
हमारा दिन "सुप्रभात!" वाक्यांश के साथ शुरू होता है। दिन के दौरान हम सहकर्मियों, रिश्तेदारों, दोस्तों और यहां तक कि अजनबियों से बात करते हैं जो निकटतम मेट्रो के लिए दिशा निर्देश मांगते हैं। हम तब भी बोलते हैं जब हमारे अपने तर्क को बेहतर ढंग से समझने के लिए हमारे आसपास कोई नहीं होता है। यह सब हमारा भाषण है - एक उपहार जो वास्तव में मानव शरीर की कई अन्य संभावनाओं के साथ अतुलनीय है। भाषण हमें सामाजिक संबंध स्थापित करने, विचारों और भावनाओं को व्यक्त करने, खुद को व्यक्त करने, उदाहरण के लिए, गीतों में अनुमति देता है।
और इसलिए, लोगों के जीवन में स्मार्ट कारें दिखाई दीं। एक व्यक्ति, या तो जिज्ञासा से बाहर है, या नई उपलब्धियों के लिए एक प्यास से बाहर है, मशीन को बोलने के लिए सिखाने की कोशिश कर रहा है। लेकिन बोलने के लिए, आपको सुनने और सुनने की जरूरत है। आजकल एक कार्यक्रम (उदाहरण के लिए सिरी) के साथ आश्चर्यचकित करना मुश्किल है जो भाषण को पहचान सकता है, नक्शे पर एक रेस्तरां ढूंढ सकता है, माँ को बुला सकता है, यहां तक कि एक चुटकुला भी बता सकता है। वह बहुत कुछ समझती है, बिल्कुल नहीं, लेकिन बहुत कुछ। लेकिन यह हमेशा ऐसा नहीं था, स्वाभाविक रूप से। दशकों पहले, यह खुशी के लिए था, जब एक मशीन कम से कम एक दर्जन शब्दों को समझ सकती थी।
आज हम इतिहास में डुबकी लगाएंगे कि कैसे मानव जाति मशीन के साथ बात करने में सक्षम थी, जो कि इस क्षेत्र में सदियों से चली आ रही सफलताओं ने भाषण मान्यता प्रौद्योगिकी के विकास के लिए प्रेरणा के रूप में कार्य किया है। हम यह भी देखते हैं कि आधुनिक उपकरण किस प्रकार हमारी आवाज़ों को देखते हैं और उन्हें संसाधित करते हैं। चलो चलते हैं।
वाक् पहचान की उत्पत्ति
भाषण क्या है? मोटे तौर पर, यह ध्वनि है। इसलिए, भाषण को पहचानने के लिए, आपको सबसे पहले ध्वनि को पहचानना होगा और उसे रिकॉर्ड करना होगा।
अब हमारे पास आईपोड, एमपी 3 प्लेयर हैं, इससे पहले टेप रिकार्डर थे, पहले भी ग्रामोफोन और ग्रामोफोन थे। ये सभी ध्वनि बजाने के उपकरण हैं। लेकिन उन सबके पूर्वज कौन थे?
 थॉमस एडिसन अपने आविष्कार के साथ। 1878 वर्ष
थॉमस एडिसन अपने आविष्कार के साथ। 1878 वर्षयह एक फोनोग्राफ था। 29 नवंबर, 1877 को महान आविष्कारक थॉमस एडिसन ने अपनी नई रचना का प्रदर्शन किया, जो ध्वनियों को रिकॉर्ड करने और पुन: पेश करने में सक्षम थी। यह एक सफलता थी जिसने समाज के प्रति गहरी रुचि पैदा की।
फोनोग्राफ का सिद्धांत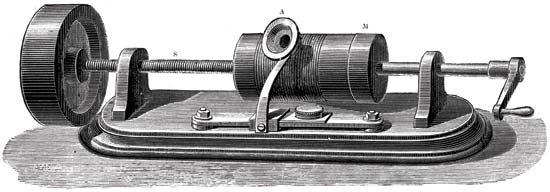
ध्वनि रिकॉर्डिंग तंत्र के मुख्य भाग पन्नी-लेपित सिलेंडर और कटिंग सुई थे। सुई एक सिलेंडर के साथ चलती थी जो घूमती थी। और एक यांत्रिक झिल्ली का उपयोग करके यांत्रिक कंपन कैप्चर किए गए थे। नतीजतन, सुई पन्नी पर निशान छोड़ गई। नतीजतन, हमें एक रिकॉर्ड के साथ एक सिलेंडर मिला। इसे पुन: पेश करने के लिए, शुरू में उसी सिलेंडर का उपयोग किया जाता था जब रिकॉर्डिंग की जाती थी। लेकिन पन्नी बहुत नाजुक थी और जल्दी से बाहर निकल गई, क्योंकि रिकॉर्ड अल्पकालिक थे। फिर उन्होंने मोम लगाना शुरू किया, जिसने सिलेंडर को कवर किया। अभिलेखों के अस्तित्व को लम्बा करने के लिए, उन्होंने इलेक्ट्रोप्लेटिंग का उपयोग करके प्रतिलिपि बनाना शुरू किया। कठिन सामग्रियों के उपयोग के माध्यम से, प्रतियां बहुत लंबे समय तक चली गईं।
