तंत्रिका नेटवर्क पर टेलीविजन पर होंठों पर 46.8% शब्द पढ़ते हैं, जबकि केवल 12.4% लोग
 चार कार्यक्रमों के फ्रेम, जिस पर कार्यक्रम का अध्ययन किया गया था, साथ ही साथ "दोपहर" शब्द, दो अलग-अलग वक्ताओं द्वारा बोला गयाथा दो हफ्ते पहले, उन्होंने लिपनेट न्यूरल नेटवर्क के बारे में बात की थी , जिसमें होंठों पर 93.4% मानव भाषण मान्यता का रिकॉर्ड गुणवत्ता दिखाया गया था। फिर भी, ऐसे कंप्यूटर सिस्टम के लिए कई एप्लिकेशन चाहिए थे: स्पीच रिकग्निशन के साथ मेडिकल हियरिंग एड की नई पीढ़ी, सार्वजनिक स्थानों पर साइलेंट लेक्चर के लिए सिस्टम, बायोमेट्रिक पहचान, जासूसी के लिए गुप्त प्रसारण के लिए सिस्टम, सर्विलांस कैमरों से वीडियो द्वारा भाषण पहचान आदि। और अब, ऑक्सफोर्ड विश्वविद्यालय के विशेषज्ञों ने Google DeepMind कर्मचारी के साथ मिलकर इस क्षेत्र में अपने स्वयं के विकास के बारे में बताया ।नए तंत्रिका नेटवर्क को बीबीसी टेलीविजन चैनल पर अभिनय करने वाले लोगों के मनमाने ग्रंथों पर प्रशिक्षित किया गया था । दिलचस्प है, प्रशिक्षण स्वचालित रूप से किया गया था, पहले भाषण को मैन्युअल रूप से एनोटेट किए बिना। सिस्टम ने स्वयं ही भाषण को मान्यता दी, वीडियो को एनोटेट किया, फ्रेम में चेहरे पाए, और फिर शब्दों (ध्वनियों) और होंठ आंदोलन के बीच संबंध निर्धारित करना सीखा।नतीजतन, यह प्रणाली प्रभावी ढंग से मनमाने ढंग से ग्रंथों को पहचानती है, जीआरआईडी वाक्यों के विशेष कोष से उदाहरणों के बजाय, जैसा कि लिपनेट ने किया था। जीआरआईडी मामले में एक सख्त सीमित संरचना और शब्दावली है, इसलिए, केवल 33,000 वाक्य संभव हैं। इस प्रकार, विकल्पों की संख्या परिमाण के आदेशों से कम हो जाती है और मान्यता सरल हो जाती है।विशेष जीआरआईडी मामला इस प्रकार बना है:कमांड (4) + रंग (4) + प्रीपोजिशन (4) + अक्षर (25) + अंक (10) + क्रिया विशेषण (4),जहां संख्या छह मौखिक श्रेणियों में से प्रत्येक के लिए शब्द वेरिएंट की संख्या से मेल खाती है।लिपनेट के विपरीत, डीपमाइंड का विकास और ऑक्सफोर्ड विश्वविद्यालय के विशेषज्ञ टेलीविजन पिक्चर क्वालिटी पर मनमाने भाषण धाराओं पर काम करते हैं। यह व्यावहारिक उपयोग के लिए तैयार एक वास्तविक प्रणाली की तरह बहुत अधिक है।