Pour Hadoop et Greenplum, il est possible de se préparer au SaaS. Et si Khadup est une chose bien connue, alors Greenplum (c'est la base du produit ArenadataDB, qui sera discuté plus tard) est intéressant, mais déjà moins "à l'oreille".
Arenadata DB est un SGBD distribué basé sur l'open source Greenplum. Comme les autres solutions MPP (traitement parallèle des données), pour les systèmes massivement parallèles, l'architecture cloud est loin d'être optimale. Cela peut réduire les performances jusqu'à 30% (généralement moins). Mais, néanmoins, ce problème peut être nivelé (ce qui sera discuté ci-dessous). En outre, il vaut la peine d'acheter un tel service à partir du cloud, il est souvent pratique et rentable par rapport au déploiement de votre propre cluster.
Sur site est clairement indiqué dans les guides, mais maintenant beaucoup de gens réalisent l'ampleur de la commodité du cloud. Tout le monde comprend qu'il y aura une sorte de dégradation des performances, mais c'est quand même tellement super pratique et rapide qu'il existe déjà des projets où cela est sacrifié à certaines étapes comme les hypothèses de test.
Si vous avez un entrepôt de données de plus de 1 To et des systèmes transactionnels - pas votre profil de charge, voici ci-dessous une histoire sur ce qui peut être fait en option. Pourquoi 1 To? À partir de ce volume, l'utilisation de MPP est plus efficace en termes de rapport performance / coût par rapport aux SGBD classiques.
Quand l'utiliser?
Lorsque le SGBD classique à nœud unique par architecture ne convient pas à vos volumes. Un cas courant est un nouvel entrepôt de données d'une capacité supérieure à 1 To. MPP DBMS est désormais à la mode et Greenplum est l'un des meilleurs du marché pour les tâches modernes. Surtout compte tenu de son ouverture. Il existe également un tas de systèmes propriétaires avec de nombreuses fonctionnalités prêtes à l'emploi: Terradata, Sap Khan, Exadata, Vertika. Par conséquent, si vous ne pouvez pas vous permettre d'ananas et de tétras, prenez la prune.
Le deuxième cas est celui où vous avez un entrepôt de données existant sur quelque chose d'universel comme Oracle ou Post-Congress, mais les utilisateurs se plaignent régulièrement de la lenteur des rapports. Et lorsqu'il y a de nouvelles tâches comme le Big Data - lorsque les utilisateurs veulent toutes les données immédiatement, ils ne peuvent pas prédire ce qu'ils en feront. Il existe de nombreuses situations où une entreprise en exploitation a besoin de rapports qui ne sont pertinents qu’une seule journée et qui n’ont pas le temps de payer en une journée. Autrement dit, il n'y a fondamentalement pas de données nécessaires. Dans ce cas, il est également pratique de prendre des bases de données MPP et d'essayer avec SaaS dans le cloud.
Le troisième cas est celui où quelqu'un suit la mode Hadup et résout les tâches standard de traitement par lots des données structurées, mais le cluster n'est pas bien assemblé. On voit souvent que la technologie est un peu appliquée et même pas du tout comme elle le devrait. Par exemple, vous n'avez pas besoin de créer une base de données relationnelle sur Khadup. Néanmoins, si votre Hadoup ne dispose soudainement pas d'un traitement en temps réel ou qu'il était censé le faire, mais que l'administrateur et le développeur ont fui avec horreur, vous pouvez également vous tourner vers Greenplum dans le cloud: le support sera très simple tout en conservant la capacité de traiter d'énormes quantités de données.
Pourquoi peu de gens essaient-ils?
Tout SGBD MPP nécessite beaucoup de capacité. Ça fait beaucoup de fer. En fait, les gens ont peur d'essayer le niveau de preuve de concept simplement à cause du prix d'entrée. Ils ne peuvent pas faire cela physiquement. L'une des principales idées de notre SaaS est de vous donner la possibilité de jouer avec tout cela sans acheter un cluster de fer.
