हम में से प्रत्येक एक काम करता है। हर कोई बॉयलरप्लेट कोड लिखता है। क्यों? क्या इस प्रक्रिया को स्वचालित करना और केवल दिलचस्प कार्यों पर काम करना बेहतर नहीं है? इस लेख को पढ़ें यदि आप चाहते हैं कि कंप्यूटर आपके लिए ऐसा काम करे।
 यह लेख एक Uber मोबाइल ऐप डेवलपर, Zack Sweers की एक रिपोर्ट के एक ट्रांसक्रिप्ट पर आधारित है, जिसने 2017 में MBLT DEV सम्मेलन में बात की थी।
यह लेख एक Uber मोबाइल ऐप डेवलपर, Zack Sweers की एक रिपोर्ट के एक ट्रांसक्रिप्ट पर आधारित है, जिसने 2017 में MBLT DEV सम्मेलन में बात की थी।
Uber में लगभग 300 मोबाइल ऐप डेवलपर हैं। मैं एक टीम में काम करता हूं जिसे "मोबाइल प्लेटफॉर्म" कहा जाता है। मेरी टीम का काम जितना संभव हो सके मोबाइल एप्लिकेशन को विकसित करने की प्रक्रिया को सरल और बेहतर बनाना है। हम मुख्य रूप से आंतरिक ढांचे, पुस्तकालयों, आर्किटेक्चर, और इसी तरह से काम करते हैं। बड़े कर्मचारियों के कारण, हमें बड़े पैमाने पर परियोजनाओं को करना होगा जो हमारे इंजीनियरों को भविष्य में आवश्यकता होगी। यह कल हो सकता है, या शायद अगले महीने या एक साल भी हो सकता है।
स्वचालन के लिए कोड पीढ़ी
मैं कोड पीढ़ी प्रक्रिया के मूल्य को प्रदर्शित करना चाहूंगा, साथ ही कुछ व्यावहारिक उदाहरणों पर विचार करूंगा। प्रक्रिया ही कुछ इस तरह दिखती है:
FileSpec.builder("", "Presentation") .addComment("Code generating your way to happiness.") .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", "Zac Sweers") .useSiteTarget(FILE) .build()) .build()
यह कोटलिन कवि का उपयोग करने का एक उदाहरण है। कोटलिन कवि एक अच्छा एपीआई के साथ एक पुस्तकालय है जो कोटलिन कोड उत्पन्न करता है। तो हम यहाँ क्या देखते हैं?
- FileSpec.builder एक फ़ाइल बनाता है जिसे “ Presentation ” कहा जाता है।
- .addComment () - उत्पन्न कोड में एक टिप्पणी जोड़ता है।
- .addAnnotation () - टाइप ऑथर का एनोटेशन जोड़ता है।
- .addMember () - पैरामीटर के साथ एक चर " नाम " जोड़ता है, हमारे मामले में यह " Zac Sweers " है। % S - पैरामीटर प्रकार।
- .useSiteTarget () - SiteTarget स्थापित करता है।
- .build () - उत्पन्न होने वाले कोड का विवरण पूरा करता है।
कोड पीढ़ी के बाद, निम्नलिखित प्राप्त होता है:
Presentation.kt // Code generating your way to happiness. @file:Author(name = "Zac Sweers")
कोड जनरेशन का परिणाम लेखक के नाम, टिप्पणी, टिप्पणी और नाम के साथ एक फाइल है। प्रश्न तुरंत उठता है: "मुझे इस कोड को उत्पन्न करने की आवश्यकता है यदि मैं इसे कुछ सरल चरणों में कर सकता हूं?" हां, आप सही हैं, लेकिन क्या होगा अगर मुझे विभिन्न कॉन्फ़िगरेशन विकल्पों के साथ इन फ़ाइलों की एक हजार की आवश्यकता है? यदि हम इस कोड में मूल्यों को बदलना शुरू करते हैं तो क्या होगा? अगर हमारे पास कई प्रस्तुतियाँ हैं तो क्या होगा? क्या होगा अगर हमारे पास बहुत सारे सम्मेलन हैं?
