentissage du renforcement interprétable à l'aide d'agents augmentant l'attention Alexander Mott, Daniel Zoran, Mike Chrzanowski, Daan Wierstra, Danilo Jimenez Rezende
- Une mesure de l'importance de la fonctionnalité MDI de biais pour les forêts aléatoires Xiao Li, Yu Wang, Sumanta Basu, Karl Kumbier, Bin Yu
- Extraction de connaissances sans données observables Jaemin Yoo, Minyong Cho, Taebum Kim, U Kang
- Une étape vers la quantification de la recherche sur l'apprentissage automatique reproductible de façon indépendante Edward Raff
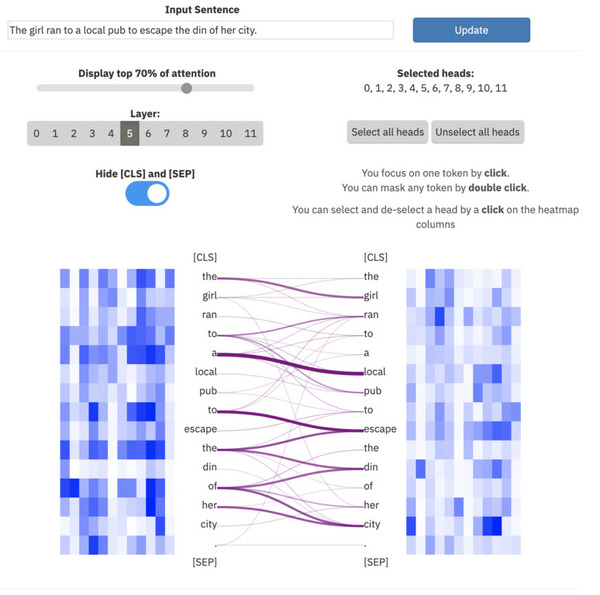 ExBert.net montre l'interprétation des modèles pour les tâches de traitement de texte
ExBert.net montre l'interprétation des modèles pour les tâches de traitement de texte
2. MultidisciplinaritéAfin d'assurer une vérification fiable et de développer des mécanismes pour tester et reconstituer les connaissances, des spécialistes de domaines connexes sont nécessaires, qui ont simultanément des compétences en ML et dans le domaine (médecine, linguistique, neurobiologie, éducation, etc.). Il convient de noter en particulier la présence plus importante d'ouvrages et de présentations sur les neurosciences et les sciences cognitives - il y a un rapprochement des spécialistes et des idées d'emprunt.
En plus de ce rapprochement, une multidisciplinarité est prévue dans le traitement conjoint d'informations provenant de différentes sources: texte et photos, texte et jeux, bases de données graphiques + texte et photos.
Articles:
 Deux modèles - un stratège et un interprète - basés sur RL et NLP jouent une stratégie en ligne3. Raisonnement
Deux modèles - un stratège et un interprète - basés sur RL et NLP jouent une stratégie en ligne3. RaisonnementRenforcer l'intelligence artificielle - un mouvement vers des systèmes d'auto-apprentissage, «conscient», raisonnement et argumentation (raisonnement). En particulier, l'inférence causale et le raisonnement de bon sens se développent. Une partie des rapports est consacrée au méta-apprentissage (comment apprendre à apprendre) et à la combinaison des technologies DL avec une logique du 1er et du 2e ordre - le terme Intelligence artificielle générale (AGI) devient un terme courant dans les discours des intervenants.
Articles:
- Apprentissage de graphes hétérogènes pour le raisonnement Visual Commonsense Weijiang Yu, Jingwen Zhou, Weihao Yu, Xiaodan Liang, Nong Xiao
- Faire le pont entre l'apprentissage automatique et le raisonnement logique par Abductive Learning Wang-Zhou Dai, Qiuling Xu, Yang Yu, Zhi-Hua Zhou
- Apprendre implicitement à raisonner en logique de premier ordre Vaishak Belle, Brendan Juba
- PHYRE: une nouvelle référence pour le raisonnement physique Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, Ross Girshick
- Intégration quantique des connaissances pour raisonner Dinesh Garg, Shajith Ikbal, Santosh K. Srivastava, Harit Vishwakarma, Hima Karanam, L Venkata Subramaniam
4. Apprentissage du renforcementLa plupart des travaux continuent de développer les domaines traditionnels de RL - DOTA2, Starcraft, combinant des architectures avec la vision par ordinateur, la PNL, des bases de données graphiques.
