Zabbix est un système de surveillance ouvert populaire utilisé par un grand nombre d'entreprises. Je vais parler de l'expérience de création d'un cluster de surveillance.
Dans le rapport, je mentionnerai brièvement les modifications apportées précédemment (correctifs), qui élargissent considérablement les capacités du système et préparent la base du cluster (téléchargement de l'historique vers «Clickhouse», interrogation asynchrone). Et j'examinerai en détail les problèmes qui se sont posés lors du clustering du système - résolution des conflits d'identité dans la base de données, un peu sur le théorème CAP et la surveillance avec des bases de données distribuées, sur les nuances du fonctionnement de Zabbix en mode cluster: sauvegarde et coordination des serveurs et des proxys, sur les "domaines de surveillance" et un nouveau look sur l'architecture du système.
Je vais parler brièvement de la façon de démarrer un cluster à la maison, où trouver les sources et quelles sources supplémentaires. des paramètres seront requis pour le cluster.

HighLoad ++ Siberia 2019. Salle Tomsk. 24 juin, 17 h Résumés et
présentation . La prochaine conférence HighLoad ++ se tiendra les 6 et 7 avril 2020 à Saint-Pétersbourg. Détails et billets
ici .
Mikhaili Makurov (ci-après - MM): - Je travaille pour une entreprise prestataire. Le fournisseur s'appelle Intersvyaz, il travaille dans la ville de Tcheliabinsk. Nous avons environ 1,5 million de personnes. Et pour que le fournisseur fonctionne, il existe une énorme infrastructure. Nous avons environ 70 000 équipements: commutateurs, dispositifs IoT ... - beaucoup de tout ce qui doit être surveillé. Plus précisément, ce rapport traite de l'utilisation de Zabbix, de la création d'un cluster basé sur Zabbix pour la surveillance de l'infrastructure.
J'ai 12 ans chez le prestataire. Maintenant, je ne fais plus du tout de technique, c'est plutôt de gérer les gens. Et ce (truc technique) est en fait mon hobby. Je développerai un peu ce sujet.
Problèmes de surveillance
Je pense que j'ai de la chance. Il y a environ un an et demi, je me suis retrouvé dans un projet qui ressemblait à ceci: "Nous devons résoudre certains problèmes avec notre surveillance." J'ai hérité d'une zone de responsabilité (monitoring), qui se composait d'un tas de serveurs, notamment de 21 serveurs:

Il y avait 4 serveurs puissants et 15 procurations - tout était matériel. Il y a eu quelques plaintes concernant cette surveillance. La première, c'est que c'était beaucoup. Nous n'avons pas un seul serveur avec le fournisseur a pris autant d'espace. C'est de l'argent, de l'électricité ... En fait, ce n'est pas un gros problème.

Le gros problème était que la surveillance ne correspondait pas à ce que nous attendions de lui. Pour ceux qui n'ont pas activement utilisé Zabbix, voici un tableau de bord qui montre le retard sur les contrôles:

La plupart de nos chèques étaient dans la zone rouge. Ils ont couru plus de 10 minutes plus lentement que nous le voulions, c'est-à-dire qu'ils avaient 10 minutes de retard. Ce n'était pas très agréable, mais il était encore possible de vivre plus ou moins. Le plus gros problème était le suivant:

C'était un système de surveillance d'un réseau fonctionnel. Lorsque les travaux prévus ont été réalisés, un segment de milliers de personnes est tombé sur cinq commutateurs. Avec ces commutateurs, le commutateur et la surveillance sont tombés dans l'oubli. Lorsque tout a été restauré, deux heures plus tard et la surveillance a été rétablie. C'était douloureusement désagréable, et cette phrase devrait figurer dans chaque rapport:

"Nous devons faire quelque chose avec ce projet!"
Et ici, je vais raconter deux histoires. Ensuite, nous avons essayé d'aller simultanément de deux manières. Nous avons un groupe d'intégration - il a choisi la façon de construire un système modulaire (il y avait un rapport très cool d'Avito à Highload en novembre de l'année dernière à Moscou - ils en ont parlé):

