तंत्रिका नेटवर्क की सहायता से मशीनी अनुवाद इस विषय पर पहले वैज्ञानिक अनुसंधान के क्षण से
एक लंबा सफर तय किया है जब तक कि Google ने
Google अनुवाद सेवा को गहन सीखने के लिए
पूर्ण हस्तांतरण की घोषणा नहीं की।
जैसा कि आप जानते हैं, तंत्रिका अनुवादक का आधार मैट्रिक्स गणनाओं पर निर्मित बिडायरेक्शनल रिक्रिएंट न्यूरल नेटवर्क्स तंत्र है, जो आपको सांख्यिकीय मशीन अनुवादकों की तुलना में काफी अधिक जटिल संभाव्य मॉडल बनाने की अनुमति देता है। हालांकि, यह हमेशा माना जाता था कि सांख्यिकीय अनुवाद की तरह, तंत्रिका अनुवाद को प्रशिक्षण के लिए समानांतर द्विभाषी ग्रंथों की आवश्यकता होती है। इन इमारतों पर एक तंत्रिका नेटवर्क को प्रशिक्षित किया जा रहा है, एक संदर्भ के रूप में मानव अनुवाद।
जैसा कि यह अब पता चला है, तंत्रिका नेटवर्क ग्रंथों के समानांतर कॉर्पस के बिना भी अनुवाद के लिए एक नई भाषा में महारत हासिल करने में सक्षम हैं! इस विषय पर
दो काम arXiv.org प्रीप्रिंट साइट पर प्रकाशित किए गए थे।
“कल्पना कीजिए कि आप एक व्यक्ति को बहुत सारी चीनी किताबें और बहुत सारी अरबी किताबें दे रहे हैं - उनमें कोई समान किताबें नहीं हैं - और यह व्यक्ति चीनी से अरबी में अनुवाद करना सीख रहा है। यह असंभव लगता है, है ना? लेकिन हमने दिखाया कि एक कंप्यूटर इसके लिए सक्षम है, ”सैन सेबेस्टियन (स्पेन) में बास्क देश के विश्वविद्यालय के कंप्यूटर वैज्ञानिक मिकेल आर्टटेक्स
कहते हैं ।
अधिकांश मशीनी अनुवाद तंत्रिका नेटवर्क को "एक शिक्षक के साथ" पढ़ाया जाता है, जिसकी भूमिका आदमी द्वारा अनुवादित ग्रंथों के समानांतर कॉर्पस है। सीखने की प्रक्रिया में, मोटे तौर पर, तंत्रिका नेटवर्क एक धारणा बनाता है, मानक के खिलाफ जांच करता है, और अपने सिस्टम में आवश्यक सेटिंग्स बनाता है, फिर आगे सीखता है। समस्या यह है कि दुनिया में कुछ भाषाओं के लिए बड़ी संख्या में समानांतर ग्रंथ नहीं हैं, इसलिए वे पारंपरिक मशीन अनुवाद तंत्रिका नेटवर्क के लिए उपलब्ध नहीं हैं।
