
20 वीं शताब्दी की शुरुआत में, एक जर्मन घोड़ा ट्रेनर और गणितज्ञ विल्हेम वॉन ऑस्टिन ने दुनिया को घोषणा की कि उन्होंने एक घोड़े को गिनना सिखाया है। सालों तक, वॉन ऑस्टिन ने इस घटना के प्रदर्शन के साथ जर्मनी की यात्रा की। उन्होंने अपने घोड़े का नाम,
क्लीवर हंस (नस्ल
ओरलोव ट्रॉटर ), सरल समीकरणों के परिणामों की गणना करने के लिए कहा। हंस ने जवाब दिया, उसके खुर का मोहर लगाना। दो प्लस दो? चार हिट।
लेकिन वैज्ञानिकों ने यह नहीं माना कि हंस उतना ही स्मार्ट था जितना कि वॉन ऑस्टिन ने दावा किया था। मनोवैज्ञानिक
कार्ल स्टम्पफ ने पूरी जांच की, जिसे "हंस कमेटी" करार दिया गया। उन्होंने पाया कि स्मार्ट हंस समीकरणों को हल नहीं करता है, लेकिन दृश्य संकेतों का जवाब देता है। हंस ने सही जवाब न मिलने तक अपने खुरों का दोहन किया, जिसके बाद उनके कोच और एक उत्साही भीड़ चीख-पुकार मच गई। और फिर वह बस रुक गया। जब उसने इन प्रतिक्रियाओं को नहीं देखा, तो उसने दस्तक देना जारी रखा।
कंप्यूटर विज्ञान हंस से बहुत कुछ सीख सकता है। इस क्षेत्र में विकास की तेज गति से पता चलता है कि हमारे द्वारा बनाए गए अधिकांश AI ने सही उत्तर प्रदान करने के लिए पर्याप्त प्रशिक्षण दिया है, लेकिन वास्तव में जानकारी को नहीं समझते हैं। और मूर्ख बनाना आसान है।
मशीन लर्निंग एल्गोरिदम तेजी से मानव झुंड के सभी-चरवाहों में बदल गया। सॉफ्टवेयर हमें इंटरनेट से जोड़ता है, हमारे मेल में स्पैम और दुर्भावनापूर्ण सामग्री की निगरानी करता है, और जल्द ही हमारी कारों को चलाएगा। उनका धोखा इंटरनेट की टेक्टॉनिक नींव को हिला देता है, और भविष्य में हमारी सुरक्षा के लिए खतरा है।
छोटे अनुसंधान समूह - पेंसिल्वेनिया स्टेट यूनिवर्सिटी, गूगल से, अमेरिकी सेना से - एआई पर संभावित हमलों से बचाने के लिए योजनाएं विकसित कर रहे हैं। अध्ययन में सामने आए सिद्धांतों में कहा गया है कि एक हमलावर "रोबोट" को देख सकता है। या फोन पर ध्वनि पहचान को सक्रिय करें और ध्वनियों का उपयोग करके एक दुर्भावनापूर्ण वेबसाइट में प्रवेश करने के लिए मजबूर करें जो केवल एक व्यक्ति के लिए शोर होगा। या नेटवर्क फ़ायरवॉल के माध्यम से वायरस को लीक होने दें।
 बाईं ओर भवन की छवि है, दाईं ओर संशोधित छवि है, जिसका गहरा तंत्रिका नेटवर्क शुतुरमुर्ग से संबंधित है। बीच में, प्राथमिक छवि पर लागू सभी परिवर्तन दिखाए गए हैं।
