नीदरलैंड के वैज्ञानिकों ने पुष्टि की है: डीएनए में एक दूसरी सूचना परत मौजूद है
हमारे शरीर की हर कोशिका में स्थित डीएनए अणु में परिभाषित आधारों का क्रम हमें आपके साथ वैसा ही बनाता है जैसा हम हैं। एक ही समय में, कई वैज्ञानिक "वैकल्पिक" छिपी हुई भाषा के अस्तित्व की संभावना और संभावना का अध्ययन कर रहे हैं, जो जीनोम की महत्वपूर्ण जानकारी को एक अलग तरीके से और एक अलग स्तर पर भी एन्कोड करता है। यह एन्कोडेड जानकारी एक तरह की गाइड टू एक्शन के रूप में काम करना चाहिए, जिसके उपयोग से हमारे शरीर की कोशिकाएँ सूचना के मुख्य शरीर को एक कड़ाई से परिभाषित अनुक्रम में पहचानने और संसाधित करने में सक्षम हैं।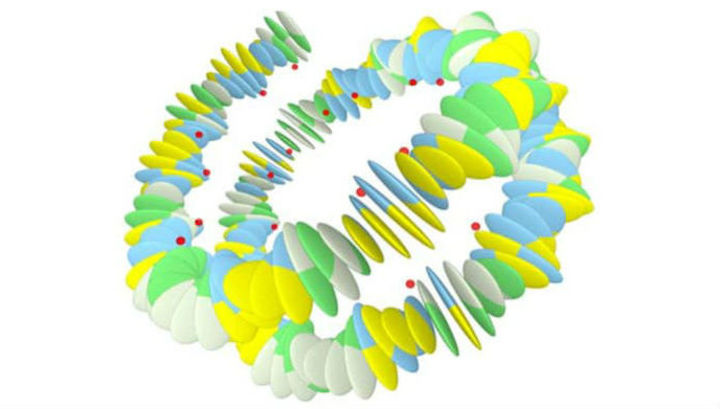 7 जून 2016 को, नीदरलैंड के वैज्ञानिकों के एक समूह का काम जो हमारे डीएनए में एक दूसरी छिपी हुई जानकारी परत के अस्तित्व को साबित करने में कामयाब रहा , वैज्ञानिक प्रकाशन पत्रिकाओं के पृष्ठ पर प्रकाशित हुआ था । ppl.org ।डीएनए प्रोटीन की संरचना को कैसे एनकोड करता हैजैसा कि आप जानते हैं, डीएनए की नींव ब्रह्मांड के निर्माण खंड हैं जो हमारे ग्रह पर सभी जीवन के अस्तित्व और प्रजनन की बहुत संभावना निर्धारित करते हैं। डीएनए अणु में "ए", "टी", "सी" और "जी" अक्षरों द्वारा निरूपित चार प्रकार के नाइट्रोजन युक्त न्यूक्लियोटाइड बेस होते हैं।हमारी प्रत्येक कोशिका में लगभग 30 हजार विभिन्न जीन होते हैं, जबकि कुछ बैक्टीरिया को केवल 500 जीन की आवश्यकता होती है। जीन में कोड होते हैं जिसके अनुसार प्रोटीन को संश्लेषित किया जाता है और उनमें अमीनो एसिड का क्रम निर्धारित किया जाता है। कोई फर्क नहीं पड़ता कि मानव शरीर में कोशिकाएं कहां हैं, वे हमेशा जीन का एक ही सेट होते हैं। हालांकि, कोशिकाओं के प्रकार पर निर्भर करता है - त्वचा कोशिकाओं, तंत्रिका कोशिकाओं या मांसपेशियों की कोशिकाओं - नए जीन के संश्लेषण के लिए विभिन्न जीन उनमें शामिल हैं।एक कोशिका के गुणसूत्रों में डीएनए की लंबी श्रृंखलाएं कसकर संकुचित होती हैं। गुणसूत्रों में डीएनए की कॉम्पैक्ट व्यवस्था विशेष प्रोटीन के कारण होती है जिसके चारों ओर डीएनए किस्में घाव होती हैं। लेकिन कोशिका में प्रोटीन होते हैं, जो डीएनए में निहित कोड के अनुसार नए प्रोटीन के संश्लेषण को सुविधाजनक बनाने के लिए, यदि आवश्यक हो तो डीएनए को कॉम्पैक्ट रूप से विस्तारित एक में स्थानांतरित करते हैं। इन प्रोटीनों के प्रभाव में, विभाजन की तैयारी करने वाले गुणसूत्र कोशिकाएं प्रकट होती हैं और उस क्षण से 10 हजार गुना अधिक जगह घेरती हैं।"