Il y a longtemps, dans une galaxie solaire très lointaine, avant même de faire partie de l'univers de Rostelecom, un petit produit webProxy a fait naître le besoin non seulement de filtrer le trafic réseau, mais aussi de construire des statistiques sur celui-ci avec son stockage ultérieur. À cette époque, les bases de données de colonnes n'étaient pas aussi populaires qu'aujourd'hui. Le seul analogue approprié était la base de données HP Vertica payante. Comment, dans la galaxie solaire, ils ont résolu ce problème et à quoi ils sont finalement arrivés, nous dirons sous la coupe.

Nous avons d'abord décidé de créer notre propre base de données. En conséquence, il a été écrit en OCaml avec un stockage binaire des colonnes (les représentations de texte ont été compressées via lz4) et son propre langage de requête assez flexible sur les expressions S. Le partitionnement a été effectué par jour.
Exemple de demande:

Ce n'était pas l'option la plus pratique et la plus rapide, mais extensible et personnalisable.
Le temps a passé, tout comme la nécessité d'accélérer la construction des statistiques et des rapports de trafic. Par conséquent, nous avons commencé à envisager d'autres options:
- postgres purs;
- Postgres + cstore_fdw;
- Clickhouse;
- Élastique
Comparaison Postgres vs Elastic
Dans un premier temps, nous avons comparé Elastic et Postgres + cstore. Postgres a été considéré le plus attentivement, car il était déjà utilisé dans le système et l'expertise était disponible pour travailler avec lui.
L'élastique a également été activement utilisé dans l'entreprise. Malgré «l'attractivité» de la recherche en texte intégral et sa rapidité, Elastic a dû être abandonné en raison du volume trop important occupé par les données sur le disque. En termes de vitesse, Elastic a gagné environ 3 fois sur des requêtes simples, par exemple sur la requête "TOP 20 sites en une semaine". Et sur les plus complexes - jusqu'à 9 fois: "TOP 20 des sites pour le trafic par mois."
Cependant, c'était mieux que sa propre base, ce qui a pris quelques minutes pour le faire contre 5-6 secondes dans Elastic et 15-55 secondes dans Postgres.
Comparaison Postgres vs Clickhouse
Données source
Avec https://github.com/wizardjedi/clickhouse-test, nous avons pris des conteneurs avec Postgres et Clickhouse. Ces conteneurs ont été conçus pour créer des tables.
Vue de table pour Postgres:

La clé primaire a dû être supprimée, car la table étrangère dans Postgres ne le permet pas.
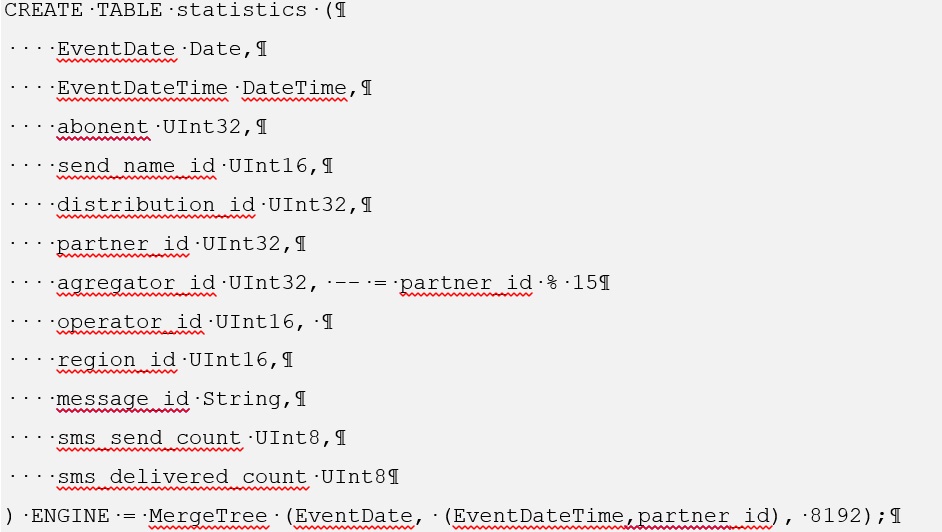
Pour Clickhouse, la création d'une telle table est la suivante:
Pour vous familiariser avec le processus d'installation de cstore pour Postgres, accédez à https://github.com/citusdata/cstore_fdw .
De plus, lors de l'installation de cstore, vous devez installer le package postgresql-server-dev-XY
Lors de la comparaison des performances, les tailles de données suivantes (en mégaoctets) ont été utilisées:

Les données source sont juste une requête SQL listant tous les tuples, c'est-à-dire données brutes.
Lors de l'exécution de requêtes, notamment lourdes, en plus des données, les dimensions de la base de données ont été mesurées.
Il a été révélé que pour Clickhouse, ils n'ont certainement pas augmenté.

Paramètres du système informatique
Fabricant: Intel
Ligne: core i5
Modèle: 8250U
Fréquence d'horloge: 1,60 GHz par cœur
Noyaux: 4
RAM: 16 Go
SSD: 256 Go
Chargement de données dans une base de données
Pour un tel volume de données dans Clickhouse, ils se sont chargés assez rapidement: 1 heure 40 minutes (c'est pour 600 millions de tuples).
Au début, nous avions prévu de tout télécharger dans un seul fichier, mais l'erreur «bad_alloc» s'est affichée. Apparemment, en raison de l'incapacité de Clickhouse d'allouer de la mémoire. Aucune solution n'a été trouvée. Par conséquent, 600 millions de tuples ont été répartis en 30 fichiers de 20 millions chacun. Dans ce cas, chaque fichier a été téléchargé un peu plus de 3 minutes.
Avec Postgres, les choses étaient plus compliquées, mais seulement au début. Le téléchargement de fichiers SQL bruts contenant la commande tuples INSERT INTO <nom_table> (attributs) VALUES prend du temps. Par conséquent, tout a été converti au format csv et la commande COPY <table_name> FROM WITH CSV a été exécutée.
Il convient de noter que nous avons d'abord chargé les données dans une table Postgres standard, d'où nous les avons copiées dans une table étrangère, qui est contrôlée par cstore. Par conséquent, le chargement de Postgres à partir d'un fichier csv a également pris un peu moins de deux heures.
Comparaison des performances
La comparaison des performances de Postgres et Clickhouse est présentée dans le tableau ci-dessous. Mais sans construire d'index ni modifier les paramètres de la base de données. À un moment donné, la mémoire sur le disque a presque épuisé, et il est donc devenu nécessaire de supprimer une table régulière non compressée de Postgres. Pour le moment, seules les tables sont disponibles dans Clickhouse et Postgres cstore.
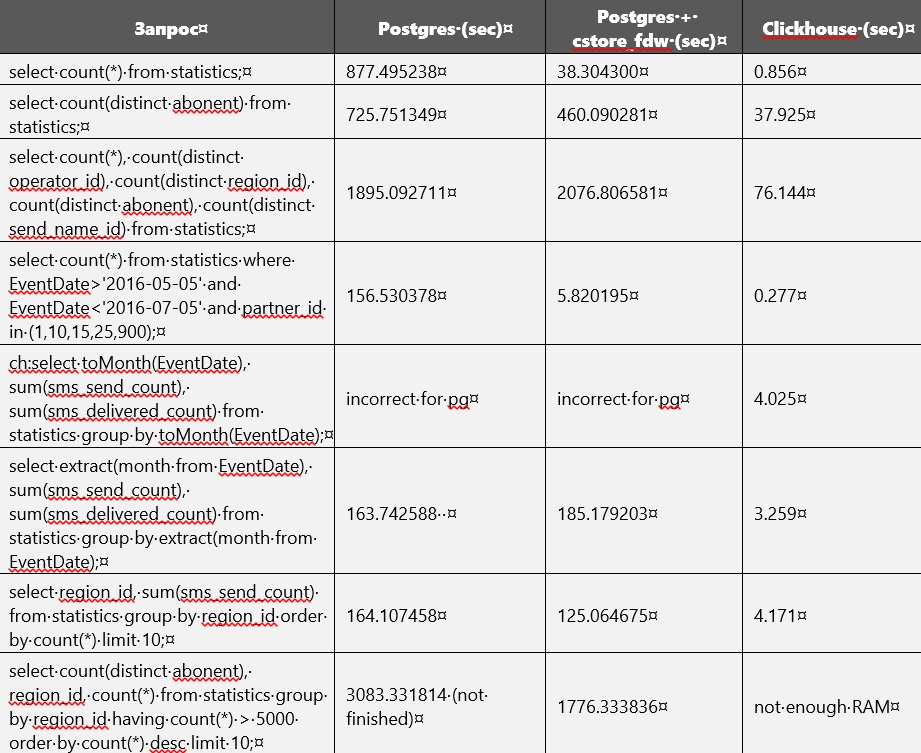
Apparemment, cstore se concentre sur le premier attribut spécifié lors de sa création. En d'autres termes, il trie toutes les données par elle. Cela peut être facilement remarqué, car les requêtes liées à EventDate étaient plus rapides à exécuter dans cstore que dans Postgres.
Lors de l'exécution de requêtes, Postgres prenait parfois jusqu'à 27 Go sur un disque externe pour les fichiers temporaires.
