
Récemment, j'ai lu un livre sur les mathématiques et la beauté des gens et j'ai réfléchi à ce qu'il y a dix ans, à l'idée de comprendre quelle beauté humaine était assez primitive. Le raisonnement sur le visage considéré comme beau du point de vue des mathématiques se résume au fait qu'il doit être symétrique. De plus, depuis la Renaissance, il y a eu des tentatives pour décrire de beaux visages en utilisant les relations entre les distances à certains points du visage et montrer, par exemple, que les beaux visages ont une sorte de relation proche du nombre d'or. Des idées similaires sur l'emplacement des points sont maintenant utilisées comme l'une des méthodes d'identification des visages (recherche de repères de visage). Cependant, l'expérience montre que si vous ne limitez pas l'ensemble des caractéristiques à la position de points spécifiques sur le visage, vous pouvez obtenir de meilleurs résultats dans un certain nombre de tâches,
notamment la détermination de l'âge, du sexe ou même de
l'orientation sexuelle . Il est déjà évident ici que la question de l'éthique de la publication des résultats de ces études peut être aiguë.
Le sujet de la beauté des gens et son évaluation peuvent également être controversés sur le plan éthique. Lors du développement de l'application, beaucoup de mes amis ont refusé d'utiliser leurs photos pour des tests, ou ne voulaient tout simplement pas connaître le résultat (c'est drôle que la plupart des filles aient refusé de connaître les résultats). En outre, l'objectif d'automatiser l'évaluation de la beauté peut soulever des questions philosophiques intéressantes. Dans quelle mesure le concept de beauté est-il déterminé par la culture? Quelle est la vérité «La beauté dans l'œil du spectateur»? Est-il possible de mettre en évidence des signes objectifs de beauté?
Pour répondre à ces questions, vous devez étudier les statistiques sur les évaluations de certaines personnes par d'autres. J'ai essayé de concevoir et de former un modèle de réseau neuronal qui évaluerait la beauté, ainsi que de l'exécuter sur un téléphone Android.