एआई ने जनवरी 2010 से दिसंबर 2015 तक ब्रिटिश बीबीसी टेलीविजन चैनल के छह टेलीविज़न शो से रिकॉर्ड किए गए 5,000 घंटे के वीडियो को प्रशिक्षित किया: ये नियमित समाचार रिलीज़ (1584 घंटे), सुबह समाचार (1997 घंटे), न्यूज़नाइट प्रसारण (590 घंटे), वर्ल्ड न्यूज़ (194) हैं। घंटे), प्रश्न समय (323 घंटे) और वर्ल्ड टुडे (272 घंटे)। कुल मिलाकर, वीडियो में निरंतर मानव भाषण के 118,116 वाक्य हैं।उसके बाद, मार्च और सितंबर 2016 के बीच प्रसारित होने वाले प्रसारणों पर कार्यक्रम की जाँच की गई।
चार कार्यक्रमों के फ्रेम, जिस पर कार्यक्रम का अध्ययन किया गया था, साथ ही साथ "दोपहर" शब्द, दो अलग-अलग वक्ताओं द्वारा बोला गयाथा दो हफ्ते पहले, उन्होंने लिपनेट न्यूरल नेटवर्क के बारे में बात की थी , जिसमें होंठों पर 93.4% मानव भाषण मान्यता का रिकॉर्ड गुणवत्ता दिखाया गया था। फिर भी, ऐसे कंप्यूटर सिस्टम के लिए कई एप्लिकेशन चाहिए थे: स्पीच रिकग्निशन के साथ मेडिकल हियरिंग एड की नई पीढ़ी, सार्वजनिक स्थानों पर साइलेंट लेक्चर के लिए सिस्टम, बायोमेट्रिक पहचान, जासूसी के लिए गुप्त प्रसारण के लिए सिस्टम, सर्विलांस कैमरों से वीडियो द्वारा भाषण पहचान आदि। और अब, ऑक्सफोर्ड विश्वविद्यालय के विशेषज्ञों ने Google DeepMind कर्मचारी के साथ मिलकर इस क्षेत्र में अपने स्वयं के विकास के बारे में बताया ।नए तंत्रिका नेटवर्क को बीबीसी टेलीविजन चैनल पर अभिनय करने वाले लोगों के मनमाने ग्रंथों पर प्रशिक्षित किया गया था । दिलचस्प है, प्रशिक्षण स्वचालित रूप से किया गया था, पहले भाषण को मैन्युअल रूप से एनोटेट किए बिना। सिस्टम ने स्वयं ही भाषण को मान्यता दी, वीडियो को एनोटेट किया, फ्रेम में चेहरे पाए, और फिर शब्दों (ध्वनियों) और होंठ आंदोलन के बीच संबंध निर्धारित करना सीखा।नतीजतन, यह प्रणाली प्रभावी ढंग से मनमाने ढंग से ग्रंथों को पहचानती है, जीआरआईडी वाक्यों के विशेष कोष से उदाहरणों के बजाय, जैसा कि लिपनेट ने किया था। जीआरआईडी मामले में एक सख्त सीमित संरचना और शब्दावली है, इसलिए, केवल 33,000 वाक्य संभव हैं। इस प्रकार, विकल्पों की संख्या परिमाण के आदेशों से कम हो जाती है और मान्यता सरल हो जाती है।विशेष जीआरआईडी मामला इस प्रकार बना है:कमांड (4) + रंग (4) + प्रीपोजिशन (4) + अक्षर (25) + अंक (10) + क्रिया विशेषण (4),जहां संख्या छह मौखिक श्रेणियों में से प्रत्येक के लिए शब्द वेरिएंट की संख्या से मेल खाती है।