
Au RIT 2019, notre collègue Alexander Korotkov a fait un
rapport sur l'automatisation du développement au CIAN: pour simplifier la vie et le travail, nous utilisons notre propre plateforme Integro. Il surveille le cycle de vie des tâches, supprime les opérations de routine des développeurs et réduit considérablement le nombre de bogues en production. Dans cet article, nous compléterons le rapport d'Alexander et vous expliquerons comment nous sommes passés de simples scripts à la combinaison de produits open source via notre propre plateforme et ce que fait une équipe d'automatisation distincte.
Niveau zéro
"Il n'y a pas de niveau zéro, je ne le sais pas"
Maître Shifu du film "Kung Fu Panda"L'automatisation au CIAN a commencé 14 ans après la fondation de l'entreprise. Ensuite, il y avait 35 personnes dans l'équipe de développement. Difficile à croire, non? Bien sûr, l'automatisation existait sous une certaine forme, mais un domaine distinct d'intégration continue et de livraison de code a commencé à prendre forme en 2015.
À cette époque, nous avions déployé un énorme monolithe de Python, C # et PHP sur des serveurs Linux / Windows. Pour le déploiement de ce monstre, nous avions un ensemble de scripts que nous avons exécuté manuellement. Il y avait également un assemblage monolithique, causant des douleurs et des souffrances dues aux conflits lors de la fusion des branches, de la modification des défauts et de la reconstruction "avec un ensemble de tâches différent dans la génération". Le processus simplifié ressemblait à ceci:

Cela ne nous convenait pas et nous voulions créer un processus de construction et de déploiement reproductible, automatisé et contrôlé. Pour ce faire, nous avions besoin d'un système CI / CD, et nous avons choisi entre la version gratuite de Teamcity et la Jenkins gratuite, car nous travaillions avec eux et nous convenions tous les deux pour un ensemble de fonctions. Nous avons choisi Teamcity comme produit plus récent. Ensuite, nous n'avons pas utilisé d'architecture de microservices et ne comptions pas sur un grand nombre de tâches et de projets.
Nous arrivons à l'idée de notre propre système
L'implémentation de Teamcity n'a supprimé qu'une partie du travail manuel: il y avait encore la création de Pull Request, la promotion des tâches par statut dans Jira, la sélection des tâches à publier. Teamcity ne pouvait plus faire face à cela. Il fallait choisir la voie d'une automatisation plus poussée. Nous avons envisagé des options pour travailler avec des scripts dans Teamcity ou passer à des systèmes d'automatisation tiers. Mais au final, nous avons décidé que nous avions besoin de la flexibilité maximale que seule notre propre solution offre. C'est ainsi que la première version du système d'automatisation interne appelée Integro est apparue.
Teamcity est engagé dans l'automatisation au niveau de démarrage des processus d'assemblage et de déploiement, et Integro s'est concentré sur l'automatisation de haut niveau des processus de développement. Il était nécessaire de combiner le travail avec les tâches dans Jira avec le traitement du code source associé dans Bitbucket. À ce stade, Integro a commencé à avoir ses propres workflows pour travailler avec des tâches de différents types.