Zabbix = personnes + API + efficacité
Les gars de petites pièces ont commencé à construire un système. Et avec plusieurs passionnés, j'ai continué à travailler sur Zabbix. Il y avait des raisons à cela. Quelles en sont les raisons?
- Tout d'abord, il existe une API sympa. Et lorsque vous disposez de 60 à 70 000 éléments de surveillance, il est clair que tout cela ne fonctionne que automatiquement - vous ne pouvez pas ajouter autant de mains sans erreurs.
- Personnel. Il y a des quarts de surveillance en service qui se tiennent 24/7. Ce ne sont pas des informaticiens, ce sont des gens de service. Nous avons montré au «Grafan» quelques autres systèmes - c'est difficile pour eux. Il y a des administrateurs habitués à la diversité, à la commodité de la surveillance dans le Zabbix lui-même: modèles, détection automatique - et tout cela est cool!
- Zabbix peut être efficace.
La base de données SQL ralentit-elle? Une réponse - Clickhouse
La première raison était évidente. Nous avons ensuite travaillé sur MySQL, et nous avons rencontré environ 6 à 7 000 métriques par seconde, nous avons constaté des retards constants sur les disques.

Aujourd'hui, il a déjà sonné 100 fois: la seule réponse est Clickhouse:
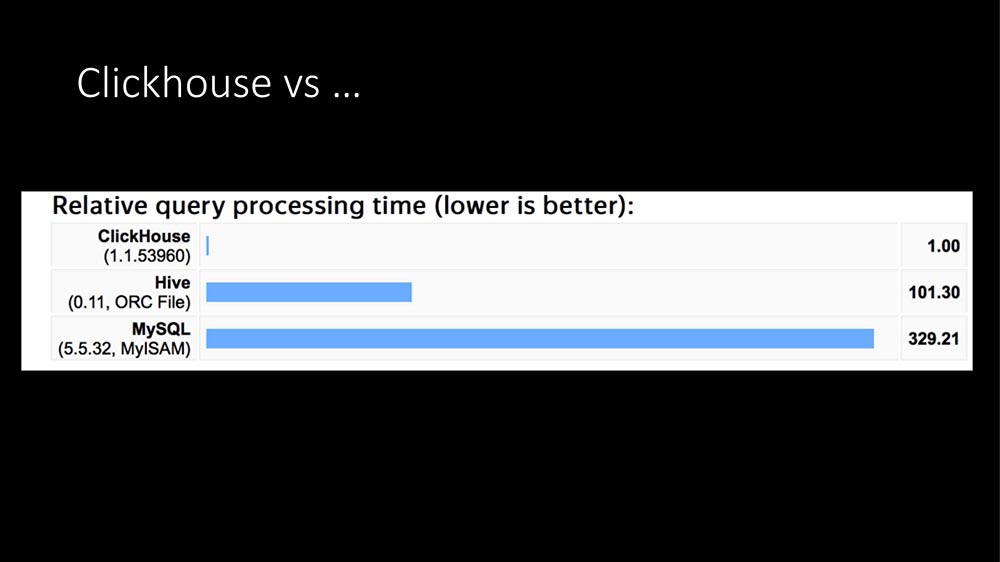
Dans la structure des requêtes, la majeure partie des requêtes (notre profilage en quelques heures) sont des enregistrements de métriques. L'écriture de métriques dans une base de données SQL coûte extrêmement cher. Ici TimeScaleDB est apparu ... Ensuite, nous avons eu un «Clickhouse» en fonctionnement pendant environ un an pour d'autres tâches (nous faisons du big data, nous avons une grosse application - en général, un fournisseur est maintenant une entreprise informatique entière).
Après avoir regardé de beaux graphiques sur Internet (que le «Clickhouse» est des centaines de fois plus rapide, qu'il a besoin de très peu d'espace) et ayant une expérience actuelle, nous avons écrit notre module HistoryStorage pour «Zabbix» afin qu'il puisse enregistrer directement les données «Clickhouse» (c'est-à-dire, pas à partir de l'exportation de fichiers, mais directement à la volée).

