प्रीप्रोसेसिंग उनके मॉडल को स्थानांतरित करने से पहले डेटा के साथ किए गए सभी जोड़तोड़ के लिए एक सामान्य शब्द है, जिसमें सेंटिंग, सामान्यकरण, स्थानांतरण, घूर्णन, फसल, आदि शामिल हैं। एक नियम के रूप में, दो मामलों में प्रीप्रोसेसिंग की आवश्यकता होती है।
- डेटा की सफाई । मान लें कि कुछ कलाकृतियाँ छवियों में मौजूद हैं। मॉडल प्रशिक्षण की सुविधा के लिए, पूर्व प्रसंस्करण चरण में कलाकृतियों को हटाया जाना चाहिए।
- डेटा का जोड़ । कभी-कभी छोटे डेटा सेट उच्च गुणवत्ता वाले गहरे मॉडल के प्रशिक्षण के लिए पर्याप्त नहीं होते हैं। इस समस्या को हल करने में एक डेटा पूरक दृष्टिकोण बहुत सहायक है। यह प्रत्येक डेटा नमूने को विभिन्न तरीकों से बदलने और डेटा सेट में ऐसे संशोधित नमूने जोड़ने की प्रक्रिया है। इस तरह, डेटा सेट के प्रभावी आकार को बढ़ाया जा सकता है।
केरस के माध्यम से पूर्व-प्रसंस्करण और उनके कार्यान्वयन के दौरान कुछ संभावित परिवर्तन विधियों पर विचार करें।

डेटा
इस और बाद के लेखों में, छवियों के भावनात्मक रंग का विश्लेषण करने के लिए एक डेटासेट का उपयोग किया जाएगा। इसमें छवियों के 1,500 उदाहरण हैं, जो दो वर्गों में विभाजित हैं - सकारात्मक और नकारात्मक। आइए कुछ उदाहरण देखें।
 नकारात्मक उदाहरण
नकारात्मक उदाहरण सकारात्मक उदाहरण
सकारात्मक उदाहरणसफाई रूपांतरण
अब आमतौर पर डेटा को साफ करने के लिए उपयोग किए जाने वाले संभावित परिवर्तनों, उनके कार्यान्वयन और छवियों पर प्रभाव पर विचार करें।
सभी कोड स्निपेट
प्रीप्रोसेसिंग.पिनब किताब में पाए जा सकते हैं।
rescaling
छवियाँ आमतौर पर RGB (Red Green Blue) प्रारूप में संग्रहीत की जाती हैं। इस प्रारूप में, छवि को तीन-आयामी (या तीन-चैनल) सरणी द्वारा दर्शाया गया है।
 छवि का आरजीबी अपघटन। विकीवंड से लिया गया चार्ट
छवि का आरजीबी अपघटन। विकीवंड से लिया गया चार्टएक आयाम चैनलों (लाल, हरा और नीला) के लिए उपयोग किया जाता है, अन्य दो स्थान का प्रतिनिधित्व करते हैं। इस प्रकार, प्रत्येक पिक्सेल तीन संख्याओं के साथ एन्कोडेड है। प्रत्येक संख्या को आमतौर पर 8-बिट अहस्ताक्षरित पूर्णांक प्रकार (0 से 255) के रूप में संग्रहीत किया जाता है।