दो नए मॉडल एक नया दृष्टिकोण प्रदान करते हैं:
एक शिक्षक के बिना मशीन अनुवाद तंत्रिका नेटवर्क
को पढ़ाना। प्रणाली स्वयं एक दूसरे के चारों ओर शब्दों को जोड़ते हुए, ग्रंथों के समानांतर कॉर्पस बनाने की कोशिश कर रही है। तथ्य यह है कि दुनिया की अधिकांश भाषाओं में एक ही अर्थ हैं, जो बस अलग-अलग शब्दों के अनुरूप हैं। तो, इन सभी अर्थों को समान समूहों में बांटा गया है, अर्थात समान शब्द-अर्थों को समान शब्द-अर्थों के चारों ओर वर्गीकृत किया गया है, लगभग भाषा की परवाह किए बिना (लेख "
Google अनुवाद तंत्रिका नेटवर्क ने मानव शब्दों के अर्थ का एकीकृत आधार संकलित किया है ") ।
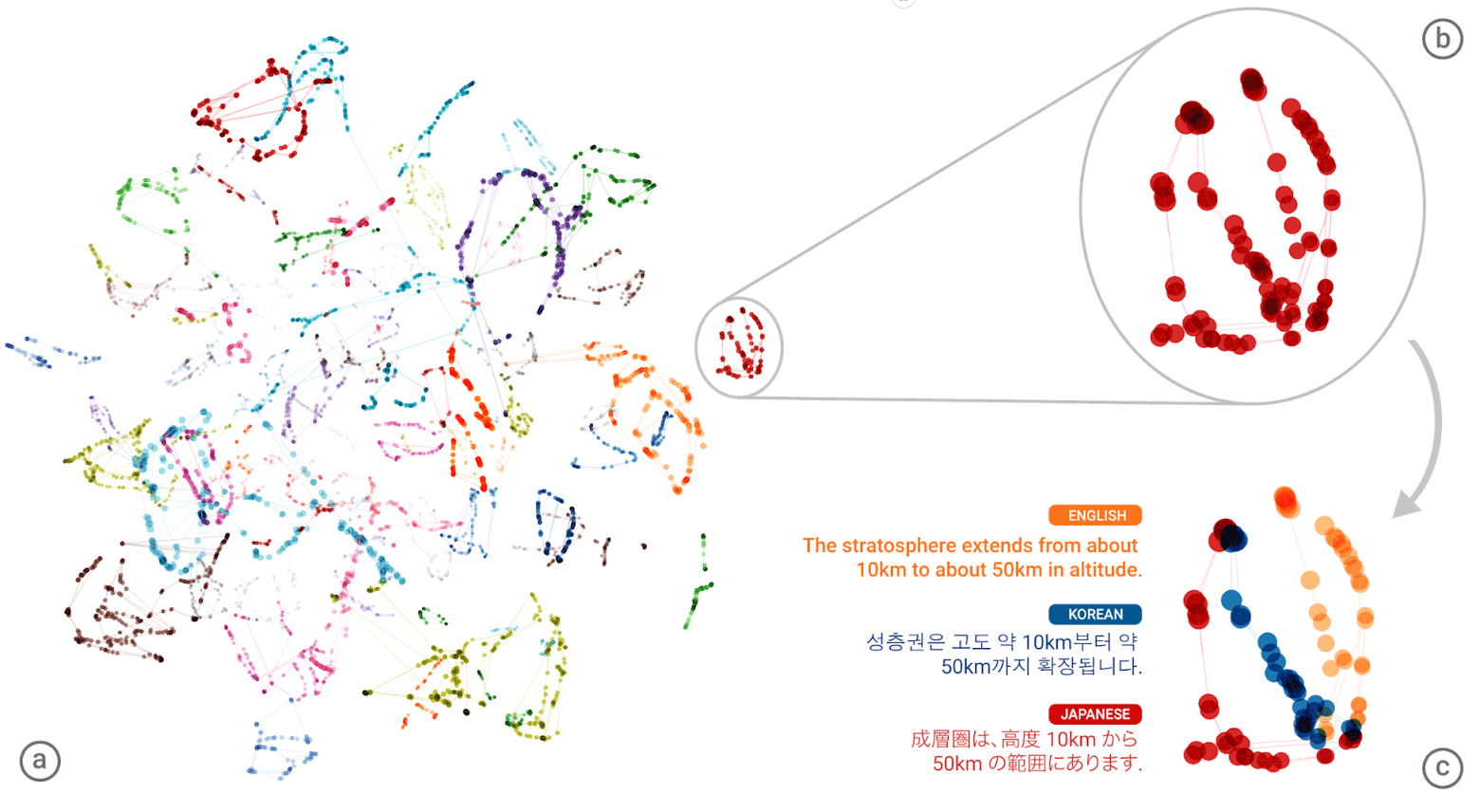 Google तंत्रिका मशीन अनुवाद (GNMT) तंत्रिका नेटवर्क की "सार्वभौमिक भाषा"। प्रत्येक शब्द के अर्थों के समूहों को बाएं चित्रण में अलग-अलग रंगों में दिखाया गया है, निम्न अर्थ विभिन्न मानव भाषाओं से प्राप्त किए गए शब्द हैं: अंग्रेजी, कोरियाई और जापानी
Google तंत्रिका मशीन अनुवाद (GNMT) तंत्रिका नेटवर्क की "सार्वभौमिक भाषा"। प्रत्येक शब्द के अर्थों के समूहों को बाएं चित्रण में अलग-अलग रंगों में दिखाया गया है, निम्न अर्थ विभिन्न मानव भाषाओं से प्राप्त किए गए शब्द हैं: अंग्रेजी, कोरियाई और जापानीप्रत्येक भाषा के लिए एक विशाल "एटलस" संकलित करने के बाद, सिस्टम एक दूसरे पर इस तरह के एटलस को ओवरले करने की कोशिश करता है - और यहां आप हैं, आप किसी प्रकार के समानांतर पाठ कॉर्पस के लिए तैयार हैं!