Une journée distincte de la conférence a été consacrée à l'atelier RL, qui a présenté l'architecture du modèle Optimistic Actor Critic, surpassant toutes les précédentes, en particulier Soft Actor Critic.
Articles:
 Les joueurs de StarCraft affrontent Alphastar (DeepMind)5. GAN
Les joueurs de StarCraft affrontent Alphastar (DeepMind)5. GANLes réseaux génératifs sont toujours au centre de l'attention: de nombreux travaux utilisent des GAN vanille pour les preuves mathématiques, et les appliquent également dans de nouvelles versions inhabituelles (modèles génératifs de graphes, travail avec des séries, application des relations de cause à effet dans les données, etc.).
Articles:
Étant donné que le travail a été pris plus de
1 400 ci-dessous, nous parlerons des performances les plus importantes.
Conférences invitées
«Intelligence sociale», Blaise Aguera y Arcas (Google)
LienDiapositives et vidéosLe rapport est consacré à la méthodologie générale d'apprentissage automatique et aux perspectives qui changent actuellement l'industrie - à quel carrefour sommes-nous confrontés? Comment fonctionnent le cerveau et l'évolution, et pourquoi utilisons-nous si peu que nous connaissons déjà bien le développement des systèmes naturels?
Le développement industriel du ML coïncide largement avec les étapes du développement de Google, qui publie d'année en année ses recherches sur NeurIPS:
- 1997 - lancement des capacités de recherche, premiers serveurs, petite puissance de calcul
- 2010 - Jeff Dean lance le projet Google Brain, un boom des réseaux neuronaux au tout début
- 2015 - implémentation industrielle des réseaux de neurones, reconnaissance rapide des visages directement sur l'appareil local, processeurs bas niveau affinés par le calcul tensoriel - TPU. Google lance Coral ai - un analogue de Raspberry Pi, un mini-ordinateur pour introduire des réseaux de neurones dans des installations expérimentales
- 2017 - Google commence le développement d'une formation décentralisée et combine les résultats de la formation de réseaux de neurones à partir de différents appareils en un seul modèle - sur Android
Aujourd'hui, toute une industrie se préoccupe de la sécurité des données, combinant et reproduisant les résultats d'apprentissage sur les appareils locaux.
Apprentissage fédéré - direction ML, dans laquelle les modèles individuels étudient indépendamment, puis sont combinés en un seul modèle (sans centraliser les données sources), ajusté pour les événements rares, les anomalies, la personnalisation, etc. Tous les appareils Android sont essentiellement un seul supercalculateur informatique pour Google.
Les modèles génératifs basés sur l'apprentissage fédéré sont un futur domaine prometteur, selon Google, qui est «aux premiers stades de la croissance exponentielle». Selon le conférencier, les GAN sont capables d'apprendre à reproduire le comportement de masse des populations d'organismes vivants, en pensant aux algorithmes.
En utilisant deux architectures GAN simples à titre d'exemple, il est montré que la recherche du chemin d'optimisation se déplace dans un cercle, ce qui signifie que l'optimisation ne se produit pas en tant que telle. De plus, ces modèles modélisent avec beaucoup de succès les expériences que les biologistes effectuent sur les populations bactériennes, les forçant à apprendre de nouvelles stratégies de comportement à la recherche de nourriture. Nous pouvons conclure que la vie fonctionne différemment de la fonction d'optimisation.
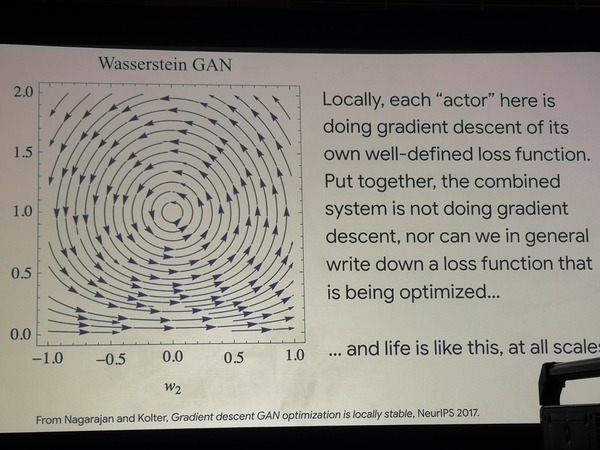 Optimisation du GAN errant
Optimisation du GAN errantTout ce que nous faisons maintenant dans le cadre de l'apprentissage automatique, ce sont des tâches étroites et extrêmement formalisées, alors que ces formalismes sont peu généralisés et ne correspondent pas à nos connaissances dans des domaines tels que la neurophysiologie et la biologie.
