Le mappage de données est un moyen de séparer le code d'application en couches. Le mappage est largement utilisé dans les applications Android. Un exemple populaire de l'architecture de l'application mobile Android-CleanArchitecture utilise le mappage à la fois dans la version d'origine ( un exemple de mappeur de CleanArchitecture ) et dans la nouvelle version de Kotlin ( un exemple de mappeur ).
Le mappage vous permet de délier les couches de l'application (par exemple, de vous débarrasser de l'API), de simplifier et de rendre le code plus visuel.
Un exemple de mappage utile est illustré dans le diagramme:
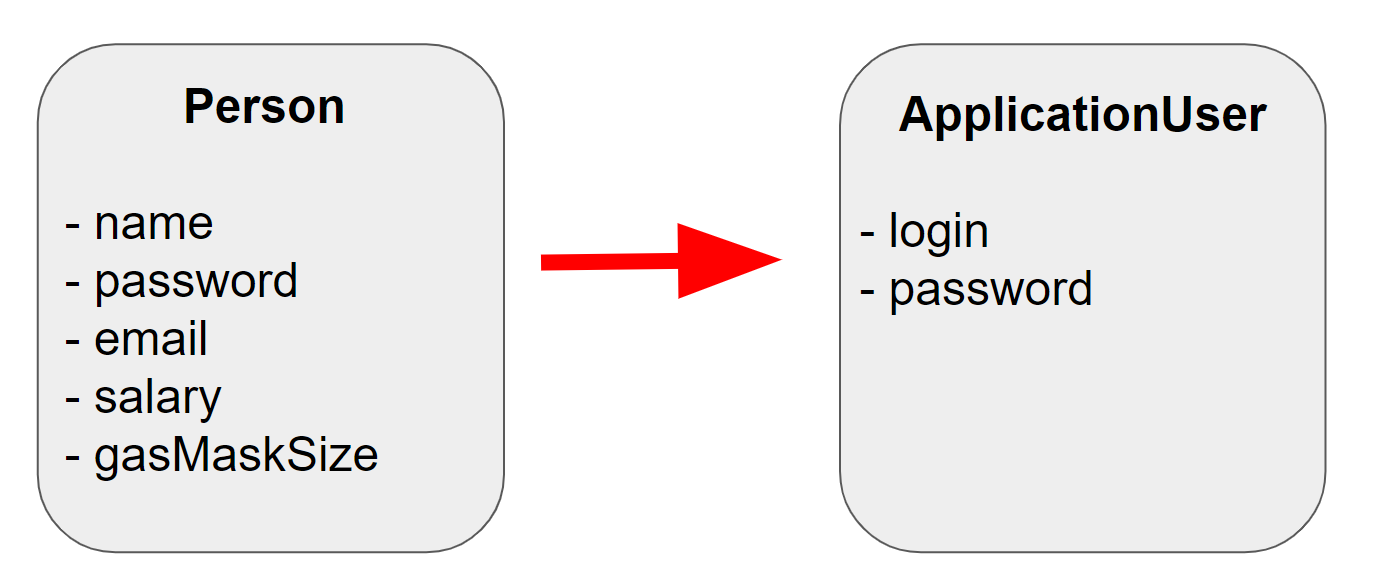
Il n'est pas nécessaire de transférer tous les champs du modèle Person si dans la partie de l'application qui nous intéresse nous n'avons besoin que de deux champs: login et password . S'il est plus pratique pour nous de considérer Person comme un utilisateur d'application, après la carte, nous pouvons facilement utiliser un modèle avec un nom que nous comprenons.
Examinons des méthodes pratiques et pratiques de mappage de données à l'aide de l'exemple de conversion de deux modèles Person et Salary de la couche Source vers le modèle de couche Destination .

Par exemple, les modèles sont simplifiés. Person contient un Salary dans les deux couches de l'application.
Dans ce code, si vous avez le même modèle, il peut être utile de réviser les couches de l'application et de ne pas utiliser le mappage.
