Google ब्रेन डेवलपर्स ने साबित किया है कि "परस्पर विरोधी" छवियां एक व्यक्ति और एक कंप्यूटर दोनों को पकड़ सकती हैं; और संभावित परिणाम भयावह हैं।
ऊपर की तस्वीर में - बाईं तरफ एक बिल्ली का कोई संदेह नहीं है। लेकिन क्या आप यह सुनिश्चित करने के लिए कह सकते हैं कि बिल्ली सही पर है, या सिर्फ एक कुत्ता है जो उसके जैसा दिखता है? दोनों के बीच का अंतर यह है कि सही एक विशेष एल्गोरिथ्म का उपयोग करके बनाया गया है जो कंप्यूटर मॉडल को "कन्वेक्शनल न्यूरल नेटवर्क" नहीं देता है (CNNs, कन्वेन्शनल न्यूरल नेटवर्क, इसके बाद SNA के रूप में संदर्भित) को स्पष्ट रूप से चित्र में समाप्त करने के लिए। इस मामले में, एसएनएस का मानना है कि यह एक बिल्ली की तुलना में कुत्ते का अधिक है, लेकिन सबसे दिलचस्प रूप से - ज्यादातर लोग उसी तरह सोचते हैं।
यह एक "विरोधाभासी तस्वीर" कहा जाता है (इसके बाद KARP के रूप में जाना जाता है) का एक उदाहरण है: यह विशेष रूप से संशोधित किया गया है ताकि SNA को धोखा देने और सामग्री को सही ढंग से पहचाने जाने से रोका जा सके। Google ब्रेन के शोधकर्ता यह समझना चाहते थे कि क्या हमारे सिर में जैविक तंत्रिका नेटवर्क को उसी तरह से खराब करना संभव है, और परिणामस्वरूप बनाए गए विकल्प जो कारों और लोगों को समान रूप से प्रभावित करते हैं, जिससे उन्हें लगता है कि वे कुछ ऐसा देख रहे हैं वास्तव में नहीं।
परस्पर विरोधी छवियां क्या हैं?
लगभग हर जगह, SNA में मान्यता के लिए, दृश्य वर्गीकरण एल्गोरिदम का उपयोग किया जाता है। कार्यक्रम को "पांडा" के साथ बड़ी संख्या में विभिन्न चित्रण दिखाते हुए, आप इसे पांडा को पहचानने के लिए प्रशिक्षित कर सकते हैं, क्योंकि यह पूरे सेट के लिए एक सामान्य सुविधा के लिए तुलना करके सीखता है। जैसे ही एसएनए (जिसे
"क्लासिफायर" भी कहा जाता
है ) प्रशिक्षण डेटा पर "पांडा संकेत" की एक पर्याप्त सरणी एकत्र करता है, यह पांडा को किसी भी नए चित्रों में पहचानने में सक्षम होगा जो इसे प्रदान करेगा।
हम पांडा को उनकी सार विशेषताओं से पहचानते हैं: छोटे काले कान, बड़े सफेद सिर, काली आँखें, फर, और यह सब जैज। SNA अन्यथा करता है, जो आश्चर्य की बात नहीं है, क्योंकि पर्यावरण के बारे में जानकारी है कि लोगों को हर मिनट की व्याख्या बहुत बड़ी है। इसलिए, मॉडल की बारीकियों को ध्यान में रखते हुए, छवियों को इस तरह से प्रभावित करना संभव है कि उन्हें सावधानीपूर्वक गणना किए गए डेटा के साथ मिलाकर "असंगत" बनाया जाए, जिसके बाद एक व्यक्ति के लिए परिणाम लगभग मूल जैसा दिखेगा, लेकिन
क्लासिफायर के लिए पूरी तरह से अलग, जो निर्धारित करने की कोशिश करते समय गलतियां करना शुरू कर देगा। सामग्री।
