R est un outil très puissant pour travailler avec des statistiques: du prétraitement à la construction de modèles de toute complexité et des graphiques correspondants.
Une simple demande Google fournira une grande quantité de documentation sur la façon «d'utiliser R facilement et rapidement». Il y aura d'énormes livres et de nombreuses notes sur le débordement de pile , qui, à première vue, semblent être une mine d'exemples sans fin, chacun en deux chefs d'accusation va collecter le code nécessaire pour résoudre un problème spécifique. Cependant, en réalité, ce n'est pas du tout vrai. Il y a très peu de documents qui diraient, par exemple, comment construire un programme simple "à partir de zéro" avec des recettes prêtes à l'emploi pour résoudre les difficultés qui surgiront au cours de la résolution de ce problème.
Pour résoudre des problèmes pratiques, des instructions spécifiques étape par étape sont nécessaires, et non une description détaillée de la pleine puissance d'un package. De plus, les études de cas toutes faites (les mêmes iris ) sont souvent peu utiles, car elles sautent immédiatement l'une des étapes les plus importantes du travail avec les statistiques - la collecte préliminaire et le traitement des données elles-mêmes. Mais c'est précisément pour ce travail que presque une grande partie du temps prend souvent! Un problème distinct est la création d'horaires qui correspondent aux normes formelles et plus souvent informelles d'un certain environnement professionnel.
Mes collègues et moi devons régulièrement faire de plus en plus de visualisations de statistiques et de modèles basés sur eux pour publier des résultats scientifiques. Comme les études concernent l'économie, nombre de ces travaux sont similaires au journalisme professionnel.
À un moment donné, il est devenu clair que pour un travail d'équipe efficace, une sorte de pipeline de traitement des statistiques à part entière est nécessaire. Cet article est né comme un guide d'introduction pour les collègues et une feuille de triche pour moi-même pour faire fonctionner ce convoyeur. Il semble que ce matériel puisse être utile à un public plus large.
Graphiques sans douleur R: Procédure pas à pas
Réglage de base R
Pour fonctionner, vous avez besoin d'un bundle standard: R + RStudio . Ils sont disponibles gratuitement pour toutes les plateformes courantes. R est installé en premier, puis RStudio. Il n'y a généralement aucun problème.
Avant de travailler, il est préférable d'enregistrer immédiatement le nouveau script quelque part dans votre système de fichiers et d'installer immédiatement le répertoire de travail R dans le dossier où le script est stocké (menu Session - Définir le répertoire de travail - Vers l'emplacement du fichier source). La dernière note est importante, car sinon, le démarrage d'un script externe ou natif après le redémarrage de RStudio n'aura pas lieu. Pour une raison quelconque, RStudio ne le fait pas par défaut, ce qui serait logique.
Même dans le package de base R, il existe des outils de visualisation standard (fonction de tracé ) qui vous permettent de créer de nombreux types de graphiques, mais néanmoins, ces fonctionnalités ne sont clairement pas suffisantes pour des illustrations complètes et hautement personnalisables.
La bibliothèque de graphiques en R la plus utilisée est le paquet ggplot2 , que nous utiliserons également.
Il vaut également la peine d'installer immédiatement les packages readxl (pour lire les fichiers .xls, .xlsx) et dplyr (pour travailler avec les tableaux), les échelles (pour travailler avec différentes échelles de données), Cairo (pour dessiner des graphiques de ggplot vers des fichiers). Tout cela peut être fait avec une seule commande:
install.packages("ggplot2", "readxl", "scales", "dplyr", "Cairo")
Collecte et préparation des données
La chose la plus surprenante est que cette étape de la littérature, qu'il s'agisse d'un livre théorique sérieux sur les statistiques théoriques appliquées ou de directives pour des progiciels statistiques spécifiques, est consacrée à un espace et à un temps catastrophiques. Néanmoins, selon l'expérience de la recherche indépendante et du leadership des étudiants et des collègues juniors, il est connu que c'est à ce stade que la part du lion du temps et des efforts peut chuter, il est donc très important de les économiser même lors de la résolution de problèmes purement techniques.
