
मार्च में, गर्व नाम "हैंड्स-औकी" के साथ हमारी विकास टीम ने हैकथॉन AI.HACK के डिजिटल क्षेत्रों पर दो दिनों के लिए सावधानीपूर्वक लड़ाई लड़ी। कुल मिलाकर, विभिन्न कंपनियों के पाँच कार्य प्रस्तावित थे। हमने Gazpromneft के कार्य पर ध्यान केंद्रित किया: B2B ग्राहकों से ईंधन की मांग का पूर्वानुमान। ईंधन खरीद क्षेत्र, ईंधन संख्या, ईंधन का प्रकार, मूल्य, तिथि, और ग्राहक आईडी के अनुसार, अज्ञात आंकड़ों के अनुसार, यह जानना आवश्यक था कि भविष्य में कोई विशेष ग्राहक कितना खरीदेगा। आगे देखना - हमारी टीम ने इस समस्या को उच्चतम सटीकता के साथ हल किया। ग्राहकों को तीन खंडों में विभाजित किया गया था: बड़े, मध्यम और छोटे। और मुख्य कार्य के अलावा, हमने प्रत्येक सेगमेंट के लिए कुल खपत का पूर्वानुमान भी बनाया है।
नवंबर 2016 से 15 मार्च, 2018 की अवधि के लिए ग्राहकों की खरीद पर अनलोडिंग में डेटा शामिल था (1 जनवरी, 2018 से 15 मार्च, 2018 की अवधि के लिए, डेटा में वॉल्यूम शामिल नहीं थे)।
नमूना डेटा:
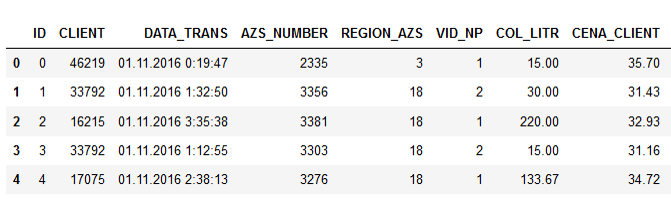
स्तंभों के नाम अपने लिए बोलते हैं, मुझे लगता है कि इसका कोई मतलब नहीं है।
प्रशिक्षण नमूने के अलावा, आयोजकों ने इस वर्ष के तीन महीनों के लिए एक परीक्षण नमूना प्रदान किया। कीमतें कॉरपोरेट क्लाइंट्स के लिए हैं, जो खाते में विशेष छूट, विशेष ऑफ़र और अन्य बिंदुओं पर एक विशेष ग्राहक की खपत पर निर्भर करते हैं।