यहाँ एक पांडा उदाहरण दिया गया है:
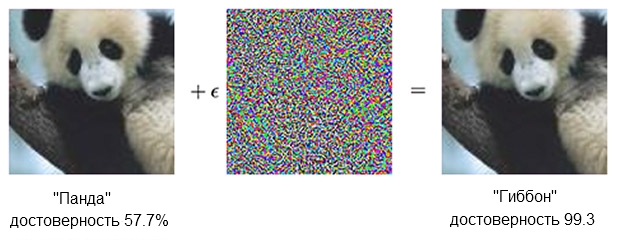 एक पांडा की छवि, आक्रोश के साथ मिलकर, क्लासिफायर को आश्वस्त कर सकती है कि यह वास्तव में एक गिबन है।स्रोत: OpenAI
एक पांडा की छवि, आक्रोश के साथ मिलकर, क्लासिफायर को आश्वस्त कर सकती है कि यह वास्तव में एक गिबन है।स्रोत: OpenAISNA पर आधारित
क्लासिफायर यह सुनिश्चित करता है कि बाईं ओर का पांडा लगभग 60% है। लेकिन अगर आप थोड़ा अराजक शोर ("आक्रोश पैदा करें") स्रोत को जोड़ते हैं, जो सिर्फ अराजक शोर की तरह दिखता है, तो वही क्लासिफायर 99.3 प्रतिशत सुनिश्चित होगा कि यह अब गिब्बन को देख रहा है। छोटे परिवर्तन जिन्हें स्पष्ट रूप से नहीं देखा जा सकता है, एक बहुत ही सफल हमले को जन्म देते हैं, लेकिन यह केवल एक विशिष्ट कंप्यूटर मॉडल पर काम करेगा और उन चीजों को नहीं करेगा जो किसी अन्य चीज़ पर "सीखा" जा सकता है।
कृत्रिम विश्लेषकों की एक बड़ी और विविध संख्या के बीच गलत प्रतिक्रिया को भड़काने वाली सामग्री बनाने के लिए, किसी को अधिक कठोर व्यवहार करना चाहिए - छोटे सुधारों को प्रभावित नहीं करेगा। मज़बूती से जो काम करता है वह "छोटे साधनों" के साथ नहीं किया जा सकता है। दूसरे शब्दों में, यदि आप सभी कोणों और दूरियों से काम करने वाली सामग्री प्राप्त करना चाहते हैं, तो आपको अधिक हस्तक्षेप करना होगा, या जैसा कि कोई व्यक्ति कहेगा, अधिक स्पष्ट है।
दृष्टि में - एक आदमी
यहां कठोर कार्प के दो उदाहरण हैं, जहां एक व्यक्ति आसानी से हस्तक्षेप का पता लगा सकता है।
 स्रोत: बाईं ओर ओपन AI , दाईं ओर Google ब्रेन
स्रोत: बाईं ओर ओपन AI , दाईं ओर Google ब्रेनबाईं ओर बिल्ली की तस्वीर, जिसे एसएनएस कंप्यूटर के रूप में परिभाषित किया गया है, "टूटी हुई ज्यामिति" का उपयोग करके बनाया गया था। यदि आप एक करीब नज़र डालें (या बहुत करीब नहीं हैं), तो आप देखेंगे कि कई कोणीय और बॉक्स के आकार की संरचनाएं हैं जो एक सिस्टम यूनिट के आकार के समान हो सकती हैं। और दाईं ओर केले की छवि, जिसे एक टोस्टर के रूप में मान्यता प्राप्त है, लगातार किसी भी दृष्टिकोण से एक झूठी सकारात्मक देता है। फिलहाल लोगों को यहां एक केला मिलेगा, हालांकि, इसके बगल में एक अजीब से गर्भनिरोधक में एक टोस्टर के कुछ संकेत हैं - और यह तकनीक को मूर्ख बनाता है।
जब आप एक गारंटीकृत उपयुक्त "विरोधाभासी" छवि बनाते हैं जिसे आपको पहचानने वाले मॉडल की एक पूरी कंपनी को हरा देने की आवश्यकता होती है, तो बहुत बार यह "मानव कारक" की उपस्थिति की ओर जाता है। दूसरे शब्दों में, जो एकल तंत्रिका नेटवर्क को भ्रमित करता है उसे एक समस्या के रूप में नहीं माना जा सकता है, और जब आप एक रिबस प्राप्त करने की कोशिश करते हैं जो निश्चित रूप से एक बार में पांच या दस को धोखा देने के लिए उपयुक्त होता है, तो यह पता चलता है कि यह तंत्र के आधार पर काम करता है, यदि लोग पूरी तरह से बेकार हैं।
