Nous verrons comment Zabbix fonctionne avec la base de données TimescaleDB en tant que backend. Nous montrons comment repartir de zéro et comment migrer avec PostgreSQL. Nous donnons également des tests de performance comparatifs des deux configurations.

HighLoad ++ Siberia 2019. Salle Tomsk. 24 juin, 16h00. Résumés et
présentation . La prochaine conférence HighLoad ++ se tiendra les 6 et 7 avril 2020 à Saint-Pétersbourg. Détails et billets
ici .
Andrey Gushchin (ci -
après dénommé
AG): - Je suis ingénieur du support technique ZABBIX (ci-après dénommé Zabbix), un formateur. Je travaille dans le support technique depuis plus de 6 ans et j'ai été directement confronté à la performance. Aujourd'hui, je vais parler des performances que TimescaleDB peut donner par rapport à PostgreSQL 10. Par ailleurs, une partie introductive - sur la façon dont cela fonctionne.
Principaux défis de performance: de la collecte au nettoyage des données
Pour commencer, il existe certains défis de performances que chaque système de surveillance rencontre. Le premier défi de performance est la collecte et le traitement rapides des données.

Un bon système de surveillance doit recevoir rapidement et en temps opportun toutes les données, les traiter selon des expressions de déclenchement, c'est-à-dire les traiter selon certains critères (dans différents systèmes, c'est différent) et les enregistrer dans la base de données afin d'utiliser ces données à l'avenir.

Le deuxième défi de performance est de garder l'histoire. Stockez souvent dans la base de données et accédez rapidement et facilement à ces mesures qui ont été collectées sur une période de temps. La chose la plus importante est qu'il est pratique d'obtenir ces données, de les utiliser dans des rapports, des graphiques, des déclencheurs, dans certaines valeurs de seuil, pour des alertes, etc.

Le troisième défi en termes de performances consiste à effacer l'histoire, c'est-à-dire lorsque votre journée est telle que vous n'avez pas besoin de stocker des statistiques détaillées qui ont été collectées sur 5 ans (voire des mois ou deux mois). Certains nœuds de réseau ont été supprimés ou certains hôtes, les mesures ne sont plus nécessaires car elles sont déjà obsolètes et ne sont plus collectées. Tout cela doit être nettoyé pour que votre base de données ne s'agrandisse pas. En général, l'effacement de l'historique est le plus souvent un test sérieux pour le stockage - très souvent, il affecte les performances.
Comment résoudre les problèmes de mise en cache?
Je vais maintenant parler spécifiquement du Zabbix. Dans Zabbix, les premier et deuxième appels sont résolus à l'aide de la mise en cache.

Collecte et traitement des données - nous utilisons la RAM pour stocker toutes ces données. Maintenant, ces données seront discutées plus en détail.
Du côté de la base de données, il existe également une certaine mise en cache pour les principaux échantillons - pour les graphiques, etc.
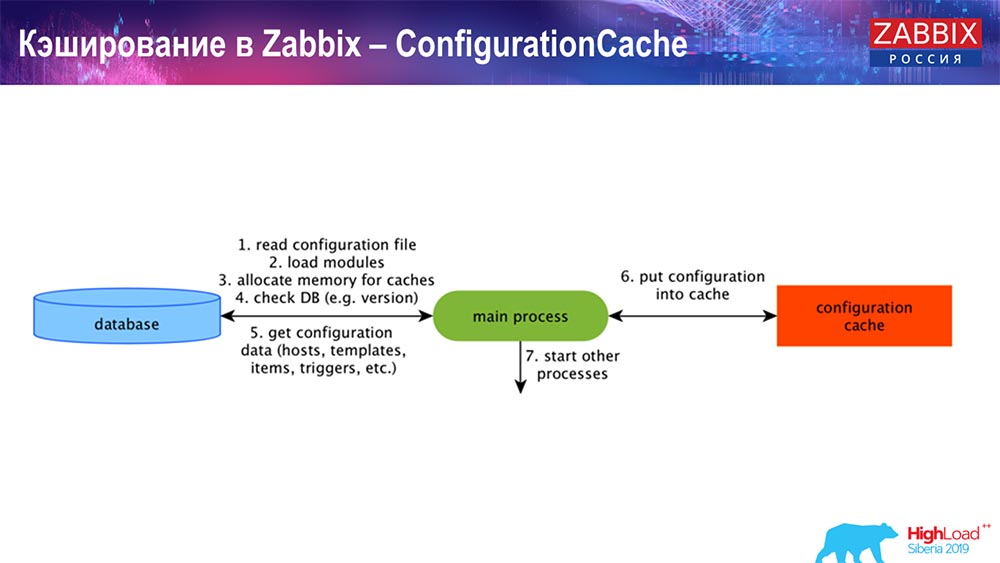
Mise en cache du côté du serveur Zabbix lui-même: nous avons ConfigurationCache, ValueCache, HistoryCache, TrendsCache. Qu'est ce que c'est

ConfigurationCache est le cache principal dans lequel nous stockons les métriques, les hôtes, les éléments de données, les déclencheurs; tout ce dont vous avez besoin pour traiter le prétraitement, collecter les données, auprès de quels hôtes collecter, avec quelle fréquence. Tout cela est stocké dans ConfigurationCache, afin de ne pas aller dans la base de données, de ne pas créer de requêtes inutiles. Après le démarrage du serveur, nous mettons à jour ce cache (créer) et le mettons à jour périodiquement (en fonction des paramètres de configuration).
Mise en cache dans Zabbix. Collecte de données
Ici, le schéma est assez grand:

Les principaux dans le schéma sont ces collecteurs:
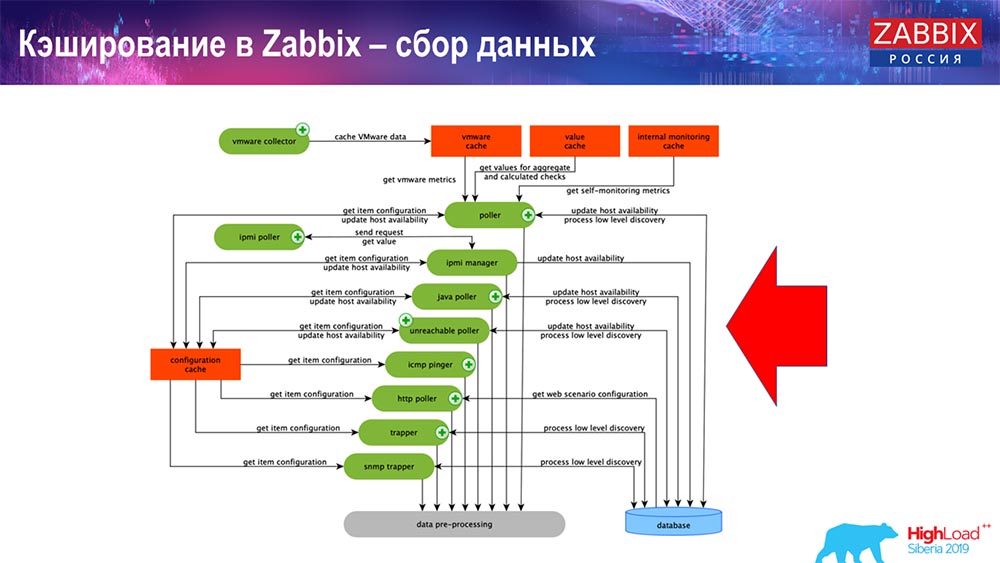
Ce sont les processus d'assemblage eux-mêmes, divers «scrutateurs» qui sont responsables de différents types d'assemblages. Ils collectent des données via icmp, ipmi, selon différents protocoles et transfèrent le tout au prétraitement.
Historique de prétraitement
De plus, si nous avons des éléments de données calculés (qui sait Zabbix - sait), c'est-à-dire des éléments de données calculés et agrégés, nous les prenons directement de ValueCache. Je dirai plus tard comment il est rempli. Tous ces collecteurs utilisent ConfigurationCache pour obtenir leurs travaux, puis les passent au prétraitement.
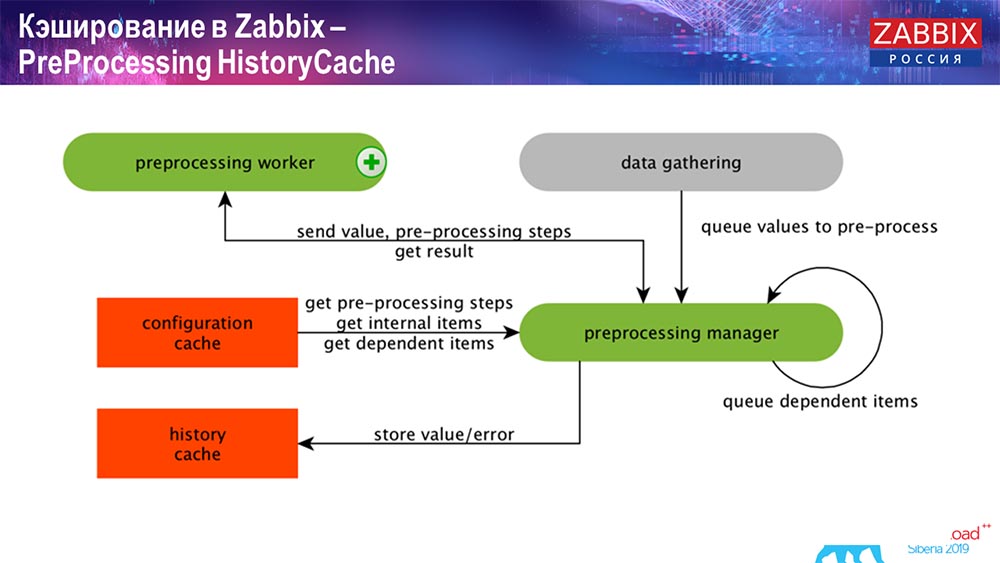
Le prétraitement utilise également ConfigurationCache pour obtenir les étapes de prétraitement; il traite ces données de différentes manières. À partir de la version 4.2, nous l'avons soumis au proxy. C'est très pratique, car le prétraitement lui-même est une opération assez difficile. Et si vous avez un très gros "Zabbix", avec un grand nombre d'éléments de données et une fréquence de collecte élevée, cela facilite grandement le travail.
En conséquence, après avoir traité ces données d'une manière ou d'une autre en utilisant le prétraitement, nous les enregistrons dans HistoryCache afin de les traiter plus en détail. Cela met fin à la collecte de données. Nous passons au processus principal.
Fonctionnement du synchroniseur d'historique
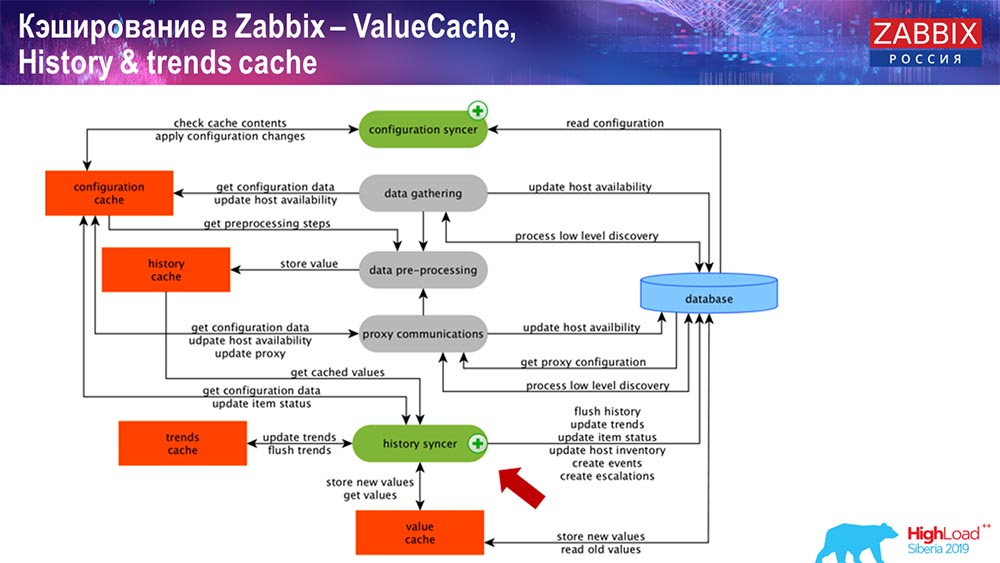
Le principal processus de Zabbix (car il s'agit d'une architecture monolithique) est le synchroniseur d'histoire. Il s'agit du processus principal qui traite spécifiquement du traitement atomique de chaque élément de données, c'est-à-dire de chaque valeur:
- la valeur vient (elle le prend de HistoryCache);
- vérifie dans le synchroniseur de configuration: existe-t-il des déclencheurs de calcul? les calcule;
s'il y en a, il crée des événements, crée une escalade afin de créer une alerte, si nécessaire par configuration; - enregistre les déclencheurs pour le traitement ultérieur, l'agrégation; si vous agrégez au cours de la dernière heure et ainsi de suite, cette valeur se souvient de ValueCache, afin de ne pas accéder à la table d'historique; Ainsi, ValueCache est rempli avec les données nécessaires qui sont nécessaires pour calculer les déclencheurs, les éléments calculés, etc.
- puis le synchroniseur d'historique écrit toutes les données dans la base de données;
- la base de données les écrit sur le disque - c'est là que le processus de traitement se termine.
Bases de données Mise en cache
Du côté de la base de données, lorsque vous souhaitez consulter des graphiques ou des rapports d'événements, il existe plusieurs caches. Mais dans le cadre de ce rapport, je n'en parlerai pas.
Pour MySQL, il y a Innodb_buffer_pool, un tas de caches différents qui peuvent également être configurés.
Mais ce sont les principaux:
- shared_buffers;
- effective_cache_size;
- shared_pool.

J'ai cité pour toutes les bases de données qu'il existe certains caches qui vous permettent de garder en mémoire les données qui sont souvent nécessaires pour les requêtes. Là, ils ont leurs propres technologies pour cela.
À propos des performances de la base de données
En conséquence, il existe un environnement concurrentiel, c'est-à-dire que le serveur Zabbix collecte des données et les enregistre. Lors du redémarrage, il lit également à partir de l'historique pour remplir ValueCache et ainsi de suite. Ici, vous pouvez avoir des scripts et des rapports qui utilisent l'API Zabbix, qui est construite sur la base de l'interface Web. "Zabbiks" -API est inclus dans la base de données et reçoit les données nécessaires pour obtenir des graphiques, des rapports ou une liste d'événements, des problèmes récents.

