मैं दूर से शुरू करूँगा। पिछली सर्दियों में मैं FPGA में होस्ट किए गए कोर के साथ एक यूएसबी डिवाइस बनाने के लिए हुआ था। बेशक, मैं वास्तव में इस बस की वास्तविक बैंडविड्थ की जांच करना चाहता था। आखिरकार, नियंत्रक में - बहुत कुछ करना है। आप हमेशा कह सकते हैं कि देरी है, या वहाँ पर। FPGAs के मामले में, मुझे एक ब्लॉक पम्पिंग डेटा दिखाई देता है, इसलिए उसने मुझे बताया कि इसमें डेटा है। लेकिन मैंने निर्धारित किया कि सब कुछ संसाधित किया गया था, और मैं एक नया हिस्सा स्वीकार करने के लिए तैयार हूं (उसी समय, यह पहले से ही उसी समापन बिंदु के दूसरे बफर में डेटा प्राप्त करता है)। महान, बहुत पहले उपाय से तत्परता सेट करें और देखें कि क्या होता है जब यूएसबी रोक के बिना "हथौड़ा" कर सकता है।
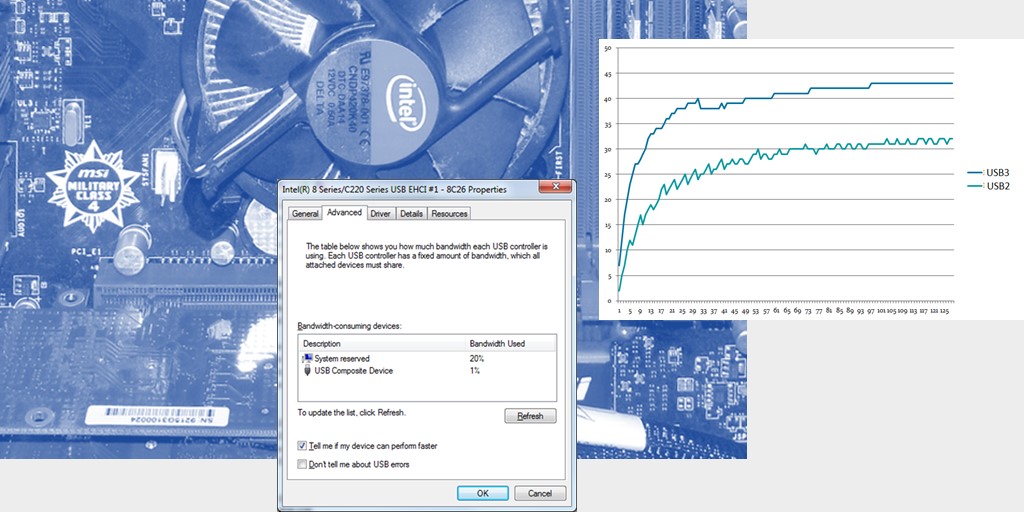
लेकिन यह एक आश्चर्यजनक बात है। यदि यूएसबी 2.0 डिवाइस "ब्लू" कनेक्टर (जो यूएसबी 3.0 है) में फंस गया है, तो गति एक है। अगर "काला" में - एक और। यहाँ USB रिकॉर्डिंग गति बनाम डेटा लंबाई का मेरा ग्राफ है। USB3 और USB2 कनेक्टर के प्रकार हैं, डिवाइस हमेशा USB 2.0 HS है।
मैंने अलग-अलग मशीनों में कोशिश की। परिणाम करीब है। कोई भी मुझे इस घटना की व्याख्या नहीं कर सका। बाद में, मुझे सबसे संभावित कारण मिला। और इसका कारण बहुत सरल है। यहाँ USB 2.0 नियंत्रक के गुण हैं:

"ब्लू" कनेक्टर को नियंत्रित करने वाले नियंत्रक नहीं करते हैं। और अंतर सिर्फ 20 प्रतिशत का है।
इससे हम यह निष्कर्ष निकालते हैं कि बैंडविड्थ सीमाएं हमेशा बस के भौतिक गुणों से निर्धारित नहीं होती हैं। कभी-कभी कुछ और चीजें भी सुपरिम्पोज हो जाती हैं। हम इन दिनों इस ज्ञान के साथ गुजरते हैं।
प्राथमिक प्रयोग
So. यह सब काफी सांसारिक शुरू हुआ। एक कार्यक्रम की जाँच थी। एक साथ कई डिस्क पर डेटा लिखने की प्रक्रिया की जाँच की गई। हार्डवेयर सरल है: चार पीसीआई-स्लॉट्स के साथ एक मदरबोर्ड है। AHCI नियंत्रकों के साथ बिल्कुल समान कार्ड सभी स्लॉट्स में डाले गए हैं, जिनमें से प्रत्येक विशेष रूप से PCIe X1 का समर्थन करता है।

प्रत्येक कार्ड में 4 ड्राइव हैं।
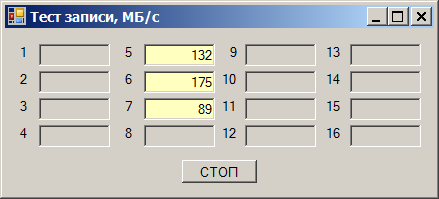
और फिर निम्नलिखित प्रभाव का पता चलता है। हम एक डिस्क लेते हैं और इसके लिए डेटा लिखना शुरू करते हैं। हमें प्रति सेकंड 180 से 220 मेगाबाइट की गति मिलती है (इसके बाद, मेगाबाइट 1024 * 1024 बाइट हैं):

हम दूसरी ड्राइव लेते हैं। उस पर लिखने की गति 170 से 190 एमबी / एस है:

हम दोनों को तुरंत लिखते हैं - हमें गति की एक गिरावट मिलती है:
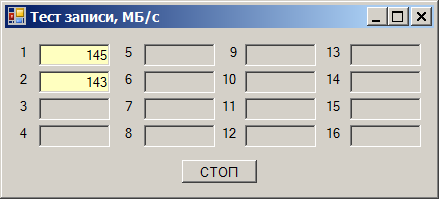
कुल गति 290 एमबी / एस के आसपास है। लेकिन आश्चर्यजनक बात यह है कि हमने इस कार्यक्रम को उसी ड्राइव पर नहीं, बल्कि अन्य चैनलों पर डिबेट किया। और वहां सब कुछ ठीक था। हम जल्दी से उन चैनलों को स्थानांतरित करते हैं (वे दूसरे कार्ड से गुजरेंगे), हमें एक उत्कृष्ट नौकरी मिलती है:
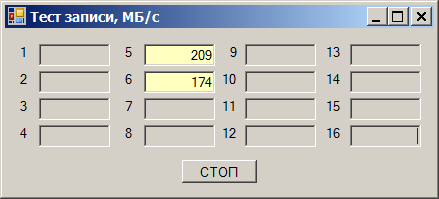
मैं एक अच्छे क्षेत्र में एक स्लॉट खरीदूंगा
मुझे तुरंत कहना होगा कि यह किसी और के घटकों पर सब कुछ दोष देने के लायक नहीं है। यहां सब कुछ हमारे द्वारा लिखा गया है, कार्यक्रम से ही शुरू होता है, ड्राइवरों के साथ समाप्त होता है। तो पूरे डेटा पथ पर नजर रखी जा सकती है। अज्ञात केवल तभी आता है जब अनुरोध हार्डवेयर में गया था।
प्रारंभिक विश्लेषण के बाद, यह पता चला कि गति "लंबे" PCIe स्लॉट में सीमित नहीं है और "कम" वाले में सीमित है। लंबे वे हैं जहां आप x16 कार्ड डाल सकते हैं (हालांकि उनमें से कोई भी x4 से अधिक मोड में काम करता है), और छोटे वाले केवल एक्स 1 कार्ड से हैं।