conferences .flatMap { it.presentations } .onEach { (presentationName, comment, author) -> FileSpec.builder("", presentationName) .addComment(comment) .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", author) .useSiteTarget(FILE) .build()) .build() }
नतीजतन, हम इस निष्कर्ष पर पहुंचेंगे कि मैन्युअल रूप से ऐसी कई फाइलों को बनाए रखना असंभव है - इसे स्वचालित करना आवश्यक है। इसलिए, कोड जनरेशन का पहला फायदा रूटीन काम से छुटकारा पा रहा है।
त्रुटि मुक्त कोड पीढ़ी
स्वचालन का दूसरा महत्वपूर्ण लाभ त्रुटि मुक्त संचालन है। सभी लोग गलतियाँ करते हैं। यह विशेष रूप से अक्सर होता है जब हम एक ही काम करते हैं। कंप्यूटर, इसके विपरीत, इस तरह के काम को पूरी तरह से करते हैं।
एक साधारण उदाहरण पर विचार करें। एक व्यक्ति वर्ग है:
class Person(val firstName: String, val lastName: String)
मान लीजिए कि हम JSON में इसे क्रमांकन जोड़ना चाहते हैं। हम
मोशी पुस्तकालय का उपयोग कर ऐसा करेंगे, क्योंकि यह प्रदर्शन के लिए काफी सरल और महान है। एक पर्सनजोन एडेप्टर बनाएं और टाइप पर्सन के पैरामीटर के साथ JsonAdapter से वारिस करें:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { }
अगला, हम fromJson विधि को लागू करते हैं। यह पढ़ने के लिए एक पाठक प्रदान करता है जो अंततः व्यक्ति को वापस कर दिया जाएगा। फिर हम पहले और अंतिम नाम के साथ फ़ील्ड भरें और व्यक्ति का नया मूल्य प्राप्त करें:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String return Person(firstName, lastName) } }
अगला, हम JSON प्रारूप में डेटा को देखते हैं, इसे जांचें और इसे आवश्यक फ़ील्ड में दर्ज करें:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() } } return Person(firstName, lastName) } }
क्या यह काम करेगा? हां, लेकिन एक अति सूक्ष्म अंतर है: जिन वस्तुओं को हम पढ़ते हैं उन्हें JSON के अंदर होना चाहिए। सर्वर से आने वाले अतिरिक्त डेटा को फ़िल्टर करने के लिए, कोड की दूसरी पंक्ति जोड़ें:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() else -> reader.skipValue() } } return Person(firstName, lastName) } }
इस बिंदु पर, हम नियमित रूप से नियमित कोड के क्षेत्र को दरकिनार करते हैं। इस उदाहरण में, केवल दो मान फ़ील्ड। हालाँकि, इस कोड में विभिन्न वर्गों का एक समूह है जहाँ आप अचानक दुर्घटनाग्रस्त हो सकते हैं। अचानक हमने कोड में गलती कर दी?
एक अन्य उदाहरण पर विचार करें:
class Person(val firstName: String, val lastName: String) class City(val name: String, val country: String) class Vehicle(val licensePlate: String) class Restaurant(val type: String, val address: Address) class Payment(val cardNumber: String, val type: String) class TipAmount(val value: Double) class Rating(val numStars: Int) class Correctness(val confidence: Double)
यदि आपको हर 10 मॉडल में कम से कम एक समस्या है, तो इसका मतलब है कि आपको निश्चित रूप से इस क्षेत्र में कठिनाइयाँ होंगी। और यह वह स्थिति है जब कोड पीढ़ी वास्तव में आपकी सहायता के लिए आ सकती है। यदि बहुत सारी कक्षाएं हैं, तो आप स्वचालन के बिना काम नहीं कर पाएंगे, क्योंकि सभी लोग टाइपो की अनुमति देते हैं। कोड पीढ़ी की मदद से, सभी कार्य स्वचालित रूप से और त्रुटियों के बिना किए जाएंगे।
कोड पीढ़ी के लिए अन्य लाभ हैं। उदाहरण के लिए, यह कोड के बारे में जानकारी देता है या कुछ गलत होने पर आपको बताता है। परीक्षण चरण के दौरान कोड पीढ़ी उपयोगी होगी। यदि आप उत्पन्न कोड का उपयोग करते हैं, तो आप देख सकते हैं कि काम करने वाला कोड वास्तव में कैसा दिखेगा। आप अपने काम को आसान बनाने के लिए परीक्षणों के दौरान कोड पीढ़ी भी चला सकते हैं।