De plus, nous avons écrit un module pour le «front». Tous ces beaux graphiques dans le panneau d'administration Zabbix peuvent être créés à partir de Clickhouse. Il est clair que l'API fonctionne également.
L'effet est à peu près le même - le serveur SQL en tant qu'entité dédiée n'est pas devenu complètement, c'est-à-dire que la charge est tombée à zéro. Ce qui est le plus remarquable, nous avions déjà un cluster «Clickhouse» dédié: lorsque nous y avons consacré toute notre charge, il est passé de 6 à 10 000 métriques. Les gars qui administrent ont dit: "Mais nous ne voyons pas quelque chose qui est arrivé. Non! "
Comment nous avons élargi Clickhouse
Je dirai encore plus: pour les tests, nous avons essayé de charger jusqu'à 140-150 mille métriques par seconde (nous ne pouvions plus presser depuis Zabbix, plus tard je dirai pourquoi), et le Clickhouse ne voit pas non plus cette charge. Autrement dit, il est très confortable, charge fraîche. En général, il existe un tel module.
De plus, nous l'avons un peu élargi:

Dans notre version, vous pouvez désactiver les nanosecondes. Vous savez probablement: Zabbix écrit des secondes et des nanosecondes dans deux champs. Dans les champs «Clickhouse» dans lesquels la variabilité est très importante, occupez beaucoup d'espace.
Au fait, à propos de l'endroit. Une métrique dans Clickhouse (nous avons maintenant environ 700 milliards de métriques enregistrées) prend 2,9 octets. Selon la documentation de Zabbix, une métrique dans les bases de données SQL prend de 40 à 100 octets. La désactivation des nanosecondes permet d'économiser 40% supplémentaires, soit environ 1,5 octet par métrique. Autrement dit, "Clickhouse" est très efficace en termes de localisation.
À la demande de nos gars qui sont engagés dans l'apprentissage automatique, nous avons fait une option pour que nous puissions écrire l'hôte et le nom de la métrique. Étant donné que la variabilité des données est importante, cela ne prend pas beaucoup de place supplémentaire, malgré le fait que les données textuelles peuvent être importantes (elles n'ont pas encore été vérifiées avec de longs tests).
De plus, nous avons fait deux ajouts, car nous avons développé Zabbix et avons souvent dû le retirer. Un ajout très cool: au début, puisque "Clickhouse" vous permet de lire des millions d'enregistrements, nous pouvons remplir le cache historique. Au début, nous sommes retardés de 30 à 40 secondes supplémentaires, mais nous obtenons un service immédiatement lancé avec un cache chauffé.
Dans les cas où il est plus facile de collecter à partir de l'infrastructure, il existe toujours une telle option: interdire la lecture du cache pendant un certain temps. Il vaut mieux travailler rapidement pendant 5 minutes, sans compter les déclencheurs, puis le cache se remplira - si vous ne le faites pas, la stagnation des plombs d’histoire commence.
En général, il existe un module «Clickhouse». Il peut être utilisé.
Efficacité d'interrogation
Malgré le fait que nous ayons ensuite résolu les problèmes avec la base, les freins et le problème avec quinze mandataires restaient. Ils étaient liés à cela:

Il s'agit du principal pipeline de traitement de données chez Zabbix. Il y a une étape de collecte de données, il y a un prétraitement et il y a des synchroniseurs historiques qui font tout le travail (calcul des déclencheurs, alertes, sauvegarde de l'historique). Le goulot d'étranglement du cache s'est avéré être:

Pourquoi le vote est-il lent? Parce que les threads qui effectuent les requêtes vont dans la file d'attente dans la configuration du cache pour les mesures d'unité et la bloquent. Il y a d'autres endroits, mais ils ne sont pas si étroits. Par exemple, il y a un prétraitement lui-même et il y a un cache d'historique. Sur notre SQL, nous avons obtenu les restrictions suivantes:

Cela est peut-être dû au fait que dans notre cas, la base est d'environ 5 millions de mesures, que nous supprimons. Avec toutes les optimisations que nous avons faites, nous avons pu obtenir 70 000 mesures dans le goulot d'étranglement (sur le cache de configuration), mais uniquement dans le cas où nous les avons traitées en masse.
Qu'est-ce que le traitement en vrac? Poller va au cache de configuration et prend la tâche non pas pour une métrique, mais pour 4 ou 8 000. En même temps, il a une autre merveilleuse opportunité: il peut désormais effectuer des sondages de manière asynchrone, car il a obtenu 4 000 métriques ... Pourquoi font-ils l'un après l'autre? Vous pouvez tout demander immédiatement!
L'interrogation asynchrone est plus efficace que le proxy!
Pour les principaux types utilisés par le fournisseur - ce sont SNMP et AGENT, nous avons réécrit l'interrogation en mode asynchrone, et agrégé cela a donné une augmentation de la vitesse de 100 à 200 fois. Nous avions 15 procurations, nous les avons divisées en 150 - elles étaient complètement parties. En conséquence, tout cela s'est transformé en deux banques, qui ne sont nécessaires que pour la réserve:

Banque Uniprocesseur (un Xeon 1280 coûte). Voici mon temps:

Environ 60% est gratuit, mais cette sonnerie de 60% à 40% exécute des scripts périodiques sur la machine elle-même (scripts externes). Ils peuvent être optimisés jusqu'à la création de problèmes.
L'échelle est quelque chose comme ceci:

Ce sont 62 000 hôtes, environ 5 millions de métriques. Notre besoin actuel est d'environ 20 000 mesures par seconde.
Eh bien, comme tout? Nous avons résolu les problèmes de performances, l'historique étendu, le sondage est génial. Le problème est-il résolu? Pas vraiment ... Tout serait trop simple.
J'ai joué un tour sur le tableau précédent (pas tous montré):

Il y a deux problèmes. Je veux dire: "Fous, routes." Il y a un facteur humain, il y a du matériel.
Un serveur ne suffit toujours pas. En environ un an de fonctionnement, il y a eu deux cas de problèmes matériels - un lecteur SSD et autre chose. La plupart des problèmes sont le facteur humain lorsque les gens font des tests. Dans notre entreprise, Zabbix est utilisé comme un service: tous les départements peuvent y écrire quelque chose qui leur est propre.
J'aimerais élargir. Je voudrais ne pas dépendre d'une seule boîte. Je voulais que nous soyons encore plus forts. Et je voudrais évoluer selon le principe de mise à l'échelle. Il n'y a même rien à discuter ici: croître, augmenter la capacité d'une boîte, n'a plus d'importance depuis 20 ans déjà.

Le cluster a demandé ...
Quelque part en décembre, la première version est apparue. Une unité de cluster atomique est ce qui est traité sur un hôte distinct. L'hôte a été sélectionné.

Le fait est que dans Zabbix, il existe des connexions assez fortes entre les éléments qui peuvent être sur le même hôte, c'est-à-dire que les déclencheurs peuvent être connectés, ils peuvent être traités ensemble en prétraitement. Mais entre les hôtes, la connectivité n'est pas si élevée, il est donc normal d'utiliser ce cluster entre les nœuds du cluster - il y aura beaucoup de trafic là-bas. La tâche principale des clusters est de convenir entre eux qui est engagé dans quels hôtes.
Je voudrais contourner notre limite maximale de 60 à 70 000 métriques, car l'appétit vient avec l'alimentation. Nous avons des gars qui sont engagés dans la QoE ... Qualité de l'expérience - une analyse du fonctionnement d'Internet pour les abonnés basée sur les métriques de transit, c'est-à-dire que vous fournissez toutes les métriques TCP à 1,5 million de personnes, en les injectant dans la surveillance - il y a beaucoup de données.
Et je voulais de la fiabilité. Je le voulais si quelque chose se produisait ... L'officier de quart a appelé, a dit: "Nous avons des problèmes avec le serveur", l'a éteint, nous le découvrirons demain.
Premier cluster
La première version a été implémentée sur la base de etcd:

Etcd est un stockage de valeurs-clés distribué utilisé dans de nombreux projets progressifs (pour autant que je sache, dans Kubernetes). Tout était super. Etcd fournit des outils très intéressants - par exemple, il résout le problème du choix du serveur principal. Mais un tel problème ...
Nous avions un "Zabbix" classique à trois liens: "web" - la base - le serveur lui-même. Et nous y avons ajouté "Clickhouse", et maintenant nous avons ajouté etcd aussi. Les administrateurs ont commencé à se gratter derrière la tête: il y a trop de dépendances ici - ce ne sera probablement pas fiable. Dans le processus de développement, une autre chose est devenue claire: dans Zabbix lui-même, il existe déjà un moyen intégré de communication interserveur, il est juste utilisé entre le serveur et le proxy, le soi-disant processus d'interrogation du proxy:

C'est assez cool pour la communication interserveur avec des changements minimes. Cela a permis à etcd de ne pas utiliser (au moins temporairement), de simplifier considérablement le code, et surtout, de travailler sur du code qui a été vérifié (il semble que ce code ait 5 ou 7 ans).
Comment les serveurs sont-ils coordonnés dans un cluster?
La coordination se fait par type, comme le protocole IGP. Pour que les serveurs aient la priorité (je vais maintenant dire pourquoi c'est nécessaire) et pour éviter les conflits dans la base de données SQL lors de l'écriture des journaux, chaque serveur se voit attribuer un identifiant (jusqu'à présent manuellement) - c'est un nombre de 0 à 63 (63 - c'est juste une constante, peut-être plus):

Le serveur avec l'identifiant maximum devient le "maître". Lorsque nous avons lancé nos premiers clusters de tests, la première chose que nos administrateurs ont dit était: «Wow! Et mettons-les sur différents sites. Eh bien, génial! »(Nous y reviendrons). Et lorsque quelqu'un aura distribué des clusters, il sera possible de contrôler la redistribution de la topologie: où ira le rôle du «maître» en cas de chute du serveur principal «Zabbix»:

Dans ce cas, comme ceci:

Stepping
Dans le Zabbix d'origine, cela se fait comme ceci: le serveur lui-même est responsable de la génération des index d'incrémentation automatique. Pour empêcher de nombreuses instances de marcher sur les talons les uns des autres (afin de ne pas créer de journaux avec les mêmes index), le pas est utilisé: «Zabbix» avec l'identifiant «1» générera des multiples de un - 1, 11, 21; avec l'identifiant "7" - 7, 17, 27 (avec des nuances).
Nous avons conduit avec des modificateurs.

Comment les serveurs interagissent-ils entre eux?
Il s'agit de l'héritage des paquets Hello IGP toutes les 5 secondes. Les serveurs savent donc qu'ils ont des voisins. Le «maître» sait donc qu'il y a des voisins à proximité, et sur cette base, le «maître» décide quels hôtes peuvent être distribués sur quels serveurs.