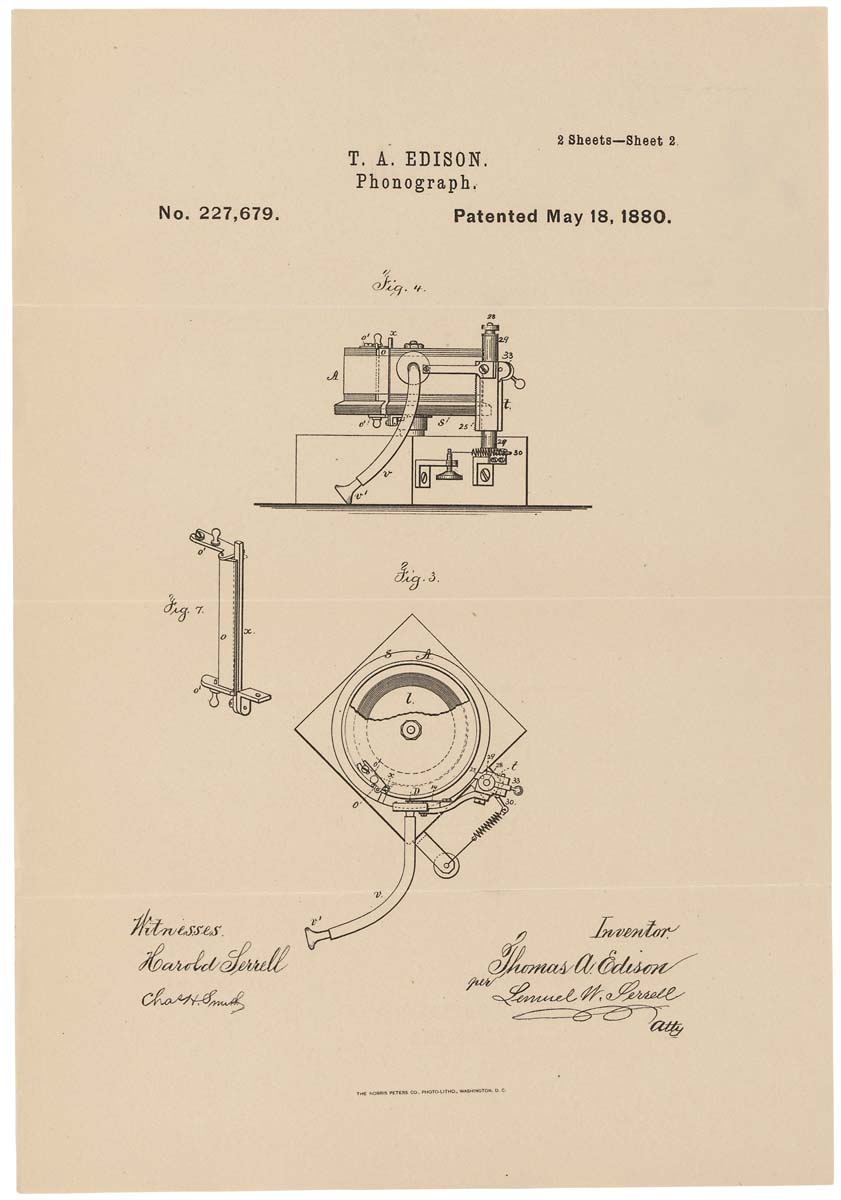 पेटेंट पर एक फोनोग्राफ का योजनाबद्ध चित्रण। 1880, 18 मई
पेटेंट पर एक फोनोग्राफ का योजनाबद्ध चित्रण। 1880, 18 मईउपरोक्त कमियों को देखते हुए, फोनोग्राफ, हालांकि यह एक दिलचस्प मशीन थी, लेकिन यह अलमारियों से बह नहीं गई थी। केवल डिस्क फोनोग्राफ के आगमन के साथ - जिसे ग्रामोफोन के रूप में बेहतर जाना जाता है - क्या सार्वजनिक मान्यता आई थी। नवीनता ने लंबी रिकॉर्डिंग बनाने की अनुमति दी (पहला फोनोग्राफ केवल कुछ मिनटों को रिकॉर्ड कर सकता था), जो लंबे समय तक सेवा करता था। और ग्रामोफोन खुद एक स्पीकर से लैस था जिसने प्लेबैक वॉल्यूम बढ़ाया।
थॉमस एडिसन ने मूल रूप से फोनोग्राफ को टेलीफोन वार्तालापों की रिकॉर्डिंग के लिए एक उपकरण के रूप में कल्पना की थी, जैसे कि आधुनिक आवाज रिकॉर्डर। हालांकि, संगीत रचना के पुनरुत्पादन में उनकी रचना को बहुत लोकप्रियता मिली है। रिकॉर्डिंग उद्योग के गठन के लिए शुरुआत के रूप में सेवा की।
भाषण "अंग"
बेल लैब्स दूरसंचार के क्षेत्र में अपने आविष्कारों के लिए प्रसिद्ध है। ऐसा ही एक आविष्कार था वोडर।
1928 में वापस, होमर डुडले ने वोकोडर पर काम शुरू किया, जो एक उपकरण है जो भाषण को संश्लेषित करने में सक्षम है। हम उसके बारे में बाद में बात करेंगे। अब हम इसके भाग पर विचार करेंगे - वाडर।
 एक वाडर का योजनाबद्ध चित्रण
एक वाडर का योजनाबद्ध चित्रणवाडर का मूल सिद्धांत मानव भाषण को ध्वनिक घटकों में तोड़ना था। मशीन बेहद जटिल थी, और केवल एक प्रशिक्षित ऑपरेटर ही इसे संचालित कर सकता था।
वाडर ने मानव मुखर पथ के प्रभावों का अनुकरण किया। 2 मुख्य ध्वनियां थीं जो ऑपरेटर अपनी कलाई के साथ चुन सकते थे। फुट पैडल का इस्तेमाल असंतुलित दोलनों (भनभनाने की आवाज) के जनरेटर को नियंत्रित करने के लिए किया गया था, जिससे स्वरयुक्त स्वर और नाक की आवाज़ पैदा हुई। गैस डिस्चार्ज ट्यूब (हिसिंग) ने सिबिलेंट्स (फ्रिकेटिव व्यंजन) बनाए। ये सभी ध्वनियाँ 10 में से एक फिल्टर से होकर गुज़रीं, जिसे चाबियों के साथ चुना गया था। "पी" या "डी" जैसी ध्वनियों के लिए विशेष कुंजी भी थीं, और "जॉ" शब्द में "जे" और "पनीर" शब्द में "जे" के लिए भी।
वाडर की प्रस्तुति का यह छोटा सा अंश इसके संचालन और ऑपरेटर कार्यों के सिद्धांत को स्पष्ट रूप से प्रदर्शित करता हैएक ऑपरेटर कई महीनों के कठिन अभ्यास और प्रशिक्षण के बाद ही एक मान्य पहचान योग्य भाषण प्रस्तुत कर सकता है।
1939 में न्यूयॉर्क में एक प्रदर्शनी में पहली बार वाहक का प्रदर्शन किया गया था।
भाषण संश्लेषण के माध्यम से बचत
अब एक वोडर पर विचार करें, जिसका एक हिस्सा पूर्वोक्त चालक था।
 वोकोडर मॉडल में से एक: HY-2 (1961)
वोकोडर मॉडल में से एक: HY-2 (1961)स्वर संदेश प्रसारित करते समय वोकोडर मूल रूप से रेडियो लिंक की आवृत्ति संसाधनों को बचाने के लिए था। आवाज के बजाय, इसके विशिष्ट मापदंडों के मूल्यों को प्रेषित किया गया था, जो आउटपुट पर भाषण सिंथेसाइज़र द्वारा संसाधित किया गया था।
