विज्ञान पढ़ने से विज्ञान को कैसे लाभ हो सकता है?
पिछली बार हमने हबीब पर भाषाई डेटा की भीड़-भाड़ के बारे में लिखा था । यह रूसी में आधुनिक ग्रंथों के रूपात्मक मार्कअप (भाषण टैगिंग का हिस्सा) के बारे में था। तब से, लगभग 2.2 मिलियन कार्यों को चिह्नित किया गया है, और लगभग 3 हजार लोगों ने इसमें भाग लिया है। हम आधे से ज्यादा रास्ते से चले हैं। हमें मदद करने के लिए धन्यवाद!OpenCorpora में, हम रूसी में पाठ विश्लेषण के गणितीय मॉडल के प्रशिक्षण और परीक्षण के लिए खुला डेटा बनाते हैं। इस प्रकार, हम रूसी कंप्यूटर भाषा विज्ञान को पश्चिमी के साथ पकड़ने में मदद करते हैं। फिर हम आगे निकलने में मदद करेंगे;)आज हम नामित संस्थाओं के मार्कअप के बारे में बात करेंगे। यह ओपन एनक्लोजर में टेक्स्ट मार्कअप की एक और परत है। हम पाठ में लोगों के नाम, कंपनियों के नाम और भौगोलिक वस्तुओं पर प्रकाश डालेंगे। हम ऐसा क्यों कर रहे हैं?हमने रूपात्मक अंकन शुरू किया और अपनी पहल पर जारी है। हम factRuEval-2016 प्रतियोगिता की आयोजन समिति के साथ मिलकर इकाई मार्कअप पर काम कर रहे हैं , जिसे कंप्यूटर भाषा विज्ञान पर डायलॉग -21 सम्मेलन के हिस्से के रूप में आयोजित किया जाएगा । इस स्तर पर, संस्थाओं को पूरे भवन में चिह्नित नहीं किया जाता है, लेकिन केवल इसके एक छोटे उपसमुच्चय में, जो प्रतियोगिता के प्रतिभागियों के लिए प्रशिक्षण और परीक्षण संग्रह बन जाएगा। कुल मिलाकर, यह 3-4 पैराग्राफ की मात्रा में लगभग 1000 समाचार ग्रंथ हैं। हमेशा की तरह, मार्कअप परिणाम एक क्रिएटिव कॉमन्स लाइसेंस के तहत प्रकाशित किया जाएगा। संग्रह का प्रशिक्षण भाग प्रकाशित होने के साथ ही प्रकाशित हो जाएगा, और परीक्षण भाग का मार्कअप प्रतियोगिता के अंत और उसके परिणामों से पहले प्रकाशित नहीं किया जाएगा।नामित संस्थाओं का मार्कअप क्या है?पाठ से नामित संस्थाओं को निकालना पाठ विश्लेषिकी के मांग-बाद के कार्यों में से एक है (इसे विस्तार से देखें, उदाहरण के लिए, Textocat ब्लॉग में )।यह अच्छा होगा यदि कई दर्जन प्रतिस्पर्धी समाधान थे जो पाठ में उल्लिखित सभी वस्तुओं को सूचीबद्ध करेंगे, उनके सामान्यीकृत नाम और संबंधित वस्तु पहचानकर्ता देंगे। और यह सब रूसी भाषा और खुले स्रोत के लिए। FactRuEval प्रतियोगिता के संगठन में भाग लेना और इसके लिए डेटा तैयार करना, हम इस दिशा में एक कदम उठाते हैं और आपको इसमें शामिल होने के लिए आमंत्रित करते हैं।संक्षेप में, नामित संस्थाओं का चयन ग्रंथों (व्यक्तियों के पूर्ण नाम, संगठनों और भौगोलिक वस्तुओं के नाम) में उचित नाम खोजने, उन्हें उजागर करने और उन्हें उपयुक्त टैग के साथ चिह्नित करने में होता है। उदाहरण के लिए, व्यक्तियों के लिए उपनाम, नाम और पेट्रोनामिक को अलग से नोट करना आवश्यक है, और फिर चयनित सेगमेंट को एक प्रकार की व्यक्ति की वस्तु के संदर्भ में संयोजित करें। हमने इस बारे में विस्तृत निर्देश लिखे और एक छोटा सा वीडियो रिकॉर्ड किया ।
