Basé sur la discussion dans le chat de la
communauté AWS MinskRécemment, de véritables batailles ont fait rage pour la définition de DevOps et SRE.
Malgré le fait que, à bien des égards, les discussions sur ce sujet ont déjà pris fin, y compris moi, j'ai décidé de porter à la Cour la communauté habr et mon opinion sur ce sujet. Pour ceux qui sont intéressés, bienvenue au chat. Et que tout recommence!
Contexte
Ainsi, dans les temps anciens, une équipe distincte de développeurs de logiciels et d'administrateurs de serveurs vivait séparément. Le premier a écrit le code avec succès, le second, en utilisant divers mots chaleureux et affectueux adressés au premier, a installé les serveurs, venant périodiquement aux développeurs et recevant en retour un «tout fonctionne sur ma machine» exhaustif. L'entreprise attendait le logiciel, tout était inactif, périodiquement cassé, tout le monde était nerveux. Surtout celui qui a payé pour tout ce bordel. Ère glorieuse de lampe. Eh bien, oui, vous savez déjà d'où proviennent les jambes DevOps.
Pratiques DevOps de naissance
Puis des oncles sérieux sont venus et ont dit que ce n'est pas une industrie, il est impossible de travailler comme ça. Et les modèles de cycle de vie traînés. Par exemple, un modèle en V.
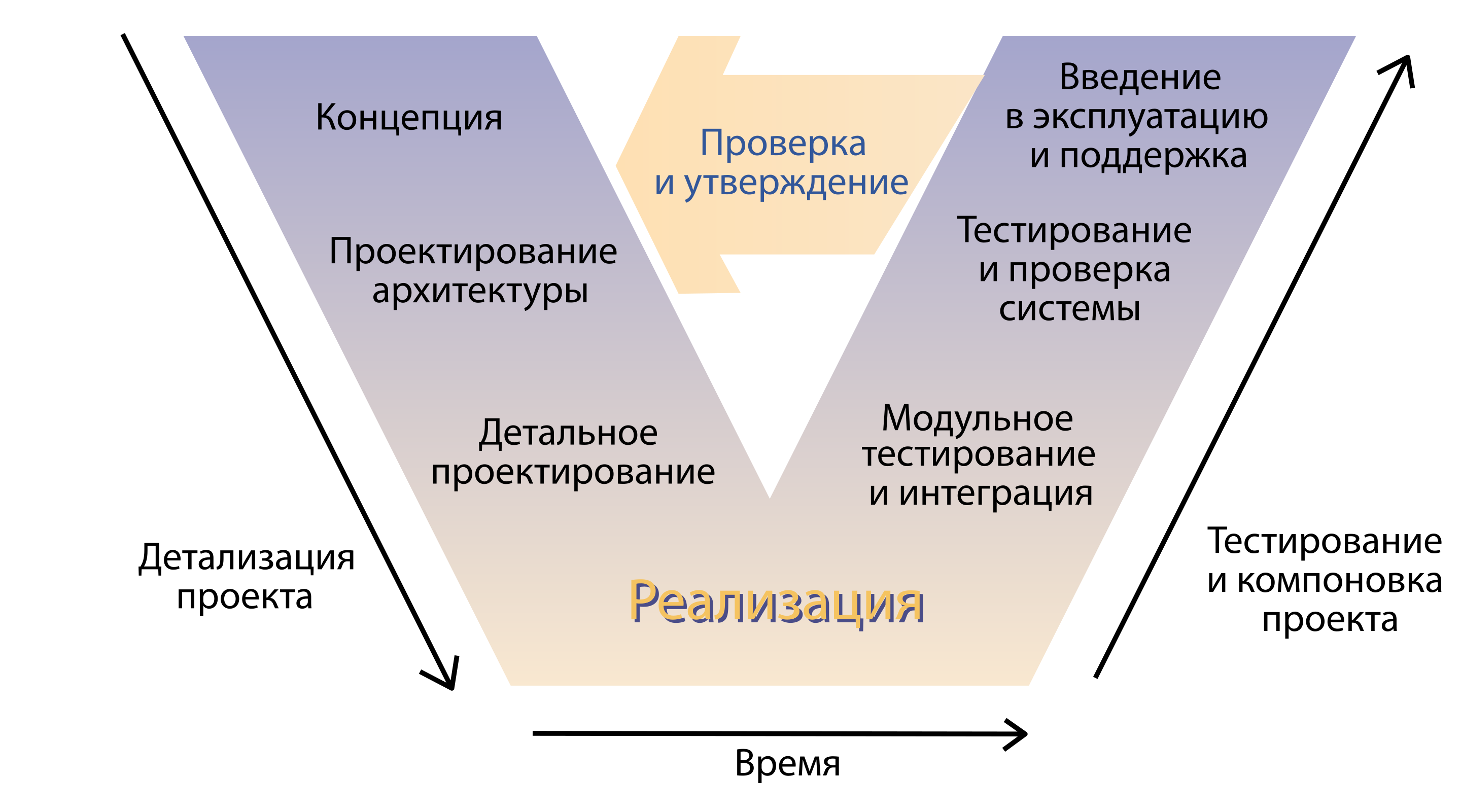
Alors que voyons-nous? L'entreprise vient avec un concept, les architectes conçoivent des solutions, les développeurs écrivent du code, puis l'échec. Quelqu'un teste le produit d'une manière ou d'une autre, quelqu'un le livre à l'utilisateur final d'une manière ou d'une autre et quelque part à la sortie de ce modèle miracle, il y a un client solitaire qui attend le temps promis par la mer. Nous sommes arrivés à la conclusion que nous avons besoin de méthodes qui permettront d’établir ce processus. Et ils ont décidé de créer des pratiques qui les mettraient en œuvre.
Digression lyrique sur ce qu'est la pratique
Par pratique, je veux dire un tas de technologie et de discipline. Un exemple est la pratique de décrire l'infrastructure avec du code terraform. La discipline consiste à décrire l'infrastructure avec du code, c'est à la tête du développeur, et la technologie se terraforme elle-même.