Partie 0. Pipeline
Afin de comprendre comment les prochaines étapes sont liées les unes aux autres, j'ai dessiné un schéma du projet:
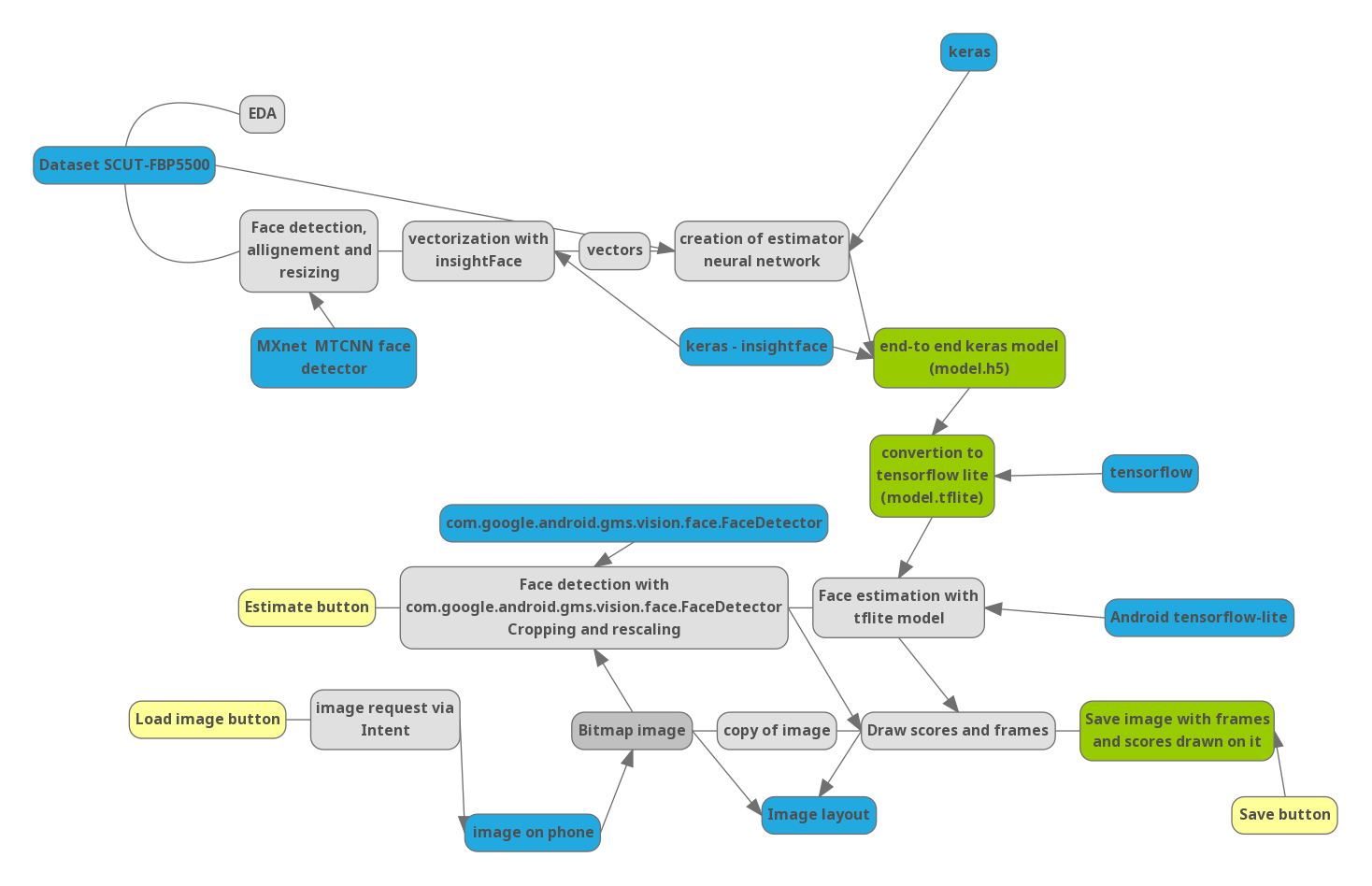
Bleu - bibliothèques importantes et données externes. Jaune - contrôle dans l'application.
Partie 1. Python
Étant donné que l'évaluation de la beauté est un sujet assez délicat, il n'y a pas beaucoup de jeux de données dans le domaine public contenant des photos avec une évaluation (je suis sûr que les services de rencontres en ligne comme l'amadou ont des ensembles de statistiques beaucoup plus importants). J'ai trouvé
une base de données compilée dans l'une des universités en Chine, contenant 5500 photographies, chacune évaluée par 7 évaluateurs parmi des étudiants chinois. Sur les 5 500 photographies, 2 000 sont des hommes asiatiques (MA), 2 000 sont des femmes asiatiques (FA), et 750 hommes Europioïdes (CM) et femmes (CF) chacun.
Lisons les données en utilisant le module Python pandas et jetons un coup d'œil rapide aux données. Distribution estimée pour différents genres et races:
import pandas as pd import matplotlib.pyplot as plt ratingDS=pd.read_excel('../input/faces-scut/scut-fbp5500_v2/SCUT-FBP5500_v2/All_Ratings.xlsx') Answer=ratingDS.groupby('Filename').mean()['Rating'] ratingDS['race']=ratingDS['Filename'].apply(lambda x:x[:2]) fig, ax = plt.subplots(2, 2, sharex='col') for i, race in enumerate(['CF','CM','AF','AM']): sbp=ax[i%2,i//2] ratingDS[ratingDS['race']==race].groupby('Filename')['Rating'].mean().hist(alpha=0.5, bins=20,label=race,grid=False,rwidth=0.9,ax=sbp) sbp.set_title(race)
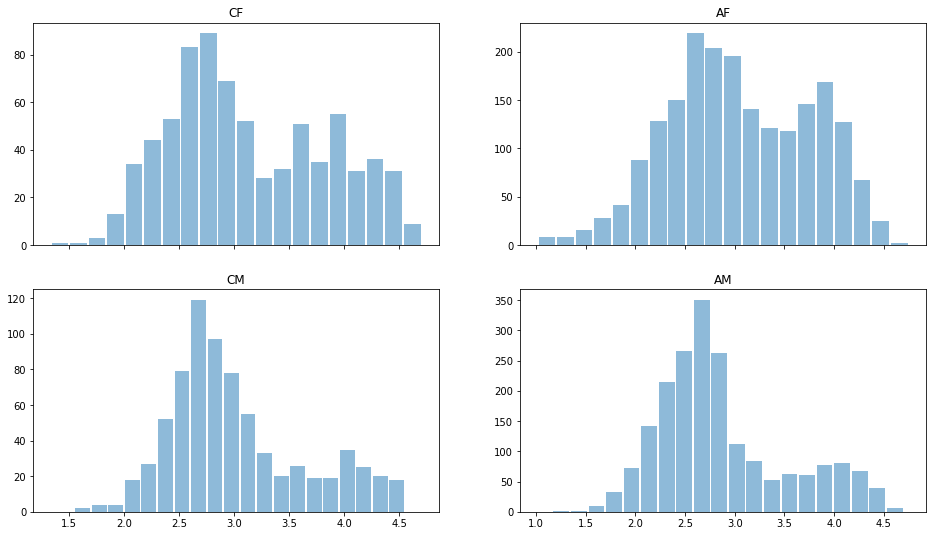
On peut voir qu'en général, les hommes sont considérés comme moins beaux que les femmes, la distribution est bimodale - il y en a. qui sont considérés comme beaux et "moyens". Il n'y a presque pas de notes basses, les données pourraient donc être renormalisées. Mais laissons-les pour l'instant.