En raison de l'augmentation de l'automatisation des processus métier, le nombre de projets et d'exécutions dans Teamcity a augmenté. Un nouveau problème est donc venu: une instance gratuite de Teamcity manquait (3 agents et 100 projets), nous avons ajouté une autre instance (3 agents et 100 projets supplémentaires), puis une autre. En conséquence, nous avons obtenu un système de plusieurs clusters, qui était difficile à gérer:
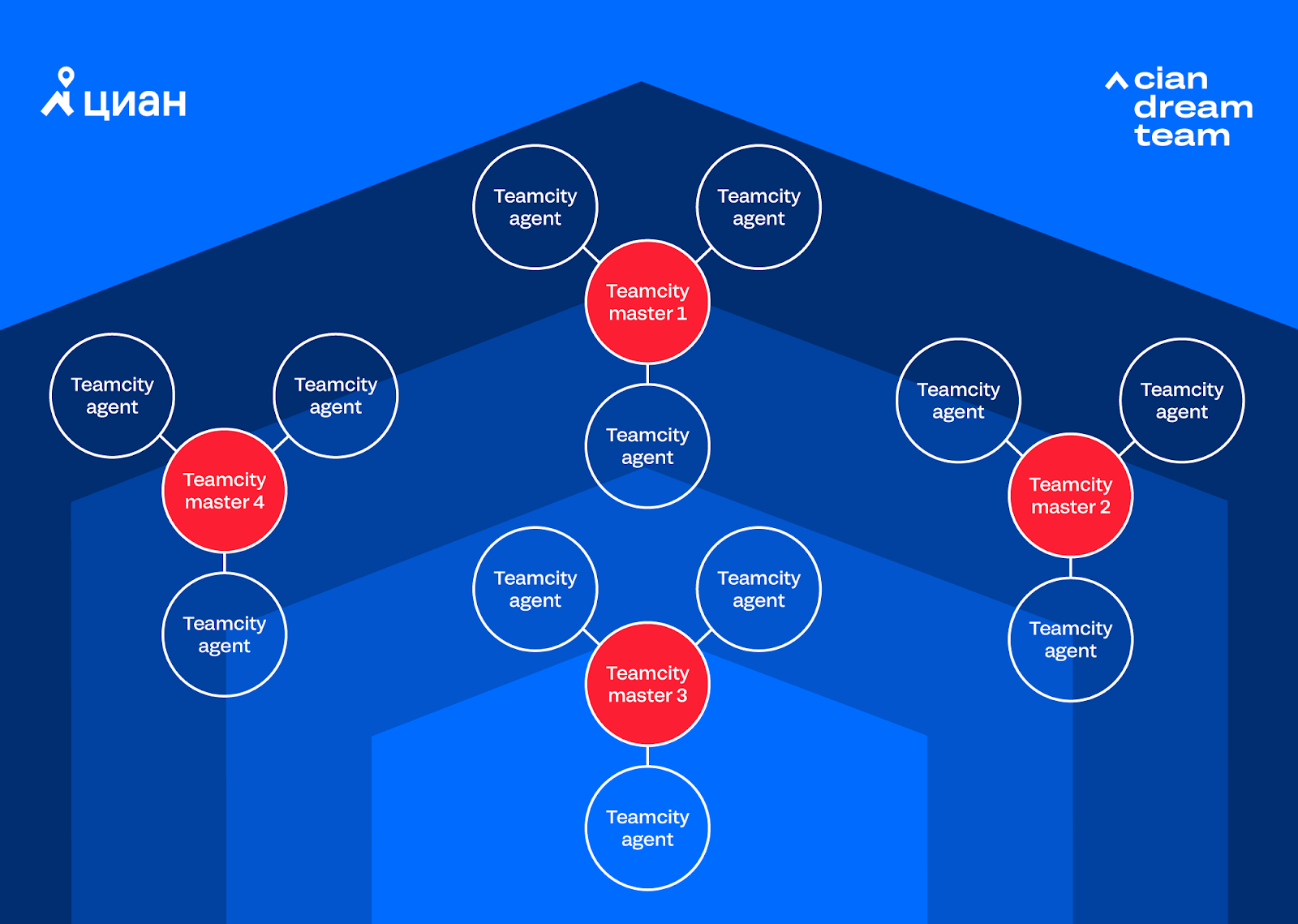
Lorsque la question s'est posée à propos de l'instance 4, nous avons réalisé que nous ne pouvions plus vivre comme ça, car le coût total de la prise en charge de 4 instances ne correspond plus à aucun cadre. La question s'est posée d'acheter un Teamcity payant ou d'opter pour un Jenkins gratuit. Nous avons effectué des calculs sur les instances et les plans d'automatisation et décidé que nous vivrions sur Jenkins. Après quelques semaines, nous sommes passés à Jenkins et nous sommes débarrassés des maux de tête associés à la prise en charge de plusieurs instances Teamcity. Par conséquent, nous avons pu nous concentrer sur le développement d'Integro et l'achèvement de Jenkins pour nous-mêmes.