Clickhouse prend beaucoup de RAM.
Dans le fichier de configuration /etc/clickhouse/users.xml, <max_memory_usage> 12000000000 </max_memory_usage> et <max_bytes_before_external_sort> 1000000000 </max_btes_before_external_sort> ont été spécifiés.
Pour certaines requêtes, la RAM n'était pas suffisante, c'est pourquoi nous avons dû l'augmenter. Après cela, le traitement des demandes s'est poursuivi, mais à la dernière demande, il a encore été interrompu. Il y avait plusieurs autres paramètres disponibles pour limiter la mémoire consommée https://clickhouse.yandex/docs/ru/query_language/queries/ .
Il se trouve que nous avons ajouté un peu plus de données à Clickhouse: 695_640_000 tuples au lieu de 600_000_000, mais cela ne l'a pas empêché de gagner.
Sur cstore_fdw, vous pouvez configurer divers paramètres https://github.com/citusdata/cstore_fdw/issues/174 , https://github.com/citusdata/cstore_fdw , qui affectent les performances.
Partitionnement
Quant au partitionnement, il se trouve également dans Clickhouse https://github.com/yandex/ClickHouse/blob/master/docs/ru/table_engines/custom_partitioning_key.md , https://clickhouse.yandex/docs/ru/table_engines/custom_partitioning_key / , et en Postgres (versions 10 et 11). Un exemple de partitionnement dans clickhouse peut être trouvé à https://github.com/yandex/ClickHouse/blob/master/dbms/tests/queries/0_stateless/00502_custom_partitioning_local.sql et https://github.com/yandex/ClickHouse/issues/1513 .
L'utilisation du partitionnement dans Postgres est possible à condition que cstore ne fonctionne qu'avec des tables étrangères, car vous devez créer un serveur pour celui-ci et vous ne pouvez pas spécifier de serveur pour les tables normales. Une table étrangère ne peut pas être divisée en partitions; elle peut elle-même agir comme une partition. Par conséquent, il n'y a qu'une seule façon d'utiliser le partitionnement: créer une table parent régulière, vous pouvez y attacher des tables étrangères sous la forme de partitions, qui fonctionnent déjà sur cstore_fdw.
Chez Clickhouse, le partitionnement fonctionne dès le départ.
Conclusion
En conséquence, nous avons décidé d'utiliser Clickhouse, car il est intelligent: il est toujours au moins 10 fois plus rapide que les analogues. Sur les serveurs de mémoire, il y a généralement plus de 32 Go, 64 et 128, donc les requêtes sur des tables d'environ 50 Go fonctionneront correctement. Si la table est très grande, c'est-à-dire que le partitionnement ou le réglage fin des paramètres du clickhouse-server vous aidera.