क्या हम आर्टिफिशियल इंटेलिजेंस का ब्लैक बॉक्स खोल सकते हैं?
 डीन पोमर्लेउ आज भी याद करते हैं कि उन्हें ब्लैक बॉक्स की समस्या से पहली बार कब जूझना पड़ा था। 1991 में, उन्होंने इस क्षेत्र में पहले प्रयासों में से एक बनाया जो अब हर कोई अध्ययन कर रहा है जो एक रोबोट कार बनाने की कोशिश कर रहा है: कंप्यूटर चलाना सीखना।और इसका मतलब यह था कि आपको विशेष रूप से तैयार हुमवे (सेना के ऑफ-रोड वाहन) को चलाने और शहर की सड़कों के माध्यम से सवारी करने की आवश्यकता है। इस तरह कार्नेगी मेलन विश्वविद्यालय में रोबोटिक्स के पूर्व स्नातक छात्र पोमेलो ने इस बारे में बताया। एक कंप्यूटर ने कैमरे के माध्यम से प्रोग्राम करने के लिए प्रोग्राम किया, जो सड़क पर क्या हो रहा है, इसकी व्याख्या करता है और चालक के सभी आंदोलनों को याद करता है और इसके साथ सवार होता है। पोमेलो को उम्मीद थी कि कार अंततः स्वतंत्र ड्राइविंग के लिए पर्याप्त संघों का निर्माण करेगी।प्रत्येक यात्रा के लिए, पोमेलो ने प्रणाली को कई मिनटों के लिए प्रशिक्षित किया, और फिर इसे अपने दम पर चलाने दिया। सब कुछ ठीक लग रहा था - जब तक एक बार हुमवे पुल के पास पहुंच गया, अचानक किनारे की तरफ मुड़ गया। एक व्यक्ति केवल स्टीयरिंग व्हील को पकड़कर और नियंत्रण वापस करके एक दुर्घटना से बचने में कामयाब रहा।प्रयोगशाला में, पोमेलो ने एक कंप्यूटर त्रुटि का पता लगाने की कोशिश की। "मेरे वैज्ञानिक कार्यों में से एक कार्य 'ब्लैक बॉक्स' को खोलना था और यह पता लगाना था कि वह किस बारे में सोच रहा था," वे बताते हैं। लेकिन कैसे? उन्होंने कंप्यूटर को "न्यूरल नेटवर्क" के रूप में क्रमादेशित किया - एक प्रकार की कृत्रिम बुद्धि जो मस्तिष्क के कामकाज की नकल करती है, वास्तविक दुनिया से संबंधित जटिल परिस्थितियों से निपटने में मानक एल्गोरिदम से बेहतर होने का वादा करती है। दुर्भाग्य से, ऐसे नेटवर्क एक वास्तविक मस्तिष्क की तरह अपारदर्शी हैं। वे स्मृति के स्वच्छ ब्लॉक में सीखी गई हर चीज को संग्रहीत नहीं करते हैं, बल्कि जानकारी को फैलाते हैं ताकि उसे समझना मुश्किल हो जाए। विभिन्न इनपुट मापदंडों के लिए सॉफ्टवेयर प्रतिक्रिया परीक्षणों की एक विस्तृत श्रृंखला के बाद ही, पोमेलो ने एक समस्या की खोज की: नेटवर्क ने दिशाओं को निर्धारित करने के लिए सड़कों के किनारों के साथ घास का इस्तेमाल किया, और इसलिए पुल की उपस्थिति ने उसे भ्रमित कर दिया।