A la veille du début du cours «Mathématiques pour la science des données. Cours avancé », nous avons organisé un webinaire ouvert sur le thème« Méthodes d'analyse de régression en science des données ». Nous y avons découvert le concept des régressions linéaires, étudié où et comment elles peuvent être appliquées dans la pratique, et également appris quels sujets et sections de l'analyse mathématique, l'algèbre linéaire et la théorie des probabilités sont utilisés dans ce domaine. Chargé de cours - Peter Lukyanchenko , maître de conférences à l'École supérieure d'économie, responsable des projets technologiques.
Si nous parlons de mathématiques dans le contexte de la science des données, nous pouvons distinguer les trois problèmes les plus fréquemment résolus (bien qu'il y ait, bien sûr, plus de problèmes):

Parlons plus en détail de ces tâches:
- La tâche de l'analyse de régression ou d'identifier les dépendances (lorsque nous avons un certain ensemble d'observations). Dans le graphique ci-dessus, vous pouvez voir qu'il existe une certaine variable x et une certaine variable y, et nous observons les valeurs de y pour un x spécifique. Nous connaissons ces points et connaissons leurs coordonnées, et nous savons également que x influence en quelque sorte y, c'est-à-dire que ces deux variables sont interdépendantes. Naturellement, nous voulons calculer l'équation de leur dépendance - pour cela, nous utilisons le modèle de la régression linéaire de paire classique , quand on suppose que leur dépendance peut être décrite par une certaine droite. Par conséquent, les coefficients de ligne droite sont sélectionnés de manière à minimiser l'erreur dans la description des données. Et juste sur le type d'erreur (métrique de qualité) qui sera sélectionné, le résultat réel de la construction d'une régression linéaire dépend.
- Une autre tâche de l'analyse des données concerne les systèmes de recommandation . C'est quand nous disons qu'il y a, par exemple, des magasins en ligne, qu'ils ont un certain ensemble de marchandises et qu'une personne fait des achats. Sur la base de ces informations, il est possible de fournir une description de cette personne dans l'espace vectoriel et, ayant construit cet espace vectoriel, de construire une dépendance mathématique de la probabilité avec laquelle cette personne achètera tel ou tel produit, en connaissant ses achats antérieurs. En conséquence, nous parlons de classification, lorsque nous classons les acheteurs potentiels selon les principes: «acheter-ne pas acheter», «intéressant-inintéressant», etc. Il existe différentes approches: basées sur les utilisateurs et basées sur les articles.
- Le troisième domaine est la vision par ordinateur . Au cours de cette tâche, nous essayons de déterminer où se trouve l'objet qui nous intéresse. Il s'agit en fait d'une solution au problème de la minimisation des erreurs en sélectionnant des pixels spécifiques qui forment l'image de l'objet.
Dans les trois problèmes, il y a l'optimisation, la minimisation des erreurs et la présence de l'un ou l'autre modèle qui décrit la dépendance des variables. En même temps, à l'intérieur de chacun se trouve une représentation des données qui se décompose en une description vectorielle. Dans notre article, nous porterons une attention particulière à la section qui affecte
les modèles de régression .
Nous avons déjà mentionné qu'il existe un certain ensemble de paires de données: X et Y. Nous savons quelles valeurs Y prend par rapport à X. Si X est le temps, alors nous obtenons un modèle de série chronologique dans lequel Y est, disons, le prix du pétrole et en même temps, le taux de change du rouble au dollar, et X est une certaine période de temps de 2014 à 2018:
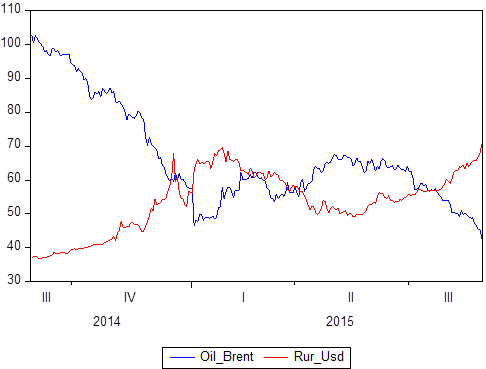
Si vous construisez graphiquement, il est clair que ces deux séries temporelles sont interdépendantes. Après avoir défini le concept de corrélation, vous pouvez calculer le degré de leur dépendance, puis, si vous savez que certaines valeurs sont parfaitement corrélées (la corrélation est 1 ou -1), vous pouvez l'utiliser pour des tâches de prévision ou pour des tâches de description.