Avec la croissance de l'automatisation de base (sous forme de création automatique de demandes de tirage, de collecte et de publication de la couverture du Code et d'autres vérifications), il y avait une forte volonté de refuser autant que possible les versions manuelles et de confier ce travail aux robots. En outre, la société a commencé à passer aux microservices, qui nécessitaient des versions fréquentes et séparément les uns des autres. Nous sommes donc progressivement arrivés aux versions automatiques de nos microservices (pour l'instant, nous lançons le monolithe manuellement en raison de la complexité du processus). Mais, comme cela arrive généralement, une nouvelle complexité est apparue.
Automatiser les tests
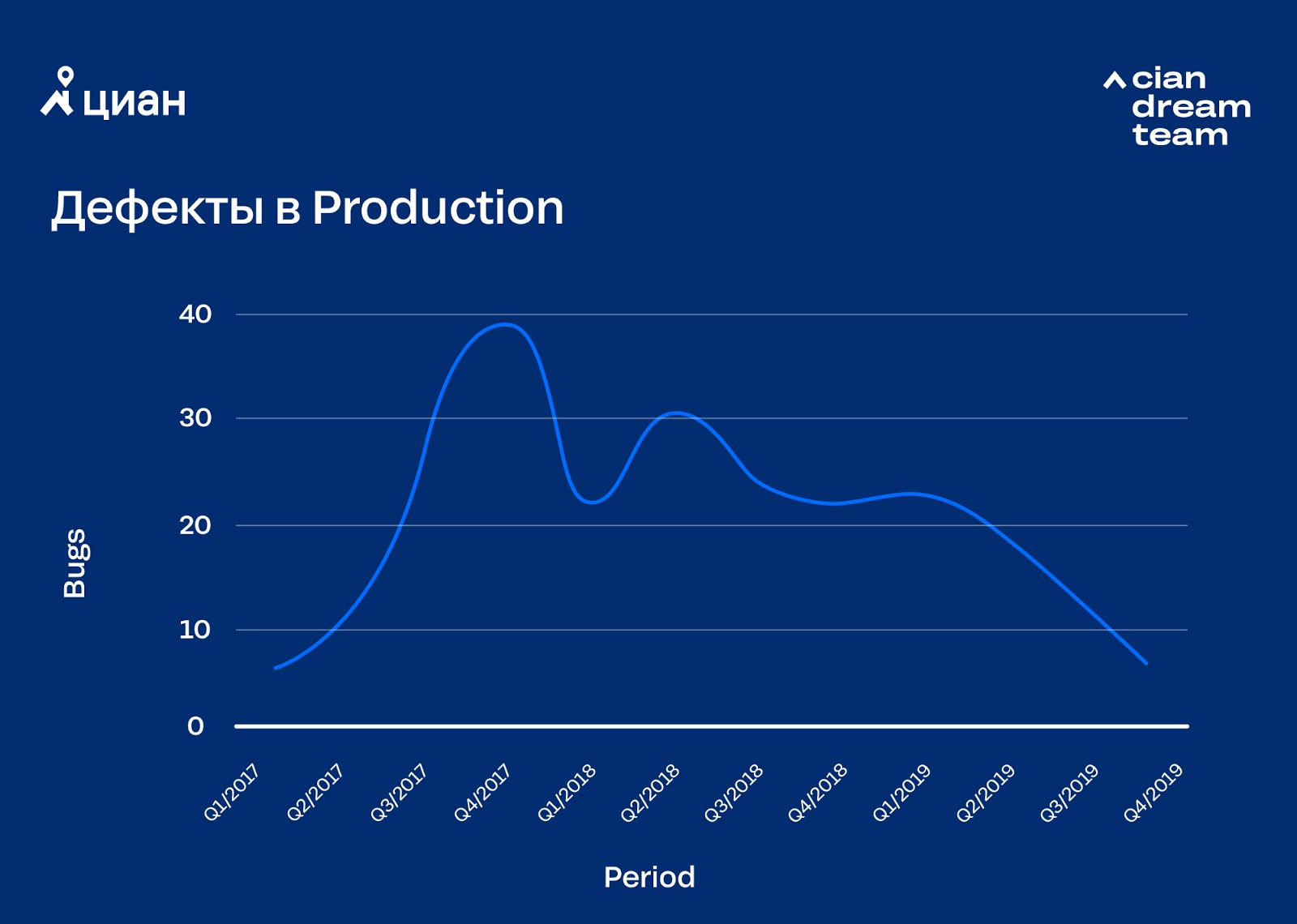
En raison de l'automatisation des versions, les processus de développement se sont accélérés, en partie à cause du saut de certaines étapes des tests. Et cela a entraîné une perte temporaire de qualité. Cela semble ringard, mais avec l'accélération des versions, il a fallu changer la méthodologie de développement des produits. Il était nécessaire de penser à tester l'automatisation, à inculquer la responsabilité personnelle (ici, nous parlons d '«accepter une idée dans la tête» plutôt que des amendes pécuniaires) du développeur pour le code publié et les bugs qu'il contient, ainsi qu'à la décision d'émettre / de ne pas émettre la tâche via un déploiement automatique.