25 वर्षों के बाद, इस कार्य की तात्कालिकता को बढ़ाते हुए, ब्लैक बॉक्स को डीकोडिंग करना और अधिक कठिन हो गया है। प्रौद्योगिकी की जटिलता और व्यापकता में विस्फोटक वृद्धि हुई है। एक पॉमेलो, कार्नेगी मेलन में रोबोटिक्स प्रशिक्षण में अंशकालिक, आधुनिक मशीनों पर बेचे जाने वाले विशाल तंत्रिका नेटवर्क की तुलना में अपने लंबे समय तक चलने वाले सिस्टम को "गरीबों के लिए तंत्रिका नेटवर्क" के रूप में वर्णित करता है । गहरी सीखने की तकनीक (जीआई), जिसमें नेटवर्क "बड़े डेटा" से अभिलेखागार पर प्रशिक्षण प्राप्त करता है, ब्राउज़िंग इतिहास के आधार पर साइटों पर उत्पाद की सिफारिशों के लिए डाकू से विभिन्न व्यावसायिक अनुप्रयोगों को पाता है।प्रौद्योगिकी विज्ञान में सर्वव्यापी होने का वादा करती है। भविष्य की रेडियो वेधशालाएँ डेटा सरणियों में महत्वपूर्ण संकेतों की खोज के लिए GO का उपयोग करेंगीअन्यथा आप रेक नहीं करेंगे । गुरुत्वाकर्षण तरंग डिटेक्टर छोटे शोर को समझने और खत्म करने के लिए उनका उपयोग करेंगे। प्रकाशक उन्हें लाखों शोध पत्रों और पुस्तकों को छानने और टैग करने के लिए उपयोग करेंगे। कुछ का मानना है कि अंततः GO की मदद से कंप्यूटर कल्पना और रचनात्मक क्षमताओं को प्रदर्शित करने में सक्षम होंगे। कैलिफोर्निया इंस्टीट्यूट ऑफ टेक्नोलॉजी के भौतिक विज्ञानी ज्यां-रोच वेल्लिमेंट कहते हैं, "आप सिर्फ डेटा को मशीन में गिरा सकते हैं और यह आपको प्रकृति के नियमों को लौटा देगा।"लेकिन इस तरह की सफलता ब्लैक बॉक्स की समस्या को और अधिक गंभीर बना देगी। मशीन वास्तव में महत्वपूर्ण संकेत कैसे खोजती है? आप यह कैसे सुनिश्चित कर सकते हैं कि उसके निष्कर्ष सही हैं? लोगों को गहरी शिक्षा पर कितना भरोसा करना चाहिए? "मुझे लगता है कि हमें इन एल्गोरिदम के साथ देना है," न्यूयॉर्क में कोलंबिया विश्वविद्यालय से रोबोटिक्स विशेषज्ञ होड लिप्सन कहते हैं। वह बुद्धिमान एलियंस के साथ एक बैठक के साथ स्थिति की तुलना करता है, जिसकी आंखें न केवल लाल, हरे और नीले, बल्कि चौथा रंग भी देखती हैं। उनके अनुसार, लोगों को यह समझना बहुत मुश्किल होगा कि ये एलियंस दुनिया को कैसे देखते हैं, और उनके लिए यह हमें समझाते हैं। कंप्यूटर को अपने फैसले समझाने में समान समस्याएं होंगी, वे कहते हैं। "कुछ बिंदु पर, यह कुत्ते को शेक्सपियर को समझाने के प्रयासों से मिलता-जुलता होगा।"इस तरह की समस्याओं का सामना करने के बाद, एआई शोधकर्ता पोमेलो की तरह ही प्रतिक्रिया करते हैं - वे एक ब्लैक बॉक्स खोलते हैं और नेटवर्क के संचालन को समझने के लिए न्यूरोलॉजी जैसा दिखता है। सर्न भौतिक विज्ञानी विन्केन्ज़ो इनोसेंटे कहते हैं, "उत्तर सहज नहीं हैं, जो अपने क्षेत्र में एआई का उपयोग करने वाले पहले व्यक्ति थे। “एक वैज्ञानिक के रूप में, मैं कुत्तों को बिल्लियों से अलग करने की सरल क्षमता से संतुष्ट नहीं हूँ। एक वैज्ञानिक को यह कहने में सक्षम होना चाहिए: अंतर यह है कि और