Et ils ont décidé de les appeler des pratiques DevOps - je pense que cela signifiait du développement aux opérations. Nous avons trouvé différentes choses délicates - des pratiques CI / CD, des pratiques basées sur le principe IaC, des milliers d'entre elles. Et tout a commencé, les développeurs écrivent le code, les ingénieurs de DevOps transforment la description du système sous forme de code en systèmes de travail (oui, le code n'est malheureusement qu'une description, mais pas le mode de réalisation du système), la livraison tourne, et ainsi de suite. Les administrateurs d'hier, après avoir maîtrisé de nouvelles pratiques, se sont fièrement recyclés en tant qu'ingénieurs DevOps, et tout a commencé. Et il y avait un soir, et il y avait un matin ... désolé, pas à partir de là.
Tout n'est pas encore merci à Dieu
Dès que tout s'est calmé, et que divers "méthodologistes" rusés ont commencé à écrire des livres épais sur les pratiques DevOps, les conflits ont éclaté tranquillement, qui est un ingénieur DevOps si notoire et que DevOps est une culture de production, le mécontentement a de nouveau mûri. Du coup, la livraison de logiciels était une tâche absolument non triviale. Chaque infrastructure de développement a sa propre pile, vous devez la collecter quelque part, vous devez déployer l'environnement quelque part, ici vous avez besoin de Tomcat, vous avez toujours besoin d'un moyen délicat pour le démarrer - en général, la tête se fissure. Et le problème, curieusement, s'est avéré être principalement dans l'organisation des processus - cette fonction de livraison, comme un goulot d'étranglement, a commencé à bloquer les processus. De plus, l'opération (Opérations) n'a pas été annulée. Il n'est pas visible dans le modèle en V, et il y a tout le cycle de vie à droite. En conséquence, il est nécessaire de prendre en charge l'infrastructure d'une manière ou d'une autre, d'examiner la surveillance, de résoudre les incidents et même de gérer la livraison. C'est-à-dire de s'asseoir avec un pied à la fois dans le développement et dans l'exploitation - et tout à coup, ce développement et opérations s'est avéré. Et puis il y avait un battage médiatique massif pour les microservices. Et avec eux, le développement à partir des machines locales a commencé à migrer vers le cloud - essayez de déboguer quelque chose localement, s'il y a des dizaines et des centaines de microservices, la livraison constante devient ici un moyen de survie. Pour la «petite entreprise modeste», c'était toujours n'importe où, mais quand même? Et Google?