Et nous rencontrons régulièrement des clients qui disent que nous ne voudrions pas accompagner, opérer et ainsi de suite de façon indépendante. Et je voudrais externaliser. Il s'agit d'un système analytique, et le plus souvent, il est critique pour l'entreprise, mais pas pour la mission. Beaucoup en Occident sous-traitent; nous avons également commencé récemment.
Quelle est la meilleure chose à faire sur MPP?
Entrepôt de données d'entreprise classique: pour toutes les sources de données, vous obtenez des données incrémentielles, puis les fenêtres sont conçues pour les utilisateurs. Les utilisateurs situés au-dessus de ces vitrines créent leurs rapports. «Chaque jour, je veux voir comment les choses se passent dans les affaires» - c'est tout.
Encore quelques mots sur la solution cloud
Autrefois, ces infrastructures étaient mal conçues pour les nuages. Mais en réalité, de plus en plus de clients entrent dans les nuages. Le travail nécessite de hautes performances, car il tourne autour d'un grand nombre de requêtes analytiques volumineuses qui consomment beaucoup de CPU, nécessitent beaucoup de mémoire et ont des exigences élevées sur les disques et l'infrastructure réseau. Par conséquent, lorsque les clients déploient des SGBD distribués dans le cloud, ils peuvent rencontrer plusieurs problèmes.
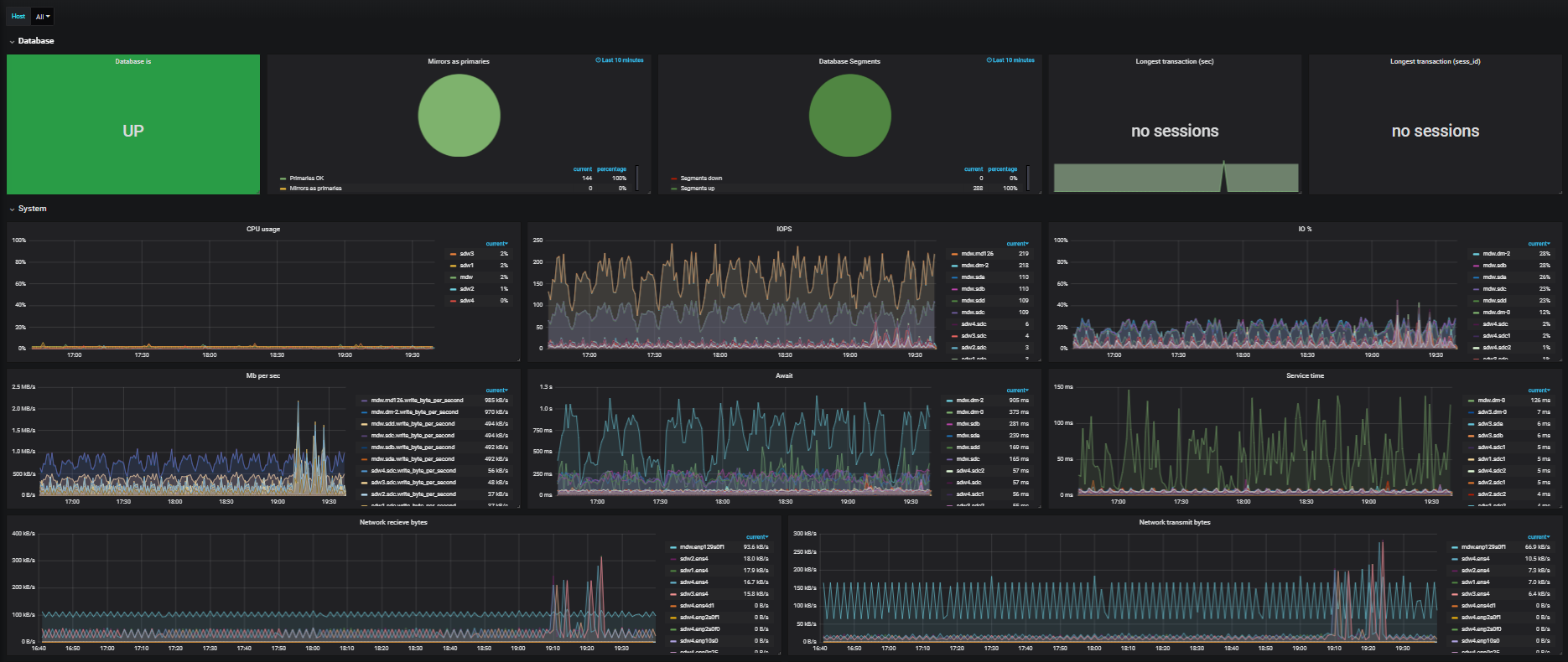
Le premier est la mauvaise performance du réseau. Étant donné que tout cela se produit dans le cloud dans un environnement virtuel, il peut y avoir plusieurs machines sur un hyperviseur. Les machines virtuelles peuvent être dispersées sur différents hyperviseurs. De plus, à certains moments, ils peuvent être dispersés dans différents centres de données, les superviseurs peuvent les tourner virtuellement. Et à cause de cela, le réseau souffre grandement. Lors du traitement d'un milliard d'enregistrements dans une table, disons 10 serveurs, et il entraîne ces données entre tous les serveurs. Une sous-espèce fonctionne à l'intérieur, et même à l'intérieur d'un serveur, de nombreuses sous-espèces fonctionnent. Il peut y en avoir 10 à 20 et maintenant, ils commencent tous à générer des données sur le réseau pendant l'exécution de la demande. Le réseau tombe comme les cultures d'hiver. Quelle conclusion peut-on en tirer? Utilisez des nuages à large bande passante, tels que le nuage CROC, qui offre 56 Go sur Infiniband.