डीन पोमर्लेउ आज भी याद करते हैं कि उन्हें ब्लैक बॉक्स की समस्या से पहली बार कब जूझना पड़ा था। 1991 में, उन्होंने इस क्षेत्र में पहले प्रयासों में से एक बनाया जो अब हर कोई अध्ययन कर रहा है जो एक रोबोट कार बनाने की कोशिश कर रहा है: कंप्यूटर चलाना सीखना।और इसका मतलब यह था कि आपको विशेष रूप से तैयार हुमवे (सेना के ऑफ-रोड वाहन) को चलाने और शहर की सड़कों के माध्यम से सवारी करने की आवश्यकता है। इस तरह कार्नेगी मेलन विश्वविद्यालय में रोबोटिक्स के पूर्व स्नातक छात्र पोमेलो ने इस बारे में बताया। एक कंप्यूटर ने कैमरे के माध्यम से प्रोग्राम करने के लिए प्रोग्राम किया, जो सड़क पर क्या हो रहा है, इसकी व्याख्या करता है और चालक के सभी आंदोलनों को याद करता है और इसके साथ सवार होता है। पोमेलो को उम्मीद थी कि कार अंततः स्वतंत्र ड्राइविंग के लिए पर्याप्त संघों का निर्माण करेगी।प्रत्येक यात्रा के लिए, पोमेलो ने प्रणाली को कई मिनटों के लिए प्रशिक्षित किया, और फिर इसे अपने दम पर चलाने दिया। सब कुछ ठीक लग रहा था - जब तक एक बार हुमवे पुल के पास पहुंच गया, अचानक किनारे की तरफ मुड़ गया। एक व्यक्ति केवल स्टीयरिंग व्हील को पकड़कर और नियंत्रण वापस करके एक दुर्घटना से बचने में कामयाब रहा।प्रयोगशाला में, पोमेलो ने एक कंप्यूटर त्रुटि का पता लगाने की कोशिश की। "मेरे वैज्ञानिक कार्यों में से एक कार्य 'ब्लैक बॉक्स' को खोलना था और यह पता लगाना था कि वह किस बारे में सोच रहा था," वे बताते हैं। लेकिन कैसे? उन्होंने कंप्यूटर को "न्यूरल नेटवर्क" के रूप में क्रमादेशित किया - एक प्रकार की कृत्रिम बुद्धि जो मस्तिष्क के कामकाज की नकल करती है, वास्तविक दुनिया से संबंधित जटिल परिस्थितियों से निपटने में मानक एल्गोरिदम से बेहतर होने का वादा करती है। दुर्भाग्य से, ऐसे नेटवर्क एक वास्तविक मस्तिष्क की तरह अपारदर्शी हैं। वे स्मृति के स्वच्छ ब्लॉक में सीखी गई हर चीज को संग्रहीत नहीं करते हैं, बल्कि जानकारी को फैलाते हैं ताकि उसे समझना मुश्किल हो जाए। विभिन्न इनपुट मापदंडों के लिए सॉफ्टवेयर प्रतिक्रिया परीक्षणों की एक विस्तृत श्रृंखला के बाद ही, पोमेलो ने एक समस्या की खोज की: नेटवर्क ने दिशाओं को निर्धारित करने के लिए सड़कों के किनारों के साथ घास का इस्तेमाल किया, और इसलिए पुल की उपस्थिति ने उसे भ्रमित कर दिया।25 वर्षों के बाद, इस कार्य की तात्कालिकता को बढ़ाते हुए, ब्लैक बॉक्स को डीकोडिंग करना और अधिक कठिन हो गया है। प्रौद्योगिकी की जटिलता और व्यापकता में विस्फोटक वृद्धि हुई है। एक पॉमेलो, कार्नेगी मेलन में रोबोटिक्स प्रशिक्षण में अंशकालिक, आधुनिक मशीनों पर बेचे जाने वाले विशाल तंत्रिका नेटवर्क की तुलना में अपने लंबे समय तक चलने वाले सिस्टम को "गरीबों के लिए तंत्रिका नेटवर्क" के रूप में वर्णित करता है । गहरी सीखने की तकनीक (जीआई), जिसमें नेटवर्क "बड़े डेटा" से अभिलेखागार पर प्रशिक्षण प्राप्त करता है, ब्राउज़िंग इतिहास के आधार पर साइटों पर उत्पाद की सिफारिशों के लिए डाकू से विभिन्न व्यावसायिक अनुप्रयोगों को पाता है।