Regardons l'écart type dans les estimations:
ratingDS.groupby('Filename')['Rating'].std().mean()
Il est de 0,64, ce qui signifie que la différence dans les évaluations des différents évaluateurs est inférieure à 1 point sur 5, ce qui indique l'unanimité dans les évaluations de la beauté. On peut raisonnablement dire que «la beauté n'est PAS dans l'œil du spectateur». Lors de la moyenne, vous pouvez utiliser les données de manière fiable pour former le modèle et ne pas vous soucier de l'impossibilité fondamentale de l'évaluation programmatique.
Cependant, malgré la faible valeur de l'écart type de l'estimation, l'opinion de certains évaluateurs peut être très différente de celle «ordinaire». Construisons la distribution de la différence entre l'estimation et la médiane:
R2=ratingDS.join(ratingDS.groupby('Filename')['Rating'].median(), on='Filename', how='inner',rsuffix =' median') R2['ratingdiff']=(R2['Rating median']-R2['Rating']).astype(int) print(set(R2['ratingdiff'])) R2['ratingdiff'].hist(label='difference of raings',bins=[-3.5,-2.5,-1.5,-0.5,0.5,1.5,2.5,3.5,4.5],grid=False,rwidth=0.5)
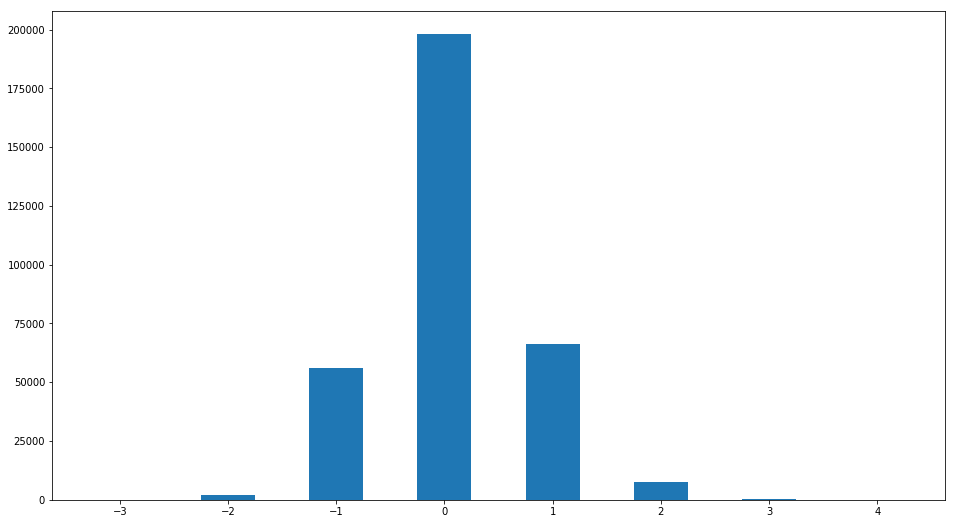
Un motif intéressant est trouvé. Personnes dont le score diffère de la médiane de plus d'un point
len(R2[R2['ratingdiff'].abs()>1])/len(R2)
0,02943333333333333332
Moins de 3%. Autrement dit, l'unanimité frappante est à nouveau confirmée en matière d'évaluation de la beauté.
Créer un tableau avec les notes moyennes nécessaires
Answer=ratingDS.groupby('Filename').mean()['Rating']
Notre base de données est petite; De plus, toutes les photos contiennent principalement des images faciales, et j'aimerais un résultat fiable pour n'importe quelle position du visage. Pour résoudre les problèmes avec une petite quantité de données, la technique d'apprentissage par transfert est souvent utilisée - l'utilisation de modèles pré-formés pour des tâches similaires et leur modification. Près de ma tâche est la tâche de reconnaissance faciale. Il est généralement résolu en trois étapes.