बाईं ओर भवन की छवि है, दाईं ओर संशोधित छवि है, जिसका गहरा तंत्रिका नेटवर्क शुतुरमुर्ग से संबंधित है। बीच में, प्राथमिक छवि पर लागू सभी परिवर्तन दिखाए गए हैं।एक रोबोमोबाइल के नियंत्रण का नियंत्रण लेने के बजाय, यह विधि उसे एक मतिभ्रम जैसा कुछ दिखाती है - एक ऐसी छवि जो वास्तव में मौजूद नहीं है।
इस तरह के हमले एक चाल के साथ छवियों का उपयोग करते हैं [प्रतिकूल उदाहरण - कोई स्थापित रूसी शब्द नहीं है, शब्दशः यह "विपरीत के साथ उदाहरण" या "प्रतिद्वंद्वी उदाहरण" की तरह कुछ बाहर निकलता है - लगभग। अनुवाद।]: चित्र, ध्वनियाँ, पाठ जो लोगों को सामान्य दिखते हैं लेकिन एक पूरी तरह से अलग मशीन द्वारा माना जाता है। हमलावरों द्वारा किए गए छोटे बदलाव गहरे तंत्रिका नेटवर्क को गलत निष्कर्ष निकालने के लिए पैदा कर सकते हैं जो इसे दिखाता है।
"कोई भी प्रणाली जो सुरक्षा-महत्वपूर्ण निर्णय लेने के लिए मशीन लर्निंग का उपयोग करती है, वह इस प्रकार के हमले के लिए संभावित रूप से कमजोर होती है," बर्कले विश्वविद्यालय के एक शोधकर्ता एलेक्स कंचेलिन ने कहा, जो स्पूफ इमेज का उपयोग करके मशीन लर्निंग हमलों का अध्ययन करता है।
एआई विकास के शुरुआती चरणों में इन बारीकियों को जानने से शोधकर्ताओं को यह समझने का उपकरण मिलता है कि इन कमियों को कैसे ठीक किया जाए। कुछ ने पहले ही इसे ले लिया है, और वे कहते हैं कि उनके एल्गोरिदम इस कारण अधिक से अधिक कुशल हो गए हैं।
एआई अनुसंधान की अधिकांश मुख्य धारा गहरे तंत्रिका नेटवर्क पर आधारित है, जो मशीन सीखने के व्यापक क्षेत्र पर आधारित है। MoD प्रौद्योगिकियां हम में से अधिकांश द्वारा उपयोग किए जाने वाले सॉफ़्टवेयर बनाने के लिए अंतर और अभिन्न कलन और आँकड़ों का उपयोग करती हैं, जैसे मेल में स्पैम फ़िल्टर या इंटरनेट पर खोज। पिछले 20 वर्षों में, शोधकर्ताओं ने इन तकनीकों को एक नए विचार, तंत्रिका नेटवर्क - सॉफ्टवेयर संरचनाओं के लिए लागू करना शुरू कर दिया है जो मस्तिष्क समारोह की नकल करते हैं। यह विचार हजारों छोटे समीकरणों ("न्यूरॉन्स") की गणना को विकेन्द्रीकृत करने के लिए है जो डेटा प्राप्त करते हैं, प्रक्रिया करते हैं और उन्हें हजारों छोटे समीकरणों की अगली परत तक पहुंचाते हैं।
ये एआई एल्गोरिदम को उसी तरह से प्रशिक्षित किया जाता है जैसे कि एमओ के मामले में, जो बदले में, किसी व्यक्ति की सीखने की प्रक्रिया की नकल करता है। उन्हें विभिन्न चीजों और उनके संबंधित टैग के उदाहरण दिखाए जाते हैं। कंप्यूटर (या बच्चे) को बिल्ली की छवि दिखाएं, कहें कि बिल्ली इस तरह दिखती है, और एल्गोरिथ्म बिल्लियों को पहचानना सीखेगा। लेकिन इसके लिए, कंप्यूटर को बिल्लियों और बिल्लियों की हजारों और लाखों छवियों को देखना होगा।