सब कुछ ठीक होगा, लेकिन वर्तमान कार्ड में नियंत्रक, PCIex1 के अलावा अन्य मोड में काम नहीं कर सकते हैं। यही है, सभी नियंत्रक स्लॉट लंबाई की परवाह किए बिना, बिल्कुल समान परिस्थितियों में होना चाहिए! लेकिन नहीं। कौन "लंबे" में रहता है - तेजी से काम करता है, जो "कम" में - धीरे-धीरे। सब ठीक है। और तेज - कितना तेज? तीसरी ड्राइव जोड़ें, तीनों को लिखें।
"लघु" स्लॉट में, सीमा अभी भी लगभग 290 एमबी / एस है:

"लंबी" में - 400 एमबी / एस के क्षेत्र में:

मैंने पूरा इंटरनेट सर्च किया। सबसे पहले, कुछ समय बाद मैं पहले से ही उन लेखों से हँसा, जहां यह कहता है कि PCIe 1 के जीन और 1 के लिए जीन 2 250 और 500 MB / s है। ये कच्चे मेगाबाइट हैं। ओवरहेड के कारण (मैं इस गैर-रूसी शब्द का उपयोग सेवा विनिमय को प्रदर्शित करने के लिए करता हूं जो कि मुख्य 2 के समान लाइनों के साथ जाता है) जीन 2 के लिए हमें उपयोगी स्ट्रीम के प्रति सेकंड 400 मेगाबाइट मिलते हैं। दूसरे, मैं हठपूर्वक मैजिक नंबर 290 के बारे में कुछ भी नहीं पा सका (आगे देखते हुए - मुझे अभी भी यह नहीं मिला)।
बहुत बढ़िया। हमारे नियंत्रकों के समावेश की टोपोलॉजी को देखने की कोशिश कर रहा है। यहाँ यह है (013-015 - ये डिवाइस नाम प्रत्यय हैं जिनके द्वारा मैंने किसी तरह अंतर करने के लिए उनका मिलान किया)। हरा तेज है, लाल धीमा है।
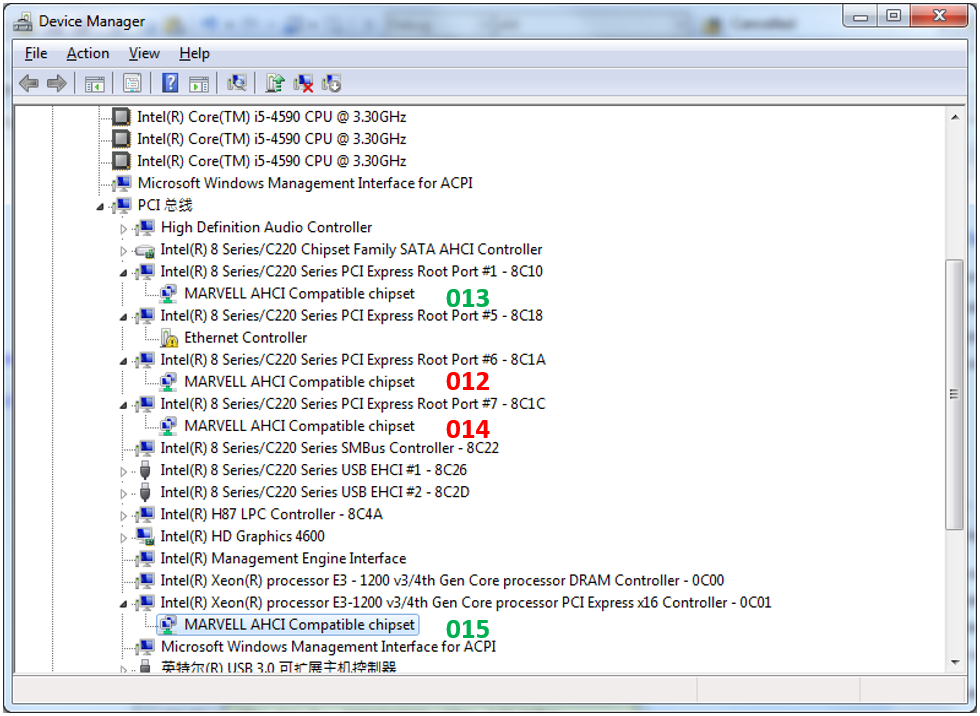
नियंत्रक "015" हम भी नहीं मानते हैं। वह वीडियो कार्ड के लिए डिज़ाइन किए गए विशेषाधिकार प्राप्त स्लॉट में रहता है। लेकिन 013 वें 014 वें से 012 वें के रूप में एक ही स्विच से जुड़ा हुआ है। वह अलग कैसे है?
कुछ लेख कहते हैं कि मैक्स पेलोड सेटिंग्स में अलग-अलग कार्ड अलग-अलग हो सकते हैं। मैंने सभी कार्डों के कॉन्फ़िगरेशन स्थान का अध्ययन किया - यह पैरामीटर सभी के लिए समान, न्यूनतम संभव मूल्य में है। इसके अलावा, इस मदरबोर्ड के चिपसेट के लिए प्रलेखन का कहना है कि इसका कोई अन्य अर्थ नहीं हो सकता है।