निष्कर्ष: यह त्रुटियों से छुटकारा पाने के लिए संभावित समाधान के रूप में कोड पीढ़ी पर विचार करने के लायक है।
अब सॉफ्टवेयर टूल देखते हैं जो कोड जनरेशन की मदद करते हैं।
उपकरण
- Java और Kotlin के लिए JavaPoet और KotlinPoet लाइब्रेरी क्रमशः। ये कोड जनरेशन के मानक हैं।
- मानकीकरण। जावा के लिए टेम्प्लेट करने का एक लोकप्रिय उदाहरण अपाचे वेलोसिटी है , और आईओएस हैंडल के लिए ।
- एसपीआई - सेवा प्रोसेसर इंटरफ़ेस। यह जावा में बनाया गया है और आपको एक इंटरफ़ेस बनाने और लागू करने की अनुमति देता है और फिर इसे एक जार में घोषित करता है। जब प्रोग्राम निष्पादित किया जाता है, तो आप इंटरफ़ेस के सभी तैयार किए गए कार्यान्वयन प्राप्त कर सकते हैं।
- कंपाइल टेस्टिंग Google की एक लाइब्रेरी है जो कंप्लायंस टेस्टिंग में मदद करती है। कोड पीढ़ी के संदर्भ में, इसका मतलब है: "यहां वही है जो मुझे उम्मीद थी, लेकिन यहां वह है जो मुझे अंततः मिला है।" संकलन मेमोरी में शुरू होगा, और फिर सिस्टम आपको बताएगा कि यह प्रक्रिया पूरी हुई या क्या त्रुटियां हुईं। यदि संकलन पूरा हो गया है, तो आपको अपनी अपेक्षाओं के साथ परिणाम की तुलना करने के लिए कहा जाएगा। तुलना संकलित कोड पर आधारित है, इसलिए कोड स्वरूपण या कुछ और जैसी चीजों के बारे में चिंता न करें।
कोड बिल्ड टूल
बिल्डिंग कोड के लिए दो मुख्य उपकरण हैं:
- एनोटेशन प्रोसेसिंग - आप कोड में एनोटेशन लिख सकते हैं और उनके बारे में अतिरिक्त जानकारी के लिए कार्यक्रम पूछ सकते हैं। कंपाइलर स्रोत कोड के साथ काम करने से पहले ही जानकारी दे देगा।
- ग्रैडल अपने कोड असेंबली लाइफ साइकल में कई हुक (फंक्शन कॉल के अवरोधन) के साथ एक एप्लीकेशन असेंबली सिस्टम है। यह Android विकास में व्यापक रूप से उपयोग किया जाता है। यह आपको कोड पीढ़ी को स्रोत कोड पर लागू करने की भी अनुमति देता है, जो वर्तमान स्रोत से स्वतंत्र है।
अब कुछ उदाहरणों पर विचार करें।
मक्खन चाकू
बटर नाइफ जेक व्हार्टन द्वारा विकसित एक पुस्तकालय है। वह डेवलपर समुदाय में एक प्रसिद्ध व्यक्ति हैं। एंड्रॉइड डेवलपर्स के बीच लाइब्रेरी बहुत लोकप्रिय है क्योंकि यह बड़ी मात्रा में नियमित काम से बचने में मदद करता है जो लगभग हर किसी का सामना करता है।
आमतौर पर हम इस तरह से दृश्य को इनिशियलाइज़ करते हैं:
TextView title; ImageView icon; void onCreate(Bundle savedInstanceState) { title = findViewById(R.id.title); icon = findViewById(R.id.icon); }
बटरकनीफ़ के साथ, यह इस तरह दिखेगा:
@BindView(R.id.title) TextView title; @BindView(R.id.icon) ImageView icon; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
और हम आसानी से किसी भी संख्या को जोड़ सकते हैं, जबकि ऑनक्रैट विधि बॉयलरप्लेट कोड नहीं बढ़ाएगी:
@BindView(R.id.title) TextView title; @BindView(R.id.text) TextView text; @BindView(R.id.icon) ImageView icon; @BindView(R.id.button) Button button; @BindView(R.id.next) Button next; @BindView(R.id.back) Button back; @BindView(R.id.open) Button open; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
हर बार इस बंधन को मैन्युअल रूप से करने के बजाय, आप बस इन फ़ील्ड्स में @BindView एनोटेशन और साथ ही पहचानकर्ता (आईडी) जोड़ते हैं, जिसे उन्हें सौंपा गया है।
बटर नाइफ के बारे में अच्छी बात यह है कि यह कोड का विश्लेषण करेगा और इसके सभी समान खंडों को आप तक पहुंचाएगा। नए डेटा के लिए इसमें उत्कृष्ट मापनीयता भी है। इसलिए, यदि नया डेटा दिखाई देता है, तो फिर से onCreate को लागू करने या मैन्युअल रूप से कुछ ट्रैक करने की कोई आवश्यकता नहीं है। यह लाइब्रेरी डाटा डिलीट करने के लिए भी बढ़िया है।