Méthode n ° 1: Méthodes de mappage
Un exemple:
class PersonSrc( private val name: String, private val salary: SalarySrc ) { fun mapToDestination() = PersonDst( name, salary.mapToDestination()
La méthode la plus rapide et la plus simple. C'est lui qui est utilisé dans CleanArchitecture Kotlin ( un exemple de cartographie ).
Un avantage est la possibilité de masquer les champs. Les champs dans PersonSrc peuvent être private , le code qui utilise la classe PersonSrc est indépendant d'eux, ce qui signifie que la cohérence du code est réduite.
Un tel code est plus rapide à écrire et plus facile à modifier - les déclarations de champ et leur utilisation sont au même endroit. Pas besoin d'exécuter le projet et de modifier différents fichiers lors de la modification des champs de classe.
Cependant, cette option est plus difficile à tester. La méthode de mappage de la classe PersonSrc PersonSrc appel à la méthode de SalarySrc . Ainsi, tester uniquement la cartographie des Person sans la cartographie des Salary sera plus difficile. Vous devrez utiliser moki pour cela.
Un autre problème peut survenir si, selon les exigences de l'architecture, les couches d'application ne peuvent pas se connaître: i.e. dans la classe Src d'un calque, vous ne pouvez pas travailler avec un calque Dst et vice versa. Dans ce cas, cette version du mappage ne peut pas être utilisée.
Dans l'exemple considéré, la couche Src dépend de la couche Dst et peut créer des classes de cette couche. Pour la situation inverse (lorsque Dst dépend de Src ), l'option avec les méthodes d'usine statiques convient:
class PersonDst( private val name: String, private val salary: SalaryDst ) { companion object { fun fromSource( src: PersonSrc ) = PersonDst(src.name, SalaryDst.fromSource(src.salary)) } } class SalaryDst( private val amount: Int ) { companion object { fun fromSource(src: SalarySrc) = SalaryDst(src.amount) } }
Le mappage est à l'intérieur des classes de la couche Dst , ce qui signifie que ces classes ne révèlent pas toutes leurs propriétés et leur structure au code qui les utilise.
Si dans l'application une couche dépend de l'autre et que les données sont transférées entre les couches d'application dans les deux sens, il est logique d'utiliser des méthodes d'usine statiques avec des méthodes de mappage.
Résumé de la méthode de mappage:
+ Écrivez rapidement du code, le mappage est toujours à portée de main
+ Modification facile
+ Connectivité faible code
- Tests unitaires difficiles (moki nécessaire)
- Pas toujours autorisé par l'architecture
Méthode 2: fonctions de mappeur
Modèles:
class PersonSrc( val name: String, val salary: SalarySrc ) class SalarySrc(val amount: Int) class PersonDst( val name: String, val salary: SalaryDst ) class SalaryDst(val amount: Int)
Mappeurs:
fun mapPerson( src: PersonSrc, salaryMapper: (SalarySrc) -> SalaryDst = ::mapSalary
Dans cet exemple, mapPerson est une fonction d'ordre supérieur car elle obtient le mappeur pour le modèle de Salary . Une caractéristique intéressante de l'exemple spécifique est l'argument par défaut de cette fonction. Cette approche nous permet de simplifier le code appelant et en même temps de redéfinir facilement le mappeur dans les tests unitaires. Vous pouvez utiliser cette méthode de mappage sans la méthode par défaut, en la passant toujours dans le code appelant.
Placer le mappeur et les classes avec lesquelles il fonctionne à différents endroits du projet n'est pas toujours pratique. Avec des modifications fréquentes de la classe, vous devrez rechercher et modifier différents fichiers à différents endroits.
Cette méthode de mappage nécessite que toutes les propriétés avec des données de classe soient visibles pour le mappeur, c'est-à-dire private visibilité private ne peut pas être utilisée pour eux.