शोधकर्ताओं ने पता लगाया है कि इन प्रणालियों पर विशेष रूप से चयनित भ्रामक डेटा के साथ हमला किया जा सकता है, जिसे उन्होंने "प्रतिकूल उदाहरण" कहा।
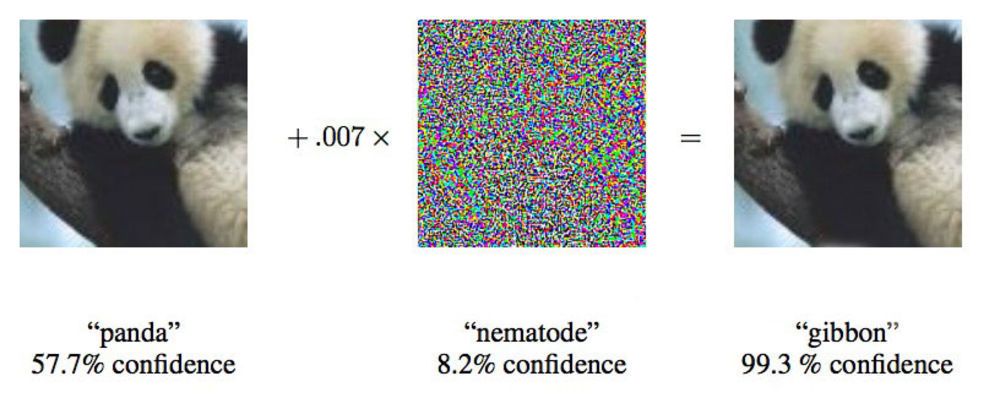 2015 के एक पेपर में, Google के शोधकर्ताओं ने दिखाया कि गहरे तंत्रिका नेटवर्क को पांडा की इस छवि को रिबन के लिए मजबूर करने के लिए मजबूर किया जा सकता है।
2015 के एक पेपर में, Google के शोधकर्ताओं ने दिखाया कि गहरे तंत्रिका नेटवर्क को पांडा की इस छवि को रिबन के लिए मजबूर करने के लिए मजबूर किया जा सकता है।"हम आपको एक तस्वीर दिखाते हैं जो स्पष्ट रूप से स्कूल बस को दिखाती है, और आपको लगता है कि यह एक शुतुरमुर्ग है," Google के शोधकर्ता इयान गुडफेलो ने कहा, जो तंत्रिका नेटवर्क पर इस तरह के हमलों पर सक्रिय रूप से काम कर रहा है।
केवल 4% द्वारा तंत्रिका नेटवर्क को प्रदान की गई छवियों को बदलना, शोधकर्ताओं ने 97% मामलों में वर्गीकरण के साथ गलतियां करने में उन्हें मुश्किल में डाल दिया। यहां तक कि अगर उन्हें नहीं पता था कि तंत्रिका नेटवर्क छवियों को कैसे संसाधित करता है, तो वे 85% मामलों में इसे धोखा दे सकते हैं। नेटवर्क आर्किटेक्चर पर डेटा के बिना धोखाधड़ी
का अंतिम संस्करण "ब्लैक बॉक्स अटैक" कहलाता है। यह एक गहरे तंत्रिका नेटवर्क पर इस तरह के एक कार्यात्मक हमले का पहला प्रलेखित मामला है, और इसका महत्व यह है कि इस परिदृश्य में लगभग वास्तविक दुनिया में हमले हो सकते हैं।
अध्ययन में, पेंसिल्वेनिया स्टेट यूनिवर्सिटी, Google और यूएस नेवी रिसर्च लेबोरेटरी के शोधकर्ताओं ने एक तंत्रिका नेटवर्क पर हमला किया, जो मेटामाइंड परियोजना द्वारा समर्थित छवियों को वर्गीकृत करता है और डेवलपर्स के लिए ऑनलाइन टूल के रूप में कार्य करता है। टीम ने हमले किए गए नेटवर्क का निर्माण और प्रशिक्षण किया, लेकिन उनके हमले के एल्गोरिदम ने वास्तुकला की परवाह किए बिना काम किया। इस तरह के एक एल्गोरिथ्म के साथ, वे 84.24% की सटीकता के साथ ब्लैक बॉक्स न्यूरल नेटवर्क को धोखा देने में सक्षम थे।
 फ़ोटो और पात्रों की शीर्ष पंक्ति - सही वर्ण पहचान।
फ़ोटो और पात्रों की शीर्ष पंक्ति - सही वर्ण पहचान।