Grafana est également une solution de visualisation très populaire, utilisée par nos utilisateurs. Capable d'entrer directement à la fois via "Zabbiks" -API et via la base de données. Cela crée également une certaine concurrence pour obtenir des données: un réglage plus fin et meilleur de la base de données est nécessaire pour correspondre à la livraison rapide des résultats et des tests.

Effacer l'histoire. Zabbix a femme de ménage
Le troisième défi utilisé par Zabbix est de clarifier l'histoire avec Housekeeper. Hauskiper respecte tous les paramètres, c'est-à-dire que dans nos éléments de données, il est indiqué combien stocker (en jours), combien stocker les tendances, la dynamique des changements.
Je n'ai pas parlé de TrendCache, que nous calculons à la volée: les données arrivent, nous les agrégons en une heure (en gros ce sont des chiffres dans la dernière heure), le montant est moyen / minimum et l'écrivons une fois par heure dans le tableau des changements de dynamique (Tendances) . Hauskiper démarre et supprime les données de la base de données à l'aide de sélections régulières, ce qui n'est pas toujours efficace.
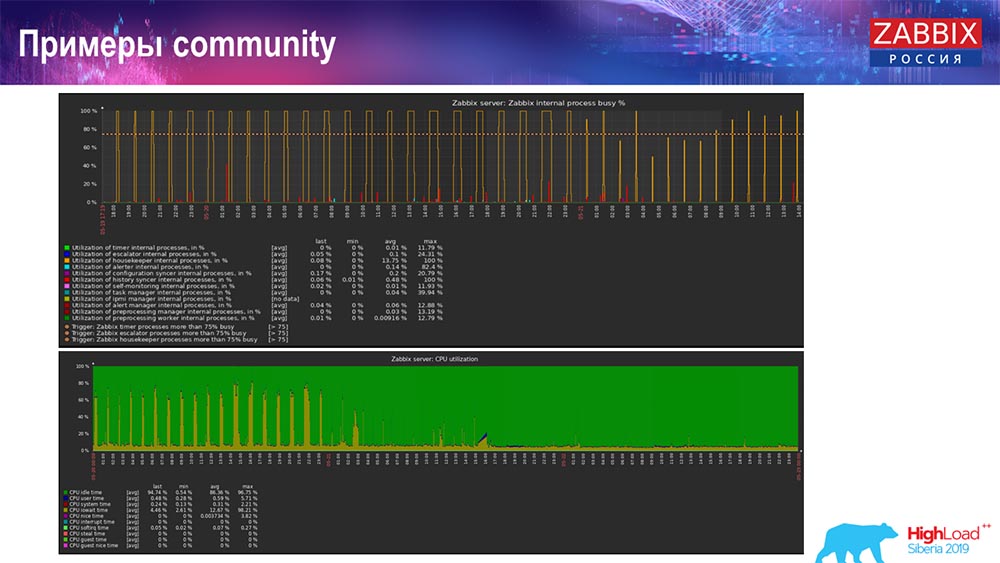
Comment comprendre qu'elle est inefficace? Vous pouvez voir l'image suivante sur les graphiques de performances des processus internes:
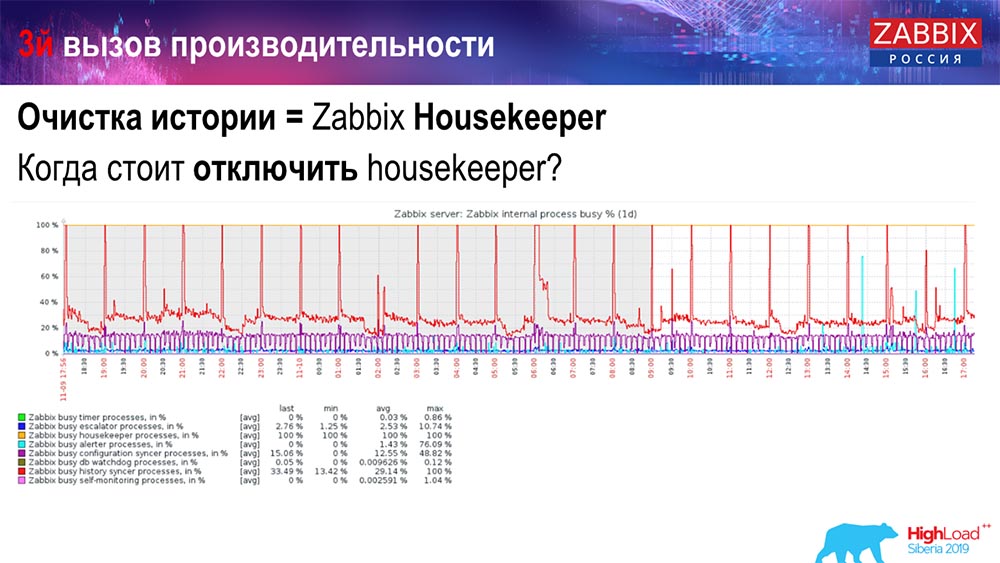
Votre synchroniseur d'historique est constamment occupé (graphique rouge). Et le tableau "rouge" qui va en haut. Il s'agit du Hauskiper, qui démarre et attend la base de données lorsqu'il supprime toutes les lignes qu'il a spécifiées.
Prenez un ID d'article: vous devez supprimer les 5 000 derniers; Bien sûr, par indices. Mais généralement, l'ensemble de données est suffisamment volumineux - la base de données lit toujours cela à partir du disque et le place dans le cache, et c'est une opération très coûteuse pour la base de données. Selon sa taille, cela peut entraîner certains problèmes de performances.
Vous pouvez désactiver Hauskiper de manière simple - nous avons une interface Web familière pour tout le monde. En paramétrant l'administration générale (paramètres de «Gouvernante»), nous désactivons la gestion interne pour l'historique et les tendances internes. En conséquence, Hauskiper ne contrôle plus cela:

Que puis-je faire ensuite? Vous vous êtes déconnecté, vos plannings se sont nivelés ... Quels problèmes peuvent être plus poussés dans ce cas? Qu'est-ce qui peut aider?
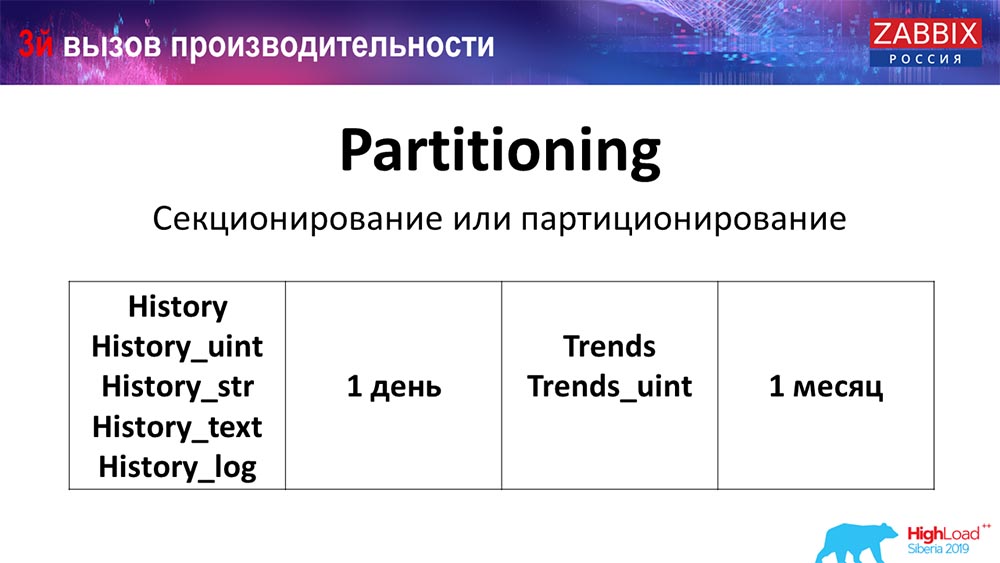
Partitionnement (partitionnement)
Ceci est généralement configuré sur chaque base de données relationnelle que j'ai répertoriée d'une manière différente. MySQL possède sa propre technologie. Mais dans l'ensemble, ils sont très similaires en ce qui concerne PostgreSQL 10 et MySQL. Bien sûr, il existe de nombreuses différences internes dans la façon dont tout est mis en œuvre et comment tout cela affecte les performances. Mais en général, la création d'une nouvelle partition entraîne souvent aussi certains problèmes.