लिपनेट के विपरीत, डीपमाइंड का विकास और ऑक्सफोर्ड विश्वविद्यालय के विशेषज्ञ टेलीविजन पिक्चर क्वालिटी पर मनमाने भाषण धाराओं पर काम करते हैं। यह व्यावहारिक उपयोग के लिए तैयार एक वास्तविक प्रणाली की तरह बहुत अधिक है।एआई ने जनवरी 2010 से दिसंबर 2015 तक ब्रिटिश बीबीसी टेलीविजन चैनल के छह टेलीविज़न शो से रिकॉर्ड किए गए 5,000 घंटे के वीडियो को प्रशिक्षित किया: ये नियमित समाचार रिलीज़ (1584 घंटे), सुबह समाचार (1997 घंटे), न्यूज़नाइट प्रसारण (590 घंटे), वर्ल्ड न्यूज़ (194) हैं। घंटे), प्रश्न समय (323 घंटे) और वर्ल्ड टुडे (272 घंटे)। कुल मिलाकर, वीडियो में निरंतर मानव भाषण के 118,116 वाक्य हैं।उसके बाद, मार्च और सितंबर 2016 के बीच प्रसारित होने वाले प्रसारणों पर कार्यक्रम की जाँच की गई।एक टेलीविजन स्क्रीन से होंठ पढ़ने का एक उदाहरण कार्यक्रम में पढ़ने की काफी उच्च गुणवत्ता दिखाई गई। उसने असामान्य व्याकरणिक निर्माणों और उचित नामों के उपयोग के साथ बहुत जटिल वाक्यों को भी सही ढंग से पहचाना। पूरी तरह से मान्यता प्राप्त वाक्यों के उदाहरण:- अधिक लोगों को एटैक में शामिल किया गया था
- CLOSE TO THE EUROPEAN COMMISSION’S MAIN BUILDING
- WEST WALES AND THE SOUTH WEST AS WELL AS WESTERN SCOTLAND
- WE KNOW THERE WILL BE HUNDREDS OF JOURNALISTS HERE AS WELL
- ACCORDING TO PROVISIONAL FIGURES FROM THE ELECTORAL COMMISSION
- THAT’S THE LOWEST FIGURE FOR EIGHT YEARS
- MANCHESTER FOOTBALL CORRESPONDENT FOR THE DAILY MIRROR
- LAYING THE GROUNDS FOR A POSSIBLE SECOND REFERENDUM
- ACCORDING TO THE LATEST FIGURES FROM THE OFFICE FOR NATIONAL STATISTICS
- IT COMES AFTER A DAMNING REPORT BY THE HEALTH WATCHDOG
एआई काफी हद तक एक व्यक्ति के काम की प्रभावशीलता को पार कर गया, होंठ पढ़ने पर एक विशेषज्ञ, जिसने एक रिकॉर्ड किए गए सत्यापन संग्रह संग्रह से 200 यादृच्छिक वीडियो क्लिप को पहचानने की कोशिश की।