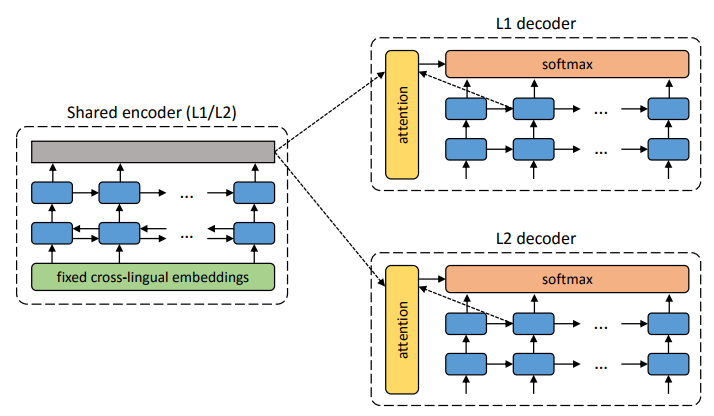
आप दो प्रस्तावित शिक्षक-कम सीखने वाले आर्किटेक्चर के पैटर्न की तुलना कर सकते हैं।
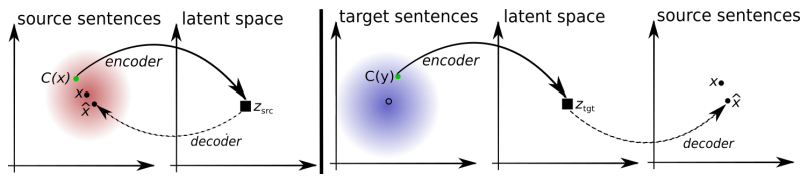
 प्रस्तावित प्रणाली की वास्तुकला। L1 भाषा में प्रत्येक वाक्य के लिए, सिस्टम दो चरणों के विकल्प को सीखता है: 1) denoising , जो एक सामान्य एनकोडर और L1 डिकोडर द्वारा इसके पुनर्निर्माण के साथ वाक्य के शोर संस्करण को एन्कोडिंग की संभावना को अनुकूलित करता है; 2) बैक-ट्रांसलेशन, जब एक वाक्य आउटपुट मोड में अनुवादित किया जाता है (यानी एक आम एनकोडर द्वारा एन्कोड किया गया और L2 डिकोडर द्वारा डिकोड किया गया), और फिर एक सामान्य एनकोडर के साथ इस अनुवादित वाक्य को एन्कोडिंग की संभावना और L1 डिकोडर द्वारा मूल वाक्य की बहाली को अनुकूलित किया जाता है। चित्रण: मिकेल आर्टिटिक्स एट अल द्वारा वैज्ञानिक लेख ।
प्रस्तावित प्रणाली की वास्तुकला। L1 भाषा में प्रत्येक वाक्य के लिए, सिस्टम दो चरणों के विकल्प को सीखता है: 1) denoising , जो एक सामान्य एनकोडर और L1 डिकोडर द्वारा इसके पुनर्निर्माण के साथ वाक्य के शोर संस्करण को एन्कोडिंग की संभावना को अनुकूलित करता है; 2) बैक-ट्रांसलेशन, जब एक वाक्य आउटपुट मोड में अनुवादित किया जाता है (यानी एक आम एनकोडर द्वारा एन्कोड किया गया और L2 डिकोडर द्वारा डिकोड किया गया), और फिर एक सामान्य एनकोडर के साथ इस अनुवादित वाक्य को एन्कोडिंग की संभावना और L1 डिकोडर द्वारा मूल वाक्य की बहाली को अनुकूलित किया जाता है। चित्रण: मिकेल आर्टिटिक्स एट अल द्वारा वैज्ञानिक लेख ।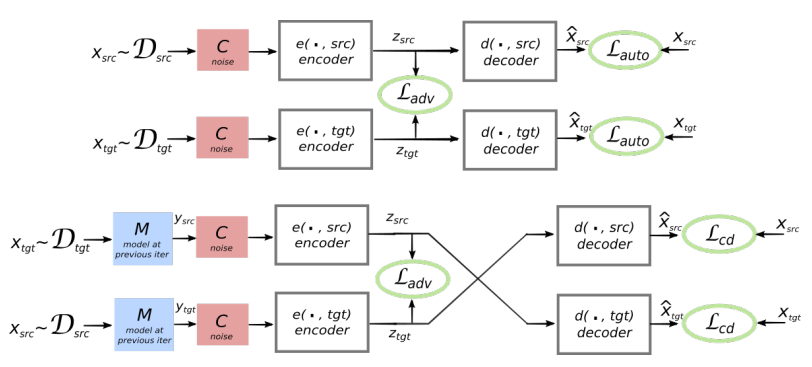 सिस्टम की प्रस्तावित वास्तुकला और सीखने के उद्देश्य (दूसरे वैज्ञानिक कार्य से)। आर्किटेक्चर एक वाक्य अनुवाद मॉडल है, जहां दोनों एन्कोडर और डिकोडर दो भाषाओं में काम करते हैं, जो इनपुट भाषा के पहचानकर्ता पर निर्भर करता है, जो खोज