En éliminant les problèmes de qualité, nous avons pris deux décisions importantes: nous avons commencé à effectuer des tests sur les canaris et à mettre en œuvre une surveillance automatique du fond d'erreur avec une réponse automatique à son excès. La première solution a permis de trouver des erreurs évidentes avant la mise en production complète du code, la seconde a réduit le temps de réponse aux problèmes de production. Bien sûr, des erreurs se produisent, mais nous consacrons la majeure partie de notre temps et de notre énergie non pas à la correction, mais à la minimisation.
Équipe d'automatisation
Maintenant, nous avons un effectif de 130 développeurs et nous continuons
de croître . L'équipe d'intégration continue et de livraison de code (ci-après dénommée l'équipe de déploiement et d'intégration ou DI) est composée de 7 personnes et travaille dans 2 directions: développement de la plateforme d'automatisation Integro et DevOps.
DevOps est responsable de l'environnement Dev / Beta du site Web de CIAN, l'environnement Integro, aide les développeurs à résoudre les problèmes et développe de nouvelles approches pour faire évoluer les environnements. Le secteur d'activité d'Integro traite à la fois d'Integro lui-même et des services connexes, par exemple, des plug-ins pour Jenkins, Jira, Confluence, et développe également des utilitaires et des applications auxiliaires pour les équipes de développement.
L'équipe DI travaille en collaboration avec l'équipe Platform, qui développe des architectures, des bibliothèques et des approches de développement au sein de l'entreprise. Dans le même temps, tout développeur à l'intérieur du CIAN peut contribuer à l'automatisation, par exemple, faire de la microautomatisation aux besoins de l'équipe ou partager une idée sympa comment rendre l'automatisation encore meilleure.
Automatisation de Puff Pie en cyan
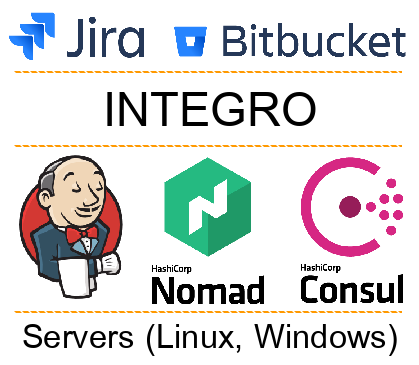
Tous les systèmes impliqués dans l'automatisation peuvent être divisés en plusieurs couches:
- Systèmes externes (Jira, Bitbucket, etc.). Les équipes de développement travaillent avec elles.
- Platform Integro. Le plus souvent, les développeurs ne travaillent pas directement avec elle, mais c'est elle qui prend en charge le travail de toute automatisation.
- Services de livraison, d'orchestration et de découverte (par exemple Jeknins, Consul, Nomad). Avec leur aide, nous déployons le code sur les serveurs et fournissons les services entre eux.
- Couche physique (serveur, OS, logiciels associés). A ce niveau, notre code fonctionne. Il peut s'agir d'un serveur physique ou virtuel (LXC, KVM, Docker).
Sur la base de ce concept, nous divisons les domaines de responsabilité au sein de l'équipe DI. Les deux premiers niveaux sont dans le domaine de responsabilité de la zone de développement d'Integro, et les deux derniers niveaux sont déjà dans le domaine de responsabilité de DevOps. Cette séparation vous permet de vous concentrer sur les tâches et n'interfère pas avec l'interaction, car nous sommes côte à côte et échangeons constamment des connaissances et des expériences.