निचला पंक्ति - नेटवर्क को संकेतों को पूरी तरह से गलत पहचानने के लिए मजबूर किया गया था।मशीनों को गलत डेटा खिलाना कोई नया विचार नहीं है, लेकिन बर्कले विश्वविद्यालय के एक प्रोफेसर डग टाइगर, जो इसके विपरीत 10 वर्षों से मशीन सीखने का अध्ययन कर रहे हैं, का कहना है कि यह हमले की तकनीक एक साधारण MO से जटिल गहरे तंत्रिका नेटवर्क में विकसित हुई है। दुर्भावनापूर्ण हैकर्स सालों से स्पैम फिल्टर पर इस तकनीक का उपयोग कर रहे हैं।
टाइगर का शोध
2006 में रक्षा मंत्रालय के साथ एक नेटवर्क पर इस तरह के हमलों पर
काम करता है, जिसका
विस्तार उन्होंने 2011 में बर्कले और कैलिफोर्निया अनुसंधान विश्वविद्यालय के शोधकर्ताओं की मदद से किया था। Google न्यूरल नेटवर्क का उपयोग करने वाली पहली टीम ने इस तरह के हमलों की संभावना की खोज के दो साल बाद 2014 में अपना
पहला काम प्रकाशित किया। वे यह सुनिश्चित करना चाहते थे कि यह किसी प्रकार की विसंगति नहीं थी, बल्कि वास्तविक संभावना थी। 2015 में, उन्होंने एक और
काम प्रकाशित किया जिसमें उन्होंने नेटवर्क की रक्षा करने और अपनी दक्षता बढ़ाने का एक तरीका बताया, और इयान गुडफेलो ने इस क्षेत्र में अन्य वैज्ञानिक कार्यों पर सलाह दी, जिसमें
ब्लैक बॉक्स हमला भी शामिल है ।
शोधकर्ता अविश्वसनीय जानकारी "बीजान्टिन डेटा" के अधिक सामान्य विचार को कहते हैं और अनुसंधान की प्रगति के लिए धन्यवाद, वे गहरी शिक्षा के लिए आए हैं। यह शब्द कंप्यूटर विज्ञान के क्षेत्र में एक सुविचारित प्रयोग "
बीजान्टिन जनरलों के कार्य " से आया है, जिसमें जनरलों के एक समूह को दूतों की मदद से अपने कार्यों का समन्वय करना होगा, इस विश्वास के बिना कि उनमें से एक देशद्रोही है। वे अपने सहयोगियों से प्राप्त जानकारी पर भरोसा नहीं कर सकते।
"इन एल्गोरिदम को यादृच्छिक शोर को संभालने के लिए डिज़ाइन किया गया है, लेकिन बीजान्टिन डेटा नहीं," टैगर कहते हैं। यह समझने के लिए कि इस तरह के हमले कैसे काम करते हैं, गुडफ़ेलो एक फैलाव आरेख के रूप में एक तंत्रिका नेटवर्क की कल्पना करने का सुझाव देता है।
आरेख में प्रत्येक बिंदु तंत्रिका नेटवर्क द्वारा संसाधित छवि के एक पिक्सेल का प्रतिनिधित्व करता है। आमतौर पर, नेटवर्क डेटा के माध्यम से एक रेखा खींचने की कोशिश करता है जो सभी बिंदुओं के सेट को सबसे अच्छी तरह से फिट करता है। व्यवहार में, यह थोड़ा अधिक जटिल है, क्योंकि विभिन्न पिक्सल के नेटवर्क के लिए अलग-अलग मूल्य हैं। वास्तव में, यह कंप्यूटर द्वारा संसाधित एक जटिल बहुआयामी ग्राफ है।