शब्दकोष का आधार तीन मुख्य गुण थे:
- शोर जनरेटर (व्यंजन ध्वनियाँ);
- स्वर जनरेटर (स्वर);
- औपचारिक फिल्टर (स्पीकर की व्यक्तिगत विशेषताओं को फिर से बनाना)।
अपने गंभीर उद्देश्य के बावजूद, वाइटोडर ने इलेक्ट्रॉनिक संगीतकारों का ध्यान आकर्षित किया। स्रोत सिग्नल को परिवर्तित करने और इसे किसी अन्य डिवाइस पर चलाने से कई प्रकार के प्रभाव प्राप्त करना संभव हो गया, जैसे कि "मानव आवाज" में एक संगीत वाद्ययंत्र गायन का प्रभाव।
गिनती की मशीन
1952 में तकनीकें उतनी उन्नत नहीं थीं जितनी अब हैं। लेकिन इसने उत्साही वैज्ञानिकों को कई लोगों के अनुसार खुद को असंभव कार्य स्थापित करने से नहीं रोका। तो सज्जन स्टीफन बालाशेक (एस। बालशेख), रॉलन बिडल्फ़ (आर। बिडुलफ़) और के.के.एच. डेविस (केएच डेविस) ने उनके भाषण को समझने के लिए मशीन को सिखाने का फैसला किया। इस विचार के बाद, ऑड्रे की कार अस्तित्व में आई। उसकी क्षमताएं बहुत सीमित थीं - वह केवल 0 से 9 तक की संख्या को पहचान सकती थी। लेकिन यह पहले से ही कंप्यूटर प्रौद्योगिकी में सुरक्षित रूप से सफलता की घोषणा करने के लिए पर्याप्त था।
 अपने रचनाकारों में से एक के साथ ऑड्रे (इंटरनेट के अनुसार, मुझे सही करें अगर यह नहीं है)
अपने रचनाकारों में से एक के साथ ऑड्रे (इंटरनेट के अनुसार, मुझे सही करें अगर यह नहीं है)अपनी छोटी क्षमताओं के बावजूद, ऑड्रे समान आयामों का दावा नहीं कर सकता था। वह एक बड़ी "लड़की" थी - रिले कैबिनेट लगभग 2 मीटर ऊंची थी, और सभी तत्वों ने एक छोटे से कमरे पर कब्जा कर लिया था। जो उस समय के कंप्यूटरों के लिए आश्चर्यजनक नहीं है।
ऑपरेटर और ऑड्रे के बीच बातचीत की प्रक्रिया में कुछ शर्तें भी थीं। ऑपरेटर ने एक नियमित टेलीफोन के हैंडसेट में शब्दों (संख्या, इस मामले में) को बोला, प्रत्येक शब्द के बीच 350 मिलीसेकेंड का ठहराव सुनिश्चित करें। ऑड्रे ने जानकारी को स्वीकार किया, इसे इलेक्ट्रॉनिक प्रारूप में अनुवादित किया और एक विशेष अंक के लिए एक विशिष्ट प्रकाश बल्ब चालू किया। इस तथ्य का उल्लेख नहीं करने के लिए कि प्रत्येक ऑपरेटर को सटीक उत्तर नहीं मिल सकता है। 97% की सटीकता प्राप्त करने के लिए, ऑपरेटर को एक व्यक्ति होना चाहिए जो लंबे समय से ऑड्रे के साथ "बकबक" का अभ्यास कर रहा था। दूसरे शब्दों में, ऑड्रे ने केवल अपने रचनाकारों को समझा।
यहां तक कि ऑड्रे की सभी कमियों को ध्यान में रखते हुए, जो डिजाइन त्रुटियों के साथ नहीं जुड़े हैं, लेकिन उन समय की प्रौद्योगिकी की सीमाओं के साथ, वह मशीनों के क्षितिज में पहला सितारा बन गया जो मानव आवाज को समझता है।
जूता बॉक्स में भविष्य
1961 में, आईबीएम एडवांस्ड सिस्टम्स डेवलपमेंट लेबोरेटरी में, एक नया चमत्कार उपकरण विकसित किया गया था - शोएबॉक्स, जो 16 शब्दों (विशेष रूप से अंग्रेजी में) को पहचान सकता है और 0 से 9 तक संख्याएं। इस कंप्यूटर के लेखक विलियम सी। डर्श थे।
 आईबीएम से Shoebox
