Bonjour, Habr! Je vous présente la traduction de l'article "Visualiser un modèle de traduction automatique neuronal (Mécanique des modèles Seq2seq avec attention)" de Jay Alammar.
Les modèles de séquence à séquence (seq2seq) sont des modèles d'apprentissage en profondeur qui ont connu un grand succès dans des tâches telles que la traduction automatique, le résumé de texte, l'annotation d'images, etc.Par exemple, fin 2016, un modèle similaire a été intégré à Google Translate. Les fondements des modèles seq2seq ont été jetés en 2014 avec la publication de deux articles - Sutskever et al., 2014 , Cho et al., 2014 .
Afin de comprendre et d'utiliser suffisamment ces modèles, certains concepts doivent d'abord être clarifiés. Les visualisations proposées dans cet article seront un bon complément aux articles mentionnés ci-dessus.
Le modèle séquence à séquence est un modèle qui accepte une séquence d'éléments en entrée (mots, lettres, attributs d'image, etc.) et renvoie une autre séquence d'éléments. Le modèle formé fonctionne comme suit:
En traduction automatique neuronale, une séquence d'éléments est un ensemble de mots qui sont traités à leur tour. La conclusion est également un ensemble de mots:
Jetez un œil sous le capot
Sous le capot, le modèle dispose d'un encodeur et d'un décodeur.
Le codeur traite chaque élément de la séquence d'entrée, traduit les informations reçues en un vecteur appelé contexte. Après avoir traité toute la séquence d'entrée, le codeur envoie le contexte au décodeur, qui commence alors à générer la séquence de sortie élément par élément.
La même chose se produit avec la traduction automatique.
Pour la traduction automatique, le contexte est un vecteur (un tableau de nombres), et l'encodeur et le décodeur, à leur tour, sont le plus souvent des réseaux de neurones récurrents (voir l'introduction de RNN - Une introduction conviviale aux réseaux de neurones récurrents ).

Le contexte est un vecteur de nombres à virgule flottante. Plus loin dans l'article, les vecteurs seront visualisés en couleur de sorte que la couleur plus claire correspond aux cellules avec de grandes valeurs.
Lors de la formation du modèle, vous pouvez définir la taille du vecteur de contexte - le nombre de neurones cachés (unités cachées) dans l'encodeur RNN. Les données de visualisation montrent un vecteur à 4 dimensions, mais dans des applications réelles, le vecteur de contexte aura une dimension de l'ordre de 256, 512 ou 1024.
Par défaut, à chaque intervalle de temps, RNN reçoit deux éléments en entrée: l'élément d'entrée lui-même (dans le cas d'un codeur, un mot de la phrase d'origine) et l'état caché. Le mot, cependant, doit être représenté par un vecteur. Pour convertir un mot en vecteur, ils ont recours à une série d'algorithmes appelés plongements de mots. Les intégrations traduisent les mots en espaces vectoriels contenant des informations sémantiques et sémantiques à leur sujet (par exemple, «roi» - «homme» + «femme» = «reine» ).
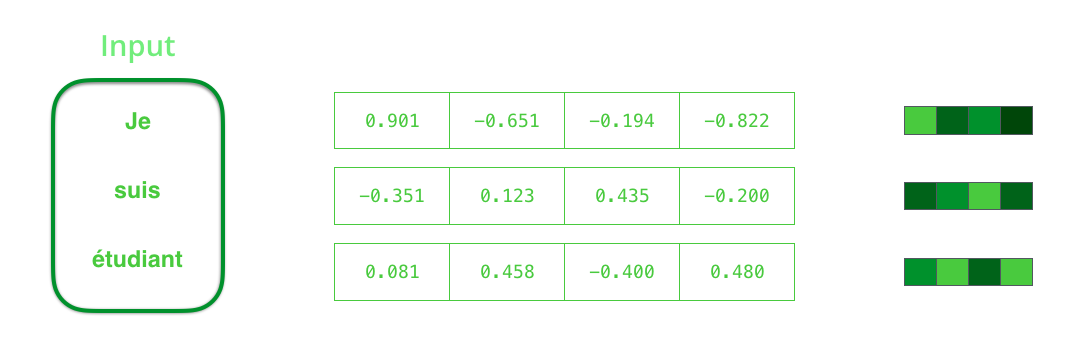
Avant de traiter des mots, vous devez les convertir en vecteurs. Cette transformation est effectuée à l'aide de l'algorithme d'intégration de mots. Vous pouvez utiliser à la fois des intégrations pré-formées et des intégrations de train sur votre ensemble de données. 200-300 - dimension typique du vecteur d'intégration; cet article utilise la dimension 4 pour plus de simplicité.