Rescaling एक ऑपरेशन है जो डेटा की संख्यात्मक सीमा को केवल एक पूर्व निर्धारित स्थिरांक द्वारा विभाजित करके बदलता है। गहरे तंत्रिका नेटवर्क में, संभावित अतिप्रवाह, अनुकूलन मुद्दों, स्थिरता, आदि के कारण इनपुट डेटा को 0 से 1 तक सीमित करना आवश्यक हो सकता है।
उदाहरण के लिए, हम अपने डेटा को श्रेणी [0 से पुनर्विक्रय करते हैं; 255] सीमा तक [0]; 1]। इसके बाद, हम
केरस इमेजडैगनेटेटर वर्ग का उपयोग करेंगे, जो आपको मक्खी पर सभी परिवर्तनों को करने की अनुमति देता है।
आइए इस वर्ग के दो उदाहरण बनाएँ: एक परिवर्तित डेटा के लिए, दूसरा स्रोत के लिए:

(या डिफ़ॉल्ट डेटा के लिए)। केवल स्केलिंग स्थिरांक को निर्दिष्ट करना आवश्यक है। इसके अलावा,
ImageDataGenerator वर्ग आपको
flow_from_directory विधि का उपयोग करके अपनी हार्ड ड्राइव पर एक फ़ोल्डर से सीधे डेटा स्ट्रीम करने की अनुमति देता है।
सभी मापदंडों को
प्रलेखन में पाया जा सकता है, लेकिन मुख्य पैरामीटर हैं: स्ट्रीम और लक्ष्य छवि आकार का पथ (यदि छवि लक्ष्य आकार से मेल नहीं खाती है, तो जनरेटर बस काटता है या बनाता है)। अंत में, हम जनरेटर से एक नमूना प्राप्त करते हैं और परिणामों पर विचार करते हैं।
नेत्रहीन, दोनों छवियां समान हैं, लेकिन इसका कारण यह है कि पायथन * उपकरण स्वचालित रूप से छवियों का आकार बदलते हैं
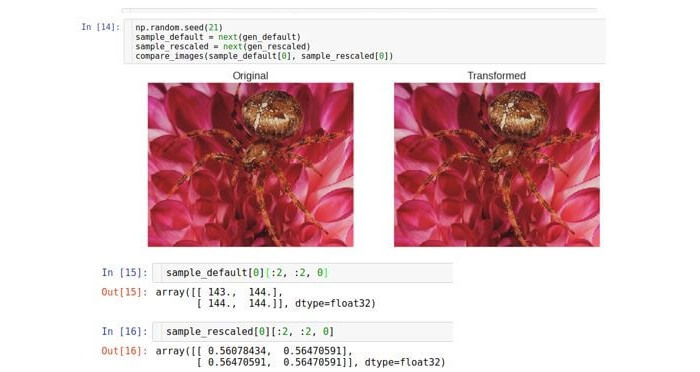
डिफ़ॉल्ट सीमा पर ताकि वे स्क्रीन पर प्रदर्शित हो सकें। कच्चे डेटा (सरणियों) पर विचार करें। जैसा कि आप देख सकते हैं, कच्चे द्रव्यमान लगभग 255 गुना भिन्न होते हैं।
भूरे रंग में अनुवाद
एक अन्य प्रकार का रूपांतरण जो उपयोगी हो सकता है,