पेशेवर केवल 12.4% शब्दों की गलती के बिना एनोटेट करने में सक्षम था, जबकि एआई ने सही ढंग से 46.8% दर्ज किया। शोधकर्ताओं ने ध्यान दिया कि कई त्रुटियों को मामूली कहा जा सकता है। उदाहरण के लिए, शब्दों के अंत में लापता "एस"। यदि हम परिणामों का विश्लेषण कम सख्ती से करते हैं, तो वास्तव में प्रणाली ने हवा पर आधे से अधिक शब्दों को मान्यता दी।इस परिणाम के साथ, दीपमिन्द अन्य सभी होंठ पाठकों से काफी बेहतर है, जिसमें उपरोक्त लिपनेट भी शामिल है, जिसे ऑक्सफोर्ड विश्वविद्यालय द्वारा भी विकसित किया गया है। हालाँकि, परम श्रेष्ठता के बारे में बोलना जल्दबाजी होगी, क्योंकि इतने बड़े डेटा सेट पर लिपनेट को प्रशिक्षित नहीं किया गया था। विशेषज्ञों केअनुसार , डीपमाइंड पूरी तरह से स्वचालित लिप रीडिंग सिस्टम विकसित करने की दिशा में एक बड़ा कदम है। WLAS मॉड्यूल की वास्तुकला (वॉच, लिसन, अटेंड एंड स्पेल) और होठों को पढ़ने के लिए एक दृढ़ तंत्रिका नेटवर्क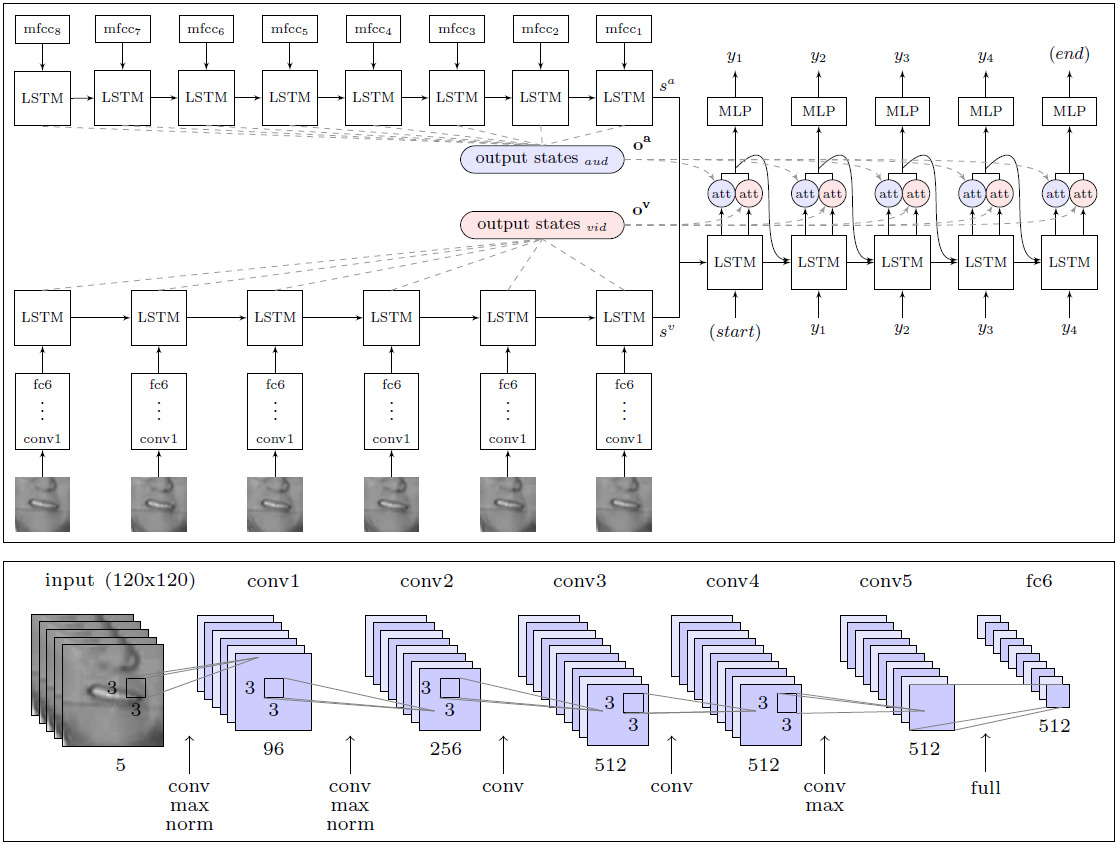 शोधकर्ताओं की महान योग्यता इस तथ्य में निहित है कि उन्होंने 17,500 अद्वितीय शब्दों के साथ प्रणाली के प्रशिक्षण और परीक्षण के लिए एक विशाल डेटा सेट संकलित किया। आखिरकार, यह अच्छी अंग्रेजी में टेलीविजन कार्यक्रमों की सिर्फ पांच साल की निरंतर रिकॉर्डिंग नहीं है, बल्कि वीडियो और ध्वनि का स्पष्ट सिंक्रनाइज़ेशन भी है (टीवी पर अक्सर पेशेवर अंग्रेजी टेलीविजन पर भी 1 सेकंड तक सिंक होता है), साथ ही भाषण मान्यता के लिए एक मॉड्यूल का विकास, जो सुपरिम्पोज किया गया है वीडियो पर और लिप रीडिंग सिस्टम (WLAS मॉड्यूल, ऊपर चित्र देखें) को पढ़ाने में उपयोग किया जाता है।थोड़ी सी भी rassynchron के मामले में, प्रशिक्षण व्यावहारिक रूप से बेकार हो जाता है, क्योंकि कार्यक्रम ध्वनियों और होंठ आंदोलनों के सही पत्राचार का निर्धारण नहीं कर सकता है। पूरी तरह से तैयारी के बाद, कार्यक्रम का प्रशिक्षण पूरी तरह से स्वचालित था - इसने सभी 5000 वीडियो को स्वतंत्र रूप से संसाधित किया।पहले, इस तरह के एक सेट बस मौजूद नहीं था, इसलिए उसी लिपनेट लेखकों को खुद को जीआरआईडी आधार तक सीमित करने के लिए मजबूर किया गया था। डीपमाइंड डेवलपर्स के क्रेडिट के लिए, उन्होंने अन्य एआई को प्रशिक्षण देने के लिए सार्वजनिक डोमेन में डेटा सेट प्रकाशित करने का वादा किया। लिपनेट विकास टीम के सहकर्मी पहले ही कह चुके हैं कि वे इसके लिए तत्पर हैं।