Maintenant que nous avons pris connaissance de nos principaux vecteurs / tenseurs, rappelons le mécanisme de RNN et créons des visualisations pour le décrire:
Dans l'étape suivante, RNN prend le deuxième vecteur d'entrée et l'état latent # 1 pour former la sortie à cet intervalle de temps. Plus loin dans l'article, une animation similaire est utilisée pour décrire les vecteurs à l'intérieur d'un modèle de traduction automatique neuronale.
Dans la visualisation suivante, chaque trame décrit le traitement des entrées par un codeur et la génération des sorties par un décodeur dans un intervalle de temps. Étant donné que le codeur et le décodeur sont tous deux RNN, à chaque intervalle de temps, le réseau neuronal est occupé à traiter et à mettre à jour ses états cachés sur la base des entrées actuelles et précédentes. Dans ce cas, le dernier des états cachés du codeur est le contexte même qui est transmis au décodeur.
Le décodeur contient également des états cachés qu'il transfère d'un intervalle de temps à un autre. (Ce n'est pas dans la visualisation, représentant uniquement les principales parties du modèle.)
Nous nous tournons maintenant vers un autre type de visualisation de modèles de séquence à séquence. Cette animation aidera à comprendre les graphiques statiques qui décrivent ces modèles - les soi-disant une vue déroulée, où au lieu d'afficher un décodeur, nous en montrons une copie pour chaque intervalle de temps. Nous pouvons donc regarder les éléments d'entrée et de sortie à chaque intervalle de temps.
Faites attention!
Le vecteur de contexte est un goulot d'étranglement pour ce type de modèle, ce qui rend difficile pour eux de faire face à de longues phrases. La solution a été proposée dans des articles de Bahdanau et al., 2014 et Luong et al., 2015 , qui présentaient une technique appelée mécanisme d'attention. Ce mécanisme améliore considérablement la qualité des systèmes de traduction automatique, permettant aux modèles de se concentrer sur les parties pertinentes des séquences d'entrée.