ग्रेस्केल है , जो एक रंग RGB छवि को एक छवि में परिवर्तित करता है जिसमें सभी रंगों को ग्रे के रंगों में दर्शाया जाता है। पारंपरिक छवि प्रसंस्करण बाद की सीमा के साथ संयोजन में ग्रेस्केल अनुवाद का उपयोग कर सकता है। परिवर्तनों की यह जोड़ी शोर पिक्सेल को अस्वीकार कर सकती है और छवि में आकृतियों को परिभाषित कर सकती है। आज, ये सभी ऑपरेशन कन्वेंशनल न्यूरल नेटवर्क (सीएनएन) द्वारा किए जाते हैं, लेकिन पूर्व-प्रसंस्करण कदम के रूप में ग्रेस्केल रूपांतरण अभी भी उपयोगी हो सकता है। इस चरण को Keras में उसी जनरेटर वर्ग के साथ चलाएँ।
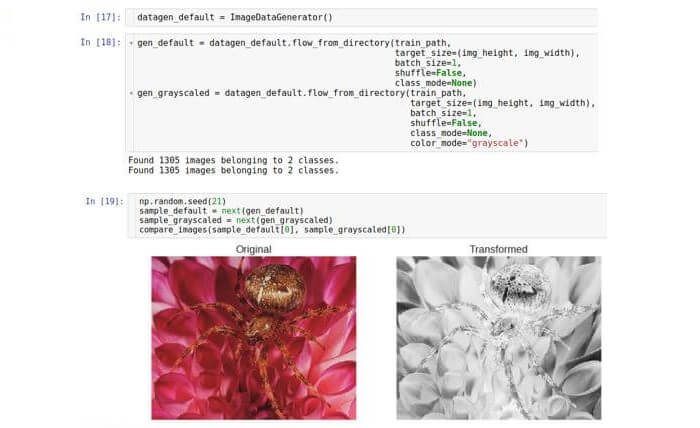
यहां हम कक्षा का केवल एक उदाहरण बनाते हैं और इसमें से दो अलग-अलग जनरेटर लेते हैं। दूसरा जनरेटर
color_mode पैरामीटर को "ग्रेस्केल" (डिफ़ॉल्ट मान "RGB") सेट करता है।
केंद्रित नमूने
हमने पहले ही देखा है कि कच्चे डेटा का मान 0 से 255 तक होता है। इस प्रकार, एक नमूना 0 से 255 तक की तीन-आयामी सरणी है। अनुकूलन की स्थिरता के सिद्धांतों के प्रकाश में (गायब या संतृप्त मूल्यों की समस्या से छुटकारा पाने के लिए),
डेटा सेट को सामान्य करने के लिए आवश्यक हो सकता है। ताकि प्रत्येक डेटा नमूने का औसत 0 हो ।
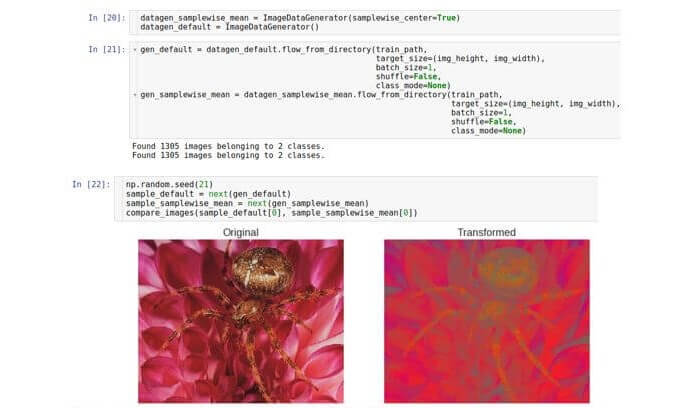
इसके लिए, पूरे नमूने पर औसत मूल्य की गणना करना और दिए गए नमूने में प्रत्येक संख्या से इसे घटाना आवश्यक है।
कैरस में , यह
नमूनावाइज_सेंटर पैरामीटर का उपयोग करके किया जाता है।
नमूनों के मानक विचलन का सामान्यीकरण
यह पूर्व-प्रसंस्करण चरण नमूनों के केंद्र के समान विचार पर आधारित है, लेकिन औसत से 0 सेट करने के बजाय, यह मानक विचलन को 1 पर सेट करता है।
 मानक
मानक विचलन का सामान्यीकरण पैरामीटर
नमूनावाइज_स्टीडी_नॉर्मलाइजेशन द्वारा नियंत्रित किया
जाता है । यह ध्यान दिया जाना चाहिए कि नमूनों को सामान्य करने के इन दो तरीकों को अक्सर एक साथ उपयोग किया जाता है।
इस परिवर्तन का उपयोग गहन शिक्षण मॉडल में किया जा सकता है ताकि विस्फोट के प्रभाव को कम करके अनुकूलन स्थिरता में सुधार किया जा सके।
सुविधा केंद्र