1. Il y a une détection de visage sur l'image et sa mise à l'échelle.
2. À l'aide d'un réseau neuronal convolutif, l'image du visage est convertie en un vecteur caractéristique, et les propriétés d'une telle transformation sont telles que la transformation est invariante par rapport à la rotation du visage, au changement de coiffure. manifestations d'émotions et toutes images temporaires. La formation d'un tel réseau est en soi une tâche intéressante qui peut être écrite pendant longtemps. De plus, de nouveaux développements apparaissent constamment pour améliorer cette conversion afin d'améliorer les algorithmes de suivi et d'identification de masse. Ils optimisent à la fois l'architecture du réseau et la méthode d'apprentissage (exemple perte triplet-perte de face-arcface).
3. Comparaison du vecteur d'entité avec ceux stockés dans la base de données.
Pour notre tâche, j'ai utilisé des solutions toutes faites de 1 à 2 points. La tâche de détection des visages est généralement résolue de nombreuses manières.En outre, presque tous les appareils mobiles disposent de détecteurs de visages (sur Android, ils font partie du package de services GooglePlay standard), qui sont utilisés pour se concentrer sur les visages lors de la photographie. Quant à la traduction des personnes sous forme vectorielle, il y a un point subtil non évident. Le fait est que les signes. extraites pour résoudre le problème de reconnaissance - sont caractéristiques d'une personne, mais elles peuvent ne pas du tout correspondre à la beauté. de plus. en raison des particularités des réseaux de neurones convolutifs, ces signes sont principalement locaux, et en général cela peut causer de nombreux problèmes (attaque à pixel unique). Néanmoins, j'ai trouvé que les résultats dépendent fortement de la dimension du vecteur, et si 128 signes ne suffisent pas pour déterminer la beauté, 512 suffisent. Sur cette base, un
réseau insightFace pré-formé basé sur Reset a été choisi. Nous utiliserons également les keras comme cadre d'apprentissage automatique.
Un code détaillé pour télécharger des modèles pré-formés peut être trouvé
ici. model=LResNet100E_IR()
Le détecteur de
visage mtcnn a été utilisé comme détecteur de visage pour le prétraitement
. detector = MtcnnDetector(model_folder=mtcnn_path, ctx=ctx, num_worker=1, accurate_landmark = True, threshold=det_threshold)
Alignez, recadrez et vectorisez les images de l'ensemble de données:
imgpath='../input/faces-scut/scut-fbp5500_v2/SCUT-FBP5500_v2/Images/'
Nous préparerons les données en les décomposant en vecteurs de formation (90% d’entre eux, nous les étudierons) et de validation (nous vérifierons le travail du modèle). Nous normalisons les données dans une plage de 0 à 1.
X=np.stack(facevecs)[:,0,:] Y=(Answer[:])/5 Indicies=np.arange(len(Answer)) X,Y,Indicies=sklearn.utils.shuffle(X,Y,Indicies) Xtrain=X[:int(len(facevecs)*0.9)] Ytrain=Y[:int(len(facevecs)*0.9)] Indtrain=Indicies[:int(len(facevecs)*0.9)] Xval=X[int(len(facevecs)*0.9):] Yval=Y[int(len(facevecs)*0.9):] Indval=Indicies[int(len(facevecs)*0.9):]
Passons maintenant au modèle. décrivant la beauté.
def Createheadmodel(): inp=keras.layers.Input((512,)) x=keras.layers.Dense(32,activation='elu')(inp) x=keras.layers.Dropout(0.1)(x) out=keras.layers.Dense(1,activation='hard_sigmoid',use_bias=False,kernel_initializer=keras.initializers.Ones())(x) model=keras.models.Model(input=inp,output=out) model.layers[-1].trainable=False model.compile(optimizer=keras.optimizers.Adam(lr=0.0001), loss='mse') return model modelhead=Createheadmodel()
Ce modèle est un réseau de neurones monocouche entièrement connecté avec 32 neurones et 512 nœuds d'entrée - l'une des architectures les plus simples, qui est néanmoins bien formée:
hist=modelhead.fit(Xtrain,Ytrain, epochs=4000, batch_size=5000, validation_data=(Xval,Yval) )
4950/4950 [===============================] - 0s 3us / step - perte: 0,0069 - val_loss: 0,0071
Construisons des courbes d'apprentissage
plt.plot(hist.history['loss'][100:], label='loss') plt.plot(hist.history['val_loss'][100:],label='validation_loss') plt.legend(bbox_to_anchor=(0.95, 0.95), loc='upper right', borderaxespad=0.)