लेकिन एक स्कैप्लेट के हमारे सरल सादृश्य में, डेटा के माध्यम से खींची गई रेखा का आकार यह निर्धारित करता है कि नेटवर्क क्या सोचता है कि वह देखता है। ऐसी प्रणालियों पर एक सफल हमले के लिए, शोधकर्ताओं को इन बिंदुओं का केवल एक छोटा सा हिस्सा बदलने की जरूरत है, और नेटवर्क को ऐसा निर्णय लेने की आवश्यकता है जो वास्तव में मौजूद नहीं है। शुतुरमुर्ग की तरह दिखने वाली बस के उदाहरण में, स्कूल बस की तस्वीर को नेटवर्क से परिचित शुतुरमुर्ग की अनूठी विशेषताओं से जुड़े पैटर्न के अनुसार व्यवस्थित पिक्सल के साथ बिंदीदार किया गया है। यह आंख के लिए एक अदृश्य समोच्च है, लेकिन जब एल्गोरिथ्म
प्रक्रिया करता है और डेटा को सरल करता है , तो शुतुरमुर्ग के लिए चरम डेटा बिंदु यह एक उपयुक्त वर्गीकरण विकल्प लगता है। ब्लैक बॉक्स संस्करण में, शोधकर्ताओं ने यह निर्धारित करने के लिए अलग-अलग इनपुट डेटा के साथ काम किया कि एल्गोरिथ्म कुछ वस्तुओं को कैसे देखता है।
ऑब्जेक्ट क्लासिफायर फर्जी इनपुट देकर और मशीन द्वारा किए गए निर्णयों का अध्ययन करके, शोधकर्ता छवि प्रणाली को धोखा देने के लिए एल्गोरिथ्म को पुनर्स्थापित करने में सक्षम थे। संभावित रूप से, इस मामले में रोबोमेबल्स में ऐसी प्रणाली स्टॉप साइन के बजाय "रास्ता दे" साइन देख सकती है। जब वे समझ गए कि नेटवर्क कैसे काम करता है, तो वे मशीन को कुछ भी देखने में सक्षम थे।
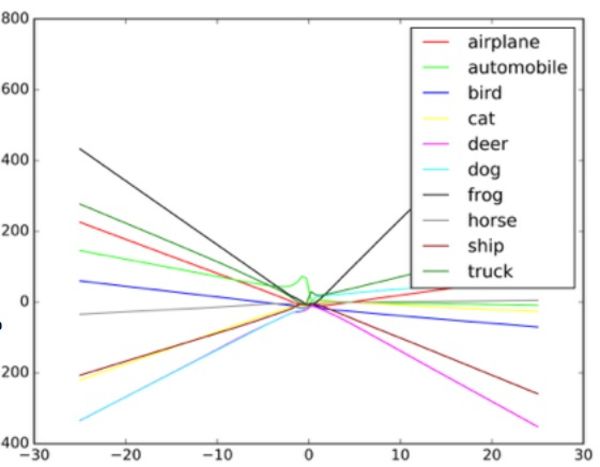 छवि क्लासीफायर छवि में अलग-अलग वस्तुओं के आधार पर अलग-अलग रेखाएं कैसे खींचता है इसका एक उदाहरण। नकली उदाहरणों को ग्राफ पर चरम मूल्यों के रूप में माना जा सकता है।
छवि क्लासीफायर छवि में अलग-अलग वस्तुओं के आधार पर अलग-अलग रेखाएं कैसे खींचता है इसका एक उदाहरण। नकली उदाहरणों को ग्राफ पर चरम मूल्यों के रूप में माना जा सकता है।शोधकर्ताओं का कहना है कि इस तरह के हमले को छवि प्रसंस्करण प्रणाली में सीधे प्रवेश किया जा सकता है, कैमरे को दरकिनार किया जा सकता है, या इन जोड़तोड़ों को एक वास्तविक संकेत के साथ किया जा सकता है।
लेकिन कोलंबिया विश्वविद्यालय के सुरक्षा विशेषज्ञ, एलिसन बिशप ने कहा कि इस तरह का पूर्वानुमान अवास्तविक है, और रॉबटेल में इस्तेमाल की जाने वाली प्रणाली पर निर्भर करता है। यदि हमलावरों के पास पहले से ही कैमरे से डेटा स्ट्रीम तक पहुंच है, तो वे पहले से ही कोई इनपुट दे सकते हैं।