Integro
Concentrons-nous sur Integro et commençons par la pile technologique:
- CentOs 7
- Docker + Nomade + Consul + Vault
- Java 11 (l'ancien monolithe Integro restera en Java 8)
- Spring Boot 2.X + Spring Cloud Config
- PostgreSql 11
- Rabbitmq
- Apache s'enflammer
- Camunda (intégré)
- Grafana + Graphite + Prométhée + Jaeger + ELK
- Interface utilisateur Web: React (CSR) + MobX
- SSO: Keycloak
Nous adhérons au principe du développement de microservices, bien que nous ayons un héritage sous la forme d'un monolithe de la version antérieure d'Integro. Chaque microservice tourne dans son conteneur Docker, les services communiquent entre eux via des requêtes HTTP et des messages RabbitMQ. Les microservices se trouvent via Consul et lui exécutent une demande, en passant l'autorisation via SSO (Keycloak, OAuth 2 / OpenID Connect).

Comme exemple réel, considérons l'interaction avec Jenkins, qui comprend les étapes suivantes:
- Le microservice de gestion des workflows (ci-après dénommé le microservice Flow) souhaite exécuter l'assembly dans Jenkins. Pour ce faire, il trouve via Consul IP: PORT l'intégration du microservice avec Jenkins (ci-après microservice Jenkins) et lui envoie une demande asynchrone pour démarrer l'assemblage dans Jenkins.
- Le microservice Jenkins, à réception de la demande, génère et restitue le Job ID, grâce auquel il sera alors possible d'identifier le résultat du travail. Parallèlement à cela, il démarre la génération dans Jenkins via un appel à l'API REST.
- Jenkins construit et, une fois terminé, envoie un webhook avec les résultats au microservice Jenkins.
- Un microservice Jenkins, ayant reçu un webhook, génère un message sur l'achèvement du traitement de la demande et y joint les résultats de l'exécution. Le message généré est envoyé à la file d'attente RabbitMQ.
- Par le biais de RabbitMQ, le message publié parvient au microservice Flow, qui apprend le résultat du traitement de sa tâche en faisant correspondre l'ID de tâche de la demande et le message reçu.
Nous avons maintenant environ 30 microservices qui peuvent être divisés en plusieurs groupes:
- Gestion de la configuration.
- Informer et interagir avec les utilisateurs (messageries instantanées, courrier).
- Travaillez avec le code source.
- Intégration avec les outils de déploiement (jenkins, nomade, consul, etc.).
- Surveillance (versions, bugs, etc.).
- Utilitaires Web (interface utilisateur pour gérer les environnements de test, collecter des statistiques, etc.).
- Intégration avec les trackers de tâches et les systèmes similaires.
- Gérez le flux de travail pour différentes tâches.
Tâches de workflow
Integro automatise les activités liées au cycle de vie des tâches. Simplifié par le cycle de vie d'une tâche, nous entendons le flux de travail d'une tâche dans Jira. Dans nos processus de développement, il existe plusieurs variantes de workflow en fonction du projet, du type de tâche et des options sélectionnées dans une tâche particulière.