ए", "टी", "सी" और "जी" प्रकार के न्यूक्लियोटाइड्स, जो लंबे डीएनए अणुओं का हिस्सा हैं, उनके संश्लेषण के दौरान प्रोटीन के कोडिंग को सुनिश्चित करने के लिए एक निश्चित क्रम में व्यवस्थित होते हैं, जो 20 विभिन्न प्रकार के एमिनो एसिड से होता है। इसी समय, डीएनए एक मैट्रिक्स की भूमिका निभाता है - प्रत्येक प्रोटीन का अपना जीन होता है, जिसके नमूने के अनुसार वांछित प्रोटीन बनाने वाले अमीनो एसिड का संश्लेषण होता है। इस प्रकार, आनुवंशिक कोड प्रोटीन में सन्निहित है, और जीन में न्यूक्लियोटाइड्स का अनुक्रम प्रोटीन में अमीनो एसिड के अनुक्रम को निर्धारित करता है। सबसे सरल सादृश्य मोर्स कोड है, जहां डॉट्स, डैश और उनका संयोजन वर्णमाला के कुछ अक्षरों के अनुरूप है। एक बार में तीन पढ़े जाने वाले न्यूक्लियोटाइड्स का क्रम एक प्रोटीन में अमीनो एसिड के अनुक्रम से मेल खाता है। इस मामले में, एक बार में पढ़े जाने वाले तीन न्यूक्लियोटाइड का एक सेट एक एमिनो एसिड को एनकोड करता है।उदाहरण के लिए, AUG न्यूक्लियोटाइड सेट अमीनो एसिड एसिडोमेथिओनिन को एनकोड करता है।64 न्यूक्लियोटाइड संयोजन हैं, लेकिन केवल 20 विभिन्न प्रकार के अमीनो एसिड संश्लेषित हैं। इसका मतलब यह है कि कुछ टर्नरी न्यूक्लियोटाइड अनुक्रमों का उपयोग अमीनो एसिड के संश्लेषण के लिए नहीं किया जाता है, लेकिन संश्लेषण प्रक्रिया में एक रुकावट को इंगित करने के लिए किया जाता है। टर्नरी न्यूक्लियोटाइड्स के पूरी तरह से अर्थहीन सेट नहीं हैं - उनमें से प्रत्येक कुछ विशिष्ट कार्य करता है। न्यूक्लियोटाइड के कई सेट हैं जो समान अमीनो एसिड को एनकोड करते हैं। सबसे बड़े जीन में दो मिलियन न्यूक्लियोटाइड होते हैं, जो अपने प्रत्येक स्ट्रैंड पर स्थित होते हैं, और एक हजार में सबसे छोटा होता है।आनुवंशिक जानकारी ("प्रतिलेखन") पढ़ने की प्रक्रिया क्रोमोसोम के अंत में डीएनए डबल हेलिक्स के एक छोटे हिस्से की खोज और तैनाती के साथ शुरू होती है। गुणसूत्र के इस हिस्से के आनुवंशिक कोड को तब कॉपी प्रक्रिया के विकास के रूप में बढ़ते हुए आरएनए अणु पर कॉपी किया जाता है, जबकि प्रोटीन कॉपी तंत्र डीएनए स्ट्रैंड के साथ चलता है। आनुवंशिक कोड को स्थानांतरित करने की प्रक्रिया तब समाप्त होती है जब एमिनो एसिड के तथाकथित टर्मिनल समूह को आरएनए के अंत में संश्लेषित किया जाता है - इसकी उपस्थिति इस कोड की प्रोटीन श्रृंखला के अंत का संकेत देती है।अणुओं में इन आधारों के प्रत्यावर्तन का क्रम उन सूचनाओं को निर्धारित करता है जो हमारे शरीर की कोशिकाओं को आवश्यक प्रोटीनों की एक सख्ती से परिभाषित मात्रा का उत्पादन करने और अन्य महत्वपूर्ण कार्यों का समर्थन करने की अनुमति देता है। लेकिन, इस तथ्य के बावजूद कि हमारे शरीर की सभी कोशिकाओं में जीन का एक ही सेट होता है, कोशिकाएं स्वयं अलग-अलग तरीके से विकसित होती हैं और इसकी सबसे सरल पुष्टि विभिन्न प्रकार के ऊतक कोशिकाओं का अस्तित्व है जो विभिन्न अंगों का निर्माण करते हैं। और यह सब फिर से और फिर से वैज्ञानिकों को "अतिरेक" के लिए एक अतिरिक्त कुंजी की तलाश करता है, अर्थात्, अभी तक पूरी तरह से जानकारी का डिकिप्राइड नहीं है।