तालिकाओं को स्वैप करता है। ऊपर (ऑटो-कोडिंग): मॉडल सीख रहा है कि प्रत्येक डोमेन में शोर में कमी कैसे करें। नीचे (अनुवाद): पहले की तरह, हम दूसरी भाषा से कोड का उपयोग करते हैं, पिछले पुनरावृति (नीले आयत) में मॉडल द्वारा उत्पादित अनुवाद के इनपुट के रूप में। हरी दीर्घवृत्त हानि फ़ंक्शन में शर्तों को इंगित करते हैं। चित्रण: गिलौम लैम्पल एट अल का वैज्ञानिक लेख ।
सिस्टम की प्रस्तावित वास्तुकला और सीखने के उद्देश्य (दूसरे वैज्ञानिक कार्य से)। आर्किटेक्चर एक वाक्य अनुवाद मॉडल है, जहां दोनों एन्कोडर और डिकोडर दो भाषाओं में काम करते हैं, जो इनपुट भाषा के पहचानकर्ता पर निर्भर करता है, जो खोज तालिकाओं को स्वैप करता है। ऊपर (ऑटो-कोडिंग): मॉडल सीख रहा है कि प्रत्येक डोमेन में शोर में कमी कैसे करें। नीचे (अनुवाद): पहले की तरह, हम दूसरी भाषा से कोड का उपयोग करते हैं, पिछले पुनरावृति (नीले आयत) में मॉडल द्वारा उत्पादित अनुवाद के इनपुट के रूप में। हरी दीर्घवृत्त हानि फ़ंक्शन में शर्तों को इंगित करते हैं। चित्रण: गिलौम लैम्पल एट अल का वैज्ञानिक लेख ।दोनों वैज्ञानिक कागज मामूली अंतर के साथ एक समान रूप से समान तकनीक का उपयोग करते हैं। लेकिन दोनों मामलों में, अनुवाद एक मध्यवर्ती "भाषा" या, बेहतर, एक मध्यवर्ती आयाम या स्थान के माध्यम से किया जाता है। अब तक, एक शिक्षक के बिना तंत्रिका नेटवर्क अनुवाद की उच्च गुणवत्ता नहीं दिखाते हैं, लेकिन लेखकों का कहना है कि यदि आप किसी शिक्षक की थोड़ी मदद का उपयोग करते हैं, तो अभी सुधार करना आसान है, केवल उस प्रयोग की शुद्धता के लिए जो उन्होंने नहीं किया।
ध्यान दें कि दूसरा वैज्ञानिक कार्य फेसबुक एआई डिवीजन के शोधकर्ताओं द्वारा प्रकाशित किया गया था।
लर्निंग रिप्रेजेंटेशन 2018 पर अंतर्राष्ट्रीय सम्मेलन के लिए कार्य प्रस्तुत किए गए हैं। कोई भी लेख अभी तक वैज्ञानिक प्रेस में प्रकाशित नहीं हुआ है।