आईबीएम से Shoeboxअसामान्य नाम मशीन की उपस्थिति के अनुरूप था, यह आकार और आकार में एक जूता बॉक्स की तरह था। केवल एक चीज जिसने मेरी आंख को पकड़ा, वह माइक्रोफोन था, जो उच्च, मध्यम और निम्न ध्वनियों को पहचानने के लिए आवश्यक तीन ऑडियो फिल्टर से जुड़ा था। फिल्टर एक लॉजिक डिकोडर (डायोड-ट्रांजिस्टर लॉजिक सर्किट) और एक लाइट स्विच मैकेनिज्म से जुड़े थे।
ऑपरेटर ने माइक्रोफोन को अपने मुंह में लाया और एक शब्द (उदाहरण के लिए, संख्या 7) कहा। मशीन ने ध्वनिक डेटा को इलेक्ट्रॉनिक सिग्नल में बदल दिया। समझ का परिणाम हस्ताक्षर "7" के साथ एक प्रकाश बल्ब का समावेश था। व्यक्तिगत शब्दों को समझने के अलावा, शोएबॉक्स साधारण अंकगणित समस्याओं (जैसे 5 + 6 या 7-3) को समझ सकता है और सही उत्तर दे सकता है।
शाओबॉक्स को 1962 में सिएटल वर्ल्ड एक्सपो में इसके निर्माता द्वारा पेश किया गया था।
कार से फोन पर बातचीत
1971 में, नवीन आविष्कारों और प्रौद्योगिकियों के अपने प्यार के लिए पहचाने जाने वाले आईबीएम ने भाषण मान्यता को व्यवहार में लाने का फैसला किया। स्वचालित कॉल पहचान प्रणाली ने संयुक्त राज्य अमेरिका में कहीं भी स्थित एक इंजीनियर को उत्तरी केरोलिना के रैले में एक कंप्यूटर को कॉल करने की अनुमति दी। कॉल करने वाला एक सवाल पूछ सकता है और उसे एक आवाज का जवाब मिल सकता है। इस प्रणाली की विशिष्टता कई आवाजों को समझने में थी, उनकी टोन, जोर, बोलने की मात्रा आदि को देखते हुए।
हार्पी उच्च बढ़ते
रक्षा विभाग के एडवांस्ड रिसर्च प्रोजेक्ट्स ऑफिस (DARPA फॉर शॉर्ट) ने 1971 में एक स्पीच रिकग्निशन डेवलपमेंट एंड रिसर्च प्रोग्राम शुरू करने की घोषणा की जिसका उद्देश्य ऐसी मशीन बनाना है जो 1,000 शब्दों को पहचान सके। एक साहसिक परियोजना, दसियों शब्दों में अपने पूर्ववर्ती की सफलताओं को देखते हुए। लेकिन मानव संसाधन की कोई सीमा नहीं है। और 1976 में कार्नेगी मेलन यूनिवर्सिटी ने हार्पी को प्रदर्शित किया, जो 1011 शब्दों को पहचानने में सक्षम है।
हार्पी वीडियो प्रदर्शनविश्वविद्यालय ने पहले से ही स्पीच रिकग्निशन सिस्टम - हेयर्स -1 और ड्रैगन विकसित किया है। उनका उपयोग हार्पी को लागू करने के लिए आधार के रूप में किया गया था।
Hearsay-1 में, ज्ञान (यानी, एक मशीन शब्दकोश) को प्रक्रियाओं के रूप में और ड्रैगन में - मार्कोव नेटवर्क के रूप में एक प्राथमिक संभाव्य संक्रमण के रूप में दर्शाया गया है। हार्पी में, नवीनतम मॉडल का उपयोग करने का निर्णय लिया गया था, लेकिन इस संक्रमण के बिना।
इस वीडियो में, ऑपरेशन के सिद्धांत को अधिक विस्तार से वर्णित किया गया है।
सीधे शब्दों में कहें, तो आप एक नेटवर्क - शब्दों और उनके संयोजनों का एक क्रम, साथ ही एक शब्द के साथ ध्वनियों को सुन सकते हैं, मशीन के लिए एक ही शब्द के विभिन्न उच्चारणों को समझ सकते हैं।
हार्पी ने 5 ऑपरेटरों को समझा, जिनमें तीन पुरुष और दो महिलाएं शामिल हैं। यह इस मशीन की अधिक कंप्यूटिंग क्षमताओं के बारे में बात करता है। भाषण मान्यता सटीकता लगभग 95% थी।
आईबीएम द्वारा तंगोरा