तो, यह प्रणाली अंदर से कैसी दिखती है? दृश्य को कोड मान्यता द्वारा खोजा जाता है, और यह प्रक्रिया एनोटेशन प्रोसेसिंग स्टेज पर की जाती है।
हमारे पास यह क्षेत्र है:
@BindView(R.id.title) TextView title;
इन आंकड़ों को देखते हुए, उनका उपयोग एक निश्चित FooActivity में किया जाता है:
उसका अपना अर्थ (R.id.title) है, जो लक्ष्य के रूप में कार्य करता है। कृपया ध्यान दें कि डेटा प्रोसेसिंग के दौरान यह ऑब्जेक्ट सिस्टम के अंदर एक निरंतर मूल्य बन जाता है:
यह सामान्य है। यह वही है जो बटर नाइफ के पास वैसे भी पहुंच होना चाहिए। एक प्रकार के रूप में एक TextView घटक है। फ़ील्ड को ही शीर्षक कहा जाता है। यदि, उदाहरण के लिए, हम इस डेटा से एक कंटेनर क्लास बनाते हैं, तो हमें कुछ ऐसा मिलता है:
ViewBinding( target = "FooActivity", id = 2131361859, name = "title", type = "field", viewType = TextView.class )
तो, इन सभी डेटा को उनके प्रसंस्करण के दौरान आसानी से प्राप्त किया जा सकता है। यह बटर नाइफ सिस्टम के अंदर क्या करता है, यह भी बहुत समान है।
परिणामस्वरूप, यह वर्ग यहाँ उत्पन्न होता है:
public final class FooActivity_ViewBinding implements Unbinder { private FooActivity target; @UiThread public FooActivity_ViewBinding(FooActivity target, View source) { this.target = target; target.title = Utils.findRequiredViewAsType(source, 2131361859,
यहां हम देखते हैं कि इन सभी डेटा के टुकड़े एक साथ इकट्ठा होते हैं। परिणामस्वरूप, हमारे पास अंडरस्कोर जावा लाइब्रेरी से व्यूबाइंडिंग लक्ष्य वर्ग है। अंदर, इस प्रणाली को इस तरह से व्यवस्थित किया जाता है कि हर बार जब आप कक्षा का एक उदाहरण बनाते हैं, तो यह तुरंत आपके द्वारा उत्पन्न की गई जानकारी (कोड) के लिए यह सभी बाध्यकारी कार्य करता है। और यह सब पहले से एनोटेशन के प्रसंस्करण के दौरान सांख्यिकीय रूप से उत्पन्न होता है, जिसका अर्थ है कि यह तकनीकी रूप से सही है।
चलो हमारे सॉफ्टवेयर पाइपलाइन पर वापस आते हैं:
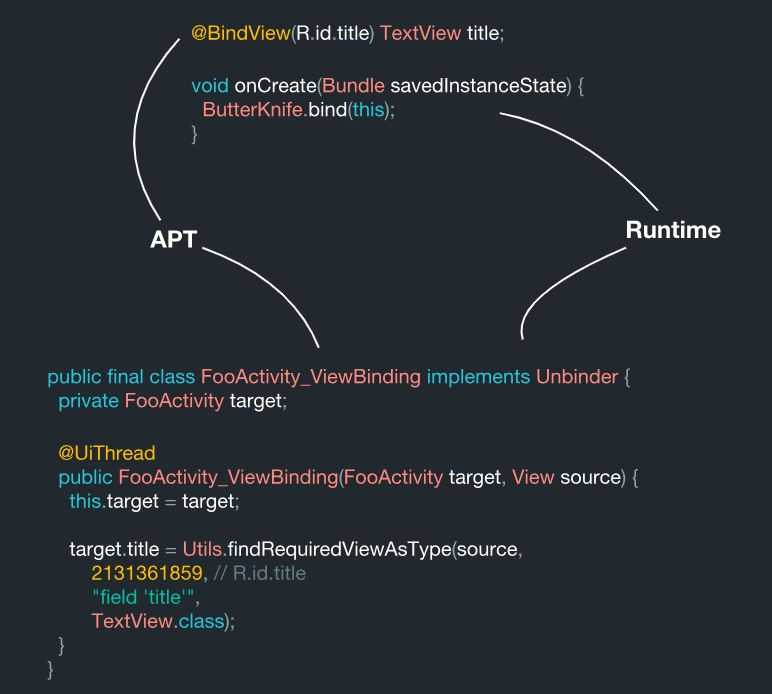
एनोटेशन प्रोसेसिंग के दौरान, सिस्टम इन एनोटेशन को पढ़ता है और व्यूबाइंडिंग क्लास बनाता है। और फिर बाइंड विधि के दौरान, हम एक ही वर्ग के लिए एक समान तरीके से एक समान खोज करते हैं: हम इसका नाम लेते हैं और अंत में व्यूबाइंड को जोड़ते हैं। अपने आप में, प्रसंस्करण के दौरान ViewBinding के साथ एक अनुभाग जावापॉइट का उपयोग करके निर्दिष्ट क्षेत्र में ओवरराइट किया जाता है।
RxBindings
RxBindings अकेले कोड जनरेशन के लिए ज़िम्मेदार नहीं है। यह एनोटेशन को हैंडल नहीं करता है और यह ग्रैडल प्लगइन नहीं है। यह एक साधारण पुस्तकालय है। यह एंड्रॉइड एपीआई के लिए प्रतिक्रियाशील प्रोग्रामिंग के सिद्धांत पर आधारित स्थिर कारखाने प्रदान करता है। इसका मतलब यह है कि, उदाहरण के लिए, यदि आपके पास setOnClickListener है, तो एक क्लिक विधि दिखाई देगी जो (ऑब्जर्वेबल) घटनाओं की एक धारा को वापस कर देगी। यह एक पुल (डिजाइन पैटर्न) के रूप में कार्य करता है।
लेकिन वास्तव में RxBinding में कोड पीढ़ी है:
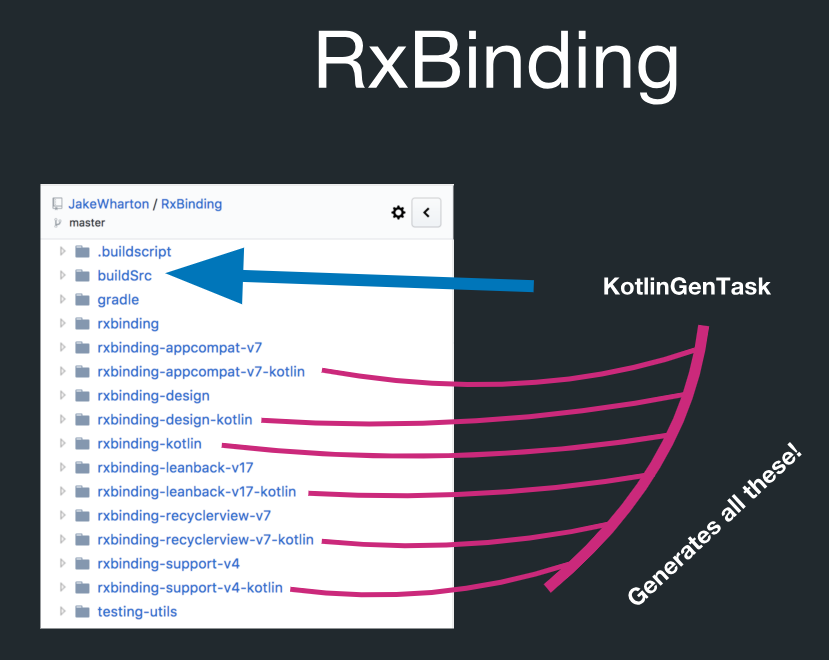
BuildSrc नामक इस डायरेक्टरी में KotlinGenTask नामक ग्रैडल टास्क है। इसका मतलब है कि यह सब वास्तव में कोड जनरेशन द्वारा बनाया गया है। RxBinding में जावा कार्यान्वयन है। उसके पास कोटलिन कलाकृतियां भी हैं जिनमें सभी प्रकार के लक्ष्य के लिए विस्तार कार्य शामिल हैं। और यह सब बहुत कड़ाई से नियमों के अधीन है। उदाहरण के लिए, आप सभी कोटलिन एक्सटेंशन फ़ंक्शन उत्पन्न कर सकते हैं, और आपको उन्हें व्यक्तिगत रूप से नियंत्रित करने की आवश्यकता नहीं है।
यह वास्तव में कैसा दिखता है?