"अगर वे कैमरे के प्रवेश द्वार तक पहुंच सकते हैं, तो ऐसी कठिनाइयों की आवश्यकता नहीं है," वह कहती हैं। "आप उसे स्टॉप साइन दिखा सकते हैं।"
अन्य हमले के तरीकों, कैमरे को दरकिनार करने के अलावा - उदाहरण के लिए, एक वास्तविक संकेत पर दृश्य चिह्न खींचना, बिशप की संभावना नहीं है। उसे संदेह है कि रोबोमोबाइल्स पर उपयोग किए जाने वाले कम रिज़ॉल्यूशन वाले कैमरे आम तौर पर साइन में होने वाले छोटे बदलावों के बीच अंतर करने में सक्षम होंगे।
 बाईं ओर की प्राचीन छवि को स्कूल बस के रूप में वर्गीकृत किया गया है। सही पर सही किया - एक शुतुरमुर्ग की तरह। बीच में - तस्वीर बदलती है।
बाईं ओर की प्राचीन छवि को स्कूल बस के रूप में वर्गीकृत किया गया है। सही पर सही किया - एक शुतुरमुर्ग की तरह। बीच में - तस्वीर बदलती है।दो समूहों, एक बर्कले विश्वविद्यालय में और दूसरा जॉर्जटाउन विश्वविद्यालय में, सफलतापूर्वक एल्गोरिदम विकसित किया है जो सिरी और Google नाओ जैसे डिजिटल सहायकों को भाषण कमांड जारी कर सकते हैं, जो अश्रव्य शोर की तरह लगते हैं। किसी व्यक्ति के लिए, ऐसे आदेश यादृच्छिक शोर की तरह प्रतीत होंगे, लेकिन साथ ही वे एलेक्सा जैसे उपकरणों को कमांड दे सकते हैं, न कि उनके मालिक द्वारा पूर्वाभास।
बीजान्टिन ऑडियो हमलों में शोधकर्ताओं में से एक निकोलस कार्लिनी का कहना है कि उनके परीक्षणों में वे 90% से अधिक सटीकता के साथ ओपन-सोर्स ऑडियो मान्यता कार्यक्रमों, सिरी और Google नाओ को सक्रिय करने में सक्षम थे।
शोर कुछ हद तक विज्ञान कथा विदेशी बातचीत की तरह है। यह सफेद शोर और एक मानवीय आवाज का मिश्रण है, लेकिन यह वॉयस कमांड की तरह बिल्कुल नहीं है।
कार्लिनी के अनुसार, इस तरह के हमले में, जिसने भी फोन का शोर सुना (जबकि आईओएस और एंड्रॉइड पर अलग से हमले की योजना बनाना आवश्यक है) को एक वेब पेज पर जाने के लिए मजबूर किया जा सकता है जो शोर भी खेलता है, जो पास में स्थित फोन को संक्रमित करेगा। या यह पृष्ठ चुपचाप एक मैलवेयर प्रोग्राम डाउनलोड कर सकता है। यह भी संभव है कि ऐसे शोर रेडियो पर खो जाएंगे, और वे सफेद शोर में या अन्य ऑडियो जानकारी के समानांतर में छिपे होंगे।
इस तरह के हमले हो सकते हैं क्योंकि मशीन को यह सुनिश्चित करने के लिए प्रशिक्षित किया जाता है कि लगभग किसी भी डेटा में महत्वपूर्ण डेटा शामिल है, साथ ही साथ एक चीज दूसरे की तुलना में अधिक सामान्य है, जैसा कि गुडफेलो द्वारा समझाया गया है।