7 जून 2016 को, नीदरलैंड के वैज्ञानिकों के एक समूह का काम जो हमारे डीएनए में एक दूसरी छिपी हुई जानकारी परत के अस्तित्व को साबित करने में कामयाब रहा , वैज्ञानिक प्रकाशन पत्रिकाओं के पृष्ठ पर प्रकाशित हुआ था । ppl.org ।डीएनए प्रोटीन की संरचना को कैसे एनकोड करता हैजैसा कि आप जानते हैं, डीएनए की नींव ब्रह्मांड के निर्माण खंड हैं जो हमारे ग्रह पर सभी जीवन के अस्तित्व और प्रजनन की बहुत संभावना निर्धारित करते हैं। डीएनए अणु में "ए", "टी", "सी" और "जी" अक्षरों द्वारा निरूपित चार प्रकार के नाइट्रोजन युक्त न्यूक्लियोटाइड बेस होते हैं।हमारी प्रत्येक कोशिका में लगभग 30 हजार विभिन्न जीन होते हैं, जबकि कुछ बैक्टीरिया को केवल 500 जीन की आवश्यकता होती है। जीन में कोड होते हैं जिसके अनुसार प्रोटीन को संश्लेषित किया जाता है और उनमें अमीनो एसिड का क्रम निर्धारित किया जाता है। कोई फर्क नहीं पड़ता कि मानव शरीर में कोशिकाएं कहां हैं, वे हमेशा जीन का एक ही सेट होते हैं। हालांकि, कोशिकाओं के प्रकार पर निर्भर करता है - त्वचा कोशिकाओं, तंत्रिका कोशिकाओं या मांसपेशियों की कोशिकाओं - नए जीन के संश्लेषण के लिए विभिन्न जीन उनमें शामिल हैं।एक कोशिका के गुणसूत्रों में डीएनए की लंबी श्रृंखलाएं कसकर संकुचित होती हैं। गुणसूत्रों में डीएनए की कॉम्पैक्ट व्यवस्था विशेष प्रोटीन के कारण होती है जिसके चारों ओर डीएनए किस्में घाव होती हैं। लेकिन कोशिका में प्रोटीन होते हैं, जो डीएनए में निहित कोड के अनुसार नए प्रोटीन के संश्लेषण को सुविधाजनक बनाने के लिए, यदि आवश्यक हो तो डीएनए को कॉम्पैक्ट रूप से विस्तारित एक में स्थानांतरित करते हैं। इन प्रोटीनों के प्रभाव में, विभाजन की तैयारी करने वाले गुणसूत्र कोशिकाएं प्रकट होती हैं और उस क्षण से 10 हजार गुना अधिक जगह घेरती हैं।"ए", "टी", "सी" और "जी" प्रकार के न्यूक्लियोटाइड्स, जो लंबे डीएनए अणुओं का हिस्सा हैं, उनके संश्लेषण के दौरान प्रोटीन के कोडिंग को सुनिश्चित करने के लिए एक निश्चित क्रम में व्यवस्थित होते हैं, जो 20 विभिन्न प्रकार के एमिनो एसिड से होता है। इसी समय, डीएनए एक मैट्रिक्स की भूमिका निभाता है - प्रत्येक प्रोटीन का अपना जीन होता है, जिसके नमूने के अनुसार वांछित प्रोटीन बनाने वाले अमीनो एसिड का संश्लेषण होता है। इस प्रकार, आनुवंशिक कोड प्रोटीन में सन्निहित है, और जीन में न्यूक्लियोटाइड्स का अनुक्रम प्रोटीन में अमीनो एसिड के अनुक्रम को निर्धारित करता है। सबसे सरल सादृश्य मोर्स कोड है, जहां डॉट्स, डैश और उनका संयोजन वर्णमाला के कुछ अक्षरों के अनुरूप है। एक बार में तीन पढ़े जाने वाले न्यूक्लियोटाइड्स का क्रम एक प्रोटीन में अमीनो एसिड के अनुक्रम से मेल खाता है। इस मामले में, एक बार में पढ़े जाने वाले तीन न्यूक्लियोटाइड का एक सेट एक एमिनो एसिड को एनकोड करता है।