प्रौद्योगिकी विज्ञान में सर्वव्यापी होने का वादा करती है। भविष्य की रेडियो वेधशालाएँ डेटा सरणियों में महत्वपूर्ण संकेतों की खोज के लिए GO का उपयोग करेंगीअन्यथा आप रेक नहीं करेंगे । गुरुत्वाकर्षण तरंग डिटेक्टर छोटे शोर को समझने और खत्म करने के लिए उनका उपयोग करेंगे। प्रकाशक उन्हें लाखों शोध पत्रों और पुस्तकों को छानने और टैग करने के लिए उपयोग करेंगे। कुछ का मानना है कि अंततः GO की मदद से कंप्यूटर कल्पना और रचनात्मक क्षमताओं को प्रदर्शित करने में सक्षम होंगे। कैलिफोर्निया इंस्टीट्यूट ऑफ टेक्नोलॉजी के भौतिक विज्ञानी ज्यां-रोच वेल्लिमेंट कहते हैं, "आप सिर्फ डेटा को मशीन में गिरा सकते हैं और यह आपको प्रकृति के नियमों को लौटा देगा।"लेकिन इस तरह की सफलता ब्लैक बॉक्स की समस्या को और अधिक गंभीर बना देगी। मशीन वास्तव में महत्वपूर्ण संकेत कैसे खोजती है? आप यह कैसे सुनिश्चित कर सकते हैं कि उसके निष्कर्ष सही हैं? लोगों को गहरी शिक्षा पर कितना भरोसा करना चाहिए? "मुझे लगता है कि हमें इन एल्गोरिदम के साथ देना है," न्यूयॉर्क में कोलंबिया विश्वविद्यालय से रोबोटिक्स विशेषज्ञ होड लिप्सन कहते हैं। वह बुद्धिमान एलियंस के साथ एक बैठक के साथ स्थिति की तुलना करता है, जिसकी आंखें न केवल लाल, हरे और नीले, बल्कि चौथा रंग भी देखती हैं। उनके अनुसार, लोगों को यह समझना बहुत मुश्किल होगा कि ये एलियंस दुनिया को कैसे देखते हैं, और उनके लिए यह हमें समझाते हैं। कंप्यूटर को अपने फैसले समझाने में समान समस्याएं होंगी, वे कहते हैं। "कुछ बिंदु पर, यह कुत्ते को शेक्सपियर को समझाने के प्रयासों से मिलता-जुलता होगा।"इस तरह की समस्याओं का सामना करने के बाद, एआई शोधकर्ता पोमेलो की तरह ही प्रतिक्रिया करते हैं - वे एक ब्लैक बॉक्स खोलते हैं और नेटवर्क के संचालन को समझने के लिए न्यूरोलॉजी जैसा दिखता है। सर्न भौतिक विज्ञानी विन्केन्ज़ो इनोसेंटे कहते हैं, "उत्तर सहज नहीं हैं, जो अपने क्षेत्र में एआई का उपयोग करने वाले पहले व्यक्ति थे। “एक वैज्ञानिक के रूप में, मैं कुत्तों को बिल्लियों से अलग करने की सरल क्षमता से संतुष्ट नहीं हूँ। एक वैज्ञानिक को यह कहने में सक्षम होना चाहिए: अंतर यह है कि औरअच्छी सवारी