Considérez l'illustration suivante:
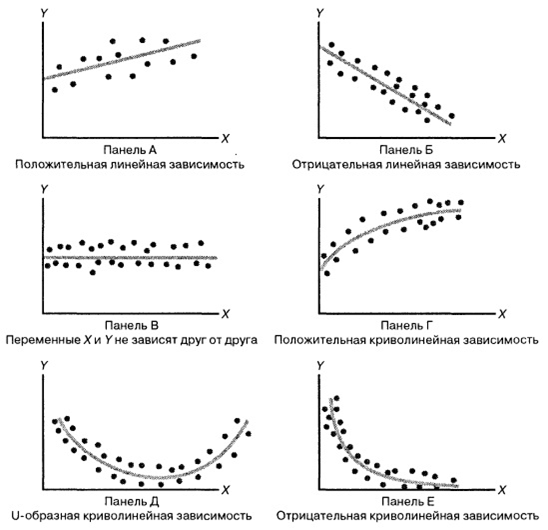
La partie la plus difficile dans la formation d'un modèle de régression est de
mettre initialement une fonction spécifique dans sa mémoire . Par exemple, pour la figure A, c'est Y = kX + b, pour B, c'est Y = -kX + b, dans la figure C, le «jeu» est égal à un certain nombre, le graphique de la figure D est très probablement basé sur la racine de « X ”, à la base de D, peut-être une parabole, et à la base de E - une hyperbole.
Il s'avère que
nous choisissons un modèle de dépendance aux données , et les types de dépendance entre les variables aléatoires sont différents. Tout n'est pas si évident, car même dans ces dessins simples, nous voyons diverses dépendances. En choisissant une relation spécifique, nous pouvons utiliser des méthodes de régression pour calibrer le modèle.
La qualité de vos prévisions dépendra du modèle que vous choisissez . Si nous nous concentrons sur des modèles de régression linéaire, nous supposons qu'il existe un certain ensemble de valeurs réelles:

La figure montre les 4 valeurs observées de X1, X2, X2, X4. Pour chacun des X, la valeur Y est connue (dans notre cas, ce sont les points: P1, P2, P3, P4). Ce sont les points que nous observons réellement sur les données. Ainsi, nous avons reçu un certain ensemble de données. Et pour une raison quelconque, nous avons décidé que la régression linéaire décrit le mieux la relation entre le X et le joueur. De plus, toute la question est de savoir comment construire l'équation d'une droite Y = b
1 + b
2 X, où b
2 est le coefficient de pente, b
1 est le coefficient d'intersection. Toute la question est de savoir quels b
2 et b
1 sont les mieux définis pour que cette ligne droite décrive la relation entre ces variables aussi précisément que possible.
Les points R
1 , R
2 , R
3 , R
4 sont les valeurs que notre modèle donne aux valeurs de X. Que se passe-t-il? Les points P sont des points que nous observons réellement (effectivement collectés), et les points R sont des points que nous observons dans notre modèle (ceux qu'il produit). Ce qui suit est une logique humaine incroyablement simple: un
modèle sera considéré comme qualitatif si et seulement si les points R sont aussi proches que possible des points P.Si nous construisons la distance entre ces points pour le même «X» (P
1 - R
1 , P
2 - R
2 , etc.), nous obtenons ce qu'on appelle des erreurs de régression linéaire. Nous obtenons les écarts en régression linéaire, et ces écarts sont appelés U
1 , U
2 , U
3 ... U
n . Et ces erreurs peuvent être en plus ou en moins (nous pourrions surestimer ou sous-estimer). Pour comparer ces écarts, ils doivent être analysés. Une méthode très large et très belle est utilisée ici - la quadrature (la quadrature «tue» le signe). Et la somme des carrés de tous les écarts dans les statistiques mathématiques est appelée RSS (somme résiduelle des carrés). En minimisant RSS par b
1 et en minimisant RSS par b
2 , nous obtenons des coefficients optimaux qui sont réellement dérivés
par la méthode des moindres carrés .