नतीजतन, किसी व्यक्ति को यह विश्वास करने के लिए मजबूर करने की कोशिश करने की बिल्कुल आवश्यकता नहीं है कि कोणीय बिल्ली एक कंप्यूटर का मामला है, और एक केले और एक अजीब डब का योग एक टोस्टर की तरह दिखता है। आपके और मेरे लिए डिज़ाइन किए गए CARP को बनाते समय यह बहुत बेहतर है कि वे उन मॉडलों का उपयोग करने पर ध्यान केंद्रित करें जो दुनिया को लोगों के रूप में देखते हैं।
आँख (और मस्तिष्क) को चकरा देना
गहन प्रशिक्षण और मानवीय दृष्टि के साथ SNA कुछ समान हैं, लेकिन मूल रूप से तंत्रिका नेटवर्क "कंप्यूटर की तरह" चीजों पर "दिखता है"। उदाहरण के लिए, जब उसे एक चित्र खिलाया जाता है, तो वह एक ही समय में आयताकार पिक्सल के स्थिर ग्रिड को "देखती है"। आंख अलग तरीके से काम करती है, एक व्यक्ति दृष्टि की रेखा के प्रत्येक तरफ लगभग पांच डिग्री के क्षेत्र में उच्च विस्तार को मानता है, लेकिन इस क्षेत्र के बाहर, विस्तार पर ध्यान रैखिक रूप से कम हो जाता है।
इस प्रकार, एक मशीन के विपरीत, कहते हैं, एक छवि के किनारों को धुंधला करना एक व्यक्ति के साथ काम नहीं करेगा और बस किसी का ध्यान नहीं जाएगा। शोधकर्ता "रेटिना लेयर" जोड़कर इस सुविधा का अनुकरण करने में सक्षम थे जो एसएनए द्वारा आपूर्ति किए गए डेटा को आंख के लिए जैसा दिखता था, तंत्रिका नेटवर्क को सामान्य दृष्टि के समान फ्रेम में सीमित करने के लक्ष्य के साथ।
यह ध्यान दिया जाना चाहिए कि एक व्यक्ति अपनी धारणा की कमियों को इस तथ्य से सामना करता है कि टकटकी एक बिंदु पर निर्देशित नहीं होती है, लेकिन लगातार चलती है, संपूर्ण छवि की जांच करती है, लेकिन प्रयोग की शर्तों के लिए क्षतिपूर्ति करना भी संभव था, जो कि एसएनए और लोगों के बीच अंतर को समतल करती है।
कार्य से ध्यान दें:
प्रत्येक प्रयोग एक इंस्टॉलेशन क्रॉसहेयर के साथ शुरू हुआ, जो 500-1000 मिली सेकेंड के लिए स्क्रीन के केंद्र में दिखाई दिया, और प्रत्येक विषय को क्रॉसहेयर पर अपनी निगाहों को ठीक करने का निर्देश दिया गया था।"रेटिना लेयर" का उपयोग अंतिम चरण था जिसे "मानव सुविधाओं" के लिए मशीन सीखने के "पतले फिट" के हिस्से के रूप में लिया जाना था। नमूनों की पीढ़ी के दौरान, उन्हें दस अलग-अलग मॉडलों के माध्यम से संचालित किया गया था, जिनमें से प्रत्येक को स्पष्ट रूप से, कहना चाहिए, एक बिल्ली, उदाहरण के लिए, एक कुत्ता। यदि परिणाम "10 में से 10 गलत थे", तो सामग्री को मनुष्यों में परीक्षण के लिए प्रस्तुत किया गया था।
क्या यह काम करता है?