उदाहरण के लिए, AUG न्यूक्लियोटाइड सेट अमीनो एसिड एसिडोमेथिओनिन को एनकोड करता है।64 न्यूक्लियोटाइड संयोजन हैं, लेकिन केवल 20 विभिन्न प्रकार के अमीनो एसिड संश्लेषित हैं। इसका मतलब यह है कि कुछ टर्नरी न्यूक्लियोटाइड अनुक्रमों का उपयोग अमीनो एसिड के संश्लेषण के लिए नहीं किया जाता है, लेकिन संश्लेषण प्रक्रिया में एक रुकावट को इंगित करने के लिए किया जाता है। टर्नरी न्यूक्लियोटाइड्स के पूरी तरह से अर्थहीन सेट नहीं हैं - उनमें से प्रत्येक कुछ विशिष्ट कार्य करता है। न्यूक्लियोटाइड के कई सेट हैं जो समान अमीनो एसिड को एनकोड करते हैं। सबसे बड़े जीन में दो मिलियन न्यूक्लियोटाइड होते हैं, जो अपने प्रत्येक स्ट्रैंड पर स्थित होते हैं, और एक हजार में सबसे छोटा होता है।आनुवंशिक जानकारी ("प्रतिलेखन") पढ़ने की प्रक्रिया क्रोमोसोम के अंत में डीएनए डबल हेलिक्स के एक छोटे हिस्से की खोज और तैनाती के साथ शुरू होती है। गुणसूत्र के इस हिस्से के आनुवंशिक कोड को तब कॉपी प्रक्रिया के विकास के रूप में बढ़ते हुए आरएनए अणु पर कॉपी किया जाता है, जबकि प्रोटीन कॉपी तंत्र डीएनए स्ट्रैंड के साथ चलता है। आनुवंशिक कोड को स्थानांतरित करने की प्रक्रिया तब समाप्त होती है जब एमिनो एसिड के तथाकथित टर्मिनल समूह को आरएनए के अंत में संश्लेषित किया जाता है - इसकी उपस्थिति इस कोड की प्रोटीन श्रृंखला के अंत का संकेत देती है।अणुओं में इन आधारों के प्रत्यावर्तन का क्रम उन सूचनाओं को निर्धारित करता है जो हमारे शरीर की कोशिकाओं को आवश्यक प्रोटीनों की एक सख्ती से परिभाषित मात्रा का उत्पादन करने और अन्य महत्वपूर्ण कार्यों का समर्थन करने की अनुमति देता है। लेकिन, इस तथ्य के बावजूद कि हमारे शरीर की सभी कोशिकाओं में जीन का एक ही सेट होता है, कोशिकाएं स्वयं अलग-अलग तरीके से विकसित होती हैं और इसकी सबसे सरल पुष्टि विभिन्न प्रकार के ऊतक कोशिकाओं का अस्तित्व है जो विभिन्न अंगों का निर्माण करते हैं। और यह सब फिर से और फिर से वैज्ञानिकों को "अतिरेक" के लिए एक अतिरिक्त कुंजी की तलाश करता है, अर्थात्, अभी तक पूरी तरह से जानकारी का डिकिप्राइड नहीं है।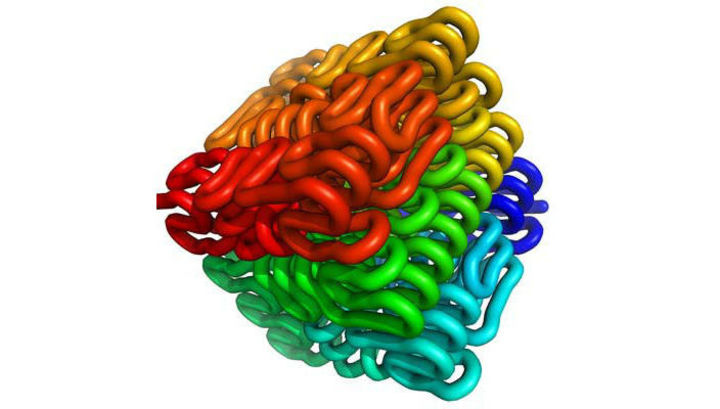 डीएनए अणु बेहद कॉम्पैक्ट रूप से भरे होते हैं। दूसरी ओर, यह ज्ञात है कि इसके असंगठित रूप में, एक कोशिका में निहित अणुओं की एक श्रृंखला, औसतन, 2 मीटर है। पिछली सदी के 80 के दशक के बाद से नहीं बदली गई एक परिकल्पना के अनुसार, डीएनए अणु के यांत्रिक गुण यह निर्धारित करते हैं कि यह सेल के अंदर "मुड़ा" कैसे होगा। डच वैज्ञानिकों के नवीनतम अध्ययनों ने पुष्टि की है: अणु के आकार में परिवर्तन से डीएनए हेलिक्स के "कनवल्शन" में बदलाव होता है। यह इस तथ्य है कि डीएनए में एक दूसरे कोडिंग तंत्र की उपस्थिति के बारे में बात करना संभव हो गया, जो मुख्य आनुवंशिक कोड की तुलना में प्रोटीन प्रजनन का समर्थन करने की प्रक्रियाओं में कोई कम महत्व नहीं निभाता है।