पहला न्यूरल नेटवर्क 1950 के दशक की शुरुआत में बनाया गया था, जो आवश्यक एल्गोरिदम के अनुसार काम करने में सक्षम कंप्यूटरों के आगमन के लगभग तुरंत बाद बना। विचार छोटे गणनीय मॉड्यूल के संचालन का अनुकरण करने के लिए है - न्यूरॉन्स - परतों में व्यवस्थित और डिजिटल "सिनेप्स" से जुड़ा हुआ है। निचली परत में प्रत्येक मॉड्यूल बाहरी डेटा प्राप्त करता है, उदाहरण के लिए, चित्र का पिक्सेल, फिर अगली परत में कुछ मॉड्यूल तक इस जानकारी को फैलाता है। दूसरी परत में प्रत्येक मॉड्यूल एक सरल गणितीय नियम के अनुसार पहली परत से इनपुट को एकीकृत करता है, और परिणाम को पास करता है। नतीजतन, शीर्ष परत एक जवाब देती है - उदाहरण के लिए, "बिल्लियों" या "कुत्तों" को मूल छवि प्रदान करती है।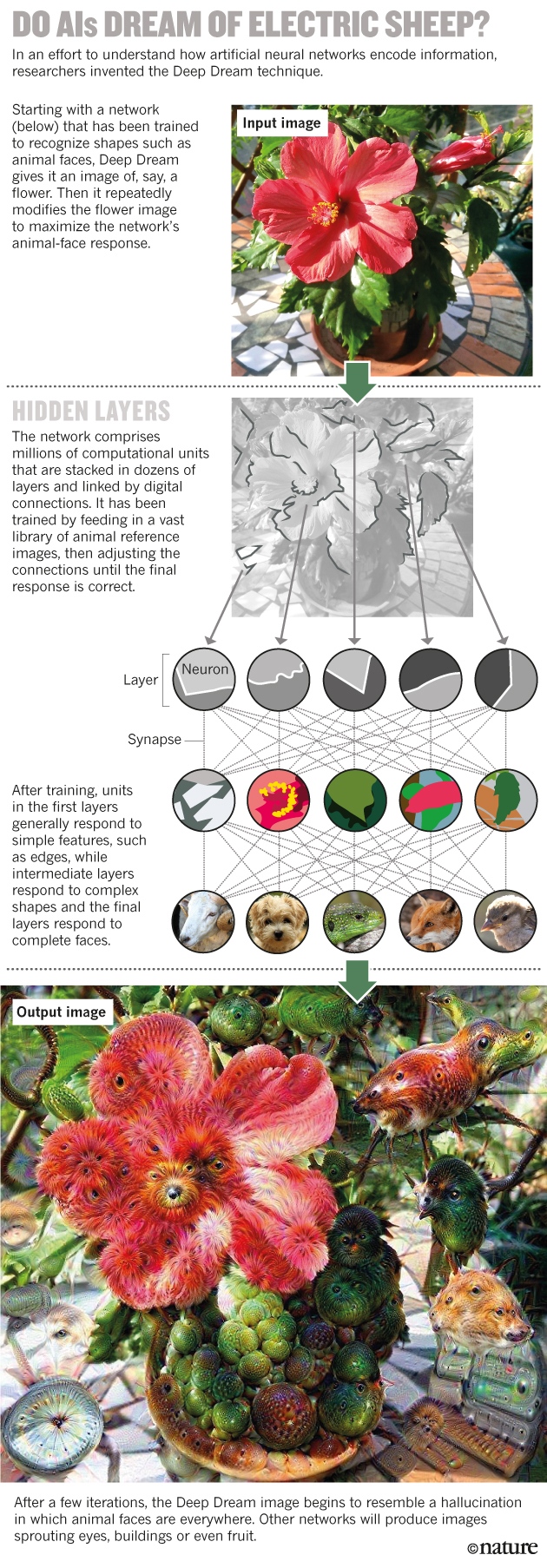 ? « » (Deep Dream) , , , , – , .
? « » (Deep Dream) , , , , – , .
, – , .
Deep Dream .ऐसे नेटवर्क की क्षमता सीखने की क्षमता से उपजी है। दिए गए सही उत्तरों के साथ प्रारंभिक डेटा सेट से सीखते हुए, वे धीरे-धीरे अपनी विशेषताओं में सुधार करते हैं, सही परिणाम उत्पन्न करने के लिए सभी लिंक के प्रभाव को समायोजित करते हैं। प्रक्रिया मस्तिष्क के प्रशिक्षण का अनुकरण करती है, जो सिनेप्स को मजबूत और कमजोर करती है, और एक नेटवर्क आउटपुट प्रदान करती है जो डेटा को वर्गीकृत करने में सक्षम है जो मूल रूप से प्रशिक्षण सेट में शामिल नहीं था।प्रशिक्षण की संभावना ने 1990 के दशक में CERN भौतिकविदों को लुभाया, जब वे विज्ञान में काम करने के लिए बड़े तंत्रिका नेटवर्क को अनुकूलित करने वाले पहले लोगों में थे। बड़े हैड्रोन कोलाइडर में कण टकरावों में पक्षों को तितर-बितर करते हुए तंत्रिका नेटवर्क ने उप-परमाणु छर्रों के प्रक्षेपवक्र के पुनर्निर्माण में मदद की।प्रशिक्षण का यह रूप भी कारण है कि जानकारी पूरे नेटवर्क में बहुत फैली हुई है: जैसा कि मस्तिष्क में, इसकी स्मृति विभिन्न यौगिकों की ताकत में एन्कोडेड है, और कुछ स्थानों पर संग्रहीत नहीं है, जैसा कि एक परिचित डेटाबेस में है। “आपके मस्तिष्क में संग्रहीत आपके फ़ोन नंबर का पहला अंक कहाँ है? शायद सिंटैप्स सेट में, शायद बाकी नंबरों से दूर नहीं, ”पियरे बल्दी, मशीन लर्निंग (एमओ) विशेषज्ञ, कैलिफोर्निया विश्वविद्यालय ने कहा। लेकिन संख्या एन्कोडिंग बिट्स का कोई निश्चित अनुक्रम नहीं है। नतीजतन, व्योमिंग विश्वविद्यालय के आईटी विशेषज्ञ जेफ क्लून कहते हैं, "भले ही हम इन नेटवर्क का निर्माण करते हैं, लेकिन हम उन्हें मानव मस्तिष्क से बेहतर नहीं समझ सकते हैं।"बड़े डेटा के साथ काम करने वाले वैज्ञानिकों के लिए, इसका मतलब है कि GO का उपयोग सावधानी से किया जाना चाहिए। एंड्रिया Vedaldi [एंड्रिया Vedaldi], ऑक्सफोर्ड यूनिवर्सिटी विशेषज्ञ से कंप्यूटर विज्ञान में बताते हैं: कल्पना करें कि भविष्य में पर तंत्रिका नेटवर्क को प्रशिक्षित करेंगे मैमोग्राम , जो नोट कर दी जाएगी कि क्या वहाँ स्तन कैंसर के साथ महिलाओं का अध्ययन किया गया था। उसके बाद, मान लीजिए कि एक स्वस्थ महिला के ऊतक रोग के लिए अतिसंवेदनशील दिखाई देते हैं। "तंत्रिका नेटवर्क ट्यूमर मार्करों को पहचानना सीख सकता है - वे जिनके बारे में हम नहीं जानते, लेकिन यह कैंसर की भविष्यवाणी कर सकता है।"