प्रारंभिक डेटा प्राप्त करने के बाद, हम, हर किसी की तरह, मशीन लर्निंग के शास्त्रीय तरीकों की कोशिश करना शुरू कर दिया, एक उपयुक्त मॉडल बनाने की कोशिश की, कुछ संकेतों के सहसंबंध को महसूस करने के लिए। हमने अतिरिक्त सुविधाएँ, निर्मित प्रतिगमन मॉडल (XGBoost, CatBoost, आदि) निकालने की कोशिश की।
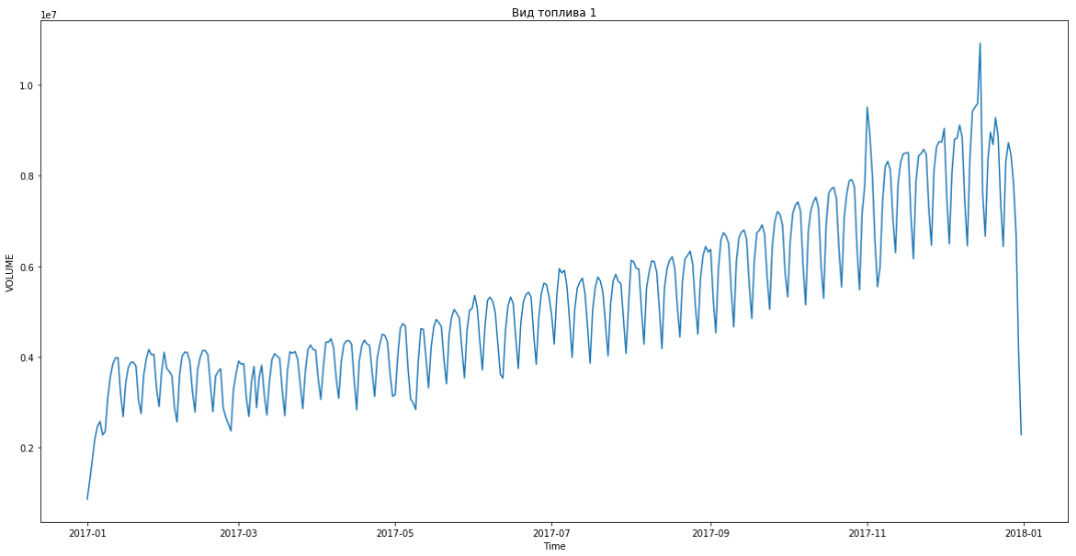
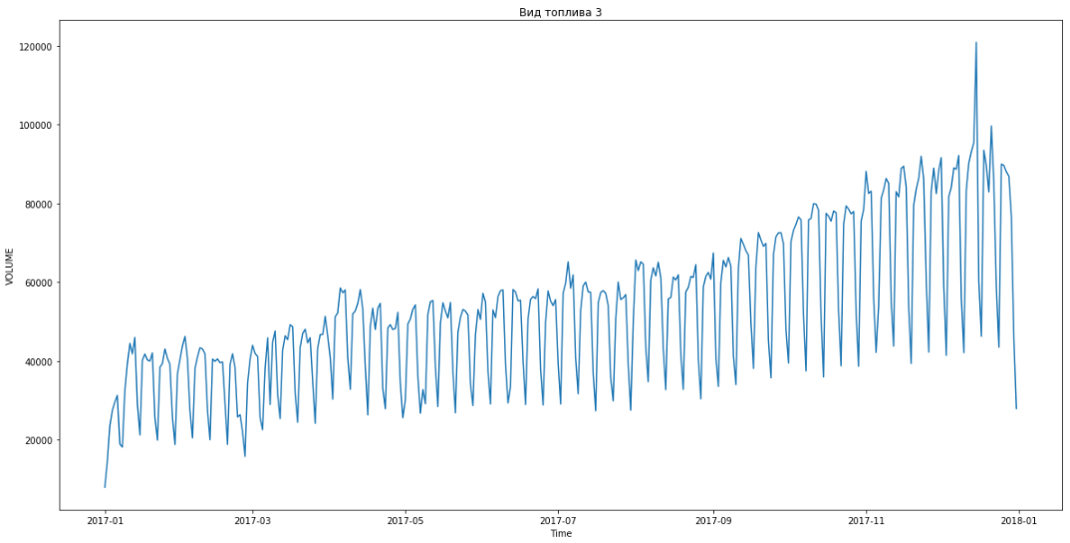
समस्या के बयान ने शुरू में ही निहित किया कि ईंधन की कीमत किसी तरह मांग को प्रभावित करती है, और इस निर्भरता को और अधिक सटीक रूप से समझने के लिए आवश्यक है। लेकिन जब हमने प्रदान किए गए डेटा का विश्लेषण करना शुरू किया, तो हमने देखा कि कीमत के साथ मांग का संबंध नहीं है।

सहसंबंध:
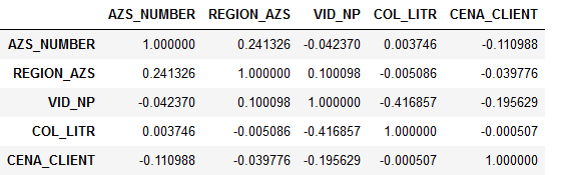
यह पता चला कि लीटर की संख्या व्यावहारिक रूप से कीमत पर निर्भर नहीं करती है। यह काफी तार्किक रूप से समझाया गया था। चालक राजमार्ग पर चला जाता है, उसे ईंधन भरने की आवश्यकता होती है। उसके पास एक विकल्प है: या तो वह एक गैस स्टेशन पर ईंधन भरेगा जिसके साथ कंपनी सहयोग करती है, या कुछ अन्य। लेकिन ड्राइवर को परवाह नहीं है कि ईंधन की लागत कितनी है - संगठन इसके लिए भुगतान करता है। इसलिए, वह बस निकटतम गैस स्टेशन को बंद कर देता है और टैंक को भरता है।
हालाँकि, सभी प्रयासों और आजमाए गए मॉडलों के बावजूद, न्यूनतम स्वीकार्य पूर्वानुमान सटीकता (आधार रेखा) प्राप्त करना संभव नहीं था, जिसे इस सूत्र का उपयोग करके गणना की गई थी (सममित माध्य निरपेक्ष प्रतिशत त्रुटि):
हमने सभी विकल्पों की कोशिश की, कुछ भी काम नहीं किया। और फिर यह हम में से एक को मशीन सीखने पर थूकने और अच्छे पुराने आंकड़ों की ओर मोड़ने के लिए हुआ: बस ईंधन के प्रकार के लिए औसत मूल्य लें, सत्यापित करें और देखें कि आपको क्या सटीकता मिलती है।