हेल्मुट शिएसेल के नेतृत्व में लीडेन इंस्टीट्यूट ऑफ फिजिक्स की एक शोध टीम ने एक कंप्यूटर मॉडल विकसित किया जिसका उद्देश्य ऊपर वर्णित परिकल्पना का परीक्षण करना था और इसकी वैधता साबित करने के तरीके खोजना था। विचाराधीन मॉडल के लिए तार्किक आधार बेकर के खमीर और जीनस Schizosaccharomycetes के खमीर के समान कोशिकाओं था, जिसमें एक ही अनुक्रम के साथ डीएनए अणु था, लेकिन विभिन्न यांत्रिक गुणों के साथ।जैसा कि मॉडल के गणितीय विश्लेषण ने दिखाया, खमीर डीएनए अणु वास्तव में अलग-अलग एल्गोरिदम में विभिन्न यांत्रिक प्रभावों के प्रभाव में एक कॉम्पैक्ट आकार को मोड़ (कॉन्फ़िगर) करते हैं और प्राप्त करते हैं।माध्यमिक कोड के लिए अन्य सबूतडीएनए में निहित मुख्य आनुवंशिक कोड पिछली शताब्दी के 60 के दशक में आंशिक रूप से वापस आ गया था। उस क्षण से, वैज्ञानिक समुदाय यह पूरी तरह सुनिश्चित था कि बाहरी घटनाओं और उत्तेजनाओं की प्रतिक्रिया के रूप में शरीर की कोशिकाओं द्वारा उत्पादित प्रोटीन के बारे में केवल जानकारी डीएनए में दर्ज की जाती है। इस तथ्य के बावजूद कि समय के साथ यह अवधारणा कुछ हद तक विस्तारित हुई, डीएनए में "मोनोलिंगुअल" कोडिंग के बुनियादी सिद्धांत अपरिवर्तित रहे।हालाँकि, इस दिशा में अनुसंधान जारी रहा। 2013 में, वाशिंगटन विश्वविद्यालय (यूडब्ल्यू) के वैज्ञानिकों के एक समूह ने पहली बार एक छिपे हुए माध्यमिक कोड के अस्तित्व की घोषणा की, जो डीएनए में निहित बुनियादी आनुवंशिक निर्देशों के अनुक्रम के पढ़ने के क्रम को सीधे निर्धारित करता है। परिकल्पना की वैधता की पुष्टि करने वाले अध्ययनों के परिणाम विज्ञान के पन्नों पर प्रकाशित किए गए थे ।वैज्ञानिकों ने निष्कर्ष निकाला है कि आनुवंशिक कोड में जानकारी दो अलग-अलग भाषाओं में लिखी गई है। पहला कोशिकाओं द्वारा निर्मित प्रोटीन की संरचना और मात्रा का वर्णन करता है और नियंत्रित करता है, दूसरा उन निर्देशों के अनुक्रम को निर्धारित करता है जो जीन के पढ़ने को नियंत्रित करते हैं। दूसरी भाषा के निर्माण, जैसा कि वैज्ञानिकों ने तब अपने प्रकाशन में नोट किया था, पहले के निर्माणों के ऊपर लिखा गया था, जिसका मुख्य कारण था कि, "सबसे अधिक दिखाई देने वाली जगह" में, यह इतने लंबे समय तक वैज्ञानिक समुदाय के ध्यान से छिपा था।