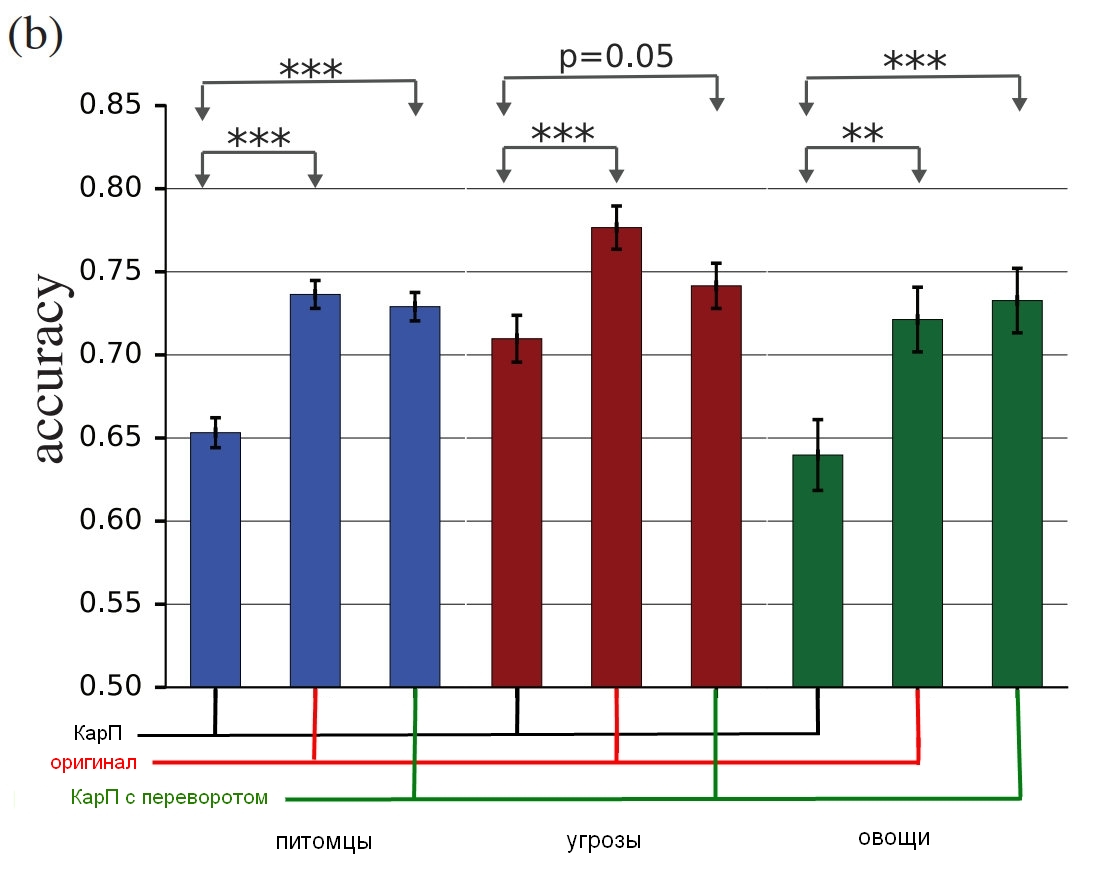
चित्रों के तीन समूह प्रयोग में शामिल थे: "पालतू जानवर" (बिल्लियाँ और कुत्ते), "सब्जियाँ" (तोरी और ब्रोकोली), और "धमकियाँ" (मकड़ियों और साँप, हालाँकि साँप के मालिक के रूप में मैं मूल्यांकन के लिए एक अलग शब्द सुझाऊँगा)। प्रत्येक समूह के लिए, सफलता को गिना जाता था यदि परीक्षण व्यक्ति ने गलत चीज को चुना - कुत्ते को बिल्ली कहा जाता है, और इसके विपरीत। प्रतिभागियों ने एक मॉनिटर के सामने बैठकर एक चित्र प्रदर्शित किया जो लगभग 60 या 70 मिली सेकेंड के लिए था, और उन्हें ऑब्जेक्ट को इंगित करने के लिए दो में से एक बटन दबाना था। चूंकि छवि को बहुत कम समय के लिए दिखाया गया था, इसने इस अंतर को समाप्त कर दिया कि लोग और तंत्रिका नेटवर्क दुनिया को कैसे समझते हैं; शीर्षक में चित्रण, त्रुटि के अपने दृढ़ता में हड़ताली है।
जो विषय दर्शाए गए हैं, वे एक असंबद्ध छवि (छवि), एक "साधारण" कार्प (सलाह), एक "उलटा" (फ्लिप) कार्प हो सकते हैं, जिस पर आवेदन से पहले शोर उल्टा हो गया था, या एक "गलत" कार्प, जिस पर एक परत थी शोर एक ऐसे चित्र पर लागू किया गया जो समूह के किसी भी प्रकार (झूठे) से संबंधित नहीं है। पिछले दो विकल्पों का उपयोग गड़बड़ी की प्रकृति को नियंत्रित करने के लिए किया गया था (क्या शोर संरचना अन्यथा उल्टा असर करेगी, या बस "खाओ-नहीं"?), इसके अलावा उन्होंने यह समझना संभव बना दिया कि क्या हस्तक्षेप लोगों को पूरी तरह से धोखा देता है या बस थोड़ी सी सटीकता को धोखा देता है।
कार्य से ध्यान दें:
गलत: विषय को गलत करने के लिए मजबूर करने के लिए एक शर्त जोड़ी गई। हमने इसे जोड़ा, क्योंकि यदि प्रारंभिक परिवर्तन पर्यवेक्षक की सटीकता को कम करते हैं, तो यह प्रत्यक्ष छवि गुणवत्ता में कमी के कारण हो सकता है। यह दिखाने के लिए कि CARPs वास्तव में प्रत्येक कक्षा में काम करते हैं, हमने उन विकल्पों को पेश किया जहां कोई विकल्प सही नहीं हो सकता था और उनकी सटीकता 0 थी, और हमने देखा कि वास्तव में उस मामले में "सही" उत्तर क्या था। हमने इमेजनेट से मनमानी छवियों का प्रदर्शन किया, जो