Il y a deux questions ici:
- Comment choisir le bon format de fichier?
- Quelle est la meilleure façon de structurer les données?
Avec le format, le dilemme est simple: CSV contre Microsoft Excel (pas si important, "nouveau" .xlsx ancien .xls). Beaucoup de gens pensent que CSV bénéficie de la simplicité (en fait, c'est un fichier texte normal dans lequel les valeurs des colonnes sont séparées par une virgule ou un point-virgule) et de la vitesse. Mais je choisis Excel pour deux raisons: premièrement, dans ce fichier, vous pouvez stocker plusieurs tableaux simultanément sur différents onglets, et deuxièmement, plus important encore, vous n'avez pas à penser à choisir le bon séparateur de colonnes et la décimale. Pour CSV, cela doit souvent être écrit manuellement dans le code R et assurez-vous que le fichier de données est enregistré avec les mêmes paramètres.
La structuration des données est un problème plus complexe, nécessitant une compréhension de base de la façon dont les bases de données doivent être organisées. Si vous n'entrez pas dans la théorie des bases de données relationnelles sur différentes formes normales, alors Le tableau de données doit être redondant, c'est-à - dire contenir des colonnes supplémentaires. Cela est nécessaire pour que plus tard dans le script dans R, vous puissiez sélectionner de manière flexible certaines informations pour un traitement ultérieur. Par exemple, si nous voulons représenter une série temporelle primitive, nous devons créer des colonnes qui correspondent à toutes les caractéristiques de regroupement possibles. Par exemple, s'il s'agit d'une série d'observations annuelles de la population de la ville conditionnelle de Severovostochinsk, nous aurons besoin des colonnes suivantes: année (année), var (nom de l'indicateur), valeur (valeur de l'indicateur).
Nous fournirons toutes les données d'entrée à ce style de présentation des informations.
Exemple
Objectif: établir une comparaison de la dynamique des volumes de récolte en Russie, dans le district fédéral de Sibérie et dans le territoire de Krasnoïarsk en 2009-2018.
L'obtention de données pour cette tâche est assez simple: il suffit de trouver l'indicateur correspondant dans le Système statistique et d'information interministériel unifié . La subtilité vient ensuite. Vous pouvez immédiatement télécharger les données au format .xlsx, puis les structurer manuellement comme indiqué ci-dessus. Heureusement, certaines sources d'informations (par exemple, EMISS) vous permettent de le faire avec les capacités du service lui-même, ce qui simplifie considérablement le travail et réduit le temps nécessaire pour le terminer.
Ainsi, pour EMISS, il suffit de passer en mode «Paramètres» (le bouton correspondant dans le coin supérieur droit de la page de données) et de déplacer tous les signes, à l'exception de la «Période» de la colonne «Colonnes» vers la colonne «Lignes». Il s'avère qu'une table est presque prête pour nos travaux futurs. De plus, déjà dans Excel (ou tout autre éditeur approprié), il est logique d'amener la structure du tableau sous une forme similaire à celle présentée ci-dessus et de s'assurer que la première ligne ne contient que les noms des variables, avec des données en latin (en principe, R peut fonctionner avec des en-têtes en russe) mais cela n'est pas pratique lors de l'écriture de code). Le résultat était un tel tableau (un fragment est donné sur plusieurs lignes).
Vous pouvez maintenant appeler cette logging feuille, enregistrer l'intégralité du livre dans le fichier graphs.xlsx et accéder à RStudio.
Nous connectons les bibliothèques nécessaires.
library(ggplot2) library(readxl) library(Cairo) library(scales) library(dplyr)
Si un calendrier est en cours de préparation pour une publication en langue russe, vous devez définitivement configurer les paramètres régionaux appropriés. L'option la plus moderne qui fonctionnera dans la plupart des cas est, bien sûr, l'encodage UTF-8:
Sys.setlocale("LC_ALL", "ru_RU.UTF-8")
Si le système est ancien (certains anciens Windows ou Linux), vous devrez d'abord comprendre quel encodage est utilisé par défaut - ce n'est pas une tâche aussi simple, ce qui est loin de l'objectif de cet article.