Résumé de la méthode de mappage:
+ Tests unitaires simples
- Modification difficile
- Nécessite des champs ouverts pour les classes de données
Méthode 3: fonctions d'extension
Mappeurs:
fun PersonSrc.toDestination( salaryMapper: (SalarySrc) -> SalaryDst = SalarySrc::toDestination ): PersonDst { return PersonDst(this.name, salaryMapper.invoke(this.salary)) } fun SalarySrc.toDestination(): SalaryDst { return SalaryDst(this.amount) }
En général, la même chose que les fonctions du mappeur, mais la syntaxe de l'appel du mappeur est plus simple: .toDestination() .
Il convient de noter que les fonctions d'extension peuvent entraîner un comportement inattendu en raison de leur nature statique: https://kotlinlang.org/docs/reference/extensions.html#extensions-are-resolved-stically
Résumé de la méthode de mappage:
+ Tests unitaires simples
- Modification difficile
- Nécessite des champs ouverts pour les classes de données
Méthode 4: classes de mappeur avec une interface
Les exemples de fonctions ont un inconvénient. Ils vous permettent d'utiliser n'importe quelle fonction avec une signature (SalarySrc) -> SalaryDst . La présence de l'interface Mapper<SRC, DST> contribuera à rendre le code plus évident.
Un exemple:
interface Mapper<SRC, DST> { fun transform(data: SRC): DST } class PersonMapper( private val salaryMapper: Mapper<SalarySrc, SalaryDst> ) : Mapper<PersonSrc, PersonDst> { override fun transform(src: PersonSrc) = PersonDst( src.name, salaryMapper.transform(src.salary) ) } class SalaryMapper : Mapper<SalarySrc, SalaryDst> { override fun transform(src: SalarrSrc) = SalaryDst( src.amount ) }
Dans cet exemple, SalaryMapper est une dépendance PersonMapper . Cela vous permet de remplacer facilement le mappeur de Salary pour les tests unitaires.
En ce qui concerne le mappage dans la fonction, cet exemple n'a qu'un seul inconvénient - la nécessité d'écrire un peu plus de code.
Résumé de la méthode de mappage:
+ Meilleure saisie
- Plus de code
Comme les fonctions du mappeur:
+ Tests unitaires simples
- Modification difficile
- nécessite des champs ouverts pour les classes de données
Méthode 5: réflexion
La méthode de la magie noire. Considérez cette méthode sur d'autres modèles.
Modèles:
data class EmployeeSrc( val firstName: String, val lastName: String, val age: Int
Mappeur:
fun EmployeeSrc.mapWithRef() = with(::EmployeeDst) { val propertiesByName = EmployeeSrc::class.memberProperties.associateBy { it.name } callBy(parameters.associateWith { parameter -> when (parameter.name) { EmployeeDst::name.name -> "$firstName $lastName"
Un exemple est espionné ici .
Dans cet exemple, EmployeeSrc et EmployeeDst stockent le nom dans différents formats. Mapper n'a besoin que de donner un nom au nouveau modèle. Les champs restants sont traités automatiquement, sans écrire de code (l'option else est when ).
La méthode peut être utile, par exemple, si vous avez de grands modèles avec un tas de champs et que les champs coïncident essentiellement pour les mêmes modèles de différentes couches.
Un gros problème se posera, par exemple, si vous ajoutez les champs requis à Dst et que cela ne se trouve pas dans Src ou dans le mappeur: une IllegalArgumentException lors de l'exécution. La réflexion a également des problèmes de performances.
Résumé de la méthode de mappage:
+ moins de code
+ tests unitaires simples
- dangereux
- peut nuire aux performances
Conclusions
De telles conclusions peuvent être tirées de notre réflexion:
Méthodes de mappage - code clair, écriture et maintenance plus rapides
Fonctions de mappage et fonctions d'extension - testez simplement le mappage.
Classes de mappage avec interface - testez simplement le mappage et un code plus clair.
Réflexion - adapté aux situations non standard.