Ce qui vaut vraiment la peine d'emprunter dans le domaine de la neurophysiologie dans un avenir proche, c'est la nouvelle architecture des neurones et une petite révision des mécanismes de rétro-propagation de l'erreur.
Le cerveau humain lui-même n'apprend pas à utiliser un réseau de neurones:
- Il n'a pas d'introduction primaire aléatoire, y compris celles fixées par les sens et dans l'enfance
- Il a les directions établies du développement instinctif (le désir d'apprendre une langue d'un nourrisson, une posture droite)
Apprendre le cerveau individuel est une tâche de bas niveau, peut-être devrions-nous considérer les «colonies» d'individus en évolution rapide, se transmettant des connaissances afin de reproduire les mécanismes de l'évolution du groupe.
Que pouvons-nous prendre en ce moment dans les algorithmes ML:
- Appliquer des modèles de lignée cellulaire qui fournissent une formation à la population, mais la courte durée de vie de l'individu («cerveau individuel»)
- Apprentissage en quelques coups sur quelques exemples
- Structures neuronales plus complexes, fonctions d'activation légèrement différentes
- Passer le «génome» aux générations futures - algorithme de rétropropagation
- Dès que nous relierons la neurophysiologie et les réseaux de neurones, nous apprendrons à construire un cerveau multifonctionnel à partir de nombreux composants.
De ce point de vue, la pratique des solutions SOTA est préjudiciable et doit être revue afin de développer des tâches communes (benchmarks).
«Science des données véridiques», Bin Yu (Berkeley)
Vidéos et diapositivesLe rapport est consacré au problème de l'interprétation des modèles d'apprentissage automatique et de la méthodologie de leur vérification et vérification directes. Tout modèle de ML formé peut être perçu comme une source de connaissances qui doit en être extraite.
Dans de nombreux domaines, en particulier en médecine, l'application du modèle est impossible sans extraire ces connaissances cachées et interpréter les résultats du modèle - sinon nous ne serons pas sûrs que les résultats seront stables, non aléatoires, fiables et ne tueront pas le patient. Toute la direction de la méthodologie de travail se développe à l'intérieur du paradigme de l'apprentissage en profondeur et dépasse ses limites - la science des données véridiques. Qu'est ce que c'est
Nous voulons atteindre la qualité des publications scientifiques et la reproductibilité des modèles afin qu'ils soient:
- prévisible
- calculable
- stable
Ces trois principes forment la base de la nouvelle méthodologie. Comment les modèles ML peuvent-ils être testés par rapport à ces critères? Le moyen le plus simple est de construire des modèles immédiatement interprétables (régressions, arbres de décision). Cependant, nous voulons obtenir les avantages immédiats de l'apprentissage en profondeur.
Plusieurs façons existantes de résoudre le problème:
- interpréter le modèle;
- Utilisez des méthodes basées sur l'attention
- utiliser des ensembles d'algorithmes pour la formation et faire en sorte que les modèles interprétables linéaires apprennent à prédire les mêmes réponses qu'un réseau neuronal, en interprétant les caractéristiques d'un modèle linéaire;
- Modifiez et augmentez les données d'entraînement. Cela comprend l'ajout de bruit, d'interférences et d'augmentation des données;
- toute méthode garantissant que les résultats du modèle ne sont pas aléatoires et ne dépendent pas de petites interférences indésirables (attaques contradictoires);
- interpréter le modèle post factum après la formation;
- étudier les poids des panneaux de différentes manières;
- étudier les probabilités de toutes les hypothèses, la distribution des classes.
 Attaque contradictoire sur un porc
Attaque contradictoire sur un porcLes erreurs de modélisation coûtent cher à tout le monde: un exemple frappant - le travail de Reinhart et Rogov "
Croissance en temps d'endettement " a influencé les politiques économiques de nombreux pays européens et les a forcés à poursuivre une politique d'épargne, mais un recoupement soigneux des données et de leur traitement des années plus tard a montré le résultat inverse!
Toute technologie ML a son propre cycle de vie de la mise en œuvre à la mise en œuvre. La tâche de la nouvelle méthodologie est de vérifier trois principes de base à chaque étape de la vie du modèle.
Résumé:
- Plusieurs projets sont en cours d'élaboration pour aider le modèle ML à être plus fiable. Il s'agit, par exemple, deeptune (lien vers: github.com/ChrisCummins/paper-end2end-dl );
- Pour poursuivre le développement de la méthodologie, il est nécessaire d'améliorer considérablement la qualité des publications dans le domaine du BC;
- L'apprentissage automatique a besoin de leaders possédant une formation multidisciplinaire et une expertise dans les domaines techniques et humanitaires.