सामान्य तौर पर, मैंने कॉन्फ़िगरेशन स्पेस में सब कुछ के माध्यम से अफवाह की - सब कुछ पहचान के साथ कॉन्फ़िगर किया गया है। और गति अलग है! चिपसेट के लिए बार-बार प्रलेखन को फिर से पढ़ें - कोई बैंडविड्थ सेटिंग्स नहीं। प्राथमिकताएं - हां, उनके बारे में कुछ लिखा गया है, लेकिन अन्य चैनलों पर लोड की पूर्ण अनुपस्थिति में परीक्षण किए जाते हैं! यानी यह उनमें नहीं है।
बस के मामले में, मैं भी रुकावट कार्यक्रम बंद कर दिया। प्रोसेसर की मात्रा पागल राशियों के लिए बढ़ गई है, क्योंकि अब यह लगातार मूर्खता से तत्परता बिट को पढ़ता है, लेकिन गति रीडिंग नहीं बदली है। इसलिए समस्याओं के लिए इस सबसिस्टम को दोष देना असंभव है।
और अन्य बोर्डों के बारे में क्या?
हमने मदरबोर्ड को बिल्कुल उसी में बदलने की कोशिश की। कोई बदलाव नहीं। उन्होंने प्रोसेसर को बदलने की कोशिश की (विश्वास करने के कारण थे कि यह मजाक था)। इसके अलावा, गति में कोई बदलाव नहीं (लेकिन पुराने प्रोसेसर वास्तव में कबाड़ है)। हमने एक नई पीढ़ी का मदरबोर्ड स्थापित किया - सब कुछ बस सभी स्लॉट्स पर उड़ता है। इसके अलावा, अधिकतम गति 400 नहीं है, लेकिन 418 मेगाबाइट प्रति सेकंड, यहां तक कि "लंबी", यहां तक कि "शॉर्ट" स्लॉट में भी