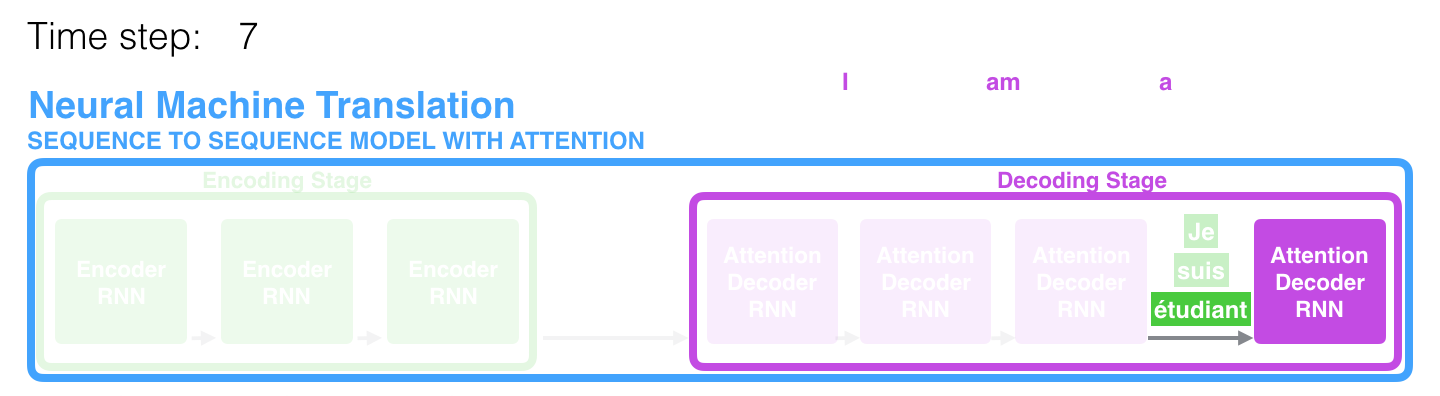
Dans le 7ème laps de temps, le mécanisme d'attention permet au décodeur de se concentrer sur le mot étudiant (étudiant en français) avant de générer une traduction en anglais. Cette capacité à amplifier le signal de la partie pertinente de la séquence d'entrée permet aux modèles basés sur le mécanisme d'attention d'obtenir un meilleur résultat par rapport aux autres modèles.
Lorsque l'on considère un modèle avec un mécanisme d'attention à un niveau d'abstraction élevé, on peut distinguer deux différences principales par rapport au modèle classique de séquence à séquence.
Premièrement, le codeur transfère beaucoup plus de données au décodeur: au lieu de transmettre uniquement le dernier état caché après la phase de codage, le codeur lui envoie tous ses états cachés:
Deuxièmement, le décodeur passe par une étape supplémentaire avant de générer la sortie. Afin de se concentrer sur les parties de la séquence d'entrée qui sont pertinentes pour la période de temps correspondante, le décodeur effectue les opérations suivantes:
- Examine un ensemble d'états latents reçus d'un codeur - chacun des états latents correspond le mieux à l'un des mots de la séquence d'entrée;
- Attribue une certaine évaluation à chaque état latent (omettons pour l'instant comment se déroule la procédure d'estimation);
- Multiplie chaque état caché par une estimation convertie par la fonction softmax, mettant ainsi en surbrillance les états cachés avec une note élevée et reléguant les états cachés avec une petite note.
Cet «exercice de gradation» est effectué au niveau du décodeur à chaque intervalle de temps.
Donc, résumant tout ce qui précède, nous considérons le processus du modèle avec le mécanisme d'attention:
- Au niveau du décodeur, le RNN reçoit l'incorporation <END> du jeton et l'état caché initial.
- Le RNN traite l'élément d'entrée, génère la sortie et un nouveau vecteur d'état caché (h4). La sortie est ignorée.
- Le mécanisme d'attention utilise les états cachés du codeur et le vecteur h4 pour calculer le vecteur de contexte (C4) à un intervalle de temps donné.
- Les vecteurs h4 et C4 sont concaténés en un seul vecteur.
- Ce vecteur passe à travers un réseau neuronal à action directe (FFN), formé avec le modèle.
- La sortie du réseau FFN indique le mot de sortie à un intervalle de temps donné.
- L'algorithme est répété pour l'intervalle de temps suivant.
Une autre façon de voir quelle partie de la phrase originale le modèle se concentre à chaque étape du décodeur:
Notez que le modèle ne connecte pas simplement sans réfléchir le premier mot de l'entrée avec le premier mot de la sortie. Elle a en fait compris au cours du processus de formation comment faire correspondre les mots de cette paire de langues considérée (dans notre cas, le français et l'anglais). Un exemple de la précision avec laquelle ce mécanisme peut fonctionner peut être trouvé dans les articles sur le mécanisme d'attention mentionnés ci-dessus.

Si vous sentez que vous êtes prêt à apprendre comment appliquer ce modèle, reportez-vous au manuel Neural Machine Translation (seq2seq) sur TensorFlow.
Les auteurs