«Modélisation du comportement humain avec l'apprentissage automatique: opportunités et défis» Nuria M Oliver, Albert Ali Salah
Conférence sur la modélisation du comportement humain, ses fondements technologiques et ses perspectives d'application.
La modélisation du comportement humain peut être divisée en:
- comportement individuel
- comportement en petit groupe
- comportement de masse
Chacun de ces types peut être modélisé à l'aide de ML, mais avec des informations et des fonctionnalités d'entrée complètement différentes. Chaque type a également ses propres problèmes éthiques que chaque projet traverse:
- comportement individuel - vol d'identité, contrefaçon;
- le comportement de groupes de personnes - désanonymisation, obtention d'informations sur les mouvements, appels téléphoniques, etc.;
Comportement individuelDans une plus large mesure, le thème de la vision par ordinateur - la reconnaissance des émotions humaines, ses réactions. Elle n'est possible que dans le contexte, dans le temps ou avec une échelle relative de sa propre variabilité des émotions. Sur la diapositive est la reconnaissance des émotions de Mona Lisa en utilisant le contexte du spectre émotionnel des femmes méditerranéennes. Résultat: un sourire de joie, mais avec mépris et dégoût. La raison en est probablement la manière technique de déterminer l'émotion «neutre».
Comportement en petits groupesJusqu'à présent, le pire est modélisé en raison du manque d'informations. Les œuvres de 2018-2019 ont été présentées à titre d'exemple. sur des dizaines de personnes X des dizaines de vidéos (cf. jeux de données images 100k ++). Pour la meilleure simulation dans cette tâche, des informations multimodales sont nécessaires, de préférence des capteurs au télé-altimètre, au thermomètre, à l'enregistrement du microphone, etc.
Comportement de masseLe domaine le plus développé, le client étant les Nations Unies et de nombreux États. Caméras de surveillance extérieures, données des tours téléphoniques - facturation, SMS, appels, données sur les déplacements entre les frontières des États - tout cela donne une idée très fiable de la circulation des flux de personnes, des instabilités sociales. Applications potentielles de la technologie: optimisation des opérations de sauvetage, assistance et évacuation rapide de la population en cas d'urgence. Jusqu'à présent, les modèles utilisés sont pour la plupart mal interprétés - il s'agit de divers LSTM et réseaux convolutionnels. Il y a eu une brève remarque que l'ONU fait pression pour une nouvelle loi qui obligera les entreprises européennes à partager les données anonymisées nécessaires à toute recherche.
«Du système 1 au système 2 Deep Learning», Yoshua Bengio
DiapositivesDans une conférence de Joshua, l'apprentissage profond de Benjio rencontre les neurosciences au niveau de la définition des objectifs.
Benjio identifie deux principaux types de tâches selon la méthodologie du lauréat du prix Nobel Daniel Kahneman (le livre «
Penser lentement, résoudre rapidement »)
type 1 - Système 1, les actions inconscientes que nous faisons «sur la machine» (l'ancien cerveau): conduire une voiture dans des endroits familiers, marcher, reconnaître des visages.
type 2 - Système 2, actions conscientes (cortex cérébral), définition d'objectifs, analyse, réflexion, tâches composites.
L'IA atteint jusqu'à présent des hauteurs suffisantes uniquement dans les tâches du premier type - alors que notre tâche est de l'amener au second, après avoir appris à effectuer des opérations multidisciplinaires et à fonctionner avec des compétences cognitives logiques de haut niveau.
Pour atteindre cet objectif, il est proposé:
- utiliser l'attention comme un mécanisme clé pour modéliser la pensée dans les tâches de PNL
- utiliser le méta-apprentissage et l'apprentissage de la représentation pour une meilleure modélisation des signes qui affectent la conscience et leur localisation - et en fonction de ceux-ci, passer à l'exploitation avec des concepts de niveau supérieur.
Au lieu de la conclusion, nous laissons l'entrée invitée: Benjio est l'un des nombreux scientifiques qui tentent d'étendre le champ ML au-delà des problèmes d'optimisation, de SOTA et de nouvelles architectures.
La question reste ouverte de savoir dans quelle mesure la combinaison des problèmes de conscience, de l'influence du langage sur la pensée, la neurobiologie et les algorithmes est ce qui nous attend dans le futur et nous permettra de passer à des machines qui «pensent» comme les gens.
Je vous remercie!