Le deuxième problème est que les pare-feu et les protections DDoS semblent très biaisés. Écaillé, décidé. Avant utilisation, nous vous recommandons de prévoir une heure supplémentaire pour vérifier tous les paramètres.
Migration et mise à jour en direct encore imperceptibles. Pour faire glisser une machine vers un autre hyperviseur, puis en arrière, vous ne devez pas perdre de paquets. Il faut chamaniser avec les réglages au final. Par exemple, nous avons presque immédiatement grimpé pour augmenter le presse-papiers. MTU porté à 9 000 jumboframes.
Bien sûr, les lecteurs qui ont un disque dur. Ils n'aiment vraiment pas un tel enregistrement, surtout quand ce sont des secteurs très, très aléatoires dans la file d'attente avec le reste des demandes. Nous avons décidé de diviser le stockage en segments: l'un est uniquement pour Greenplum, l'autre est partagé. Cela est nécessaire dans les situations où une douzaine de clients déploient des installations Greenplum en parallèle. MPP utilise autant que possible le sous-système de disques, les services cloud sont interconnectés au stockage et les performances y sont presque les mêmes que celles du canal. Si tous les clients du cloud ne calculent pas le MPP, vous pouvez obtenir un gain très important. Une distribution efficace de l'énergie dans de telles charges fonctionne très bien.
Et en raison de sa propre architecture, Greenplum dans le cloud est plus efficace que Redshift, BigQuery et Snowflake.
À quoi ressemble le déploiement:
Comme ça:
L'architecture est "respirante", c'est-à-dire que vous pouvez rapidement déployer un facteur simple dans la configuration. Par exemple, l'après-midi, nous avons cinq processeurs, et le soir, nous avons 1 000 gestionnaires en hausse et dix processeurs en fonctionnement. Dans ce cas, vous n'avez pas besoin d'équilibrer les données, car elles se trouvent à l'intérieur du même magasin. Une extension est disponible prête à l'emploi, une compression rapide doit encore être effectuée un peu.