Considérez le flux de travail que nous utilisons le plus souvent:
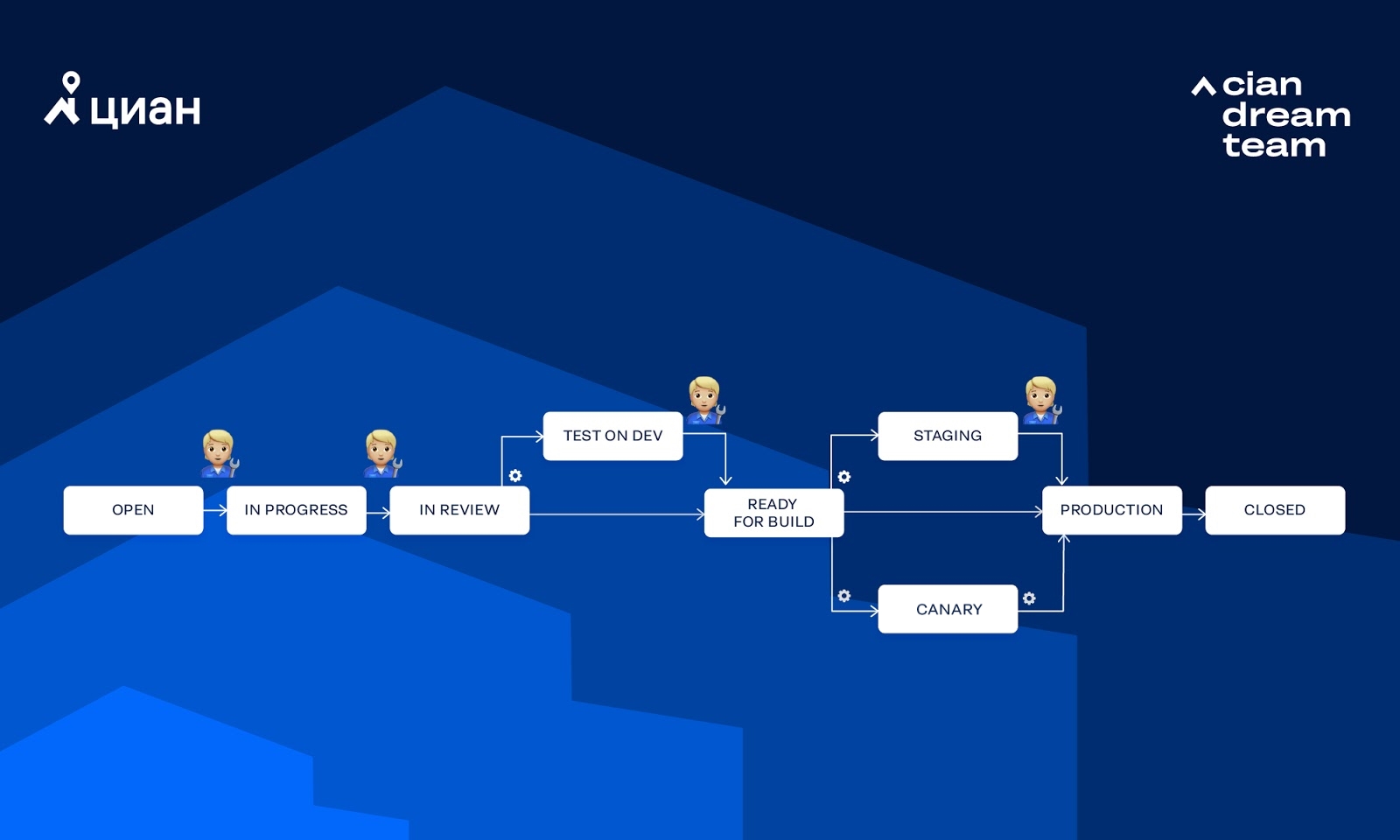
Dans le diagramme, l'engrenage indique que la transition est appelée automatiquement par Integro, tandis que la figure humaine signifie que la transition est appelée manuellement par la personne. Examinons quelques façons dont une tâche peut passer par ce flux de travail.