हम ऐसा क्यों कर रहे हैं?हमने रूपात्मक अंकन शुरू किया और अपनी पहल पर जारी है। हम factRuEval-2016 प्रतियोगिता की आयोजन समिति के साथ मिलकर इकाई मार्कअप पर काम कर रहे हैं , जिसे कंप्यूटर भाषा विज्ञान पर डायलॉग -21 सम्मेलन के हिस्से के रूप में आयोजित किया जाएगा । इस स्तर पर, संस्थाओं को पूरे भवन में चिह्नित नहीं किया जाता है, लेकिन केवल इसके एक छोटे उपसमुच्चय में, जो प्रतियोगिता के प्रतिभागियों के लिए प्रशिक्षण और परीक्षण संग्रह बन जाएगा। कुल मिलाकर, यह 3-4 पैराग्राफ की मात्रा में लगभग 1000 समाचार ग्रंथ हैं। हमेशा की तरह, मार्कअप परिणाम एक क्रिएटिव कॉमन्स लाइसेंस के तहत प्रकाशित किया जाएगा। संग्रह का प्रशिक्षण भाग प्रकाशित होने के साथ ही प्रकाशित हो जाएगा, और परीक्षण भाग का मार्कअप प्रतियोगिता के अंत और उसके परिणामों से पहले प्रकाशित नहीं किया जाएगा।नामित संस्थाओं का मार्कअप क्या है?पाठ से नामित संस्थाओं को निकालना पाठ विश्लेषिकी के मांग-बाद के कार्यों में से एक है (इसे विस्तार से देखें, उदाहरण के लिए, Textocat ब्लॉग में )।यह अच्छा होगा यदि कई दर्जन प्रतिस्पर्धी समाधान थे जो पाठ में उल्लिखित सभी वस्तुओं को सूचीबद्ध करेंगे, उनके सामान्यीकृत नाम और संबंधित वस्तु पहचानकर्ता देंगे। और यह सब रूसी भाषा और खुले स्रोत के लिए। FactRuEval प्रतियोगिता के संगठन में भाग लेना और इसके लिए डेटा तैयार करना, हम इस दिशा में एक कदम उठाते हैं और आपको इसमें शामिल होने के लिए आमंत्रित करते हैं।संक्षेप में, नामित संस्थाओं का चयन ग्रंथों (व्यक्तियों के पूर्ण नाम, संगठनों और भौगोलिक वस्तुओं के नाम) में उचित नाम खोजने, उन्हें उजागर करने और उन्हें उपयुक्त टैग के साथ चिह्नित करने में होता है। उदाहरण के लिए, व्यक्तियों के लिए उपनाम, नाम और पेट्रोनामिक को अलग से नोट करना आवश्यक है, और फिर चयनित सेगमेंट को एक प्रकार की व्यक्ति की वस्तु के संदर्भ में संयोजित करें। हमने इस बारे में विस्तृत निर्देश लिखे और एक छोटा सा वीडियो रिकॉर्ड किया । आगे क्या होगा?अंकन संस्थाएँ पहले से ही चल रही हैं। FactRuEval के लिए ग्रंथों के संग्रह को चिह्नित करने के अगले चरण में आपस में वस्तुओं के संदर्भ की पहचान होगी, विकीडाटा के साथ उनका जुड़ावऔर तथ्यों का मार्कअप। पहले दो बिंदुओं का अर्थ है कि वास्तविक दुनिया के एक ही वस्तु के पाठ में कई अलग-अलग संदर्भ (उदाहरण के लिए, इवानोव इवान, इवानोव और इवानोव द्वितीय) को एक इकाई में एक दूसरे के साथ जोड़ा जाएगा। इस इकाई के लिए WikiData से एक पहचानकर्ता निर्दिष्ट किया जाएगा।