नेटवर्क को धोखा देने के लिए, यह विश्वास करने के लिए मजबूर करना कि यह एक सामान्य वस्तु को देखता है, आसान है, क्योंकि यह मानता है कि इसे ऐसी वस्तुओं को अक्सर देखना चाहिए। इसलिए, गुडफेलो और व्योमिंग विश्वविद्यालय के एक अन्य समूह को उन चित्रों को वर्गीकृत करने के लिए नेटवर्क प्राप्त करने में सक्षम थे जो बिल्कुल भी मौजूद नहीं थे - यह सफेद शोर में वस्तुओं की पहचान करता था, यादृच्छिक रूप से काले और सफेद पिक्सेल।
गुडफेलो अध्ययन में, एक नेटवर्क से गुजरने वाले यादृच्छिक सफेद शोर को उसके द्वारा एक घोड़े के रूप में वर्गीकृत किया गया था। संयोग से, यह हमें क्लेवर हंस की कहानी पर वापस लाता है, न कि बहुत ही गणितीय रूप से उपहार में दिया गया घोड़ा।
गुडफेलो का कहना है कि स्मार्ट हंस जैसे तंत्रिका नेटवर्क वास्तव में कोई विचार नहीं सीखते हैं, लेकिन केवल तब पता लगाना सीखते हैं जब उन्हें सही विचार मिलता है। अंतर छोटा लेकिन महत्वपूर्ण है। मौलिक ज्ञान की कमी दुर्भावनापूर्ण प्रयासों को "सही" एल्गोरिथ्म परिणाम खोजने की उपस्थिति को फिर से बनाने की सुविधा प्रदान करती है, जो वास्तव में गलत साबित होती है। यह समझने के लिए कि कुछ क्या है, मशीन को यह भी समझना चाहिए कि यह क्या नहीं है।
गुडफेलो, ने प्राकृतिक छवियों और संसाधित (नकली) दोनों छवियों पर नेटवर्क को छांटने वाले चित्रों को प्रशिक्षित किया, उन्होंने पाया कि वह न केवल इस तरह के हमलों की प्रभावशीलता को 90% तक कम कर सकते हैं, बल्कि शुरुआती कार्य के साथ नेटवर्क को बेहतर ढंग से सामना कर सकते हैं।
"वास्तव में असामान्य नकली छवियों की व्याख्या करना संभव बनाकर, आप अंतर्निहित अवधारणाओं का और भी अधिक विश्वसनीय विवरण प्राप्त कर सकते हैं," गुडफेलो कहते हैं।
ऑडियो शोधकर्ताओं के दो समूहों ने Google टीम के समान एक दृष्टिकोण का उपयोग किया, अपने तंत्रिका नेटवर्क को अपने स्वयं के हमलों से ओवरट्रेनिंग से बचाते हुए। उन्होंने भी इसी तरह की सफलताएं हासिल कीं, उनकी हमले की दक्षता को 90% से अधिक घटा दिया।
यह आश्चर्य की बात नहीं है कि अनुसंधान के इस क्षेत्र में अमेरिकी सेना की दिलचस्पी है। आर्मी रिसर्च लेबोरेटरी ने इस विषय पर दो नए कामों को भी प्रायोजित किया, जिसमें ब्लैक बॉक्स हमला भी शामिल है। और यद्यपि एजेंसी अनुसंधान को वित्तपोषित कर रही है, इसका मतलब यह नहीं है कि युद्ध में प्रौद्योगिकी का उपयोग किया जा रहा है। विभाग के प्रतिनिधि के अनुसार, एक सैनिक द्वारा उपयोग के लिए उपयुक्त अनुसंधान से लेकर प्रौद्योगिकियों तक 10 साल तक का समय गुजर सकता है।