Google SRE
Google est venu, a mangé les plus grands cactus et a décidé - nous n'en avons pas besoin, nous avons besoin de fiabilité. Et la fiabilité doit être gérée. Et j'ai décidé - nous avons besoin de spécialistes qui géreront la fiabilité. Il les a appelés des ingénieurs SR et a dit, vous voilà, faites comme d'habitude, eh bien. Ici vous avez SLI, ici vous avez SLO, ici vous avez la surveillance. Et a mis son nez dans les opérations. Et appelé son "DevOps fiable" SRE. Tout semble aller bien, mais il y a un sale hack que Google pourrait se permettre - d'embaucher des personnes qui avaient des compétences de développeur et un
peu plus de couture à la maison, qui connaissaient le fonctionnement des systèmes de travail, en tant qu'ingénieurs SR. De plus, embaucher de telles personnes et Google lui-même a des problèmes - principalement parce qu'ici il est en concurrence avec lui-même - il est nécessaire de décrire la logique métier à quelqu'un. La livraison a été suspendue par les ingénieurs de la version, les ingénieurs SR - gèrent la fiabilité (bien sûr, pas directement, mais en influençant l'infrastructure, en changeant l'architecture, en suivant les changements et les indicateurs, en traitant les incidents). Bien, vous pouvez
écrire des livres . Mais que se passe-t-il si vous n'êtes pas Google, mais la fiabilité inquiète quand même?
Développer des idées DevOps
C'était juste à temps pour Docker, qui a grandi de lxc, puis de divers systèmes d'orchestration tels que Docker Swarm et Kubernetes, et les ingénieurs de DevOps ont exhalé - l'unification des pratiques a simplifié la livraison. Simplifié à tel point qu'il est même devenu possible de fournir la livraison aux développeurs - ce déploiement.yaml est là. La conteneurisation résout le problème. Et la maturité des systèmes CI / CD est déjà écrite au niveau d'un fichier et tout a commencé - les développeurs le feront eux-mêmes. Et puis nous commençons à discuter de la façon dont nous pouvons faire notre SRE, avec ... oui, au moins avec quelqu'un.
SRE pas sur Google
Eh bien, ok, nous avons livré la livraison, nous pouvons sembler expirer, revenir au bon vieux temps, lorsque les administrateurs ont regardé la charge du processeur, réglé les systèmes et siroté tranquillement quelque chose d'incompréhensible des tasses dans la paix et la tranquillité ... Arrêtez. Nous n'avons rien fait pour cela (désolé!). Il s'avère soudainement que dans l'approche de Google, nous pouvons adopter d'excellentes pratiques - ce n'est pas la charge du processeur qui importe, et non la fréquence à laquelle nous changeons de lecteur là-bas ou dans le cloud, nous optimisons le coût, et les mesures commerciales sont les mêmes SLx notoires. Et personne ne leur a enlevé la gestion des infrastructures, et il faut résoudre les incidents, et être de service au poste périodiquement, et en général pour faire l'objet de processus métiers. Et les gars, commencez déjà à programmer un peu à un bon niveau, Google vous attend.
En résumé. Du coup, mais vous êtes déjà fatigué de lire et vous avez hâte de
cracher écrire à l'auteur dans le commentaire de l'article. DevOps en tant que pratique de livraison, a été et sera. Et ça ne va nulle part. SRE en tant qu'ensemble de pratiques opérationnelles rend cette livraison réussie.