वैज्ञानिक कार्य सार्वजनिक डोमेन में arXiv वेबसाइट (arXiv: 1611.05358v1) पर प्रकाशित होता है।यदि वाणिज्यिक लिप-रीडिंग सिस्टम बाजार पर दिखाई देते हैं, तो आम लोगों का जीवन बहुत सरल होगा। यह माना जा सकता है कि इस तरह के सिस्टम को तुरंत आवाज नियंत्रण और लगभग त्रुटि मुक्त भाषण मान्यता में सुधार के लिए टीवी और अन्य घरेलू उपकरणों में बनाया जाएगा।
शोधकर्ताओं की महान योग्यता इस तथ्य में निहित है कि उन्होंने 17,500 अद्वितीय शब्दों के साथ प्रणाली के प्रशिक्षण और परीक्षण के लिए एक विशाल डेटा सेट संकलित किया। आखिरकार, यह अच्छी अंग्रेजी में टेलीविजन कार्यक्रमों की सिर्फ पांच साल की निरंतर रिकॉर्डिंग नहीं है, बल्कि वीडियो और ध्वनि का स्पष्ट सिंक्रनाइज़ेशन भी है (टीवी पर अक्सर पेशेवर अंग्रेजी टेलीविजन पर भी 1 सेकंड तक सिंक होता है), साथ ही भाषण मान्यता के लिए एक मॉड्यूल का विकास, जो सुपरिम्पोज किया गया है वीडियो पर और लिप रीडिंग सिस्टम (WLAS मॉड्यूल, ऊपर चित्र देखें) को पढ़ाने में उपयोग किया जाता है।थोड़ी सी भी rassynchron के मामले में, प्रशिक्षण व्यावहारिक रूप से बेकार हो जाता है, क्योंकि कार्यक्रम ध्वनियों और होंठ आंदोलनों के सही पत्राचार का निर्धारण नहीं कर सकता है। पूरी तरह से तैयारी के बाद, कार्यक्रम का प्रशिक्षण पूरी तरह से स्वचालित था - इसने सभी 5000 वीडियो को स्वतंत्र रूप से संसाधित किया।पहले, इस तरह के एक सेट बस मौजूद नहीं था, इसलिए उसी लिपनेट लेखकों को खुद को जीआरआईडी आधार तक सीमित करने के लिए मजबूर किया गया था। डीपमाइंड डेवलपर्स के क्रेडिट के लिए, उन्होंने अन्य एआई को प्रशिक्षण देने के लिए सार्वजनिक डोमेन में डेटा सेट प्रकाशित करने का वादा किया। लिपनेट विकास टीम के सहकर्मी पहले ही कह चुके हैं कि वे इसके लिए तत्पर हैं।वैज्ञानिक कार्य सार्वजनिक डोमेन में arXiv वेबसाइट (arXiv: 1611.05358v1) पर प्रकाशित होता है।यदि वाणिज्यिक लिप-रीडिंग सिस्टम बाजार पर दिखाई देते हैं, तो आम लोगों का जीवन बहुत सरल होगा। यह माना जा सकता है कि इस तरह के सिस्टम को तुरंत आवाज नियंत्रण और लगभग त्रुटि मुक्त भाषण मान्यता में सुधार के लिए टीवी और अन्य घरेलू उपकरणों में बनाया जाएगा।Source: https://habr.com/ru/post/hi399429/
All Articles