1980 के दशक की शुरुआत में, आईबीएम ने दशक के मध्य तक 20,000 से अधिक शब्दों को पहचानने में सक्षम प्रणाली विकसित करने का फैसला किया। इसलिए टंगोरा का जन्म हुआ, जिसके काम में छिपे हुए मार्कोव मॉडल का उपयोग किया गया था। बल्कि प्रभावशाली शब्दावली के बावजूद, सिस्टम को अपने भाषण को पहचानने का तरीका जानने के लिए नए ऑपरेटर (बोलने वाले व्यक्ति) के साथ 20 मिनट से अधिक के सहयोग की आवश्यकता नहीं थी।
जीवित गुड़िया
1987 में, वर्ल्ड ऑफ़ वंडर टॉय कंपनी ने एक क्रांतिकारी नवीनता जारी की - जूली नामक एक बोलने वाली गुड़िया। डेनिश खिलौना की सबसे प्रभावशाली विशेषता मालिक के भाषण को पहचानने के लिए इसे प्रशिक्षित करने की क्षमता थी। जूली बहुत अच्छी तरह से बात कर सकती थी। इसके अलावा, गुड़िया कई सेंसर से लैस थी, जिसकी बदौलत यह प्रतिक्रिया हुई जब इसे उठाया गया, गुदगुदी हुई, या अंधेरे से उज्ज्वल कमरे में स्थानांतरित किया गया।
वंडर कॉमर्शियल जूली के संसारों ने इसकी विशेषताओं को प्रदर्शित कियाउसकी आँखें और होंठ मोबाइल थे, जिसने और भी जीवंत छवि बनाई। खुद गुड़िया के अलावा, एक किताब खरीदना संभव था जिसमें विशेष स्टिकर के रूप में चित्र और शब्द बनाए गए थे। यदि आप गुड़िया को अपनी उंगलियों के साथ पकड़ते हैं, तो यह आवाज को स्पर्श करने के लिए "महसूस" करता है। गुड़िया जूली एक भाषण पहचान समारोह के साथ पहली डिवाइस थी, जो किसी के लिए भी उपलब्ध थी।
पहला डिक्टेशन सॉफ्टवेयर

1990 में, ड्रैगन सिस्टम्स ने भाषण मान्यता के आधार पर पहला व्यक्तिगत कंप्यूटर सॉफ्टवेयर जारी किया - ड्रैगनडिक्टेट। कार्यक्रम विशेष रूप से विंडोज पर काम किया। उपयोगकर्ता को प्रत्येक शब्द के बीच छोटे-छोटे ठहराव करने होते थे ताकि प्रोग्राम उन्हें पार्स कर सके। भविष्य में, एक अधिक परिपूर्ण संस्करण दिखाई दिया जो आपको लगातार बोलने की अनुमति देता है - ड्रैगन नेचुरलीस्पीकिंग (यह वह है जो अब उपलब्ध है, जबकि मूल ड्रैगनडिक्ट ने विंडोज 98 के बाद से अपडेट करना बंद कर दिया है)। इसके "धीमापन" के बावजूद, ड्रैगनडिकेट ने पीसी उपयोगकर्ताओं के बीच बहुत लोकप्रियता हासिल की है, खासकर विकलांग लोगों के बीच।
नॉन इजीपियन स्फिंक्स
कार्नेगी मेलन विश्वविद्यालय, जो पहले से "पहले से ही जलाया" गया है, एक और ऐतिहासिक रूप से महत्वपूर्ण भाषण मान्यता प्रणाली - स्फिंक्स 2 का जन्मस्थान बन गया है।
 स्फिंक्स Xuedong हुआंग के निर्माता
स्फिंक्स Xuedong हुआंग के निर्माताप्रणाली का प्रत्यक्ष लेखक Xuedong हुआंग था। स्फिंक्स 2 अपनी गति से अपने पूर्ववर्ती से अलग था। यह प्रणाली उन कार्यक्रमों के लिए वास्तविक समय भाषण मान्यता पर केंद्रित थी जो बोली जाने वाली (रोजमर्रा की) भाषा का उपयोग करती हैं। स्फिंक्स 2 की विशेषताएं इस प्रकार थीं: परिकल्पना गठन, भाषा मॉडल के बीच गतिशील स्विचिंग, समकक्षों का पता लगाना, आदि।
कई वाणिज्यिक उत्पादों में स्फिंक्स 2 कोड का उपयोग किया गया है। और 2000 में, सोर्सफॉर्ज वेबसाइट पर, केविन लेनजो ने सामान्य देखने के लिए सिस्टम का स्रोत कोड पोस्ट किया। जो लोग स्फिंक्स 2 के स्रोत कोड और इसके अन्य रूपों का अध्ययन करना चाहते हैं, वे
लिंक का अनुसरण कर सकते हैं।
मेडिकल डिक्टेशन