En conséquence, il existe une configuration. Selon l'ancienne mémoire, je l'appelle topologie. Une topologie est essentiellement une liste de serveurs et d'hôtes qui leur appartiennent.
Le protocole est simple - c'est JSON:

C'est également l'héritage du proxy Zabbix et de la communication du serveur Zabbix. En général, cela n'a aucun sens d'utiliser autre chose. La seule chose est que dans le cas de Zabbix il y a 4 octets (ZBXD), mais ce n'est pas le point.
Dans le paquet hello, l'identifiant du serveur est transmis: lorsque le serveur envoie le paquet, il indique son identifiant et sa version de la topologie - de cette façon, les serveurs découvrent rapidement qu'il existe une nouvelle version de la topologie et sont mis à jour très rapidement.
En fait, la topologie elle-même n'est qu'une arborescence, une liste de serveurs. Pour chaque serveur, une liste d'hôtes qu'il prend en charge:

Et puis un problème intéressant se pose.
Il y a une telle phrase magique - surveiller les domaines
À quoi ça sert? Dans le Zabbix classique, tout était simple - une attitude sans ambiguïté: cet hôte est surveillé par ce proxy, ce proxy donne des données au serveur. Si le proxy n'a pas été installé (ou n'est pas nécessaire), ce serveur surveille tous les hôtes:

Quand nous avons beaucoup de serveurs, que faire? De plus, il peut y avoir un problème avec le fait que nous avons des serveurs géographiquement distribués, et le serveur dans un bureau qui fonctionne lentement à Kemerovo commencera à essayer de surveiller toute l'infrastructure de Novossibirsk.

Nous n'en voulons pas. Nous voulons avoir une sorte de mécanisme pour que tous les serveurs, mais ceux que nous avons sélectionnés (éventuellement en fonction de la géographie) puissent surveiller un hôte particulier. En même temps, nous voulons gérer cela et nous voulons que ce soit simple. Pour cela, l'idée de surveiller les domaines a été inventée. En fait, ce sont de simples groupes - simplement, il y a déjà des groupes dans le dossier.
Et quand j'ai fait cela, les gars de l'opération m'ont parlé - ils ont dit: «Les groupes nous confondent beaucoup. Nous commençons toujours à penser à des groupes normaux. » Par conséquent, ce nom: domaines de surveillance.
Les hôtes se rapportent sans ambiguïté: un hôte - un domaine:

Le domaine hôte peut inclure n'importe quel nombre de serveurs. Les serveurs peuvent être dans n'importe quel nombre de domaines. C'est une chose très flexible. Afin d'étendre la flexibilité et de briser complètement le cerveau, il existe également un domaine par défaut:

Les serveurs qui sont membres du domaine par défaut sont surveillés par tous les hôtes qui n'ont pas de serveurs actifs ou qui n'ont pas de domaine de surveillance.
Cela nous permet simplement de lier topologiquement les hôtes à certains serveurs et de contrôler la façon dont les hôtes sont distribués en cas de panne d'un serveur:

Le prochain problème que nous avons rencontré ...
Cluster: Penser différemment
Quand nous avons beaucoup de serveurs, il y a de nouvelles opportunités pour construire un cluster, pour construire une topologie. C'est un tel classique lorsque nous avons une sorte de site central et qu'il y en a à distance; ou, disons, un proxy où la charge est déléguée:

Dans le cas du cluster Zabbix, il peut être implémenté de deux manières. Vous pouvez suivre la voie classique: il suffit de doubler l'infrastructure. Au centre, nous avons deux serveurs qui forment un cluster, peuvent réorganiser les hôtes ou assumer la charge si le voisin tombe. En conséquence, vous pouvez lever des procurations supplémentaires sur les mêmes serveurs - nous obtenons une double réserve:

Vous pouvez utiliser les nouvelles "fonctionnalités" et faire ceci:

L'essentiel n'est pas d'aller dans une situation où un serveur géographiquement distant surveille une grande infrastructure à un autre endroit. Il s'agit davantage d'un problème d'administration (je l'appelle entreprise) car il s'agit d'un problème de configuration.
Cluster: split brain et point de vue
, :
- split brain;
- point of view ( ).
. Split brain – , . , - – ? , , ( ).
point of view : , , , . . , RTT , .
:

, . , , . , – . , , , .
SQL-
, , , . . , , … . .
-, , , - – . , Galera MySQL.
PostgreSQL. «» : , , – . «», , .
?
, :


– . :
- - (Logs), . problems, events events recovery. , – , .
- 15 (State). – ( – – «» ). . , ; – …
- - (Configuration update).
«. «», SQL-:

-, :

. -, , … – , 2 ! : « , ». - , , .
. , :

, . SQL- . , SQL-. ( - ), «» ( ). …
. L'installation
, , «» . . , ?