समूह में एक या किसी अन्य वर्ग से प्रभावित थे, लेकिन उनमें से कोई भी फिट नहीं था। प्रयोग प्रतिभागी को यह निर्धारित करना था कि उसके सामने क्या था। उदाहरण के लिए, हम "कुत्ते" के शोर को लागू करके विकृत एक हवाई जहाज की तस्वीर दिखा सकते हैं, हालांकि प्रयोग के दौरान विषय को केवल एक बिल्ली या एक कुत्ते को मान्यता दी जानी चाहिए।यहां एक उदाहरण दिखाया गया है कि कितने प्रतिशत लोग एक तस्वीर को स्पष्ट रूप से कुत्ते के रूप में पहचानने में सक्षम थे, यह इस बात पर निर्भर करता है कि शोर का उपयोग कैसे किया गया था। मुझे आपको याद दिलाने के लिए, एक नज़र लेने और निर्णय लेने के लिए केवल 60-70 मिलीसेकंड था।
 स्रोत: गूगल ब्रेन
स्रोत: गूगल ब्रेन
एक कुत्ते के साथ मूल तस्वीर; एक कुत्ते के साथ कार्प, एक आदमी और एक कंप्यूटर दोनों द्वारा स्वीकार किया जाता है; शोर की एक परत के साथ नियंत्रण छवि उलटी हो गई।और यहाँ अंतिम परिणाम हैं:
 स्रोत: गूगल ब्रेन
स्रोत: गूगल ब्रेन
अध्ययन के परिणाम, कितने सच्चे लोग विकृत चित्रों की तुलना में इन चित्रों की पहचान करते हैं।चार्ट मैच की सटीकता को दर्शाता है। यदि आप एक बिल्ली चुनते हैं और यह वास्तव में एक बिल्ली है, तो सटीकता बढ़ जाती है। यदि आप एक बिल्ली चुनते हैं, लेकिन यह वास्तव में एक कुत्ता है, तो शोर को एक तरह की बिल्ली में बदल दिया जाता है, सटीकता कम हो जाती है।
जैसा कि आप देख सकते हैं, लोग "असंगत" लोगों के चयन की तुलना में अनियोजित छवियों के चयन में बहुत अधिक सही हैं या उल्टे शोर परतों के साथ हैं। यह साबित करता है कि धारणा पर हमले के सिद्धांत को कंप्यूटर से हमारे पास स्थानांतरित किया जा सकता है।
न केवल प्रभाव निर्विवाद रूप से प्रभावी हैं, वे अपेक्षा से भी पतले हैं - कोई बॉक्सकैट्स या छद्म टोस्टर या ऐसा कुछ भी नहीं। चूंकि हमने प्रसंस्करण से पहले और बाद में शोर और छवियों के साथ दोनों परतों को देखा, हमें यह पता लगाने की आवश्यकता है कि इसमें वास्तव में हमें क्या भ्रमित करता है। हालांकि शोधकर्ता सतर्क हैं, उन्होंने कहा कि "हमारे उदाहरण विशेष रूप से सिर को मूर्ख बनाने के लिए बनाए गए हैं, इसलिए आपको प्रभाव का अध्ययन करने के लिए प्रयोगात्मक रूप से लोगों का उपयोग करने से सावधान रहना चाहिए।"