पिछले दो खंडों ने एक सामान्यीकरण तकनीक का उपयोग किया था जो डेटा के प्रत्येक व्यक्तिगत नमूने को देखता था। सामान्यीकरण प्रक्रिया के लिए एक वैकल्पिक दृष्टिकोण है। एक संकेत के रूप में छवि सरणी में प्रत्येक संख्या पर विचार करें। फिर
प्रत्येक छवि एक सुविधा वेक्टर है । डेटासेट में ऐसे कई वैक्टर हैं; इसलिए, हम उन्हें कुछ अज्ञात
वितरण के रूप में मान सकते हैं। यह वितरण बहु-पैरामीटर है, और इसका आयाम सुविधाओं की संख्या के बराबर होगा, अर्थात, चौड़ाई × ऊंचाई × 3. हालांकि डेटा का सही वितरण अज्ञात है, आप औसत वितरण घटाकर इसे सामान्य करने का प्रयास कर सकते हैं। यह ध्यान दिया जाना चाहिए कि औसत मूल्य समान आयाम का एक वेक्टर है, अर्थात, यह एक छवि भी है। दूसरे शब्दों में, हम संपूर्ण डेटा सेट पर औसत रखते हैं, न कि एक नमूने पर।
एक विशेष
केरस पैरामीटर है जिसे
फीचरवाइज_केंटरिंग कहा जाता है, लेकिन, दुर्भाग्य से, अगस्त 2017 तक, इसके कार्यान्वयन में एक त्रुटि थी; इसलिए, हम इसे स्वयं लागू करते हैं। सबसे पहले, हम मेमोरी में सेट किए गए पूरे डेटा पर विचार करते हैं (हम इसे बर्दाश्त कर सकते हैं, क्योंकि हम एक छोटे डेटा सेट के साथ काम कर रहे हैं)। हमने पैकेट के आकार को डेटा सेट के आकार से सेट करके ऐसा किया। फिर हम संपूर्ण डेटा सेट पर औसत छवि की गणना करते हैं और अंत में इसे परीक्षण छवि से घटाते हैं।
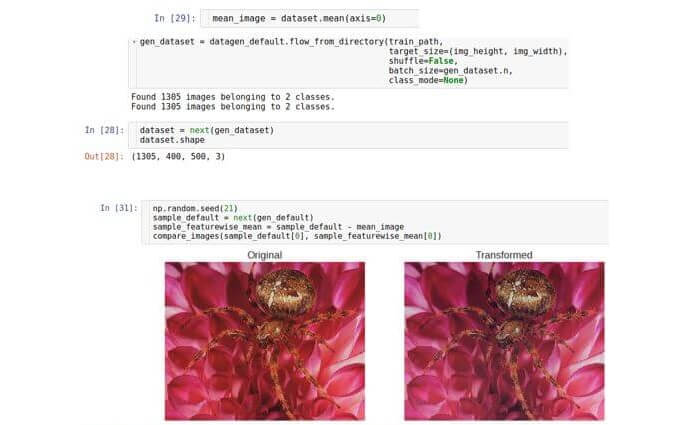
लक्षणों के मानक विचलन का सामान्यीकरण
मानक विचलन को सामान्य करने का विचार बिल्कुल वैसा ही है जैसा कि केंद्रित करने का विचार है। अंतर केवल इतना है कि औसत को घटाने के बजाय, हम मानक विचलन द्वारा विभाजित करते हैं। नेत्रहीन, परिणाम बहुत अलग नहीं है। वही काम हुआ

rescaling के दौरान, चूंकि मानक विचलन का सामान्यीकरण एक निश्चित तरीके से गणना की गई निरंतरता के साथ rescaling से अधिक कुछ नहीं है, और सरल rescaling के साथ, स्थिरांक को मैन्युअल रूप से निर्दिष्ट किया जाता है। ध्यान दें कि डेटा पैकेटों को सामान्य करने का एक समान विचार एक आधुनिक गहन सीखने की तकनीक के केंद्र में है जिसे