«»- (. . «» daemon). ( ): ( 1 63, «») ( , ).
ServerIP IP-. , , IP- . - , proxy poller, trapper hello-, proxy poller .
. , , « »:

:

, default. . – , IP-, , ( ). «» – default.
-, .
- .
- , : « , ». .
- - , .
- , hello-time, : « »; .
- .
, , , . 30-40 . , , , .
, . - : « , !» -!

– : - , - , , GitLab, CI/CD, . , , – .
, , – 4.0.9 (4.2 ). Roadmap – -. -, «»; , RPM'.

( ) «» «»-. . , . – : , - … ? !.. «», .
SQL- , , . History Storage.
Les références
5 . .
-, , , , . . -.

, ? ! , , , . - - , . , , . , :

. «»- , .
- , , , .
- «» : , Configuration Cache, .
- , , . , , .
- - , . , , . 200 , – .
Remarque: le proxy passif n'est pas encore pris en charge!J'ai supprimé le code. Cela est dû au fait qu'il est difficile pour les gens de créer un autre mécanisme, quel serveur sera toujours responsable de ce proxy.Les proxys actifs eux-mêmes vont aux serveurs. Il existe une option Serveur pour cela (proxy standard). Le proxy modifié a l'option Serveurs: Et que fait un tel serveur modifié? Il conserve une connexion KPI avec tous les serveurs qui lui sont spécifiés; demande la configuration, envoie les données au premier serveur disponible de la liste. Cela résout le problème. Supposons que si un proxy est configuré sur le serveur Zabbix et que le serveur Zabbix est tombé, il y en a un autre dans le cluster afin de ne pas rester sans proxy; alors le proxy se connecte à un autre.
Et que fait un tel serveur modifié? Il conserve une connexion KPI avec tous les serveurs qui lui sont spécifiés; demande la configuration, envoie les données au premier serveur disponible de la liste. Cela résout le problème. Supposons que si un proxy est configuré sur le serveur Zabbix et que le serveur Zabbix est tombé, il y en a un autre dans le cluster afin de ne pas rester sans proxy; alors le proxy se connecte à un autre.Des questions
Question du public (ci-après - A): - Je voudrais clarifier comment les choses se passent entre les serveurs? Avec quel protocole communiquent-ils? Y a-t-il une sorte de sécurité? Parce que ce n’est pas très «sécurisé» pour amener la communication entre les serveurs sur Internet… Comment ça se passe?
MM: - Je pense que c'est un candidat à la meilleure question - au point! En fait, lorsque nous sommes passés à la communication standard, les serveurs de leur communication interserveur ont hérité de tous les jetons de protocole de communication qui existent entre le serveur et le proxy. Je vais préciser: il y a chiffrement, compression des données. S'il vous plaît - de la même manière, tout est configuré via le Web, car il est configuré de manière standard pour le serveur et le proxy; tout fonctionnera.
R: - Comment Hauskiper fonctionne-t-il pour vous dans le cas de Clickhouse?
MM: - Dans le «Zabbix» standard, il n'y a pas d'interface entre la «femme de ménage» et l'interface historique, c'est-à-dire que l'interface historique ne prend pas en charge la rotation des données (ElasticSearch, par exemple, ne prend pas en charge). Peut-être qu'en 4.2 c'est (je n'ai pas regardé), mais jusqu'à présent en 4.0.9.
Rendez-le facile! Le nouveau "Clickhouse" a une partition. Je voudrais le faire en désengageant les partitions obsolètes. Il est clair qu'il n'y aura pas de rotation au niveau des éléments individuels, mais il y a une astuce dans Zabbix: vous pouvez spécifier des valeurs globales (par exemple, stocker l'historique complet pendant pas plus de 90 jours) - vous pouvez effacer tous les éléments, l'historique complet de ces valeurs globales . Et ce sera fait! Il y a plus sur ce sujet sur Gitlab.