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
यहाँ एक पूरी तरह से क्लासिक RxBinding विधि है। अवलोकनीय वस्तुएँ यहाँ लौटा दी जाती हैं। विधि क्लिक कहलाती है। क्लिक इवेंट के साथ काम करना "हूड के तहत" होता है। हम उदाहरण की पठनीयता को बनाए रखने के लिए अतिरिक्त कोड अंशों को छोड़ देते हैं। कोटलिन में, यह इस तरह दिखता है:
fun View.clicks(): Observable<Object> = RxView.clicks(this)
यह एक्सटेंशन फ़ंक्शन ऑब्जर्व करने योग्य ऑब्जेक्ट देता है। कार्यक्रम की आंतरिक संरचना में, यह सीधे हमारे लिए सामान्य जावा इंटरफ़ेस कहता है। कोटलिन में, आपको इसे यूनिट प्रकार में बदलना होगा:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
यही है, जावा में, यह इस तरह दिखता है:
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
और इसलिए कोटलिन कोड है:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
हमारे पास एक RxView वर्ग है जिसमें यह विधि है। हम लक्ष्य विशेषता में डेटा के संबंधित टुकड़ों को विधि के नाम के साथ नाम विशेषता में और जिस प्रकार का हम विस्तार कर रहे हैं, साथ ही वापसी मूल्य के प्रकार में स्थानापन्न कर सकते हैं। यह सभी जानकारी इन विधियों को लिखना शुरू करने के लिए पर्याप्त होगी:
BindingMethod( target = "RxView", name = "clicks", type = View.class, returnType = "Observable<Unit>" )
अब हम सीधे इन टुकड़ों को प्रोग्राम के अंदर उत्पन्न कोटलिन कोड में स्थानापन्न कर सकते हैं। यहाँ परिणाम है:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
सेवा जन
हम उबर में सर्विस जनरल पर काम कर रहे हैं। यदि आप एक कंपनी में काम करते हैं और सामान्य विशेषताओं और बैकएंड और क्लाइंट पक्ष दोनों के लिए एक सामान्य सॉफ़्टवेयर इंटरफ़ेस के साथ काम करते हैं, तो चाहे आप एंड्रॉइड, आईओएस या वेब एप्लिकेशन विकसित कर रहे हों, यह मैन्युअल रूप से मॉडल और सेवाएं बनाने के लिए कोई मतलब नहीं है। टीम के काम के लिए।
हम ऑब्जेक्ट मॉडल के लिए Google के
AutoValue लाइब्रेरी का उपयोग करते हैं। यह एनोटेशन की प्रक्रिया करता है, डेटा का विश्लेषण करता है और एक दो-लाइन हैश कोड, समान () विधि और अन्य कार्यान्वयन उत्पन्न करता है। वह एक्सटेंशन के समर्थन के लिए भी ज़िम्मेदार है।
हमारे पास राइडर का प्रकार है:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
हमारे पास ID, firstname, lastname और एड्रेस वाली लाइनें हैं। नेटवर्क के साथ काम करने के लिए, हम डेटा प्रारूप के रूप में रेट्रोफिट और ओकेहटप लाइब्रेरीज़, और JSON का उपयोग करते हैं। हम प्रतिक्रियाशील प्रोग्रामिंग के लिए RxJava का भी उपयोग करते हैं। यह हमारी उत्पन्न एपीआई सेवा की तरह दिखता है:
interface UberService { @GET("/rider") Rider getRider() }
हम यह सब मैन्युअल रूप से लिख सकते हैं, अगर हम चाहें तो। और लंबे समय तक, हमने किया। लेकिन इसमें बहुत समय लगता है। अंत में, यह समय और धन के मामले में बहुत खर्च होता है।