Vous devez maintenant charger les données dans R.
df_logging <- read_excel("graphs.xlsx", sheet ="logging")
L'option de sheet définit ici le nom de la feuille dans le classeur Excel à partir duquel les données seront chargées.
Nous construisons la version la plus simple du planning requis.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location))

En principe, quasiment «prêt à l'emploi» s'est avéré être un calendrier très digne, ce qui est tout à fait approprié pour une première analyse du processus à l'étude, mais du point de vue d'une éventuelle publication, il nécessite encore un raffinement important.
Tout d'abord, apportons le style graphique à un style plus académique. Le paquet ggplot2 a plusieurs thèmes de base prêts à l'emploi. Le thème de theme_classic peut être reconnu comme le plus adapté à notre cas. Dans le cadre de sa configuration, vous pouvez définir immédiatement la taille de base de la police et de son casque. Mes préférences personnelles appartiennent au système de police moderne PT Sans, PT Serif, PT Mono . Mais, bien sûr, vous pouvez demander un Times ou Helvetica plus classique. En outre, la publication dans laquelle la publication est prévue peut avoir des instructions spéciales à cet égard. Le point de base est déterminé empiriquement à 12 pt.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location)) + theme_classic(base_family = "PT Sans", base_size = 12)
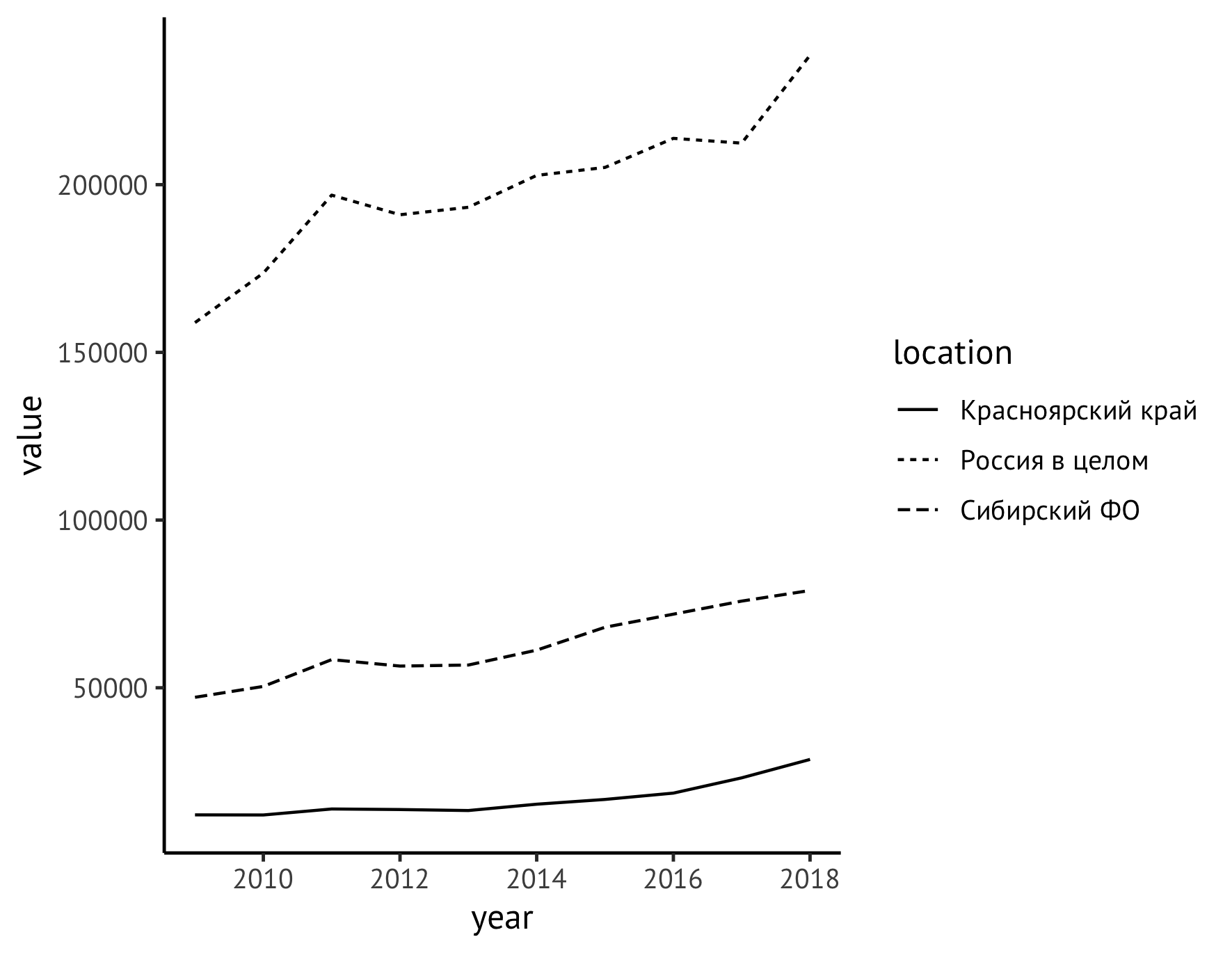
Ensuite, déplacez la légende du champ droit du graphique vers le bas (en utilisant l'instruction de theme ) et en même temps donnez des noms significatifs aux axes (instruction de labs ). Le long de l'axe Y, nous écrivons le nom de l'indicateur avec des unités de mesure ("Volumes d'enregistrement, millions de mètres cubes"), et supprimons les étiquettes le long de l'axe X, car il est clair que les années y sont marquées.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location)) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + labs(x = "", y = " , . . ", color="")

Pour rendre les unités de mesure plus pratiques pour la perception, nous allons passer de mille mètres cubes. m à des millions. Pour ce faire, divisez simplement les valeurs par 1000, c'est-à-dire ajustez la première ligne de notre code comme suit:
ggplot(data=df_logging, aes(x=year, y=value/1000))