लेकिन यहाँ - कोई चमत्कार नहीं। सामान्य हाथ आंदोलन (पहले से ही इन दिनों के लिए उपयोग किया जाता है) के साथ, हम कॉन्फ़िगरेशन स्थान को पढ़ते हैं और देखते हैं कि मैक्स पेलोड पैरामीटर 128 पर नहीं, बल्कि 256 बाइट्स पर सेट है।
बड़े पैकेट का आकार - कम पैकेट। उन्हें भेजने के लिए कम ओवरहेड - अधिक उपयोगी डेटा एक ही समय में चलाने का प्रबंधन करता है। यह सही है।
तो दोष किसे देना है?
मैंने दस्तावेजों के संदर्भ में, शीर्षक से प्रश्न का सटीक उत्तर नहीं दिया। लेकिन मेरा विचार निम्न पथ पर चला गया: मान लें कि प्रवाह प्रतिबंध चिपसेट के अंदर सेट है। यह प्रोग्राम नहीं किया जा सकता है, यह कसकर सेट है, लेकिन यह है। उदाहरण के लिए, यह प्रत्येक अंतर के लिए प्रति सेकंड 290 मेगाबाइट के बराबर है। एक युगल। अधिक - यह पहले से ही अपने आंतरिक तंत्र पर चिपसेट के अंदर कहीं कट गया है। इसलिए, "लंबे" स्लॉट में (जहां आप x4 तक कार्ड छड़ी कर सकते हैं), चिपसेट के अंदर हमारे कार्ड के लिए कुछ भी नहीं काटा जाता है, और हम X1 बस की भौतिक सीमा के खिलाफ आराम करते हैं। "शॉर्ट" कनेक्टर में, हम इस सीमा में चलते हैं।
वास्तव में, यह जांचना आसान नहीं है, लेकिन बहुत सरल है। हम 013 वें स्लॉट में AHCI नहीं, बल्कि एसएएस कंट्रोलर से चिपके रहते हैं, जो एक ही बार में 8 ड्राइव परोसता है और PCIe मोड में x4 तक काम कर सकता है। हम 4 स्मार्ट एसएसडी ड्राइव को इससे जोड़ते हैं। हम रिकॉर्डिंग गति को देखते हैं - आत्मा जितना आनन्दित करती है:

अब हम उन 4 डिस्क को जोड़ते हैं जो पहले परीक्षणों में दिखाई दी थीं। SSD का प्रदर्शन अनुमानित रूप से डूबा हुआ है:

हम एसएएस नियंत्रक से गुजरने वाली कुल गति की गणना करते हैं, हम प्रति सेकंड 1175 मेगाबाइट प्राप्त करते हैं। 4 से विभाजित करें (इतनी सारी लाइनें "लंबे" स्लॉट में जाती हैं), हम प्राप्त करते हैं ... ड्रम रोल ... 293 मेगाबाइट प्रति सेकंड। कहीं मैंने यह संख्या पहले ही देख ली थी!
तो, इस परियोजना के ढांचे के भीतर, यह साबित हो गया कि समस्या हमारे कार्यक्रम या ड्राइवर में नहीं है, बल्कि चिपसेट की अजीब सीमाओं में है, जो शायद "कसकर" वायर्ड हैं। प्रोजेक्ट में उपयोग किए जा सकने वाले मदरबोर्ड को चुनने की पद्धति विकसित की गई थी। लेकिन सामान्य तौर पर, हम निम्नलिखित निष्कर्ष निकालते हैं।
निष्कर्ष
- अक्सर वास्तविक जीवन में, उपकरण में सैद्धांतिक रूप से संभव से कम प्रदर्शन होता है। यहां तक कि ड्राइवरों द्वारा प्रतिबंध भी लगाए जा सकते हैं, जैसा कि यूएसबी के मामले में दिखाया गया है। कभी-कभी उन उपकरणों को उठाना संभव है जो (या जिनके ड्राइवर) में इस तरह के प्रतिबंध नहीं हैं।
- सीमाएं भी अनिर्दिष्ट हो सकती हैं, लेकिन स्पष्ट रूप से व्यक्त की गई हैं।
- बहुत सारे लेख जो कहते हैं कि PCIe जीन की एक अंतर जोड़ी है। 1 और जीन 2 प्रति सेकंड लगभग 250 और 500 मेगाबाइट देता है, गलत हैं। वे एक दूसरे से एक ही त्रुटि की नकल करते हैं - प्रति सेकंड कच्चे डेटा का एक मेगाबाइट। ओवरहेड इंटरफ़ेस के कई स्तरों पर जम जाता है। 128 बाइट्स के मैक्स पेलोड के साथ, PCIe gen2 वास्तव में प्रति सेकंड लगभग 400 मेगाबाइट प्राप्त करता है। PCIe की नई पीढ़ियों में, सब कुछ थोड़ा बेहतर होना चाहिए, क्योंकि भौतिक एन्कोडिंग 8b / 10b नहीं है, लेकिन अधिक किफायती है, लेकिन अभी तक कोई ड्राइव नियंत्रक नहीं मिला है, जिस पर व्यवहार में इसे सत्यापित किया जाए।