On voit que la perte (écart carré moyen) est de 0,0071 sur les données de validation, donc l'écart type = 0,084 ou 0,42 points sur une échelle à cinq points, ce qui est inférieur à la dispersion des estimations données par les personnes (0,6 point). Notre modèle fonctionne.
Pour visualiser le fonctionnement du modèle, vous pouvez utiliser le diagramme de dispersion - pour chaque photo à partir des données de validation, nous construisons un point où l'une des coordonnées correspond à la cote moyenne du visage et la seconde à la cote moyenne prédite:
Answer2=Answer.to_frame()[:5500] Answer2['ans']=0 Answer2['race']=Answer2.index Answer2['race']=Answer2['race'].apply(lambda x: x[:2]) Answer2['ans']=modelhead.predict(np.stack(facevecs)[:,0,:])*5 xy=np.array(Answer2.iloc[Indval][['ans','Rating']]) plt.scatter(xy[:,1],xy[:,0])

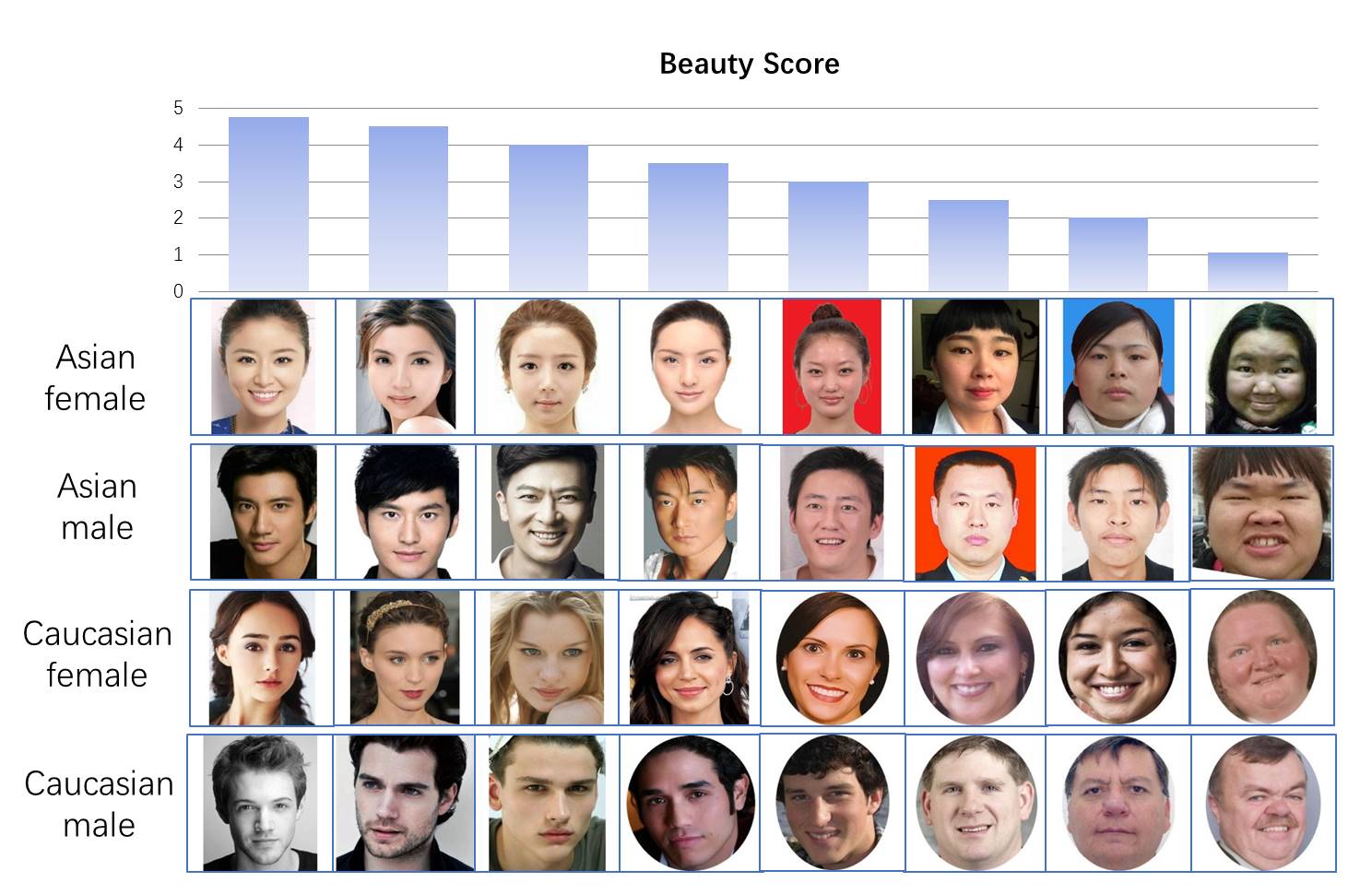
Axe Y - valeurs prédites par le modèle, axe X - valeurs moyennes des estimations des personnes. Nous voyons une corrélation élevée (le diagramme est allongé le long de la diagonale). Vous pouvez également consulter nos résultats visuellement - prenez les visages de chacune des catégories avec des notes prévues de 1 à 5
import matplotlib.image as mpimg f, axarr = plt.subplots(4,5,figsize=(10, 10)) for i, race in enumerate(['AF','CF', "AM", 'CM']): for rating in range(1,6):

On voit que le résultat du tri par beauté semble raisonnable.
Nous allons maintenant créer un modèle complet dans lequel nous soumettons un visage à l'entrée, à la sortie, nous obtenons une note de 0 à 1 et le convertissons au format tflite adapté au téléphone
import tensorflow as tf finmodel=Model(input=model.input, output=modelhead(model.output)) finmodel.save('finmodel.h5') converter = tf.lite.TFLiteConverter.from_keras_model_file('finmodel.h5') converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE] tflite_quant_model = converter.convert() open ("modelquant.tflite" , "wb").write(tflite_quant_model) from IPython.display import FileLink FileLink(r'modelquant.tflite')
Ce modèle reçoit une image d'un visage d'une taille de 112 * 112 * 3 à l'entrée et à la sortie, il donne un numéro unique de 0 à 1, ce qui signifie la beauté du visage (bien que nous devons nous rappeler que dans l'ensemble de données, les notes ne variaient pas de 0 à 5, mais de 1 à 5).