En même temps, vous devez changer les unités dans l'inscription:
labs(x = "", y = " , . ", color="")
Et immédiatement, nous allons légèrement améliorer le style d'image en ajoutant des points pour indiquer chaque valeur observée, pour lesquels nous ajouterons une instruction:
geom_point(size=2)
Vous pouvez également définir explicitement le style des lignes elles-mêmes. Il est logique de faire de l'indicateur pour la Russie une ligne continue, et pour le district fédéral sibérien et le territoire de Krasnoïarsk - différentes versions d'intermittent:
scale_linetype_manual(values=c("twodash", "solid", "dotted"))
Maintenant, le code général et le graphique ressemblent à ceci:
ggplot(data=df_logging, aes(x=year, y=value/1000)) + geom_line(aes(linetype=location)) + geom_point(size=1) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + scale_linetype_manual(values=c("twodash", "solid", "dotted")) + labs(x = "", y = " , . ", color="")

Il reste à résoudre une tâche plus substantielle - augmenter le contenu informatif de notre calendrier. Maintenant, on peut en déduire que, en général, l'indicateur pour tous les objets d'observation a augmenté, d'ailleurs, depuis environ 2014, il est plus fort qu'auparavant. Mais il serait beaucoup plus clair si nous représentions directement sur le graphique les valeurs de la première et de la dernière année et, par exemple, au sommet de 2011. La nouvelle instruction geom_text aidera:
geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8)
À première vue, cela a l'air plutôt compliqué, et je dois dire que ce n'était vraiment pas si facile de l'assembler. Je vais essayer d'expliquer ce qui se passe ici. En lui-même, geom_text ajoute des étiquettes de texte au graphique. Pour cette instruction, un ensemble de données est nécessaire. Si nous spécifions df_logging directement dedans, nous obtiendrions des inscriptions au-dessus de chaque point. Cela se fait assez souvent, mais pour des séries temporelles assez simples comme la nôtre, cette approche ne fera que créer un bruit visuel inutile sans nous fournir de nouvelles informations sur le comportement de l'indicateur observé. Par conséquent, nous ne prendrons que les années qui sont essentielles pour comprendre la dynamique de l'indicateur: 2009 (début des observations), 2011 (pic local), 2018 (fin des observations). Cela aidera le subset - subset standard.