उबर आज क्या और कैसे करता है
मेरी टीम का अंतिम कार्य खरोंच से एक पाठ संपादक बनाना है। हमने अब मैन्युअल रूप से कोड लिखने का फैसला किया है जो बाद में नेटवर्क को हिट करता है, इसलिए हम
थ्रिफ्ट का उपयोग करते हैं। यह एक प्रोग्रामिंग भाषा और एक ही समय में एक प्रोटोकॉल जैसा कुछ है। उबेर तकनीकी विशेषताओं के लिए थ्रिफ्ट को एक भाषा के रूप में उपयोग करता है।
struct Rider { 1: required string uuid; 2: required string firstName; 3: required string lastName; 4: optional Address address; }
थ्रिफ्ट में, हम बैकएंड और क्लाइंट साइड के बीच एपीआई कॉन्ट्रैक्ट्स को परिभाषित करते हैं, और फिर बस उपयुक्त कोड उत्पन्न करते हैं। हम डेटा को पार्स करने के लिए
Thrifty लाइब्रेरी का उपयोग करते हैं, और कोड जनरेशन के लिए JavaPoet का। अंत में, हम AutoValue का उपयोग करके कार्यान्वयन उत्पन्न करते हैं:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
हम JSON में सभी काम करते हैं।
AutoValue Moshi नामक एक एक्सटेंशन है, जिसे स्थैतिक jsonAdapter विधि का उपयोग करके AutoValue कक्षाओं में जोड़ा जा सकता है:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); static JsonAdapter<Rider> jsonAdapter(Moshi moshi) { return new AutoValue_Rider.JsonAdapter(moshi); } }
थ्रिफ्ट भी सेवाओं के विकास में मदद करता है:
service UberService { Rider getRider() }
हमें यहां कुछ मेटाडेटा भी जोड़ना होगा ताकि हमें पता चल सके कि हम क्या परिणाम प्राप्त करना चाहते हैं:
service UberService { Rider getRider() (path="/rider") }
कोड पीढ़ी के बाद, हम अपनी सेवा प्राप्त करेंगे:
interface UberService { @GET("/rider") Single<Rider> getRider(); }
लेकिन यह संभावित परिणामों में से केवल एक है। एक मॉडल। जैसा कि हम अनुभव से जानते हैं, किसी ने भी केवल एक मॉडल का उपयोग नहीं किया है। हमारे पास कई मॉडल हैं जो हमारी सेवाओं के लिए कोड उत्पन्न करते हैं:
struct Rider struct City struct Vehicle struct Restaurant struct Payment struct TipAmount struct Rating
फिलहाल हमारे पास लगभग 5-6 आवेदन हैं। और उनकी कई सेवाएं हैं। और हर कोई एक ही सॉफ्टवेयर पाइपलाइन के माध्यम से जाता है। हाथ से यह सब लिखना पागल होगा।
JSON में क्रमांकन में, "एडेप्टर" को मोशी में पंजीकृत होने की आवश्यकता नहीं है, और यदि आप JSON का उपयोग करते हैं, तो आपको JSON में पंजीकरण करने की आवश्यकता नहीं है। DI ग्राफ़ के माध्यम से कोड को फिर से लिखने के द्वारा कर्मचारियों को deserialization करने का सुझाव देना भी संदिग्ध है।
लेकिन हम जावा के साथ काम करते हैं, इसलिए हम फ़ैक्टरी पैटर्न का उपयोग कर सकते हैं, जो हम
भग्न पुस्तकालय के माध्यम से उत्पन्न करते हैं। हम इसे उत्पन्न कर सकते हैं क्योंकि संकलन होने से पहले हम इन प्रकारों के बारे में जानते हैं। भिन्नात्मक इस तरह एक अनुकूलक उत्पन्न करता है:
class ModelsAdapterFactory implements JsonAdapter.Factory { @Override public JsonAdapter<?> create(Type type, Set<? extends Annotation> annotations, Moshi moshi) { Class<?> rawType = Types.getRawType(type); if (rawType.isAssignableFrom(Rider.class)) { return Rider.adapter(moshi); } else if (rawType.isAssignableFrom(City.class)) { return City.adapter(moshi); } else if (rawType.isAssignableFrom(Vehicle.class)) { return Vehicle.adapter(moshi); }
उत्पन्न कोड बहुत अच्छा नहीं लगता है। यदि यह आंख को नुकसान पहुंचाता है, तो इसे मैन्युअल रूप से फिर से लिखा जा सकता है।
यहां आप सेवाओं के नाम के साथ पहले उल्लिखित प्रकार देख सकते हैं। सिस्टम स्वचालित रूप से निर्धारित करेगा कि कौन से एडेप्टर का चयन करें और उन्हें कॉल करें। लेकिन यहां हमें एक और समस्या का सामना करना पड़ रहा है। हमारे पास इनमें से 6000 एडेप्टर हैं। यहां तक कि अगर आप उन्हें एक ही टेम्पलेट के भीतर आपस में बांटते हैं, तो "ईट्स" या "ड्राइवर" मॉडल "राइडर" मॉडल में गिर जाएगा या इसके आवेदन में होगा। कोड खिंचाव होगा। एक निश्चित बिंदु के बाद, यह एक .dex फ़ाइल में भी फिट नहीं हो सकता है। इसलिए, आपको किसी तरह एडाप्टरों को अलग करने की आवश्यकता है:

अंततः, हम पहले से कोड का विश्लेषण करेंगे और ग्रैडल के अनुसार, इसके लिए एक कार्यशील सबप्रोजेक्ट तैयार करेंगे:

आंतरिक संरचना में, ये निर्भरता ग्रेडल निर्भरता बन जाती है। राइडर एप्लिकेशन का उपयोग करने वाले तत्व अब इस पर निर्भर करते हैं। इसके साथ, वे उन मॉडलों का निर्माण करेंगे जिनकी उन्हें ज़रूरत है। नतीजतन, हमारा कार्य हल हो जाएगा, और यह सब कार्यक्रम के अंदर कोड असेंबली प्रणाली द्वारा विनियमित होगा।
लेकिन यहां हमें एक और समस्या का सामना करना पड़ रहा है: अब हमारे पास कारखाने मॉडल की एक एन-संख्या है। उन सभी को विभिन्न वस्तुओं में संकलित किया गया है:
class RiderModelFactory class GiftCardModelFactory class PricingModelFactory class DriverModelFactory class EATSModelFactory class PaymentsModelFactory
प्रसंस्करण एनोटेशन की प्रक्रिया में, केवल बाहरी निर्भरता के लिए एनोटेशन को पढ़ना और उन पर केवल अतिरिक्त कोड पीढ़ी करना संभव नहीं होगा।
समाधान: हमारे पास भग्न पुस्तकालय में कुछ सहायता है, जो हमें एक मुश्किल तरीके से मदद करता है। यह डेटा बाइंडिंग प्रक्रिया में निहित है। हम उनके आगे के भंडारण के लिए जावा संग्रह में क्लासपैथ पैरामीटर का उपयोग करके मेटाडेटा का परिचय देते हैं:
class RiderModelFactory // -> json // -> ridermodelfactory-fractory.bin class MyAppGlobalFactory // Delegates to all discovered fractories