बैचनॉर्मलाइज़ेशन कहा जाता है।
जोड़ के साथ परिवर्तन
इस खंड में, हम कई डेटा-निर्भर परिवर्तनों को देखते हैं जो स्पष्ट रूप से डेटा की चित्रमय प्रकृति का उपयोग करते हैं। इस प्रकार के परिवर्तनों को अक्सर डेटा जोड़ प्रक्रियाओं में उपयोग किया जाता है।
रोटेशन
इस प्रकार का परिवर्तन छवि को एक निश्चित दिशा (दक्षिणावर्त या वामावर्त) में घुमाता है।
रोटेशन की अनुमति देने वाले पैरामीटर को रोटेशन_रेन्ग कहा जाता है। यह डिग्री में उस सीमा को इंगित करता है जिसमें से रोटेशन कोण को एक समान वितरण के साथ यादृच्छिक रूप से चुना जाता है। यह ध्यान दिया जाना चाहिए कि रोटेशन के दौरान छवि का आकार नहीं बदलता है। इस प्रकार, छवि के कुछ हिस्सों को क्रॉप किया जा सकता है और कुछ को भरा जा सकता है।
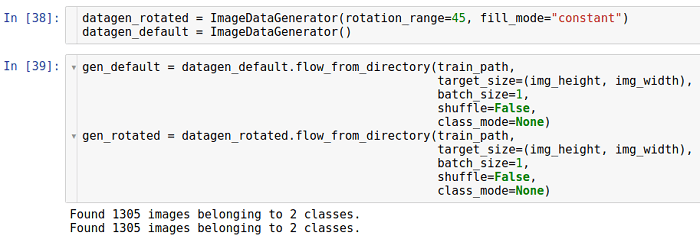
भरण मोड
fill_mode पैरामीटर का उपयोग करके सेट किया गया है। यह विभिन्न भरने के तरीकों का समर्थन करता है, लेकिन यहां हम उदाहरण के रूप में
निरंतर विधि का उपयोग करते हैं।
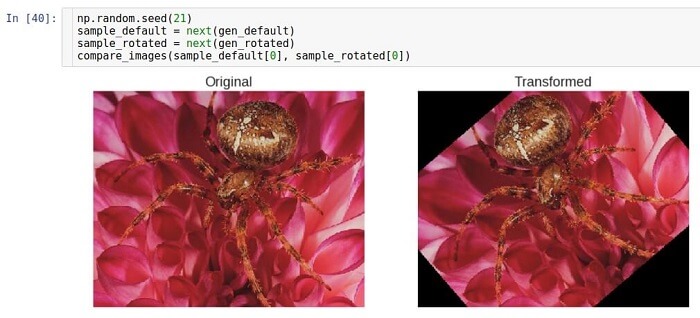
क्षैतिज बदलाव
इस प्रकार का परिवर्तन छवि को क्षैतिज अक्ष (बाएं या दाएं) के साथ एक निश्चित दिशा में स्थानांतरित करता है।

शिफ्ट का आकार
width_shift_range पैरामीटर का उपयोग करके निर्धारित किया जा सकता है और कुल छवि चौड़ाई के हिस्से के रूप में मापा जा सकता है।
लंबवत बदलाव
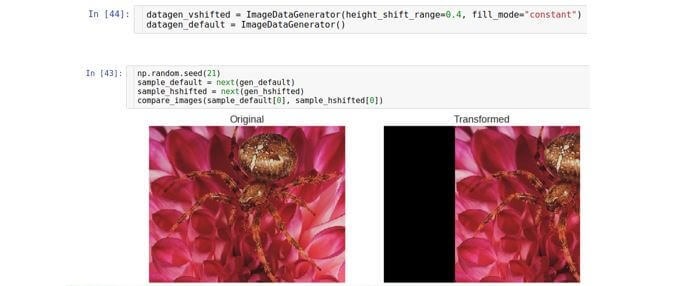
ऊर्ध्वाधर अक्ष (ऊपर या नीचे) के साथ छवि को स्थानांतरित करता है। शिफ्ट रेंज को नियंत्रित करने वाले पैरामीटर को
height_shift जनरेटर कहा जाता है और इसे छवि की कुल ऊंचाई के भाग के रूप में भी मापा जाता है।
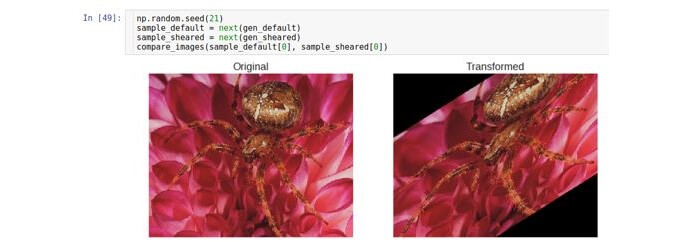
छंटाई
एक क्रॉप रूपांतरण या क्रॉपिंग प्रत्येक बिंदु को ऊर्ध्वाधर दिशा में उस बिंदु से दूरी के अनुपात में छवि के किनारे तक ले जाती है। ध्यान दें कि सामान्य स्थिति में, दिशा ऊर्ध्वाधर नहीं होती है और मनमानी होती है।
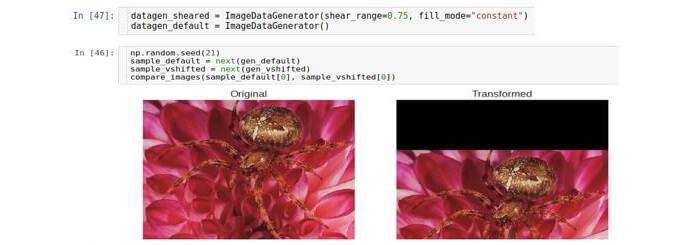