Selon votre configuration (la quantité de données que vous créez en une journée), ils définissent généralement le minimum un - 1 jour / partition, et pour les tendances, la dynamique des changements - 1 mois / nouvelle partition. Cela peut changer si vous avez une très grande configuration.
Disons tout de suite la taille de la configuration: jusqu'à 5 000 nouvelles valeurs par seconde (appelées nvps) - cela sera considéré comme une petite «configuration». Moyenne - de 5 à 25 000 valeurs par seconde. Tout ce qui est au-dessus est déjà des installations grandes et très grandes qui nécessitent une configuration très soignée de la base de données elle-même.
Sur les très grandes installations, 1 jour - cela peut ne pas être optimal. Personnellement, j'ai vu sur des partitions MySQL de 40 gigaoctets par jour (et il peut y en avoir plus). Il s'agit d'une très grande quantité de données, ce qui peut entraîner certains problèmes. Elle doit être réduite.
Pourquoi partitionner?
Ce que le partitionnement donne, je pense que tout le monde le sait, c'est le partitionnement de table. Il s'agit souvent de fichiers distincts sur les demandes de disque et d'étendue. Il sélectionne de manière plus optimale une partition, si elle fait partie de la partition habituelle.
Pour Zabbix, en particulier, il est utilisé par plage, par plage, c'est-à-dire que nous utilisons un horodatage (le nombre est ordinaire, le temps depuis le début de l'ère). Vous spécifiez le début du jour / la fin de la journée, et ceci est une partition. Par conséquent, si vous faites une demande de données il y a deux jours, tout cela est sélectionné plus rapidement dans la base de données, car vous n'avez besoin de télécharger qu'un fichier dans le cache et le problème (plutôt qu'une grande table).

De nombreuses bases de données accélèrent également l'insertion (insertion dans une seule table enfant). Bien que je parle de façon abstraite, mais c'est aussi possible. Le partage est souvent utile.
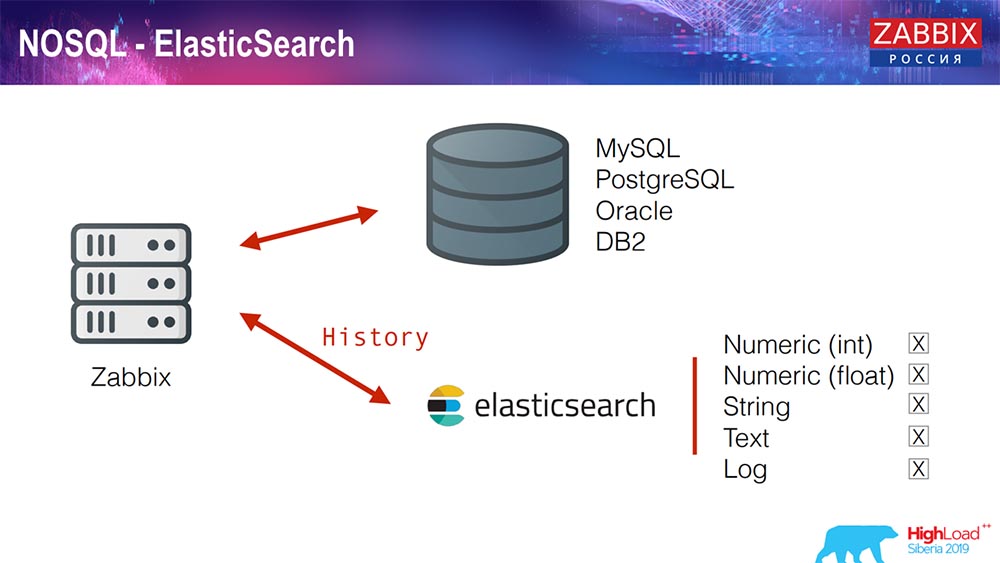
Elasticsearch pour NoSQL
Récemment, en 3.4, nous avons implémenté une solution pour NoSQL. Ajout de la possibilité d'écrire dans Elasticsearch. Vous pouvez écrire quelques types distincts: choisissez - soit écrire des nombres ou des signes; nous avons un texte de chaîne, vous pouvez écrire des journaux dans Elasticsearch ... En conséquence, l'interface Web accédera également à Elasticsearch. Cela fonctionne bien dans certains cas, mais pour le moment, il peut être utilisé.
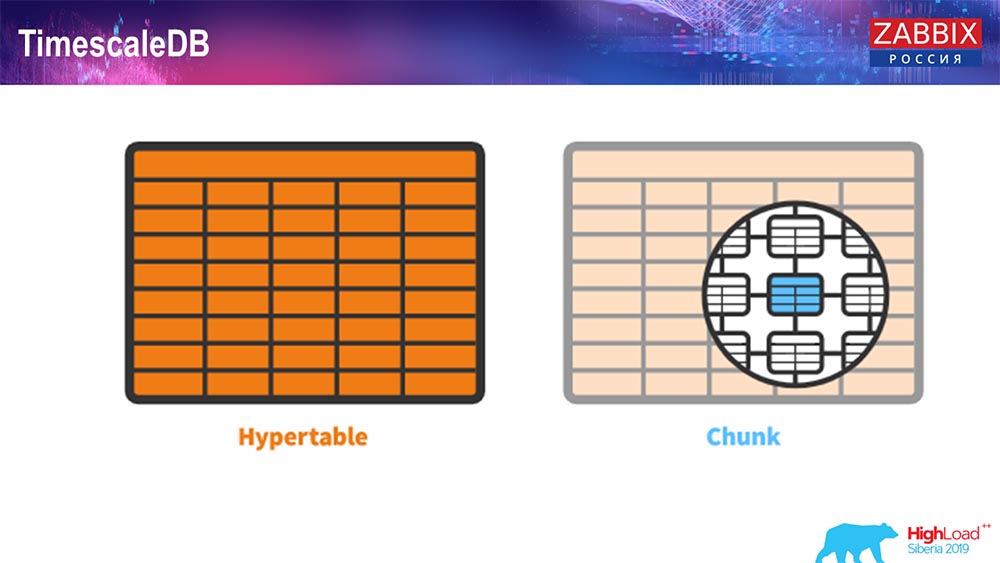
TimescaleDB. Hypertables
Pour 4.4.2, nous avons remarqué une chose comme TimescaleDB. Qu'est ce que c'est Il s'agit d'une extension pour Postgres, c'est-à-dire qu'elle a une interface PostgreSQL native. De plus, cette extension vous permet de travailler avec des données de série temporelle beaucoup plus efficacement et d'avoir un partitionnement automatique. À quoi ça ressemble:

C'est hypertable - il y a un tel concept dans Timescale. Il s'agit de l'hypertable que vous créez et il contient des morceaux. Les morceaux sont des partitions, ce sont des tables enfants, si je ne me trompe pas. C'est vraiment efficace.
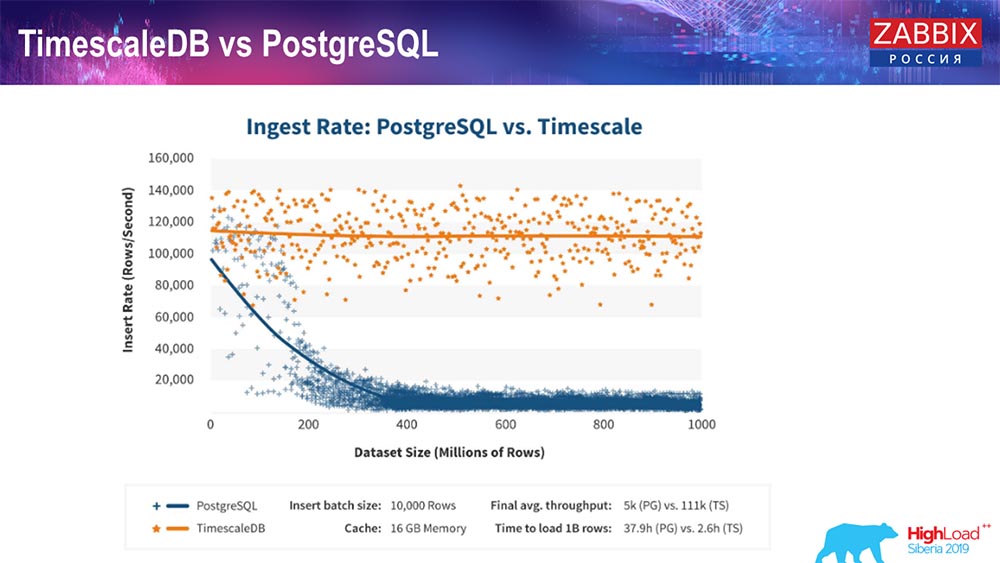
TimescaleDB et PostgreSQL
Comme les fabricants de TimescaleDB le garantissent, ils utilisent un algorithme de traitement des demandes plus correct, en particulier insert'ov, qui vous permet d'avoir des performances à peu près constantes avec une taille croissante de l'insertion de l'ensemble de données. Autrement dit, après 200 millions de lignes de «Postgres», l'habituel commence à s'affaisser et perd littéralement les performances à zéro, tandis que «Timescale» vous permet d'insérer des insertions aussi efficacement que possible avec n'importe quelle quantité de données.
Comment installer TimescaleDB? Tout est simple!
Il l'a dans la documentation, il est décrit - il peut être livré à partir de colis pour tout ... Cela dépend des colis officiels de Postgres. Il peut être compilé manuellement. Il se trouve que j'ai dû compiler pour la base de données.
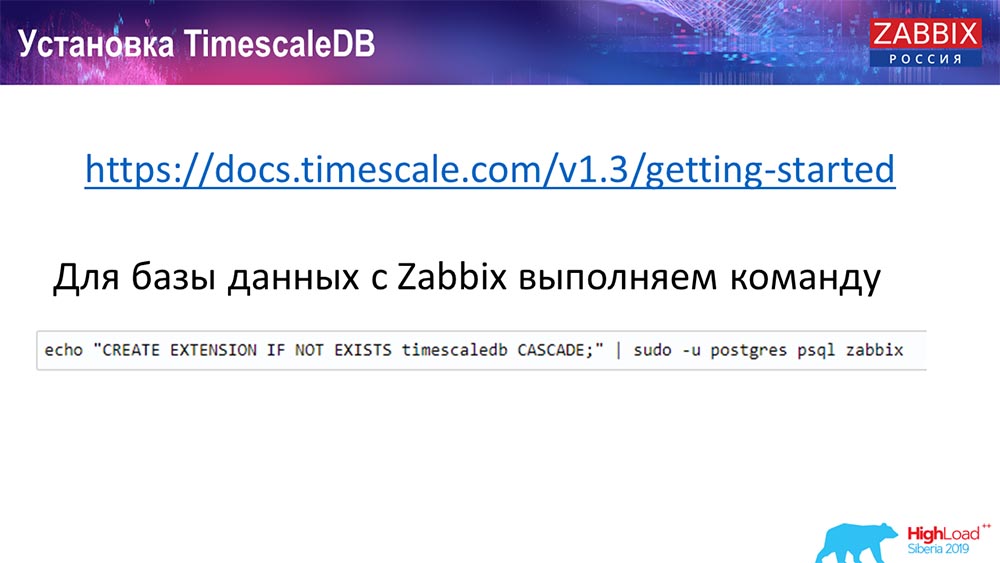
Chez Zabbix, nous venons d'activer Extention. Je pense que ceux qui ont utilisé Extention dans Postgres ... Vous venez d'activer Extention, créez-le pour la base de données Zabbix que vous utilisez.
Et la dernière étape ...
TimescaleDB. Tableaux d'historique de migration
Vous devez créer un hypertable. Il existe une fonction spéciale pour cela - Créer une hypertable. Dans ce document, le premier paramètre indique la table qui est nécessaire dans cette base de données (pour laquelle vous devez créer une hypertable).

Le champ par lequel vous souhaitez créer, et chunk_time_interval (c'est l'intervalle des morceaux (partitions à utiliser). 86 400 est un jour.
Paramètre migrate_data: si vous insérez dans true, cela transfère toutes les données actuelles aux blocs créés précédemment.
J'ai moi-même utilisé migrate_data - cela prend un temps décent, selon la taille de votre base de données. J'avais plus d'un téraoctet - la création a pris plus d'une heure. Dans certains cas, lors des tests, j'ai supprimé les données historiques du texte (history_text) et de la chaîne (history_str), afin de ne pas les transférer - elles n'étaient pas vraiment intéressantes pour moi.
Et nous faisons la dernière mise à jour dans notre db_extention: nous définissons timescaledb pour que la base de données et, en particulier, notre Zabbix comprennent ce qu'est db_extention. Il l'active et utilise la syntaxe et les requêtes de base de données correctes, en utilisant les «fonctionnalités» nécessaires à TimescaleDB.
Configuration du serveur
J'ai utilisé deux serveurs. Le premier serveur est une machine virtuelle assez petite, 20 processeurs, 16 gigaoctets de RAM. Configurez Postgres 10.8 dessus:

Le système d'exploitation était Debian, le système de fichiers était xfs. J'ai fait des réglages minimaux pour utiliser cette base de données particulière, moins ce que Zabbix utilisera. Sur la même machine se trouvait un serveur Zabbix, PostgreSQL et des agents de chargement.

J'ai utilisé 50 agents actifs qui utilisent le LoadableModule pour générer rapidement divers résultats. Ils ont généré des lignes, des nombres, etc. J'ai obstrué la base de données avec beaucoup de données. Initialement, la configuration contenait 5 000 éléments de données par hôte, et approximativement chaque élément de données contenait un déclencheur - de sorte qu'il s'agissait d'une véritable configuration. Parfois, il faut même plus d'un déclencheur pour l'utiliser.