Nous aimerions faire le droit architectural: faut-il étendre l’interface d’histoire, de manière à ce que ce soit essentiellement ... En général, je ne veux pas laisser de dettes techniques, mais ce sera fait. Parce que c'est nécessaire, plus «Clickhouse» a commencé à supporter.
R: - Comment vous sentez-vous à ce sujet? Il s'avère que vous faites beaucoup de travail non-fournisseur.
MM: - Je ne l'ai probablement pas dit très correctement. C'est mon hobby! Je ne suis pas vraiment un spécialiste technique - je suis un manager. Dans mon temps libre, je pratique.
R: - Je pensais que vous faisiez cela dans le cadre de votre activité principale ...
MM: - Les affaires me donnent un endroit cool pour tester. En fait, je recommande fortement - cela soulage le cerveau. Quelque part sur la «chose» managériale, je dirais ceci - quand vous pouvez passer des problèmes humains à ceux-ci. Ils sont tellement cool résolus! Ce sont des problèmes techniques. Vous avez programmé, et cela fonctionne comme vous avez programmé! C'est dommage que les gens ne devraient pas faire ça.
R: - Ecrivez-vous à «Clickhouse» via un proxy ou directement?
MM: - Directement. En fait, l'interface historique modifiée, qui est utilisée pour "Elastix", est également héritée. L'url est utilisée, c'est-à-dire via l'interface http "Zabbiks" envoie "Clickhouse". Ce qui est cool, Zabbix agrège quand il y a un gros flux historique, des milliers de métriques dans un pack, et cela tombe très cool sur le Clickhouse.
R: - En fait, il écrit bachi pour lui?
MM: - Oui. Une requête SQL exécutée par l'URL contient généralement un millier de mesures. Admins "Clickhouse" tout simplement heureux.
Présentateur: - Ceci est la fin du programme dans cette salle. Il y a un programme du soir qui est organisé, et il y a quelque chose que vous seul pouvez faire. Et je suggère, pendant que vous communiquerez les uns avec les autres, de réfléchir aux choses intéressantes que vous pouvez ... Lorsque vous vous parlez de vos cas, c'est très probablement ce dont vous pouvez parler. En discutant les uns avec les autres, vous pouvez trouver juste pour trouver un aperçu - le comité du programme acceptera votre candidature, examinera et aidera à en faire une bonne histoire. Peut-être avez-vous une sorte d'histoire à propos de la collaboration avec le comité de programme?
MM: - En fait, beaucoup de commentaires sont donnés. J'ai eu tellement de chance: une personne du comité du programme habite à Chelyabinsk et Highload est la seule conférence qui travaille si étroitement avec les conférenciers. Je n'ai jamais rien vu de tel ailleurs. C'est très bénéfique! Différentes étapes: les gars regardent la vidéo, font des commentaires sur les diapositives - ça se passe beaucoup dans le sujet (orthographe, fautes d'écriture). Très cool! Je le recommande! Essayez-vous!
Un peu de publicité :)
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en recommandant à vos amis
des VPS basés sur le cloud pour les développeurs à partir de 4,99 $ , un
analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur les VPS (KVM) E5-2697 v3 (6 cœurs) 10 Go DDR4 480 Go SSD 1 Gbit / s à partir de 19 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher au centre de données Equinix Tier IV à Amsterdam? Nous avons seulement
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99 $! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?