अनंतराम स्वामी, अमेरिकी सेना प्रयोगशाला में एक शोधकर्ता, एआई धोखे से निपटने वाले कई हालिया कार्यों में शामिल रहे हैं। हमारी दुनिया में धोखाधड़ी के आंकड़ों का पता लगाने और उन्हें रोकने के मुद्दे पर सेना रुचि रखती है, जहां सूचना के सभी स्रोतों की सावधानीपूर्वक जांच नहीं की जा सकती है। स्वामी विश्वविद्यालयों में स्थित सार्वजनिक सेंसर से प्राप्त आंकड़ों के एक समूह की ओर इशारा करते हैं और ओपन सोर्स प्रोजेक्ट में काम करते हैं।
“हम हमेशा सभी डेटा को नियंत्रित नहीं करते हैं। हमारे विरोधी के लिए हमें धोखा देना बहुत आसान है, ”स्वामी कहते हैं। "कुछ मामलों में, इस तरह के धोखाधड़ी के परिणाम कुछ हद तक विपरीत हो सकते हैं।"
वह यह भी कहता है कि सेना को स्वायत्त रोबोट, टैंक और अन्य वाहनों में रुचि है, इसलिए इस तरह के अनुसंधान का लक्ष्य स्पष्ट है। इन मुद्दों का अध्ययन करके, सेना विकासशील प्रणालियों में एक सिर शुरू करने में सक्षम होगी जो इस तरह के हमलों के लिए अतिसंवेदनशील नहीं हैं।
लेकिन तंत्रिका नेटवर्क का उपयोग करने वाले किसी भी समूह को एआई स्पूफिंग के साथ हमलों की क्षमता के बारे में चिंता होनी चाहिए। मशीन लर्निंग और AI अपनी प्रारंभिक अवस्था में हैं, और सुरक्षा खामियों के इस समय गंभीर परिणाम हो सकते हैं। कई कंपनियां एआई सिस्टम के लिए अत्यधिक संवेदनशील जानकारी पर भरोसा करती हैं जिन्होंने समय की परीक्षा उत्तीर्ण नहीं की है। हमारे तंत्रिका नेटवर्क अभी भी हमारे लिए बहुत छोटे हैं जो हमें उनके बारे में सब कुछ जानने की जरूरत है।
इसी तरह की निगरानी के कारण
माइक्रोसॉफ्ट के ट्विटर बॉट ने तय किया कि वह जल्द ही नरसंहार के लिए एक नस्लवादी बन जाएगा। दुर्भावनापूर्ण डेटा का प्रवाह और फ़ंक्शन "मेरे बाद दोहराएं" इस तथ्य की ओर जाता है कि तयशुदा रास्ते से ताई काफी भटक गए थे। घटिया इनपुट द्वारा बॉट को धोखा दिया गया था, और यह मशीन सीखने के खराब कार्यान्वयन का एक सुविधाजनक उदाहरण है।
कंचेलिन का कहना है कि वह नहीं मानते हैं कि Google टीम के सफल शोध के बाद इस तरह के हमलों की संभावनाएं समाप्त हो गई हैं।
"कंप्यूटर सुरक्षा के क्षेत्र में, हमलावर हमेशा हमसे आगे होते हैं," कांचीयन कहते हैं। "यह दावा करना खतरनाक होगा कि हमने उनके दोहराया प्रशिक्षण के माध्यम से तंत्रिका नेटवर्क के धोखे के साथ सभी समस्याओं को हल किया है।"