J'ai régulé l'intervalle de mise à jour, la charge elle-même de sorte que j'ai non seulement utilisé 50 agents (ajoutés plus), mais aussi à l'aide d'éléments de données dynamiques et réduit l'intervalle de mise à jour à 4 secondes.
Test de performance. PostgreSQL: 36 000 NVP
Le premier lancement, la première configuration que j'ai eue sur PostreSQL 10 pur sur ce matériel (35 000 valeurs par seconde). En général, comme vous pouvez le voir à l'écran, l'insertion de données prend des fractions de seconde - tout va bien et rapidement, les SSD (200 gigaoctets). La seule chose est que 20 Go se remplissent rapidement.
Il y aura beaucoup plus de tels graphiques. Il s'agit du tableau de bord de performances standard du serveur Zabbix.
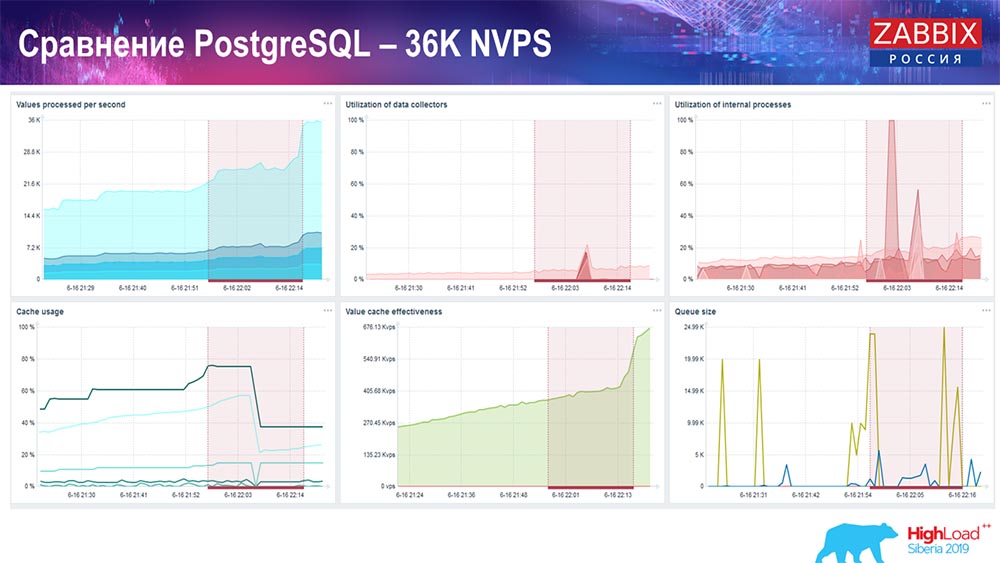
Le premier graphique est le nombre de valeurs par seconde (bleu, en haut à gauche), 35 000 valeurs dans ce cas. Ce (centre de chargement) est le chargement des processus d'assemblage, et celui (en haut à droite) charge les processus internes: les synchroniseurs d'historique et la femme de ménage, qui fonctionnent ici depuis un temps suffisant.
Ce graphique (en bas au centre) montre l'utilisation de ValueCache - combien de hits ValueCache pour les déclencheurs (plusieurs milliers de valeurs par seconde). Un autre graphique important est le quatrième (en bas à gauche), qui montre l'utilisation de HistoryCache, dont j'ai parlé, qui est un tampon avant l'insertion dans la base de données.
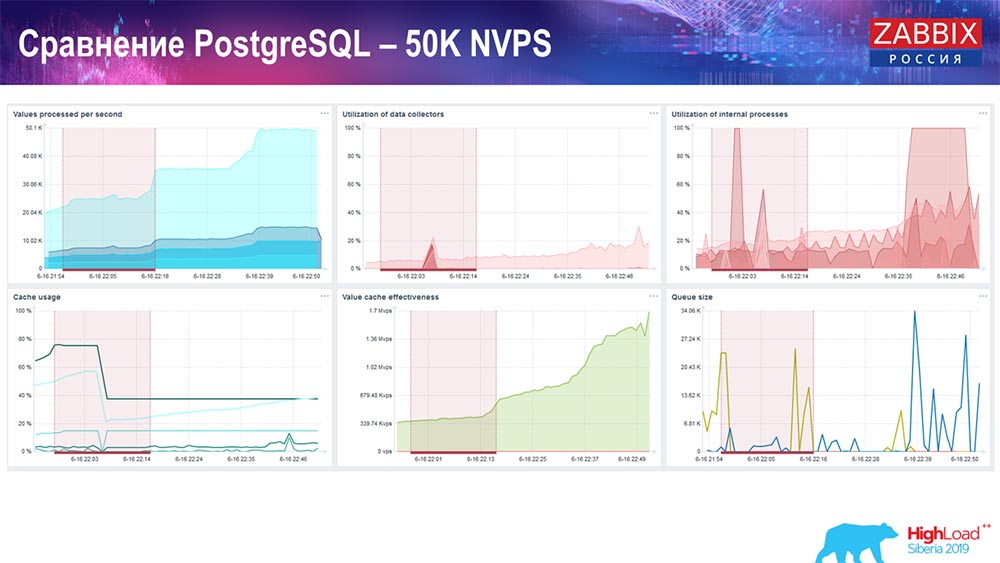
Test de performance. PostgreSQL: 50 000 NVP