आगे क्या होगा?अंकन संस्थाएँ पहले से ही चल रही हैं। FactRuEval के लिए ग्रंथों के संग्रह को चिह्नित करने के अगले चरण में आपस में वस्तुओं के संदर्भ की पहचान होगी, विकीडाटा के साथ उनका जुड़ावऔर तथ्यों का मार्कअप। पहले दो बिंदुओं का अर्थ है कि वास्तविक दुनिया के एक ही वस्तु के पाठ में कई अलग-अलग संदर्भ (उदाहरण के लिए, इवानोव इवान, इवानोव और इवानोव द्वितीय) को एक इकाई में एक दूसरे के साथ जोड़ा जाएगा। इस इकाई के लिए WikiData से एक पहचानकर्ता निर्दिष्ट किया जाएगा।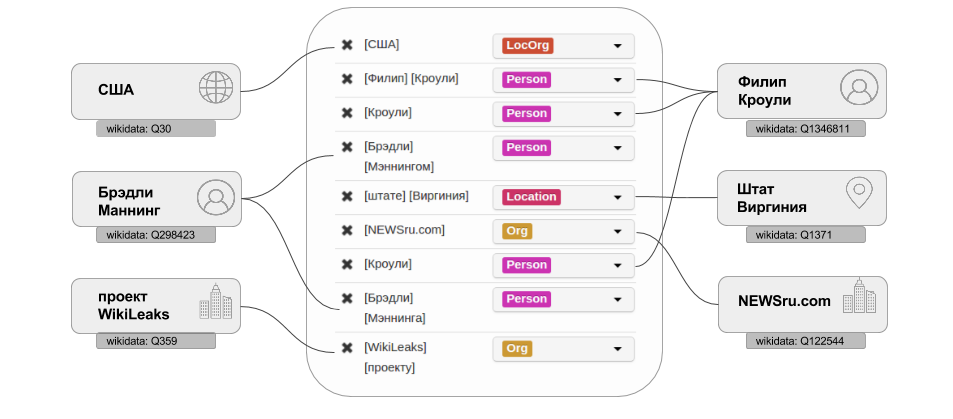 तथ्यों से हमारा तात्पर्य पिछले चरणों में पहले से उजागर की गई वस्तुओं के बीच पाठ में वर्णित संबंधों से है: व्यक्ति और संगठन के बीच संबंध संबंध (कंपनी में काम), व्यक्ति और संगठन के बीच स्वामित्व संबंध और अन्य समान संबंध।
तथ्यों से हमारा तात्पर्य पिछले चरणों में पहले से उजागर की गई वस्तुओं के बीच पाठ में वर्णित संबंधों से है: व्यक्ति और संगठन के बीच संबंध संबंध (कंपनी में काम), व्यक्ति और संगठन के बीच स्वामित्व संबंध और अन्य समान संबंध।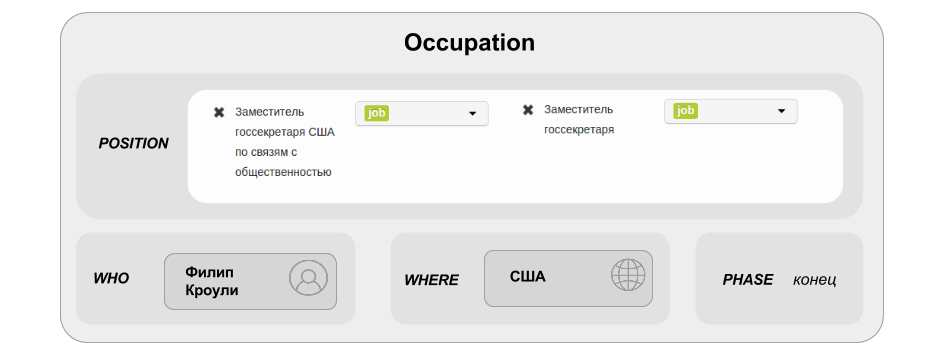 हमारी मदद कैसे करें?1. मार्कअप में भाग लें।अब हमारे पास काम के दो क्षेत्र हैं: नामित संस्थाएं और आकारिकी। दोनों दिशाओं में कार्यों को पूरा करने के लिए, बस निर्देशों को पढ़ें।2. सोशल नेटवर्क पर इस काम के बारे में लिखें और अपने दोस्तों से हमारी मदद करने को कहें।हर कोई GeekTimes नहीं पढ़ता है, लेकिन कई लोग थोड़ी मदद करने को तैयार हैं।अपडेट: इकाई मार्कअप का सीधा लिंक: http://opencorpora.org/ner.php (यह निर्देशों में है, इसे यहां भी रहने दें)।
हमारी मदद कैसे करें?1. मार्कअप में भाग लें।अब हमारे पास काम के दो क्षेत्र हैं: नामित संस्थाएं और आकारिकी। दोनों दिशाओं में कार्यों को पूरा करने के लिए, बस निर्देशों को पढ़ें।2. सोशल नेटवर्क पर इस काम के बारे में लिखें और अपने दोस्तों से हमारी मदद करने को कहें।हर कोई GeekTimes नहीं पढ़ता है, लेकिन कई लोग थोड़ी मदद करने को तैयार हैं।अपडेट: इकाई मार्कअप का सीधा लिंक: http://opencorpora.org/ner.php (यह निर्देशों में है, इसे यहां भी रहने दें)। Source: https://habr.com/ru/post/hi388061/
All Articles