आनुवांशिक अनुक्रमों का अध्ययन करते हुए, वैज्ञानिक तब इस निष्कर्ष पर पहुंचे कि कुछ प्रकार के कोडन (उनकी कुल संख्या का 15% तक), जिसे ड्यून्स कहा जाता है, के दो अर्थ हो सकते हैं, जिनमें से एक प्रोटीन की संरचना, जीन प्रबंधन के सिद्धांतों के दूसरे के साथ जुड़ा हुआ है। इसके अलावा, ये दोनों मूल्य एक-दूसरे से बहुत निकट से संबंधित हैं, क्योंकि कुछ मामलों में जीन नियंत्रण के निर्देश आपको उनके उत्पादन के समय सबसे जटिल प्रोटीन के कुछ वर्गों को स्थिर करने की अनुमति देते हैं। और यह युगल है जो दूसरी भाषा के निर्माण का आधार बनता है, जिसकी मदद से सूचना की दूसरी परत डीएनए में दर्ज की जाती है।"40 से अधिक वर्षों के लिए, हम मानते थे कि डीएनए अणुओं के आनुवंशिक कोड में सभी परिवर्तन कोशिकाओं में प्रोटीन के उत्पादन के कार्य को प्रभावित करते हैं," वाशिंगटन विश्वविद्यालय में चिकित्सा और जीनोमिक्स के प्रोफेसर डॉ। जॉन स्टमैटोयेनोपोलोस कहते हैं, "अब हम जानते हैं कि आनुवांशिक जानकारी को पढ़ते हुए, हम इसमें से लगभग आधे से चूक गए, जो बदले में, हमारे ज्ञान की समग्र तस्वीर को विकृत कर दिया। अतिरिक्त जानकारी की उपलब्धता के बारे में नए ज्ञान के साथ सशस्त्र, जल्द ही हम पूरी तरह से वह सब कुछ पढ़ सकेंगे जो डीएनए में लिखा गया है, जो आज प्रकृति द्वारा बनाए गए सबसे शक्तिशाली सूचना भंडारण उपकरण में है। ”काम का मूल्यइस तथ्य को जानने के बाद कि डीएनए अणुओं में एक साथ दो प्रकार की जानकारी होती है, जो वैज्ञानिकों को प्रोटीन में होने वाले परिवर्तनों को पूरी तरह से पहचानने में सक्षम बनाएगी जो कि डीएनए की संरचना को प्रभावित करने वाले उत्परिवर्तजन प्रक्रियाओं के परिणामस्वरूप होगा। प्रोटीन की संरचना में परिवर्तनों की एक सटीक और पूर्ण तस्वीर वैज्ञानिकों को सटीक और असमान रूप से यह निर्धारित करने की अनुमति देगी कि कौन से रोग किन कारणों से और किन परिवर्तनों के कारण होते हैं और डीएनए जानकारी के उस भाग में परिवर्तनों के आधार पर रोगों के उपचार के नए तरीकों का विकास करते हैं जो केवल जीन के कार्यों को नियंत्रित करते हैं।दूसरी ओर, पहली बार, वैज्ञानिक उस आनुवांशिक उत्परिवर्तन की पुष्टि करने में सक्षम थे, जो कि पहले सुझाव दिया गया था, केवल आनुवंशिक अनुक्रम के मूल कोड की संरचना को प्रभावित कर सकता है, डीएनए की यांत्रिक संरचना को प्रभावित कर सकता है, जो बदले में, पढ़ने के क्रम में बदलाव का कारण बनेगा। प्रोटीन के उत्पादन के लिए निर्देश, बाद के प्रकार और मात्रा को बदलते हुए। लीडेन इंस्टीट्यूट ऑफ फिजिक्सकी साइट पर प्रकाशन पीएलओएस वन पत्रिका में काम का एकविस्तृत विवरण है