Ensuite, j'ai augmenté la charge à 50 000 valeurs par seconde sur le même matériel. Lors du chargement avec Hauskiper, 10 000 valeurs ont déjà été enregistrées en 2-3 secondes avec le calcul. Ce qui, en fait, est illustré dans la capture d'écran suivante:
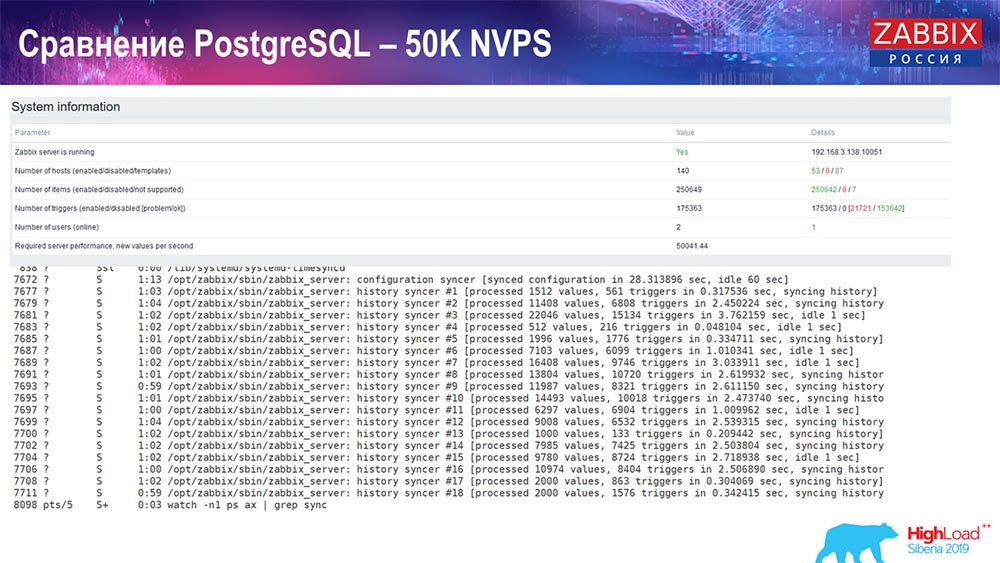
Hauskiper commence déjà à interférer avec le travail, mais en général, le chargement des trappeurs d'histoire est toujours à 60% (troisième graphique, en haut à droite). HistoryCache déjà pendant le travail de "Hauskiper" commence à se remplir activement (en bas à gauche). C'était environ un demi-gigaoctet, rempli à 20%.
Test de performance. PostgreSQL: 80 000 NVP
A augmenté à 80 000 valeurs par seconde:
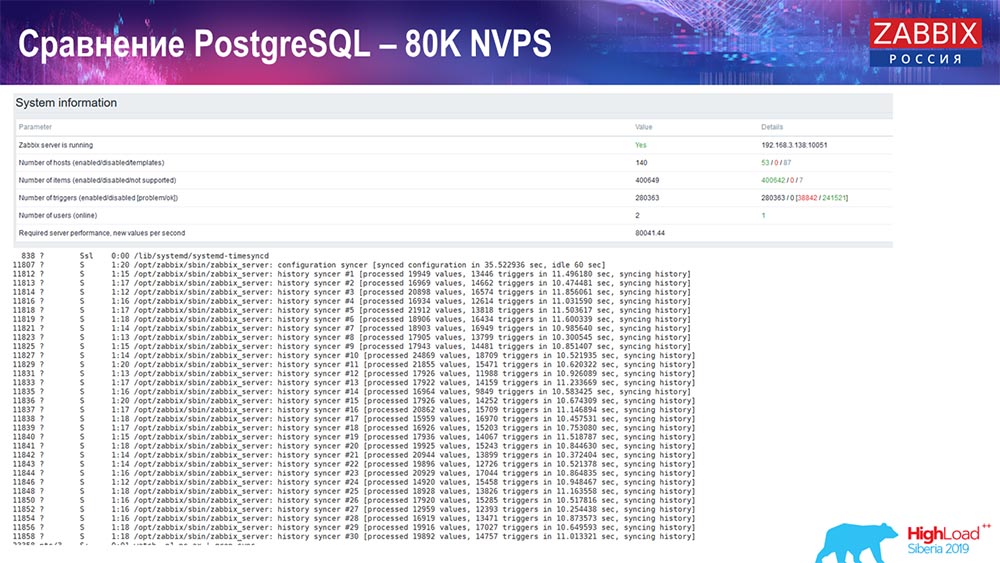
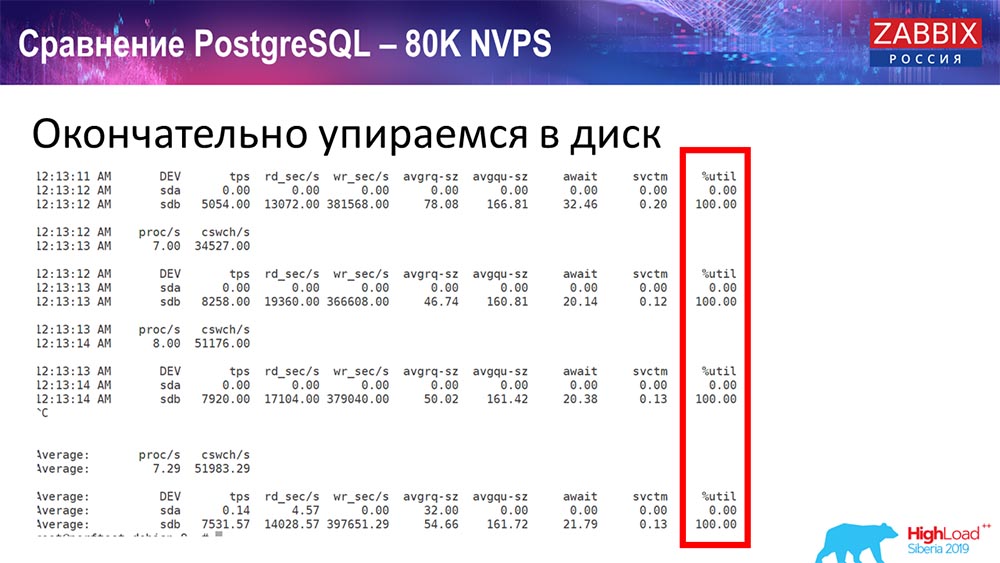
Il s'agissait d'environ 400 000 éléments de données, 280 000 déclencheurs. L'insert, comme vous pouvez le voir, pour le chargement des plombs historiques (il y en avait 30) était déjà assez élevé. De plus, j'ai augmenté divers paramètres: lesteurs d'historique, cache ... Sur ce matériel, le chargement des lesteurs d'histoire a commencé à augmenter au maximum, presque «sur l'étagère» - en conséquence, HistoryCache est passé à une charge très élevée:
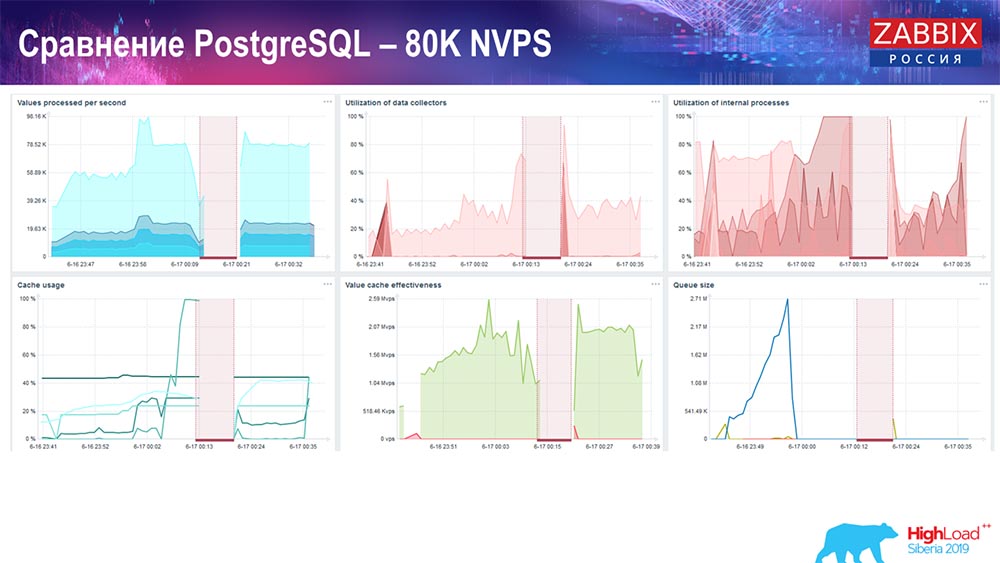
( , ) , – , . «» , , …
, 48 128 :
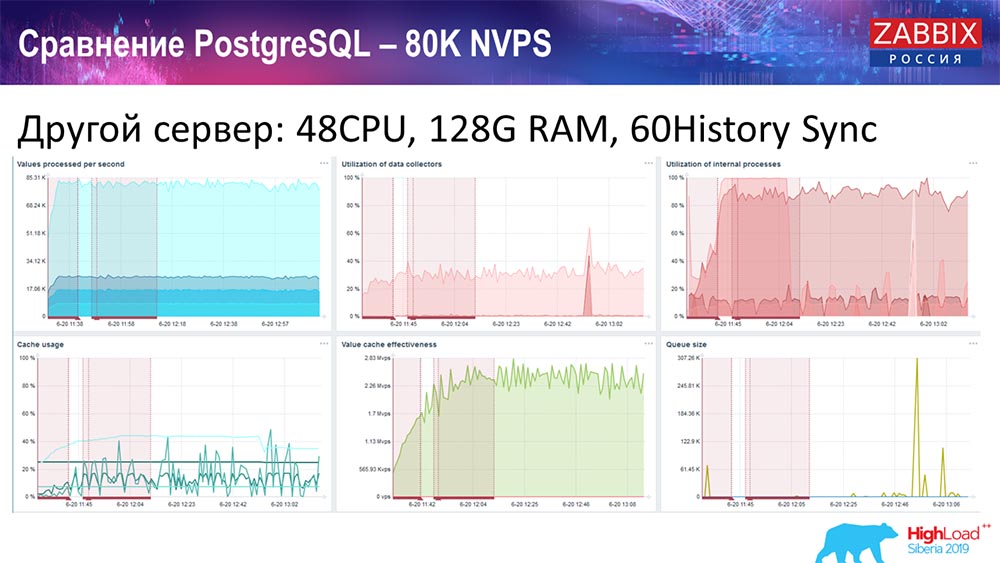
«» – History syncer (60 ) . « », , , , - .
. TimescaleDB: 80 NVPs
– TimescaleDB. :
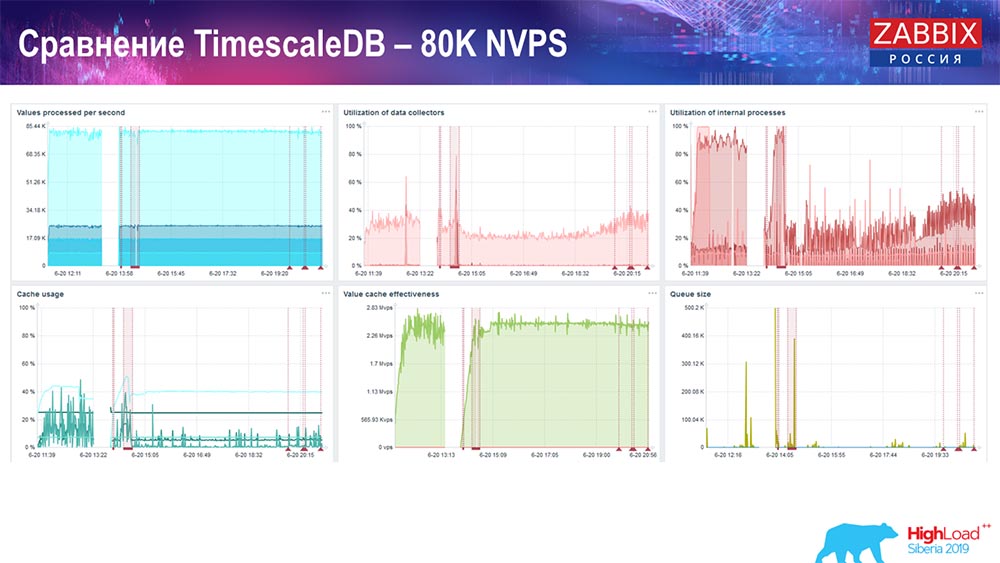
– . «»- -, , . 3 HistoryCache – , . , 80 – rate (, «»). setup, .
PostgreSQL: 120 NVPs
125 :