लेकिन अगर मशीन यह नहीं बता सकती है कि यह इसे कैसे निर्धारित करता है, तो, वेदाल्दी के अनुसार, यह डॉक्टरों और रोगियों के लिए एक गंभीर दुविधा होगी। जेनेटिक फीचर्स की मौजूदगी के कारण एक महिला के लिए ब्रेस्ट के निरोधक निष्कासन से गुजरना आसान नहीं है, जिससे कैंसर हो सकता है। और इस तरह की पसंद बनाने के लिए और भी मुश्किल होगा, क्योंकि यह भी नहीं पता होगा कि यह कारक क्या है - भले ही मशीन की भविष्यवाणियां सटीक हो।"समस्या यह है कि ज्ञान नेटवर्क में अंतर्निहित है, हम में नहीं है", माइकल टायका, एक बायोफिजिसिस्ट और Google प्रोग्रामर कहते हैं। “क्या हमें कुछ समझ में आया? नहीं - यह नेटवर्क समझा जाता है। ”वैज्ञानिकों के कई समूहों ने 2012 में ब्लैक बॉक्स की समस्या से निपटा। टोरंटो विश्वविद्यालय के एक एमओ विशेषज्ञ जेफ्री हिंटन के नेतृत्व में एक टीम ने कंप्यूटर विज़न प्रतियोगिता में भाग लिया, और पहली बार यह प्रदर्शित किया कि 1.2 मिलियन छवियों के डेटाबेस से तस्वीरों को वर्गीकृत करने के लिए जीओ का उपयोग करने के साथ किसी भी अन्य दृष्टिकोण को पार कर गया। ऐ का उपयोग करना।यह समझना संभव है कि यह कैसे संभव है, वेदाल्डी समूह ने तंत्रिका नेटवर्क को बेहतर बनाने के लिए डिज़ाइन किए गए Hinton एल्गोरिदम को लिया और उन्हें पीछे की ओर खदेड़ दिया। उत्तर को सही ढंग से व्याख्या करने के लिए नेटवर्क को प्रशिक्षित करने के बजाय, टीम ने पूर्व-प्रशिक्षित नेटवर्क लिया और चित्रों को फिर से बनाने की कोशिश की, जिसके लिए उन्होंने प्रशिक्षण दिया। इससे शोधकर्ताओं को यह निर्धारित करने में मदद मिली कि मशीन कुछ विशेषताओं को कैसे प्रस्तुत करती है - यह ऐसा था जैसे वे किसी तरह के काल्पनिक तंत्रिका नेटवर्क से कैंसर की भविष्यवाणी कर रहे थे, "मैमोग्राम के किस हिस्से ने आपको कैंसर के खतरे के निशान तक पहुंचा दिया है?"तायका और उनके Google सहयोगियों ने पिछले साल एक समान दृष्टिकोण का उपयोग किया था। उनका एल्गोरिथ्म, जिसे वे डीप ड्रीम कहते हैं, एक तस्वीर के साथ शुरू होता है, कहते हैं, एक फूल, और इसे संशोधित करता है ताकि किसी विशेष शीर्ष-स्तरीय न्यूरॉन की प्रतिक्रिया में सुधार हो सके। यदि एक न्यूरॉन, कहना, पक्षियों की छवियों को चिह्नित करना पसंद करता है, तो बदली हुई तस्वीर हर जगह पक्षियों को दिखाना शुरू कर देगी। परिणामी तस्वीरें एलएसडी के तहत दृष्टि से मिलती-जुलती हैं, जहां पक्षी चेहरे, इमारतों और कई और अधिक दिखाई देते हैं। "मुझे लगता है कि यह एक मतिभ्रम की तरह है," ताइका, जो एक कलाकार भी है, कहते हैं। जब उन्होंने और उनके सहयोगियों ने रचनात्मक क्षेत्र में एल्गोरिदम की क्षमता देखी, तो उन्होंने इसे डाउनलोड करने के लिए स्वतंत्र बनाने का फैसला किया। कुछ ही दिनों में यह विषय वायरल हो गया।