डीएनए अणु बेहद कॉम्पैक्ट रूप से भरे होते हैं। दूसरी ओर, यह ज्ञात है कि इसके असंगठित रूप में, एक कोशिका में निहित अणुओं की एक श्रृंखला, औसतन, 2 मीटर है। पिछली सदी के 80 के दशक के बाद से नहीं बदली गई एक परिकल्पना के अनुसार, डीएनए अणु के यांत्रिक गुण यह निर्धारित करते हैं कि यह सेल के अंदर "मुड़ा" कैसे होगा। डच वैज्ञानिकों के नवीनतम अध्ययनों ने पुष्टि की है: अणु के आकार में परिवर्तन से डीएनए हेलिक्स के "कनवल्शन" में बदलाव होता है। यह इस तथ्य है कि डीएनए में एक दूसरे कोडिंग तंत्र की उपस्थिति के बारे में बात करना संभव हो गया, जो मुख्य आनुवंशिक कोड की तुलना में प्रोटीन प्रजनन का समर्थन करने की प्रक्रियाओं में कोई कम महत्व नहीं निभाता है।हेल्मुट शिएसेल के नेतृत्व में लीडेन इंस्टीट्यूट ऑफ फिजिक्स की एक शोध टीम ने एक कंप्यूटर मॉडल विकसित किया जिसका उद्देश्य ऊपर वर्णित परिकल्पना का परीक्षण करना था और इसकी वैधता साबित करने के तरीके खोजना था। विचाराधीन मॉडल के लिए तार्किक आधार बेकर के खमीर और जीनस Schizosaccharomycetes के खमीर के समान कोशिकाओं था, जिसमें एक ही अनुक्रम के साथ डीएनए अणु था, लेकिन विभिन्न यांत्रिक गुणों के साथ।जैसा कि मॉडल के गणितीय विश्लेषण ने दिखाया, खमीर डीएनए अणु वास्तव में अलग-अलग एल्गोरिदम में विभिन्न यांत्रिक प्रभावों के प्रभाव में एक कॉम्पैक्ट आकार को मोड़ (कॉन्फ़िगर) करते हैं और प्राप्त करते हैं।माध्यमिक कोड के लिए अन्य सबूतडीएनए में निहित मुख्य आनुवंशिक कोड पिछली शताब्दी के 60 के दशक में आंशिक रूप से वापस आ गया था। उस क्षण से, वैज्ञानिक समुदाय यह पूरी तरह सुनिश्चित था कि बाहरी घटनाओं और उत्तेजनाओं की प्रतिक्रिया के रूप में शरीर की कोशिकाओं द्वारा उत्पादित प्रोटीन के बारे में केवल जानकारी डीएनए में दर्ज की जाती है। इस तथ्य के बावजूद कि समय के साथ यह अवधारणा कुछ हद तक विस्तारित हुई, डीएनए में "मोनोलिंगुअल" कोडिंग के बुनियादी सिद्धांत अपरिवर्तित रहे।हालाँकि, इस दिशा में अनुसंधान जारी रहा। 2013 में, वाशिंगटन विश्वविद्यालय (यूडब्ल्यू) के वैज्ञानिकों के एक समूह ने पहली बार एक छिपे हुए माध्यमिक कोड के अस्तित्व की घोषणा की, जो डीएनए में निहित बुनियादी आनुवंशिक निर्देशों के अनुक्रम के पढ़ने के क्रम को सीधे निर्धारित करता है। परिकल्पना की वैधता की पुष्टि करने वाले अध्ययनों के परिणाम विज्ञान के पन्नों पर प्रकाशित किए गए थे ।वैज्ञानिकों ने निष्कर्ष निकाला है कि आनुवंशिक कोड में जानकारी दो अलग-अलग भाषाओं में लिखी गई है। पहला कोशिकाओं द्वारा निर्मित प्रोटीन की संरचना और मात्रा का वर्णन करता है और नियंत्रित करता है, दूसरा उन निर्देशों के अनुक्रम को निर्धारित करता है जो जीन के पढ़ने को नियंत्रित करते हैं। दूसरी भाषा के निर्माण, जैसा कि वैज्ञानिकों ने तब अपने प्रकाशन में नोट किया था, पहले के निर्माणों के ऊपर लिखा गया था, जिसका मुख्य कारण था कि, "सबसे अधिक दिखाई देने वाली जगह" में, यह इतने लंबे समय तक वैज्ञानिक समुदाय के ध्यान से छिपा था।