Pour l'affichage correct des nombres conformément à la tradition russophone, nous avons besoin d'une virgule comme séparateur des parties entières et décimales ( decimal.mark ), et pour couper le nombre de décimales, l'instruction des chiffres. Diverses expériences avec elle, y compris l'utilisation de la fonction round , ont conduit au fait que si nous avons besoin d'une décimale, nous devons passer la valeur 3 aux digits .
L'option check_overlap n'est pas directement nécessaire ici, mais elle peut être utile dans d'autres cas: c'est un contrôle automatique des étiquettes qui se chevauchent. L'option vjust contrôle le placement vertical des étiquettes. La valeur est sélectionnée en fonction de considérations gustatives.
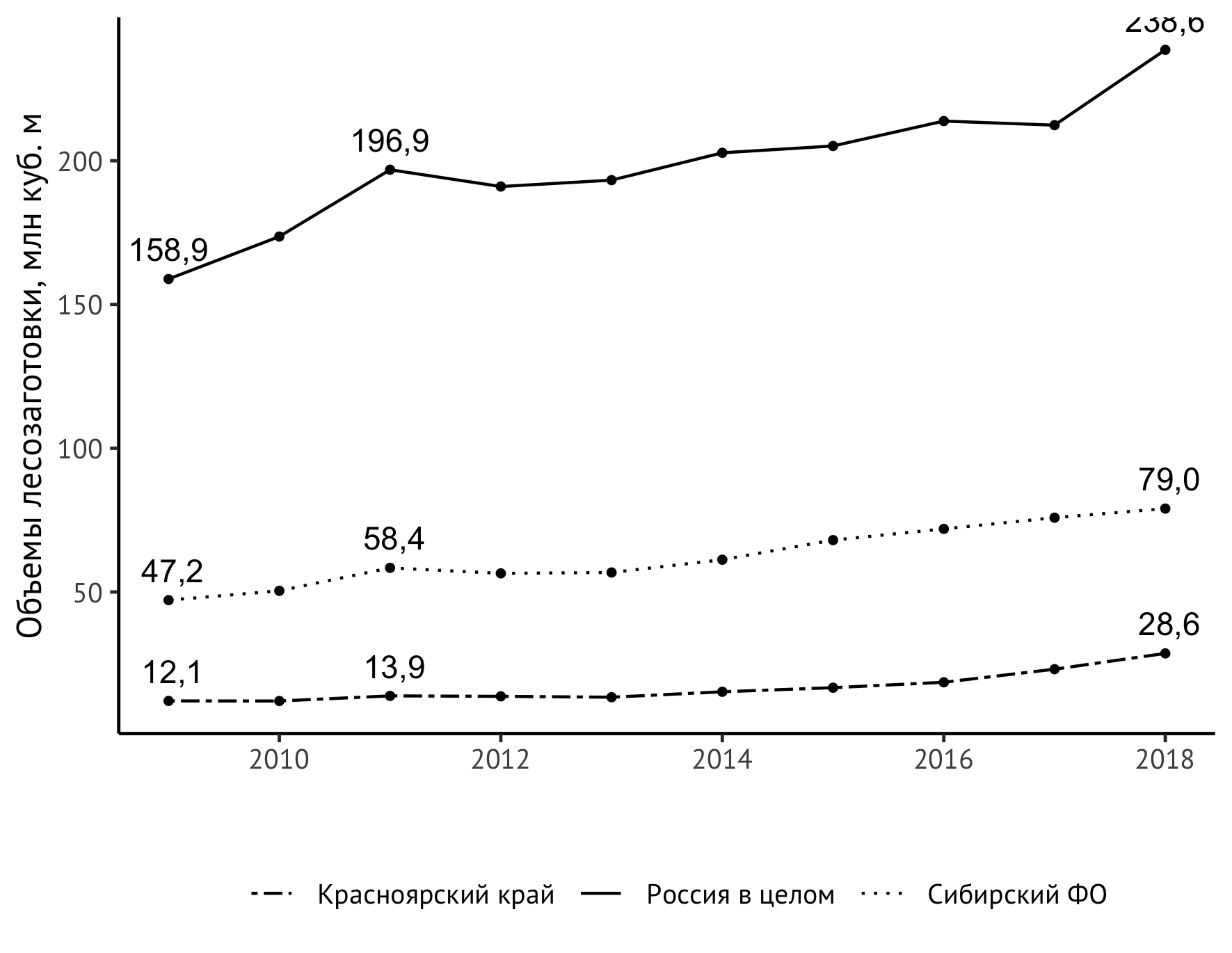
Maintenant, le calendrier est vraiment intéressant à considérer!