:
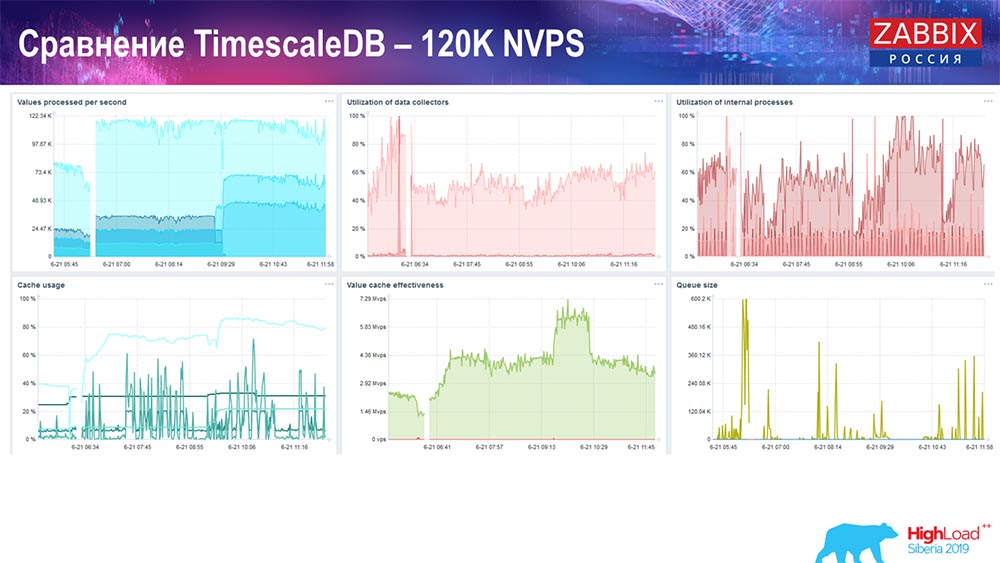
setup, . 1,5 , . , TimescaleDB, , MySQL.
, , . ! – TimescaleDB. : 120 .
«» :
TimescaleDB io.weight ; TimescaleDB. , ( SSD)!
- setup', , TimescaleDB, , . , .
: Conference – , Summit – . – «», , IRC. - – , .
( – ): – TimescaleDB , , , , «» «»? - , -, «», «», «» , ?
 :
: – , , : «» TimescaleDB. , , , «» . , ( TimescaleDB), , ! , , .
«»: - . , . setup'. MySQL… setup' .
: – , community, «»:
. «» TimescaleDB?
: – – . TimescaleDB , - . . .
: – – «».
( ): – , delete, – , , . «», , . , , big data: «!»
«» , . , select' , – « !» ( ). ! , .
: – SQL. , «» , – - . , , , , – Clickhouse, , - -?.. Kafka – ! - ?
: – . «» 3.4: , , ; - . . - , , «». , , , NoSQL- (, «») .
: – , , ?
: – , «» – , , . , - , , , .
: – , , «», ?
: – . , , , «» , . . : . – , – Grafana -.
:- Autrement dit, nous parlons d'une lutte égale, et non du grand avantage de ces bases de données rapides?AG: - Je pense que lorsque nous nous intégrerons, il y aura des tests plus précis.R: - Où est passé le bon vieux RRD? Qu'est-ce qui vous a fait passer aux bases de données SQL? Initialement, sur RRD, toutes les mesures ont été collectées.AG: - Dans le RRD «Zabbix», c'était peut-être dans une version très ancienne. Il y a toujours eu des bases de données SQL - une approche classique. L'approche classique est MySQL, PostgreSQL (ils existent déjà depuis longtemps). Nous avons une interface commune pour les bases de données SQL et RRD, que nous n'avons presque jamais utilisées.
Un peu de publicité :)
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en recommandant à vos amis
des VPS basés sur le cloud pour les développeurs à partir de 4,99 $ , un
analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur les VPS (KVM) E5-2697 v3 (6 cœurs) 10 Go DDR4 480 Go SSD 1 Gbit / s à partir de 19 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher au centre de données Equinix Tier IV à Amsterdam? Nous avons seulement
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99 $! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?