Test entièrement manuel pour DEV + BETA sans tests canaris (généralement nous publions un monolithe):
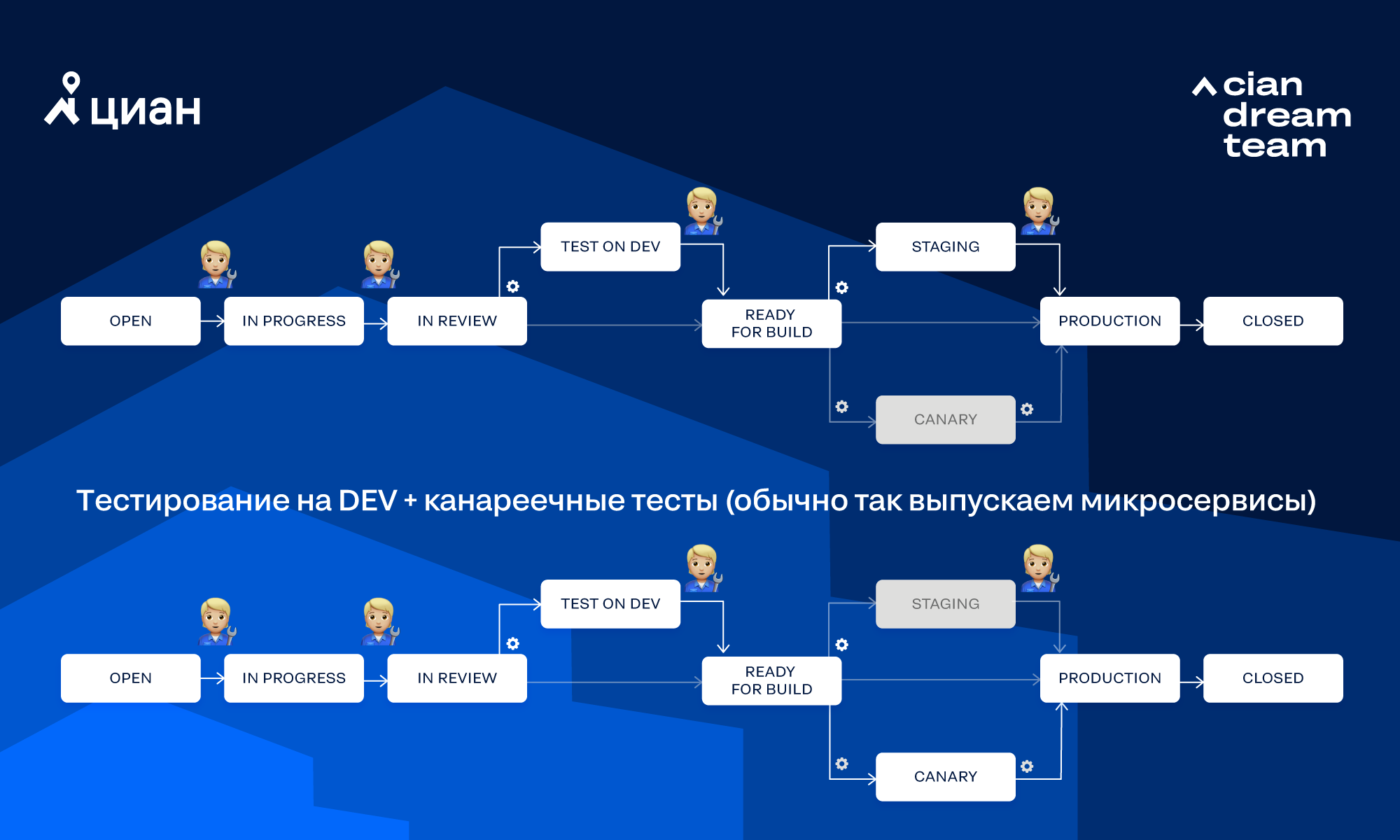
Il peut y avoir d'autres combinaisons de transition. Parfois, le chemin que prendra la tâche peut être sélectionné via les options de Jira.
Mouvement de tâche
Considérez les étapes de base qui sont effectuées lors du déplacement de la tâche sur le flux de travail "Test des tests canaries DEV +":
1. Le développeur ou le PM crée la tâche.
2. Le développeur prend la tâche au travail. À la fin, le transfère au statut EN RÉVISION.
3. Jira envoie Webhook vers le microservice Jira (est responsable de l'intégration avec Jira).
4. Le microservice Jira envoie une demande au service Flow (il est responsable des workflows internes dans lesquels le travail est effectué) pour démarrer le workflow.
5. À l'intérieur du service Flow:
- Les relecteurs de la tâche sont affectés (Utilisateurs-microservice qui sait tout sur les utilisateurs + Jira-microservice).
- Grâce au microservice Source (il connaît les référentiels et les branches, mais ne fonctionne pas avec le code lui-même), il recherche les référentiels dans lesquels il existe une branche de notre tâche (pour simplifier la recherche, le nom de la branche correspond au numéro de tâche dans Jira). Le plus souvent, la tâche ne comporte qu'une seule branche dans un référentiel, ce qui simplifie la gestion de la file d'attente au déploiement et réduit la connectivité entre les référentiels.