1996 में, आईबीएम ने मेडस्पीक को लॉन्च किया, जो भाषण मान्यता के साथ पहला वाणिज्यिक उत्पाद था। मेडिकल रिकॉर्ड को संकलित करने के लिए डॉक्टरों में इस कार्यक्रम का उपयोग करना चाहिए था। उदाहरण के लिए, एक रेडियोलॉजिस्ट, रोगी की तस्वीरों की जांच करते हुए, उसकी टिप्पणियों को आवाज दी, जिसे मेडस्पेक प्रणाली ने पाठ में अनुवादित किया।
भाषण मान्यता के साथ कार्यक्रमों के सबसे प्रसिद्ध प्रतिनिधियों पर आगे बढ़ने से पहले, आइए जल्दी से, संक्षेप में, इस तकनीक से संबंधित कुछ और ऐतिहासिक घटनाओं को देखें।
ऐतिहासिक ब्लिट्ज
- 2002 - Microsoft अपने सभी कार्यालय उत्पादों में वाक् पहचान को एकीकृत करता है;
- 2006 - यूएस नेशनल सिक्योरिटी एजेंसी ने वार्तालाप रिकॉर्ड्स में सीमित कीवर्ड की पहचान करने के लिए भाषण मान्यता कार्यक्रमों का उपयोग करना शुरू किया;
- 2007 (30 जनवरी) - माइक्रोसॉफ्ट ने विंडोज विस्टा जारी किया - भाषण मान्यता के साथ पहला ओएस;
- 2007 - Google ने GOOG-411 पेश किया - एक टेलीफोन अग्रेषण प्रणाली (एक व्यक्ति एक नंबर पर कॉल करता है, कहता है कि उसे किस संगठन या व्यक्ति की आवश्यकता है और सिस्टम उन्हें जोड़ता है)। सिस्टम ने संयुक्त राज्य अमेरिका और कनाडा के भीतर काम किया;
- 2008 (14 नवंबर) - Google ने iPhone मोबाइल उपकरणों पर आवाज खोज शुरू की। यह मोबाइल फोन में वाक् पहचान तकनीक का पहला प्रयोग था;
और अब हम उस समय की अवधि में आते हैं जब बहुत सारे लोग भाषण मान्यता प्रौद्योगिकी में आए थे।
स्त्रियाँ झगड़ा नहीं करतीं
4 अक्टूबर, 2011 को, Apple ने सिरी की घोषणा की, जिसके नाम का डिकोडिंग खुद के लिए बोलता है - स्पीच इंटरप्रिटेशन एंड रिकॉग्निशन इंटरफेस (यानी, इंटरप्रिटेशन एंड स्पीच रिकॉग्निशन इंटरफेस)।

सिरी विकास का इतिहास बहुत लंबा है (वास्तव में, इसमें 40 साल का काम है) और दिलचस्प है। इसके अस्तित्व और व्यापक कार्यक्षमता का बहुत तथ्य कई कंपनियों और विश्वविद्यालयों का संयुक्त कार्य है। हालांकि, हम इस उत्पाद पर ध्यान केंद्रित नहीं करेंगे, क्योंकि लेख सिरी के बारे में नहीं है, लेकिन सामान्य रूप से भाषण मान्यता के बारे में है।
Microsoft पीछे नहीं हटना चाहता था, क्योंकि 2014 (2 अप्रैल) में उन्होंने अपने वर्चुअल डिजिटल असिस्टेंट Cortana की घोषणा की।

Cortana की कार्यक्षमता इसके प्रतियोगी सिरी के समान है, जिसमें सूचना तक पहुंच स्थापित करने के लिए एक अधिक लचीली प्रणाली है।
कोरटाना या सिरी पर बहस। कौन बेहतर है? ” बाजार पर उनकी उपस्थिति के बाद से आयोजित। के रूप में, सामान्य रूप से, और iOS और Android के उपयोगकर्ताओं के बीच संघर्ष। लेकिन यह अच्छा है। प्रतिस्पर्धी प्रतिद्वंद्वियों की तुलना में बेहतर प्रतीत होने के प्रयास में, प्रतिस्पर्धात्मक उत्पाद, अधिक से अधिक नए अवसर प्रदान करेंगे, भाषण मान्यता के समान क्षेत्र में अधिक उन्नत तकनीकों और तकनीकों का विकास और उपयोग करेंगे। उपभोक्ता प्रौद्योगिकी के किसी भी क्षेत्र में केवल एक प्रतिनिधि होने से, इसके तेजी से विकास के बारे में बात करने की आवश्यकता नहीं है।
सिरी और कोरटाना के बीच बातचीत का एक छोटा सा मजाकिया वीडियो (जाहिर है, लेकिन कोई कम मज़ेदार नहीं)। ध्यान!: इस वीडियो में अपवित्रता है।
कारों के साथ बातचीत। वे हमें कैसे समझते हैं?