भविष्य में, टीम संशोधन की कुछ श्रेणियों के लिए कुछ सामान्य नियमों को प्राप्त करने का प्रयास करेगी, जिसमें "
किसी वस्तु के किनारों का विनाश , विशेष रूप से मध्यम प्रभावों के साथ, किनारे की रेखा से लंबवत, सीमा
की बनावट के दौरान
सीमा क्षेत्रों के सुधार ;
बनावट को बदलते हुए, अंधेरे भागों का उपयोग करके ;
" छोटी-मोटी गड़बड़ियों के बावजूद धारणा पर प्रभाव का स्तर उच्च है।" निम्नलिखित उदाहरण हैं जहां लाल चक्कर वाले क्षेत्र जिनमें वर्णित विधियां सबसे अच्छी देखी जाती हैं।
 स्रोत: गूगल ब्रेन
स्रोत: गूगल ब्रेन
विभिन्न विरूपण सिद्धांतों के साथ छवियों के उदाहरणपरिणाम क्या है?
लब्बोलुआब यह है कि यह अधिक है, सिर्फ एक चतुर चाल से बहुत अधिक है। Google ब्रेन के लोगों ने पुष्टि की कि वे धोखे की एक प्रभावी तकनीक बना सकते हैं, लेकिन वे पूरी तरह से नहीं समझते हैं कि यह क्यों काम करता है, अमूर्तता के स्तर को ध्यान में रखते हुए, और यह संभव है कि यह वास्तव में वास्तविकता का एक मूल स्तर है:
हमारी परियोजना इस बारे में बुनियादी सवाल उठाती है कि कैसे कार्प काम करते हैं, कैसे तंत्रिका नेटवर्क और मस्तिष्क काम करते हैं। क्या आपने SNA से मस्तिष्क में हमलों को स्थानांतरित करने का प्रबंधन किया क्योंकि उनमें सूचनाओं का शब्दार्थ निरूपण समान है? या क्योंकि ये दोनों प्रतिनिधित्व एक निश्चित सामान्य शब्दार्थ मॉडल के अनुरूप हैं, जो स्वाभाविक रूप से आसपास की दुनिया में मौजूद है?
अंत में, यदि आप वास्तव में थोड़ा पागल होना चाहते हैं, तो शोधकर्ता आपको एक एहसान करने के लिए खुश हैं, यह इंगित करते हुए कि "वस्तुओं की दृश्य मान्यता ... एक उद्देश्य मूल्यांकन देना मुश्किल है। क्या "अंजीर। 1" सही मायने में एक कुत्ता है, या यह एक उद्देश्य बिल्ली है जो लोगों को यह सोच सकता है कि यह एक कुत्ता है? " दूसरे शब्दों में, क्या तस्वीर वास्तव में एक वस्तु में बदल जाती है, या बस आपको अलग तरह से सोचने का मौका देती है?