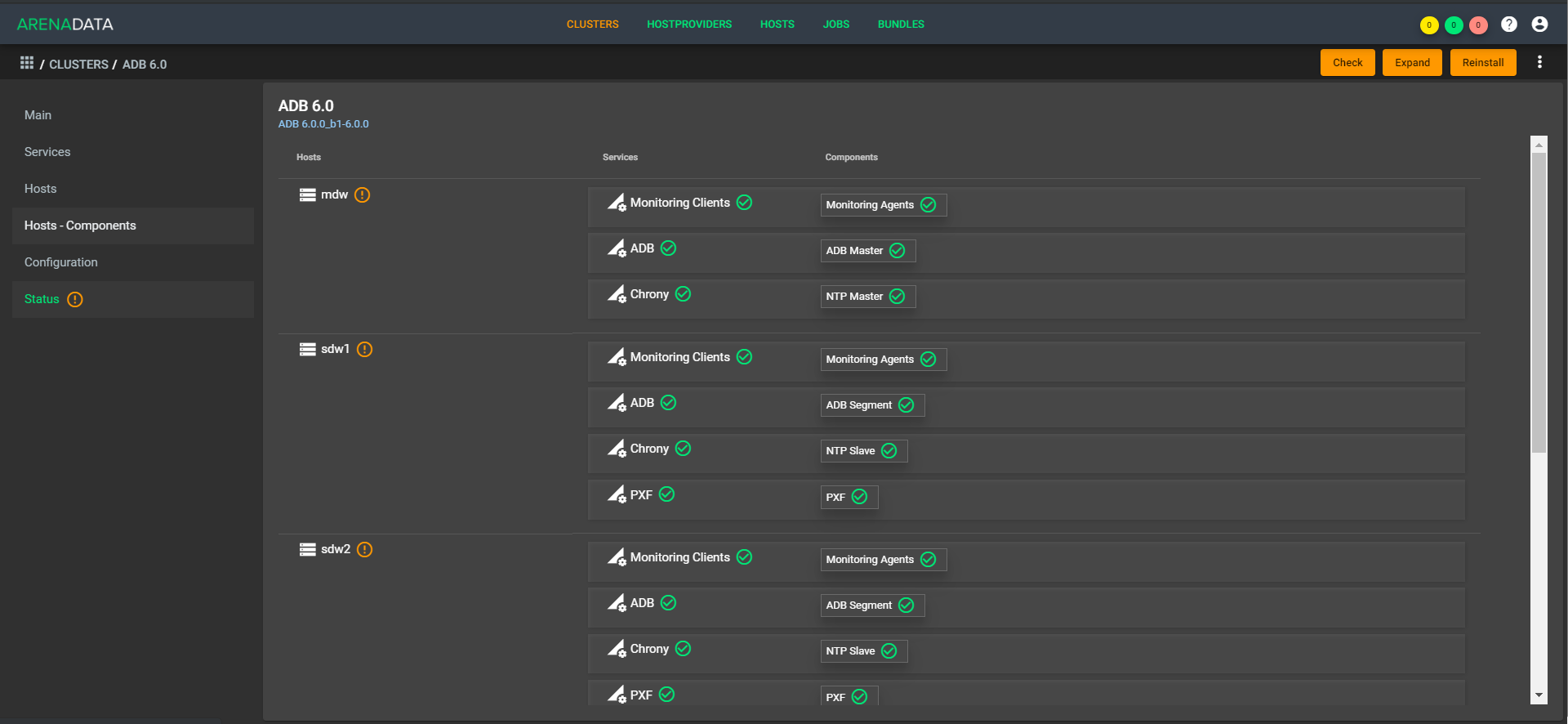
Maintenant, pour le client, il n'y a qu'un seul point de gestion. Il vient à un endroit, y lance une demande comme: «Déployez un plan de cluster pour moi sur de telles machines», et notre support déploie les machines dans le cloud (avec nous ou le client), place Greenplum là, lance, configure et fait tous les réglages. Il en va de même pour le suivi, la gestion, la mise à jour. Au fur et à mesure de l'automatisation, cela laissera un support sur les boutons de votre compte.
Nous avons d'abord compris la commodité d'une telle approche sur les projets internes, puis nous avons commencé à fournir du SaaS aux clients. Nous avons une intégration profonde avec S3 - cela vous permet d'utiliser Greenplum en tant que système avec des couches distinctes pour l'informatique et le stockage, ou d'utiliser S3 pour les sauvegardes, et Greenplum comme noyau dans QCD dans le cloud. Il existe un déploiement flexible d'environnements pour les entreprises utilisant l'API CROC et l'API ADCM.