जैसा कि मैंने पहले उल्लेख किया है, मोटे तौर पर बोल, भाषण ध्वनि है। और कार के लिए ध्वनि क्या है? ये हवा के दबाव में परिवर्तन (उतार-चढ़ाव) हैं, अर्थात्। ध्वनि तरंगें। मशीन (कंप्यूटर या फोन) के लिए भाषण को पहचानने में सक्षम होने के लिए, आपको पहले इन उतार-चढ़ाव पर विचार करना चाहिए। माप आवृत्ति कम से कम 8,000 बार प्रति सेकंड (इससे भी बेहतर - 44,100 बार प्रति सेकंड) होनी चाहिए। यदि माप बड़े समय के रुकावट के साथ किए जाते हैं, तो हमें एक गलत ध्वनि मिलेगी, जिसका अर्थ है कि अवैध भाषण। ऊपर वर्णित प्रक्रिया को 8kHz या 44.1kHz डिजिटलीकरण के रूप में जाना जाता है।
जब ध्वनि तरंगों के कंपन पर डेटा एकत्र किया जाता है, तो उन्हें क्रमबद्ध करने की आवश्यकता होती है। चूंकि सामान्य ढेर में हमारे पास भाषण और माध्यमिक ध्वनियां (मशीन शोर, सरसराहट कागज, एक काम करने वाले कंप्यूटर की आवाज़, आदि) दोनों हैं। गणितीय संचालन का संचालन करने से हमें अपने भाषण को ठीक करने में मदद मिलती है, जिसे मान्यता की आवश्यकता होती है।
अगला चयनित ध्वनि तरंग - भाषण का विश्लेषण है। चूंकि इसमें कई अलग-अलग घटक होते हैं जो कुछ ध्वनियों का निर्माण करते हैं (उदाहरण के लिए, "आह" या "ईई")। इन विशेषताओं को हाइलाइट करना और उन्हें संख्यात्मक समकक्षों में परिवर्तित करना आपको विशिष्ट शब्दों को परिभाषित करने की अनुमति देता है।
उदाहरण के लिए, अंग्रेजी भाषा में, 40 से अधिक फोनीमे (44, सटीक होने के लिए, और कुछ सिद्धांतों के अनुसार 100 से अधिक हैं), अर्थात्। भाषण लगता है। मशीन उन सभी को निर्धारित करती है, क्योंकि इसके विकास की प्रक्रिया में, प्रशिक्षण परीक्षण आयोजित किए गए थे, जिसके दौरान विभिन्न लोगों ने एक ही शब्द और वाक्यांशों का उच्चारण किया था। तो मशीन समानता और अंतर को निर्धारित कर सकती है और ध्वनियों के निर्धारण के लिए एक एल्गोरिथ्म का निर्माण कर सकती है। यह इस तथ्य पर विचार करने के लायक है कि एक ध्वनि "दिखता है" न केवल किसी व्यक्ति (या बल्कि, उसके उच्चारण, उच्चारण, आवाज का समय, आदि) से प्रभावित होती है, बल्कि एक शब्द में विभिन्न ध्वनियों के संयोजन से भी। उदाहरण के लिए, "sTar" में "t" और "ciTy" में "t" एक कार के लिए पूरी तरह से अलग दिखते हैं।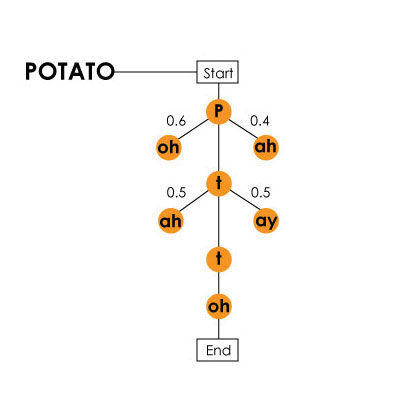 उदाहरण के रूप में "आलू" (कार्टेल) शब्द का उपयोग करते हुए मार्कोव मॉडल / हार्पी प्रणाली के बारे में वीडियो में मौजूद हैइसके अलावा, कंप्यूटर को मौखिक अनुक्रमों के गठन के लिए मॉडल का पालन करना चाहिए, यह निर्धारित करना चाहिए कि यह शब्दों को अलग करने के लायक कहां है। उदाहरण के लिए, एक वाक्यांश "हैंग टेन" है, जिसे कंप्यूटर इस तरह से विभाजित नहीं कर सकता है - "हे, एनजी", क्योंकि यह "डेटाबेस में" मेल नहीं खाता है।कंप्यूटर के लिए उक्त वाक्यांश के बजाय गिबरीश न देने के लिए, उसे यह समझने की आवश्यकता है कि कौन से शब्द उसके बाद जाते हैं। इसके लिए, न केवल ज्ञान आधार का उपयोग किया जाता है, जो घटक वाक्यांशों (शब्दों) को निर्धारित करने की अनुमति देता है, बल्कि आंशिक परिकल्पना एल्गोरिथ्म भी है, जिसकी मदद से मशीन यह निर्धारित करती है कि क्या शब्द संख्या 2 शब्द संख्या 1 के साथ संयोजन में उपयुक्त है या नहीं। वाक्यांश "नाश्ते के लिए बिल्लियों को क्या पसंद है?" "पानी गैसलाइट चार ईंट विशाल?" के रूप में सुना जा सकता है। ब्रैड, राइट। यह इस तरह के दुराचार को रोकने के लिए है कि ऊपर वर्णित एल्गोरिथ्म की आवश्यकता है। यह शब्दों के संयोजन की संभावना को भी ध्यान में रख सकता है, जो कि मशीन के तर्क के अनुसार, संयुक्त नहीं होना चाहिए। लेकिन परिकल्पना एल्गोरिथ्म मॉडल के इस सुधार में बहुत अधिक शक्ति की आवश्यकता होती है।इन सभी जटिल गणितीय, सांख्यिकीय और मापन प्रक्रियाओं को पूरा करने के बाद, कंप्यूटर उपयोगकर्ता को परिणाम देता है। इस तकनीक के सभी सौंदर्य, या इसके विकास के इस स्तर पर इस तकनीक की प्रणाली की अविश्वसनीय गति में निहित है।