Après avoir construit la régression, déterminé les coefficients optimaux b
1 et b
2 , et nous avons l'équation de régression, les problèmes ne s'arrêtent pas là et le problème continue de se développer. Le fait est que si la régression elle-même est marquée sur un graphique, toutes les valeurs que nous avons, ainsi que les valeurs moyennes des «jeux», alors la somme des erreurs quadratiques peut être clarifiée.
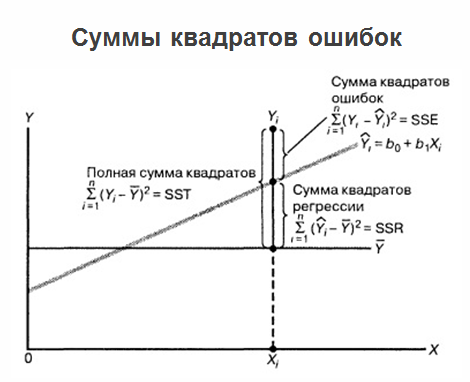
Dans le même temps, il est jugé utile d'afficher les erreurs de prédiction de régression par rapport à la variable X. Voir la figure ci-dessous:

Nous avons obtenu une sorte de régression et avons tiré les vraies données. Nous avons obtenu la distance entre chaque valeur réelle et la régression. Et nous l'avons dessiné par rapport à la valeur zéro pour les valeurs correspondantes de X. Et dans la figure ci-dessus, nous voyons une très mauvaise image: les
erreurs dépendent de X. Une certaine dépendance à la corrélation est clairement exprimée:
plus le «X» avance, plus la signification des erreurs est importante . C'est très mauvais. La présence de corrélation dans ce cas indique que nous avons pris par erreur le modèle de régression et qu'il y avait un paramètre auquel nous «n'avions pas pensé» ou simplement ignoré. Après tout, si toutes les variables sont placées à l'intérieur du modèle, les erreurs devraient être complètement aléatoires et ne devraient pas dépendre de ce que vos facteurs sont égaux.
Les erreurs doivent être avec la même distribution de probabilité , sinon vos prédictions seront erronées. Si vous avez dessiné les erreurs de votre modèle dans l'avion et rencontré un triangle divergent, il est préférable de tout recommencer à zéro et de recompter complètement le modèle.
En analysant les erreurs, vous pouvez même immédiatement comprendre où ils ont mal calculé, quel type d'erreur ils ont fait. Et ici nous ne pouvons manquer de mentionner le théorème de Gauss-Markov:

Le théorème détermine les conditions dans lesquelles les estimations obtenues par la méthode des moindres carrés sont les meilleures, cohérentes et efficaces dans la classe des estimations linéaires sans biais.
La conclusion peut être tirée comme suit: nous comprenons maintenant que le
domaine de la construction d'un modèle de régression est, en un sens, l'aboutissement du point de vue des mathématiques , car toutes les sections possibles qui peuvent être utiles dans l'analyse des données fusionnent en même temps, par exemple:
- algèbre linéaire avec méthodes de représentation des données;
- analyse mathématique avec théorie de l'optimisation et moyens d'analyse des fonctions;
- théorie des probabilités permettant de décrire des événements et des quantités aléatoires et de modéliser la relation entre les variables.
Chers collègues, je vous suggère tout de même, pas seulement de lire et de regarder l'intégralité du webinaire . L'article ne comprend pas les moments liés à la programmation linéaire, l'optimisation dans les modèles de régression et d'autres détails qui peuvent vous être utiles.