अब, हर बार आपको उन्हें एप्लिकेशन में उपयोग करने की आवश्यकता होती है, हम इन फ़ाइलों के साथ क्लासपाथ निर्देशिका के फ़िल्टर में जाते हैं, और फिर हम उन्हें JSON प्रारूप में वहां से निकालते हैं ताकि यह पता लगाया जा सके कि कौन सी निर्भरताएं उपलब्ध हैं।
यह सब एक साथ कैसे फिट बैठता है
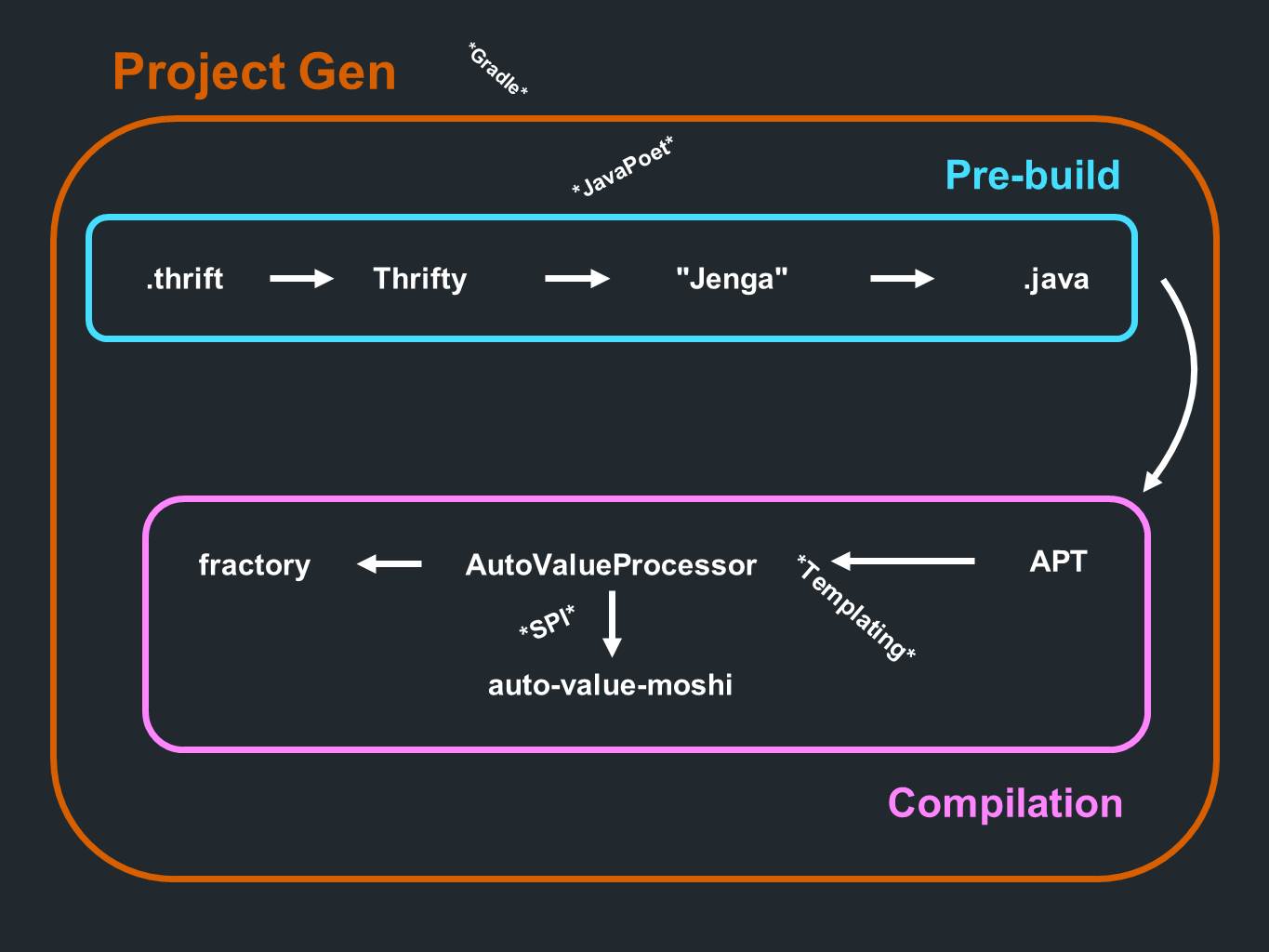
हमारे पास एक
थ्रिफ्ट है । वहां से डेटा
थ्रिप्टी में जाता है और पार्सिंग के माध्यम से जाता है। फिर वे एक कोड जनरेशन प्रोग्राम से गुजरते हैं जिसे हम
जेंगा कहते हैं। यह जावा फॉर्मेट में फाइल तैयार करता है। यह सब प्रसंस्करण के प्रारंभिक चरण या संकलन से पहले भी होता है। और संकलन प्रक्रिया के दौरान, एनोटेशन संसाधित होते हैं। कार्यान्वयन उत्पन्न
करने के लिए यह
AutoValue की बारी
है । यह JSON समर्थन प्रदान करने के लिए
AutoValue Moshi को भी कॉल करता है।
भग्न भी
शामिल है । सब कुछ संकलन प्रक्रिया के दौरान होता है। परियोजना को बनाने के लिए एक घटक से पहले प्रक्रिया होती है, जो मुख्य रूप से
ग्रैड सबप्रोजेक्ट उत्पन्न करती है।
अब जब आप पूरी तस्वीर देखते हैं, तो आप उन उपकरणों को नोटिस करना शुरू करते हैं जो पहले उल्लेख किए गए थे। इसलिए, उदाहरण के लिए, कोड पीढ़ी के लिए टेम्प्लेट, ऑटोवैल्यू, JavaPoet बनाने के लिए ग्रेड है। सभी उपकरण न केवल अपने आप में उपयोगी हैं, बल्कि एक-दूसरे के साथ संयोजन में भी उपयोगी हैं।कोड पीढ़ी के विपक्ष
नुकसान के बारे में बताना आवश्यक है। सबसे स्पष्ट माइनस कोड को फूला रहा है और इसका नियंत्रण खो रहा है। उदाहरण के लिए, डैगर एप्लिकेशन में सभी कोड का लगभग 10% हिस्सा लेता है। मॉडल में लगभग 25% - एक बड़ा हिस्सा है।उबेर में, हम अनावश्यक कोड को फेंककर समस्या को हल करने का प्रयास करते हैं। हमें कोड का कुछ सांख्यिकीय विश्लेषण करना होगा और समझना होगा कि कौन से क्षेत्र वास्तव में काम में शामिल हैं। जब हमें पता चलता है, हम कुछ परिवर्तन कर सकते हैं और देख सकते हैं कि क्या होता है।हम उत्पन्न मॉडलों की संख्या को लगभग 40% कम करने की उम्मीद करते हैं। यह अनुप्रयोगों की स्थापना और संचालन को गति देने में मदद करेगा, साथ ही साथ हमें पैसे भी बचाएगा।कोड पीढ़ी परियोजना विकास की समयसीमा को कैसे प्रभावित करती है
कोड पीढ़ी, बेशक, विकास को गति देती है, लेकिन समय उन उपकरणों पर निर्भर करता है जो टीम उपयोग करती है। उदाहरण के लिए, यदि आप ग्रैडल में काम कर रहे हैं, तो सबसे अधिक संभावना है कि आप इसे मापा गति से कर रहे हैं। तथ्य यह है कि ग्रैडल दिन में एक बार मॉडल बनाता है, न कि जब डेवलपर चाहता है।Uber और अन्य शीर्ष कंपनियों में विकास के बारे में अधिक जानें।
28 सितंबर को, मोबाइल डेवलपर्स MBLT DEV का 5 वां अंतर्राष्ट्रीय सम्मेलन मास्को में शुरू हो रहा है । 800 प्रतिभागियों, शीर्ष वक्ताओं, क्विज़ और पहेली उन लोगों के लिए जो एंड्रॉइड और आईओएस के विकास में रुचि रखते हैं। सम्मेलन के आयोजक ई-लीजन और आरएईसी हैं। आप सम्मेलन वेबसाइट पर MBLT DEV 2018 के भागीदार या भागीदार बन सकते हैं ।
रिपोर्ट वीडियो