उदाहरण के रूप में "आलू" (कार्टेल) शब्द का उपयोग करते हुए मार्कोव मॉडल / हार्पी प्रणाली के बारे में वीडियो में मौजूद हैइसके अलावा, कंप्यूटर को मौखिक अनुक्रमों के गठन के लिए मॉडल का पालन करना चाहिए, यह निर्धारित करना चाहिए कि यह शब्दों को अलग करने के लायक कहां है। उदाहरण के लिए, एक वाक्यांश "हैंग टेन" है, जिसे कंप्यूटर इस तरह से विभाजित नहीं कर सकता है - "हे, एनजी", क्योंकि यह "डेटाबेस में" मेल नहीं खाता है।कंप्यूटर के लिए उक्त वाक्यांश के बजाय गिबरीश न देने के लिए, उसे यह समझने की आवश्यकता है कि कौन से शब्द उसके बाद जाते हैं। इसके लिए, न केवल ज्ञान आधार का उपयोग किया जाता है, जो घटक वाक्यांशों (शब्दों) को निर्धारित करने की अनुमति देता है, बल्कि आंशिक परिकल्पना एल्गोरिथ्म भी है, जिसकी मदद से मशीन यह निर्धारित करती है कि क्या शब्द संख्या 2 शब्द संख्या 1 के साथ संयोजन में उपयुक्त है या नहीं। वाक्यांश "नाश्ते के लिए बिल्लियों को क्या पसंद है?" "पानी गैसलाइट चार ईंट विशाल?" के रूप में सुना जा सकता है। ब्रैड, राइट। यह इस तरह के दुराचार को रोकने के लिए है कि ऊपर वर्णित एल्गोरिथ्म की आवश्यकता है। यह शब्दों के संयोजन की संभावना को भी ध्यान में रख सकता है, जो कि मशीन के तर्क के अनुसार, संयुक्त नहीं होना चाहिए। लेकिन परिकल्पना एल्गोरिथ्म मॉडल के इस सुधार में बहुत अधिक शक्ति की आवश्यकता होती है।इन सभी जटिल गणितीय, सांख्यिकीय और मापन प्रक्रियाओं को पूरा करने के बाद, कंप्यूटर उपयोगकर्ता को परिणाम देता है। इस तकनीक के सभी सौंदर्य, या इसके विकास के इस स्तर पर इस तकनीक की प्रणाली की अविश्वसनीय गति में निहित है।उपसंहार
जैसा कि हम देखते हैं, इस तरह की एक आधुनिक और आश्चर्यजनक तकनीक ने बहुत पहले ही अपनी यात्रा शुरू कर दी थी। पिछली से पहले सदी में वापस। अगर उन दिनों में कोई यह कहेगा कि भविष्य में फोन पर बात करना संभव होगा (यह उल्लेख नहीं है कि यह वायरलेस है), तो कोई भी इस पर विश्वास नहीं करेगा। और इस तरह के बयानों के लेखक को संभवतः उपयुक्त अस्पताल में जबरन इलाज किया जाएगा। लेकिन अब यह तकनीक स्मार्टफोन, लैपटॉप, इंटरनेट जैसी आम हो गई है और भी बहुत कुछ। भविष्य की पीढ़ियों को भी याद नहीं हो सकता है कि एक बार, मशीनें एक व्यक्ति से बात नहीं कर सकती थीं।एक विज्ञापन के रूप में। नए साल में दिलचस्प प्रस्ताव का लाभ उठाने के लिए जल्दी करें और 3 या 6 महीने के लिए ऑर्डर करते समय पहले भुगतान पर 25% छूट प्राप्त करें!
ये सिर्फ वर्चुअल सर्वर नहीं हैं! ये समर्पित ड्राइव्स के साथ VPS (KVM) हैं, जो समर्पित सर्वरों से बदतर नहीं हो सकते हैं, और ज्यादातर मामलों में - बेहतर! हमने नीदरलैंड और यूएसए में समर्पित ड्राइव के साथ VPS (KVM) बनाया (VPS (KVM) से कॉन्फ़िगरेशन - E5-2650v4 (6 करोड़) / 10GB DDR4 / 240GB SSD या 4TB HDDD / 1Gbps 10TB $ 29 / महीने से कम कीमत पर उपलब्ध है। , RAID1 और RAID10 के साथ विकल्प उपलब्ध हैं) , एक नए प्रकार के वर्चुअल सर्वर के लिए ऑर्डर करने का मौका न चूकें, जहां सभी संसाधन आपके पास हैं, जैसा कि एक समर्पित एक पर है, और कीमत बहुत कम है, बहुत अधिक उत्पादक हार्डवेयर के साथ!भवन के बुनियादी ढांचे का निर्माण कैसे करें। एक पैसा के लिए 9,000 यूरो की लागत डेल R730xd E5-2650 v4 सर्वर का उपयोग कर वर्ग? डेल R730xd 2 बार सस्ता? केवल हमारे साथ2 x Intel डोडेका-कोर Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps नीदरलैंड और यूएसए में $ 249 से 100 टीवी !