Mais un problème inattendu a été découvert - la valeur supérieure droite est «coupée» par la taille verticale de l'image. Il existe plusieurs façons de résoudre ce problème. Je suis sorti avec une légère extension de l'échelle de l'axe vertical avec une limite supérieure explicite de 250 millions de mètres cubes. m:
scale_y_continuous(limits = c(0,250))
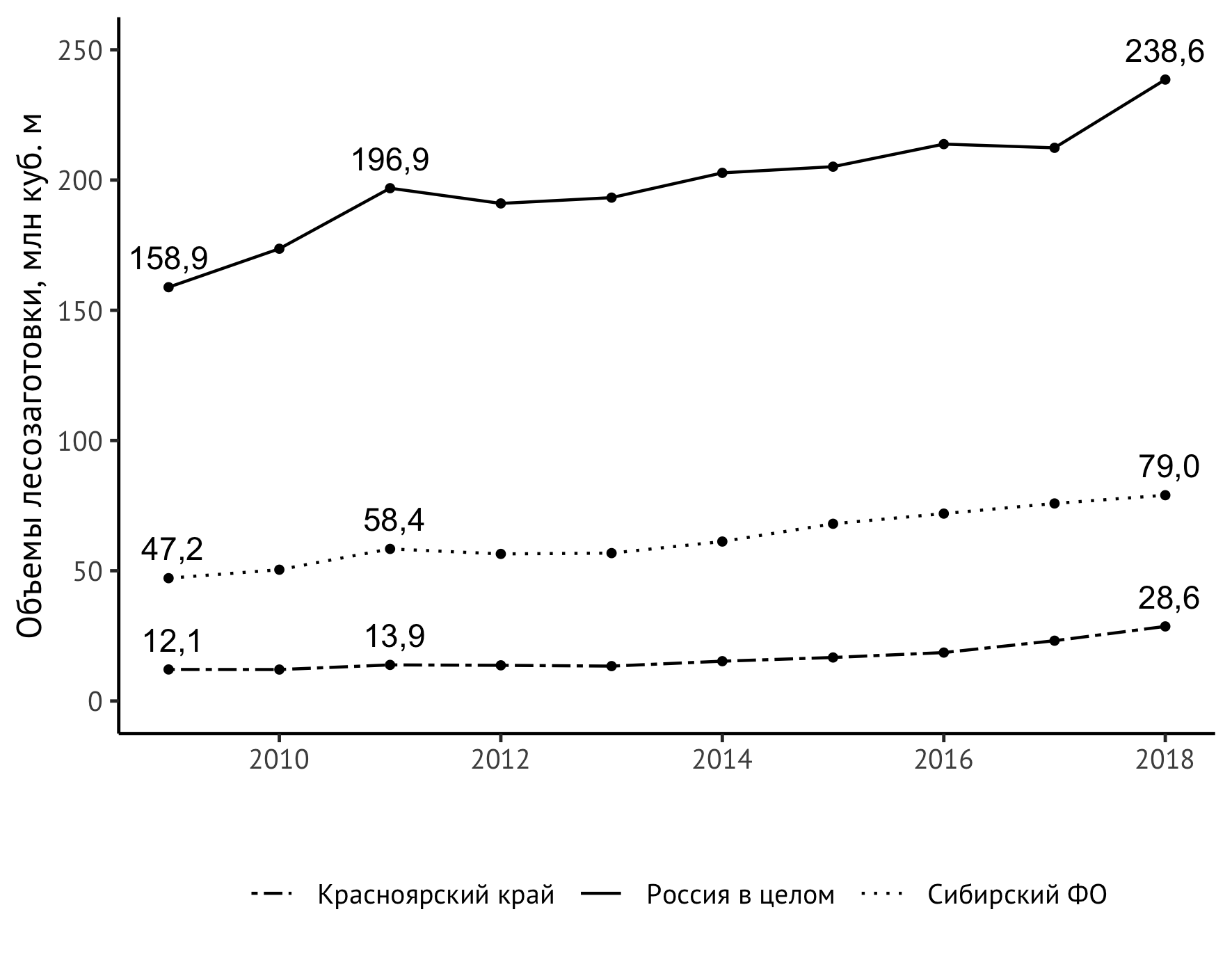
C'est fait! Ainsi, le code final ressemble à ceci:
ggplot(data=df_logging, aes(x=year, y=value/1000)) + geom_line(aes(linetype=location)) + geom_point(size=1) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8) + geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8) + scale_linetype_manual(values=c("twodash", "solid", "dotted")) + scale_y_continuous(limits = c(0,250)) + labs(x = "", y = " , . ", color="")
L'image résultante est incluse dans la monographie: La modernisation structurelle comme facteur d'augmentation de la compétitivité de la région (sur l'exemple du territoire de Krasnoïarsk) / éd. Shishatsky N.G.- Novosibirsk: IEOPP SB RAS, 2020 (sous presse).
Exporter
Le plug-in d'affichage graphique intégré à RStudio vous permet d'exporter des images dans plusieurs formats sans commandes supplémentaires, en quelques clics seulement. Le problème est que pour des tâches pratiques, ce service est pratiquement inutile. Lors de l'enregistrement au format raster (.jpg, .png), le paramètre par défaut est très faible, donc lorsque vous importez une image, par exemple, dans Word, elle sera floue. Avec le vecteur .eps ou .pdf, la situation est franchement pire: la sauvegarde se produit soit avec des erreurs qui ne permettent alors pas d'ouvrir le fichier, soit est sauvegardée sans possibilité d'utiliser des inscriptions en russe.
La solution consiste à utiliser la fonction ggplot package ggplot .
Si la sortie nécessite un fichier raster standard, par exemple, au format .png, tout est assez simple:
ggsave("logging.png", width=709, height=549, units="px")
La géométrie (options width et height ) et les unités de mesure ( units ) peuvent être omises, mais par défaut, l'image sera exportée au carré, ce qui n'est guère pratique. Par conséquent, il est préférable de définir votre propre proportion et la taille requise et de définir ces paramètres manuellement, comme cela est fait dans la ligne de code ci-dessus.
Pour l'utilisation ultérieure de l'image dans des publications papier, il est raisonnable d'exporter l'image au format vectoriel, de sorte que plus tard dans la mise en page, il est possible de modifier librement la géométrie de l'image. De nombreux magazines préfèrent le format .eps - il est également pratique de l'utiliser pour l'exportation vers Word. Nous aurons besoin du pilote Cairo déjà installé et connecté:
ggsave(filename = "export.eps", width=15, height=11.6, units="cm", device = cairo_ps)
Les fichiers seront enregistrés dans le répertoire courant où se trouve le script R.
Quoi d'autre à lire
La littérature sur les graphiques en R est assez abondante. Voici quelques exemples, dont le premier est le travail de l'auteur du paquet ggplot:
Le livre le plus détaillé et le plus détaillé sur les graphiques en R en russe est probablement le livre de Timofei Samsonov. Visualisation et analyse de données géographiques en langage R. Ceci est un excellent guide détaillé de nombreux problèmes communs et spécifiques qui peuvent être résolus avec R.
Vous pouvez également recommander un livre en russe sur R en général:
Shitikov V.K., Mastitsky S.E. Classification, régression, algorithmes d'exploration de données utilisant R. 2017 .
Un exemple intéressant et motivant est une présentation puissante sur l'utilisation de ggplot2 dans la préparation de dessins pour le journal influent Financial Times .