ऐसी तकनीकों का उपयोग करना जो किसी भी न्यूरॉन के उत्पादन को अधिकतम करते हैं, और केवल शीर्ष में से एक नहीं, 2014 में क्लून की टीम ने पाया कि ब्लैक बॉक्स की समस्या पहले की तुलना में अधिक जटिल हो सकती है। यादृच्छिक शोर या अमूर्त पैटर्न के रूप में लोगों द्वारा कथित चित्रों की मदद से तंत्रिका नेटवर्क को धोखा देना बहुत आसान है। उदाहरण के लिए, एक नेटवर्क लहराती लाइनें ले सकता है और यह तय कर सकता है कि यह एक स्टारफिश है, या स्कूल बस के साथ काली और सफेद धारियों को मिलाएं। इसके अलावा, अन्य डेटा सेटों पर प्रशिक्षित नेटवर्कों में भी यही ट्रेंड चला।शोधकर्ताओं ने नेटवर्क को बेवकूफ बनाने की समस्या के लिए कई समाधान सुझाए हैं, लेकिन अभी तक कोई सामान्य समाधान नहीं मिला है। वास्तविक अनुप्रयोगों में, यह खतरनाक हो सकता है। क्लून के अनुसार, भयावह परिदृश्यों में से एक यह है कि हैकर्स इन नेटवर्क खामियों का फायदा उठाना सीखते हैं। वे रोबोमोबाइल को एक बिलबोर्ड में भेज सकते हैं जो इसे सड़क के लिए ले जाएगा, या व्हाइट हाउस के प्रवेश द्वार पर रेटिना स्कैनर को चकमा देगा। "हमें एमओ को और अधिक विश्वसनीय और बुद्धिमान बनाने के लिए अपनी आस्तीन ऊपर रोल करने और गहन वैज्ञानिक अनुसंधान करने की आवश्यकता है," क्सुन का निष्कर्ष है।इस तरह की समस्याओं ने कुछ कंप्यूटर वैज्ञानिकों को यह सोचने के लिए प्रेरित किया कि आपको अकेले तंत्रिका नेटवर्क पर ध्यान केंद्रित नहीं करना चाहिए। कैम्ब्रिज विश्वविद्यालय के एमओ शोधकर्ता ज़ौबिन घर्रामानी का कहना है कि अगर एआई को ऐसे जवाब देने होंगे जो लोग आसानी से व्याख्या कर सकें, तो इससे "बहुत सारी समस्याओं का सामना करना पड़ेगा जो कि जीओ से निपटने में मदद नहीं कर सकते हैं।" एक उचित समझदार वैज्ञानिक दृष्टिकोण पहली बार 2009 में लिप्सन और कम्प्यूटेशनल जीवविज्ञानी माइकल श्मिट द्वारा दिखाया गया था, जो तब कॉर्नेल विश्वविद्यालय में काम कर रहे थे। उनके यूरेका एल्गोरिथ्म ने न्यूटन के नियमों को एक साधारण यांत्रिक वस्तु - पेंडुलम की एक प्रणाली - के द्वारा मोचन करते हुए फिर से प्रदर्शित करने की प्रक्रिया का प्रदर्शन किया।गणित की ईंटों के यादृच्छिक संयोजन जैसे कि +, -, साइन और कोज़ीन के साथ शुरू करते हुए, यूरेका ने डार्विनियन विकासवाद के समान, परीक्षण और त्रुटि के माध्यम से इसे तब तक बदल दिया, जब तक कि यह इन डेटा का वर्णन करने वाले फ़ार्मुलों की बात नहीं हो जाती। वह फिर मॉडल का परीक्षण करने के लिए प्रयोग करती है। इसका एक लाभ सादगी है, लिप्सन कहते हैं। “यूरेका द्वारा विकसित एक मॉडल में आमतौर पर एक दर्जन पैरामीटर होते हैं। तंत्रिका नेटवर्क के लाखों हैं। "ऑटोपायलट पर