यहां यह डरावना है (और मैं गंभीरता से "डरावना" कहता हूं) कि अंत में आपको किसी भी तथ्य को प्रभावित करने के तरीके मिल सकते हैं, क्योंकि SNA में हेरफेर करने और किसी व्यक्ति को हेरफेर करने के बीच की दूरी स्पष्ट रूप से बहुत बड़ी नहीं है। तदनुसार, मशीन सीखने की तकनीकों का उपयोग संभवतः छवियों या वीडियो को सही तरीके से विकृत करने के लिए किया जा सकता है, जो हमारी धारणा (और इसी प्रतिक्रिया) को बदल देगा, और हम यह भी समझ नहीं पाए कि क्या हुआ था। रिपोर्ट से:
उदाहरण के लिए, इन-डेप्थ ट्रेनिंग वाले मॉडलों के एक समूह को कुछ प्रकार के व्यक्तियों, विशेषताओं, अभिव्यक्तियों में आत्मविश्वास के स्तर के लोगों के आकलन पर प्रशिक्षित किया जा सकता है। "परस्पर विरोधी" आक्रोश उत्पन्न करना संभव हो जाएगा जो "विश्वसनीयता" की भावना को बढ़ाएगा या घटाएगा, और ऐसी "ट्वीड" सामग्री का उपयोग समाचार क्लिप या राजनीतिक विज्ञापन में किया जा सकता है।
भविष्य में, सैद्धांतिक जोखिमों में संवेदी उत्तेजना पैदा करने की संभावना शामिल होती है जो मस्तिष्क में विभिन्न प्रकार से और बहुत ही उच्च दक्षता के साथ टूट जाती है। जैसा कि आप जानते हैं, कई जानवरों को अति-थ्रेशोल्ड उत्तेजनाओं के रूप में देखा जाता है। मान लें कि कोयल एक साथ असहाय होने का दिखावा कर सकते हैं और एक वादी कॉल कर सकते हैं, जो संयोजन में अन्य नस्लों के पक्षियों को अपने स्वयं के वंश से पहले कोयल की चूजों को खिलाने का कारण बनता है। "संघर्षपूर्ण" नमूनों को तंत्रिका नेटवर्क के लिए सुपरथ्रेशोल्ड उत्तेजना का ऐसा अजीब रूप माना जा सकता है। और यह तथ्य कि अत्यधिक उत्तेजना, जो सिद्धांत में किसी व्यक्ति को प्रभावित करने की तुलना में अधिक संभव है कि वे कुत्ते की तस्वीर पर "बिल्ली" को लटका दें, काफी चिंता का कारण है, एक मशीन का उपयोग करके बनाया जा सकता है और फिर लोगों को हस्तांतरित किया जा सकता है।
बेशक, इस तरह के तरीकों का उपयोग "अच्छे के लिए" किया जा सकता है, और कई विकल्प पहले ही प्रस्तावित किए जा चुके हैं, जैसे "एकाग्रता की स्तर बढ़ाने के लिए छवियों की विशिष्ट विशेषताओं को तेज करना, उदाहरण के लिए, जब वायु की स्थिति को नियंत्रित करना या एक्स-रे छवियों का विश्लेषण करना, क्योंकि यह काम नीरस है, और परिणाम। लापरवाही भयानक हो सकती है। ” इसके अलावा, "उपयोगकर्ता इंटरफ़ेस डिजाइनर अधिक सहज ज्ञान युक्त इंटरफेस विकसित करने के लिए गड़बड़ी का उपयोग कर सकते हैं।" हममम। यह निश्चित रूप से बहुत अच्छा है, लेकिन मैं किसी तरह अपने दिमाग को हैक करने और लोगों में विश्वास के स्तर को स्थापित करने के बारे में अधिक चिंतित हूं, आप जानते हैं?
प्रस्तुत किए गए कुछ प्रश्न भविष्य के शोध का विषय होंगे - यह पता लगाया जा सकता है कि किसी व्यक्ति को गलती बताने के लिए क्या विशिष्ट चित्र वास्तव में अधिक उपयुक्त बनाता है, और यह मस्तिष्क के सिद्धांतों को समझने के लिए नए सुराग प्रदान कर सकता है। और यह बदले में, अधिक उन्नत तंत्रिका नेटवर्क बनाने में मदद करेगा जो तेजी से और बेहतर सीखेंगे। लेकिन हमें सावधान रहना चाहिए और याद रखना चाहिए कि, कंप्यूटर की तरह, कभी-कभी हमें धोखा देना इतना मुश्किल नहीं है।
प्रोजेक्ट
"एडवरसैरियल एग्जाम्स जो कि गनडेल्डिन एफ। एल्सैयड, श्रेया शंकर, ब्रायन चेउंग, निकोलस पैपरनोट, एलेक्स कुराकिन, इयान गुडफेलो और गूगल ब्रेन से जैस्चा सोहल-डिकस्टीन द्वारा मानव और कंप्यूटर विज़न , दोनों को आर्कएक्सिव से डाउनलोड किया जा सकता है। और यदि आपको अधिक विवादास्पद चित्रों की आवश्यकता है जो लोगों पर काम करते हैं, तो सहायक सामग्री
यहां है ।