- Pour chaque branche trouvée, la séquence d'actions suivante est effectuée:
i) Alimenter la branche master (microservice Git pour travailler avec du code).
ii) La branche est bloquée des modifications par le développeur (microservice Bitbucket).
iii) Une demande d'extraction est créée sur cette branche (microservice Bitbucket).
iv) Un message concernant la nouvelle demande Pull est envoyé aux chats du développeur (notifiez le microservice pour travailler avec les notifications).
v) Créez, testez et déployez des tâches sur DEV (microservice Jenkins pour travailler avec Jenkins).
vi) Si tous les paragraphes précédents ont été complétés avec succès, alors Integro met son approbation dans la demande d'extraction (microservice Bitbucket). - Integro attend une approbation de demande d'extraction des réviseurs désignés.
- Dès que tous les approbations nécessaires ont été reçus (y compris les tests automatisés réussis), Integro transfère la tâche au statut Test on Dev (microservice Jira).
6. Les testeurs testent la tâche. S'il n'y a aucun problème, ils transfèrent la tâche à l'état Prêt pour la construction.
7. Integro «voit» que la tâche est prête à être libérée et lance son déploiement en mode canari (microservice Jenkins). La préparation à la libération est déterminée par un ensemble de règles. Par exemple, une tâche dans le bon état, il n'y a pas de verrous sur d'autres tâches, maintenant il n'y a plus de calculs actifs de ce microservice, etc.
8. La tâche est transférée au statut de Canaries (Jira-microservice).
9. Jenkins démarre via Nomad un déploiement de tâches en mode canari (généralement 1 à 3 instances) et notifie le service de surveillance des versions (microservice DeployWatch) du calcul.
10. DeployWatch-microservice collecte les erreurs d'arrière-plan et y répond si nécessaire. Si l'erreur d'arrière-plan est dépassée (le taux d'arrière-plan est calculé automatiquement), les développeurs sont avertis via le microservice Notify. Si après 5 minutes le développeur n'a pas répondu (cliqué sur Revert ou Stay), la restauration automatique des instances canaries démarre. Si l'arrière-plan n'est pas dépassé, le développeur doit lancer manuellement le déploiement de la tâche en production (en appuyant sur le bouton dans l'interface utilisateur). Si, dans un délai de 60 minutes, le développeur n'a pas lancé de déploiement en production, les instances canaries seront également pompées pour des raisons de sécurité.
11. Après avoir lancé le déploiement en production:
- La tâche est transférée au statut Production (microservice Jira).
- Le microservice Jenkins démarre le processus de déploiement et notifie le déploiement du microservice DeployWatch.
- DeployWatch-microservice vérifie que tous les conteneurs ont été mis à jour sur Production (dans certains cas, ils n'ont pas tous été mis à jour).
- Une notification concernant les résultats du déploiement en production est envoyée via le microservice Notify.
12. Les développeurs auront 30 minutes pour démarrer la restauration de la tâche avec Production en cas de détection d'un comportement incorrect du microservice. Passé ce délai, la tâche sera automatiquement versée dans le maître (Git-microservice).
13. Après une fusion réussie dans master, le statut de la tâche sera changé en Closed (microservice Jira).
Le schéma ne prétend pas être complètement détaillé (en réalité, il y a encore plus d'étapes), mais il permet d'évaluer le degré d'intégration dans les processus. Nous ne considérons pas ce schéma comme idéal et améliorons les processus de suivi automatique des versions et des déploiements.
Et ensuite
Nous avons de grands projets pour le développement de l'automatisation, par exemple, le rejet des opérations manuelles lors des versions monolithiques, l'amélioration de la surveillance lors du déploiement automatique, l'amélioration de l'interaction avec les développeurs.
Mais pour l'instant, arrêtons-nous à cet endroit. Nous avons couvert superficiellement de nombreux sujets lors de la revue de l'automatisation, certains n'y ont pas du tout répondu, nous serons donc heureux de répondre aux questions. Nous attendons des suggestions sur ce qu'il faut couvrir en détail, écrivez dans les commentaires.