पिछले साल, गारखमनी ने एक वैज्ञानिक के काम को डेटा के अनुसार स्वचालित डेटा के लिए कच्चे डेटा से तैयार वैज्ञानिक कार्य के लिए प्रकाशित किया था। इसका सॉफ्टवेयर स्वचालित सांख्यिकीविद्, डेटा सेटों में रुझान और विसंगतियों को नोटिस करता है और तर्क की एक विस्तृत व्याख्या सहित एक राय प्रदान करता है। यह पारदर्शिता, उन्होंने कहा, विज्ञान में उपयोग के लिए "पूरी तरह से महत्वपूर्ण" है, लेकिन व्यावसायिक उपयोग के लिए भी महत्वपूर्ण है। उदाहरण के लिए, कई देशों में, ऋण से इनकार करने वाले बैंक मना करने का कारण स्पष्ट रूप से बताने के लिए बाध्य हैं - और यह गो एल्गोरिथ्म के साथ संभव नहीं हो सकता है।विभिन्न संगठनों में एक ही संदेह है, ओस्लो में अरुंडो एनालिटिक्स में डेटा विज्ञान के निदेशक ऐली डॉब्सन को बताते हैं। यदि, उदाहरण के लिए, ब्रिटेन में बेस रेट में बदलाव के कारण कुछ गलत हो जाता है, तो बैंक ऑफ इंग्लैंड बस यह नहीं कह सकता है "यह सभी ब्लैक बॉक्स के कारण है।"लेकिन, इन सभी आशंकाओं के बावजूद, कंप्यूटर वैज्ञानिक कहते हैं कि पारदर्शी AI बनाने का प्रयास नागरिक सुरक्षा का पूरक होना चाहिए, न कि इस तकनीक का प्रतिस्थापन। कुछ पारदर्शी तकनीकें पहले से ही अमूर्त डेटा के सेट के रूप में वर्णित क्षेत्रों में अच्छी तरह से काम कर सकती हैं, लेकिन धारणा के साथ सामना नहीं करती हैं - कच्चे डेटा के साथ तथ्यों को निकालने की प्रक्रिया।नतीजतन, उनके अनुसार, रक्षा मंत्रालय के लिए धन्यवाद प्राप्त जटिल उत्तर विज्ञान के उपकरणों का हिस्सा होना चाहिए, क्योंकि वास्तविक दुनिया जटिल है। मौसम या वित्तीय बाजार, कटौतीवादी, सिंथेटिक विवरण जैसी घटनाओं के लिए बस मौजूद नहीं हो सकता है। पेरिस पॉलिटेक्निक के एक गणितज्ञ स्टीफन मल्लात कहते हैं, "ऐसी चीजें हैं जिन्हें शब्दों में वर्णित नहीं किया जा सकता है।" "जब आप एक डॉक्टर से पूछते हैं कि उसने ऐसा निदान क्यों किया है, तो वह आपके लिए कारणों का वर्णन करेगा," वे कहते हैं। - लेकिन फिर आपको एक अच्छा डॉक्टर बनने के लिए 20 साल की आवश्यकता क्यों है? क्योंकि जानकारी न केवल पुस्तकों से प्राप्त की जाती है। ”बाल्दी के अनुसार, वैज्ञानिक को जीओ को स्वीकार करना चाहिए और ब्लैक बॉक्स के बारे में नहीं समझना चाहिए। उनके सिर में ऐसा ब्लैक बॉक्स है। "आप लगातार मस्तिष्क का उपयोग करते हैं, आप हमेशा इस पर भरोसा करते हैं, और आप यह नहीं समझते कि यह कैसे काम करता है।"Source: https://habr.com/ru/post/hi398451/
All Articles