विस्थापन को नियंत्रित करने वाले पैरामीटर को
shear_range कहा जाता है और मूल छवि में क्षैतिज रेखा और इस छवि में (गणितीय अर्थ में) इस रेखा के विचलन के बीच विचलन कोण (रेडियन में) से मेल खाती है।
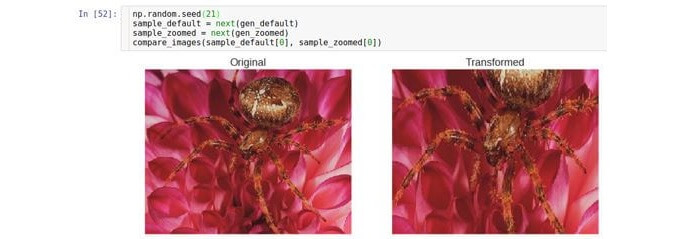
ज़ूम इन / आउट करें

इस प्रकार का परिवर्तन मूल छवि को अनुमानित या हटा देता है।
Zoom_range पैरामीटर ज़ूम फ़ैक्टर को नियंत्रित करता है।
उदाहरण के लिए, यदि
zoom_range 0.5 है, तो ज़ूम फैक्टर का चयन रेंज [0.5, 1.5] से किया जाएगा।
क्षैतिज फ्लिप

ऊर्ध्वाधर अक्ष के सापेक्ष छवि को फ़्लिप करता है। इसे
क्षैतिज_फ्लिप पैरामीटर का उपयोग करके चालू या बंद किया जा सकता है।
ऊर्ध्वाधर फ्लिप

क्षैतिज अक्ष के चारों ओर छवि को फ़्लिप करता है।
ऊर्ध्वाधर_फ्लिप पैरामीटर (प्रकार का बूलियन) इस परिवर्तन की उपस्थिति या अनुपस्थिति को नियंत्रित करता है।
संयोग
हम एक ही समय में पूरक के सभी वर्णित प्रकार के परिवर्तनों को लागू करते हैं और देखते हैं कि क्या होता है। याद रखें कि सभी परिवर्तनों के लिए मापदंडों को एक निश्चित सीमा से यादृच्छिक रूप से चुना जाता है; इसलिए, हमें महत्वपूर्ण विविधता के साथ नमूनों का एक सेट प्राप्त करना चाहिए।
हम सभी उपलब्ध मापदंडों के साथ
ImageDataGenerator आरंभ
करते हैं और छवि पर लाल हाइड्रेंट की जांच करते हैं।

ध्यान दें कि
निरंतर भरण मोड का उपयोग केवल बेहतर विज़ुअलाइज़ेशन के लिए किया गया था। अब हम
निकटतम नामक एक अधिक उन्नत पैडिंग मोड का उपयोग करेंगे; यह मोड रिक्त पिक्सेल के निकटतम मौजूदा पिक्सेल का रंग प्रदान करता है।
निष्कर्ष
यह लेख इमेज प्रीप्रोसेसिंग के लिए बुनियादी तकनीकों का अवलोकन प्रदान करता है, जैसे: स्केलिंग, सामान्यीकरण, घूर्णन, स्थानांतरण और क्रॉपिंग। उन्होंने
कायरों का उपयोग करते हुए इन परिवर्तन तकनीकों के कार्यान्वयन और तकनीकी रूप से दोनों में गहरी सीखने की प्रक्रिया में उनका परिचय
दिखाया (
इमेजडेटाजनर वर्ग) और वैचारिक रूप से (डेटा पूरक)।