Partie 2. JAVA
Essayons d'écrire une application simple pour un téléphone Android. Le langage Java est nouveau pour moi, et je n'ai jamais été impliqué dans le développement pour Android, donc le projet n'utilise pas d'optimisation du travail, n'utilise pas le contrôle de flux et d'autres choses qui demandent beaucoup de travail pour un débutant. Étant donné que le code java est plutôt lourd, je ne donnerai ici que les éléments les plus importants pour que le programme fonctionne. Le code d'application complet est disponible
ici . L'application ouvre une photo, détecte et évalue un visage à l'aide d'un réseau précédemment enregistré et affiche le résultat:

Du point de vue du développement, les fonctions suivantes y sont importantes.
1. La fonction de chargement du réseau de neurones à partir du fichier model.tflite dans le dossier d'actifs dans l'objet interpréteur
import org.tensorflow.lite.Interpreter; Interpreter interpreter; try { interpreter=new Interpreter(loadModelFile(MainActivity.this)); Log.e("TIME", "Interpreter_started "); } catch (IOException e) { e.printStackTrace(); Log.e("TIME", "Interpreter NOT started "); } private MappedByteBuffer loadModelFile(Activity activity) throws IOException { AssetFileDescriptor fileDescriptor = activity.getAssets().openFd("model.tflite"); FileInputStream inputStream = new FileInputStream(fileDescriptor.getFileDescriptor()); FileChannel fileChannel = inputStream.getChannel(); long startOffset = fileDescriptor.getStartOffset(); long declaredLength = fileDescriptor.getDeclaredLength(); return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength); }
2. Détection des visages à l'aide du module FaceDetector, qui fait partie du package de bibliothèque standard de Google, à l'aide d'un réseau de neurones et affiche les résultats.
import com.google.android.gms.vision.face.Face; import com.google.android.gms.vision.face.FaceDetector; private void detectFace(){
Si vous souhaitez jouer avec le classement sur votre téléphone, vous pouvez télécharger l'
application sur le marché GooglePlay .