आनुवांशिक अनुक्रमों का अध्ययन करते हुए, वैज्ञानिक तब इस निष्कर्ष पर पहुंचे कि कुछ प्रकार के कोडन (उनकी कुल संख्या का 15% तक), जिसे ड्यून्स कहा जाता है, के दो अर्थ हो सकते हैं, जिनमें से एक प्रोटीन की संरचना, जीन प्रबंधन के सिद्धांतों के दूसरे के साथ जुड़ा हुआ है। इसके अलावा, ये दोनों मूल्य एक-दूसरे से बहुत निकट से संबंधित हैं, क्योंकि कुछ मामलों में जीन नियंत्रण के निर्देश आपको उनके उत्पादन के समय सबसे जटिल प्रोटीन के कुछ वर्गों को स्थिर करने की अनुमति देते हैं। और यह युगल है जो दूसरी भाषा के निर्माण का आधार बनता है, जिसकी मदद से सूचना की दूसरी परत डीएनए में दर्ज की जाती है।"40 से अधिक वर्षों के लिए, हम मानते थे कि डीएनए अणुओं के आनुवंशिक कोड में सभी परिवर्तन कोशिकाओं में प्रोटीन के उत्पादन के कार्य को प्रभावित करते हैं," वाशिंगटन विश्वविद्यालय में चिकित्सा और जीनोमिक्स के प्रोफेसर डॉ। जॉन स्टमैटोयेनोपोलोस कहते हैं, "अब हम जानते हैं कि आनुवांशिक जानकारी को पढ़ते हुए, हम इसमें से लगभग आधे से चूक गए, जो बदले में, हमारे ज्ञान की समग्र तस्वीर को विकृत कर दिया। अतिरिक्त जानकारी की उपलब्धता के बारे में नए ज्ञान के साथ सशस्त्र, जल्द ही हम पूरी तरह से वह सब कुछ पढ़ सकेंगे जो डीएनए में लिखा गया है, जो आज प्रकृति द्वारा बनाए गए सबसे शक्तिशाली सूचना भंडारण उपकरण में है। ”काम का मूल्यइस तथ्य को जानने के बाद कि डीएनए अणुओं में एक साथ दो प्रकार की जानकारी होती है, जो वैज्ञानिकों को प्रोटीन में होने वाले परिवर्तनों को पूरी तरह से पहचानने में सक्षम बनाएगी जो कि डीएनए की संरचना को प्रभावित करने वाले उत्परिवर्तजन प्रक्रियाओं के परिणामस्वरूप होगा। प्रोटीन की संरचना में परिवर्तनों की एक सटीक और पूर्ण तस्वीर वैज्ञानिकों को सटीक और असमान रूप से यह निर्धारित करने की अनुमति देगी कि कौन से रोग किन कारणों से और किन परिवर्तनों के कारण होते हैं और डीएनए जानकारी के उस भाग में परिवर्तनों के आधार पर रोगों के उपचार के नए तरीकों का विकास करते हैं जो केवल जीन के कार्यों को नियंत्रित करते हैं।दूसरी ओर, पहली बार, वैज्ञानिक उस आनुवांशिक उत्परिवर्तन की पुष्टि करने में सक्षम थे, जो कि पहले सुझाव दिया गया था, केवल आनुवंशिक अनुक्रम के मूल कोड की संरचना को प्रभावित कर सकता है, डीएनए की यांत्रिक संरचना को प्रभावित कर सकता है, जो बदले में, पढ़ने के क्रम में बदलाव का कारण बनेगा। प्रोटीन के उत्पादन के लिए निर्देश, बाद के प्रकार और मात्रा को बदलते हुए। लीडेन इंस्टीट्यूट ऑफ फिजिक्सकी साइट पर प्रकाशन पीएलओएस वन पत्रिका में काम का एकविस्तृत विवरण है
यह सब, आपके साथ जटिल ड्रोनक.रू उपकरण चुनने के लिए एक सरल सेवा थी । हमारे ब्लॉग को सब्सक्राइब करना ना भूलें , और भी कई रोचक बातें होंगी ...
Source: https://habr.com/ru/post/hi395077/
All Articles