इसलिए हमने पहले थ्रेशोल्ड मान को पार किया।
हम सोचने लगे कि परिणाम को कैसे बेहतर बनाया जाए। हमने ग्राहक समूहों, ईंधन के प्रकार, क्षेत्र, और गैस स्टेशन संख्याओं द्वारा माध्य मान लेने की कोशिश की। समस्या यह थी कि परीक्षण डेटा में लगभग 30% ग्राहक आईडी जो प्रशिक्षण के नमूने में थे, गायब थे। यही है, नए ग्राहक परीक्षण में दिखाई दिए। यह एक गलती थी जो आयोजकों ने जाँच नहीं की। लेकिन हमें समस्या का हल खुद ही निकालना था। हम नए ग्राहकों की खपत को नहीं जानते थे, और इसलिए उनके लिए पूर्वानुमान नहीं बना सकते थे। और यहाँ मशीन लर्निंग ने बस मदद की।
पहले चरण में, लापता डेटा पूरे नमूने के औसत या औसत मूल्य से भरा था। और फिर यह विचार सामने आया: मौजूदा डेटा के आधार पर नए ग्राहक प्रोफाइल क्यों नहीं बनाएं? हमारे पास क्षेत्र द्वारा कटौती है, कितने ग्राहक वहां ईंधन खरीदते हैं, किस आवृत्ति, किस प्रकार के साथ। हमने मौजूदा ग्राहकों को अलग-अलग क्षेत्रों के लिए विशिष्ट प्रोफाइल संकलित किया, और उन पर XGBoost का प्रशिक्षण दिया, जो तब नए ग्राहकों के प्रोफाइल को "पूरा" करता था।
इसने हमें पहले स्थान पर तोड़ने की अनुमति दी। परिणामों को संक्षेप करने से पहले अभी भी तीन घंटे बाकी थे। हम खुश थे और बोनस समस्या को हल करना शुरू कर दिया - तीन महीने पहले सेगमेंट द्वारा पूर्वानुमान।
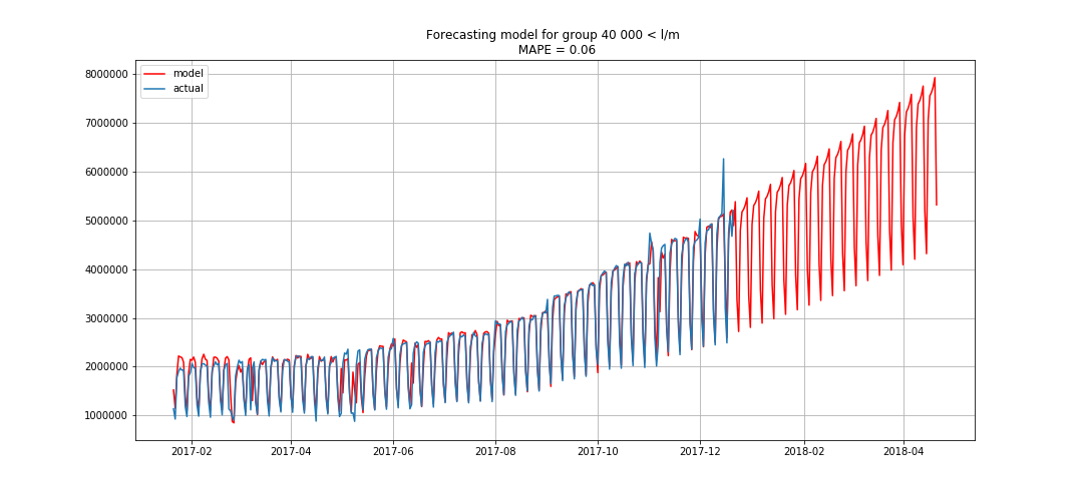
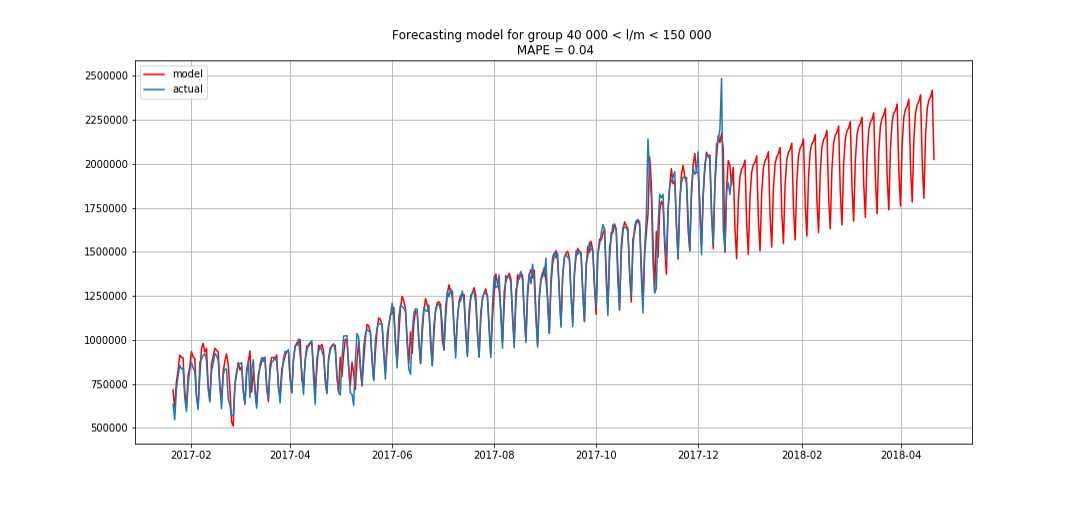
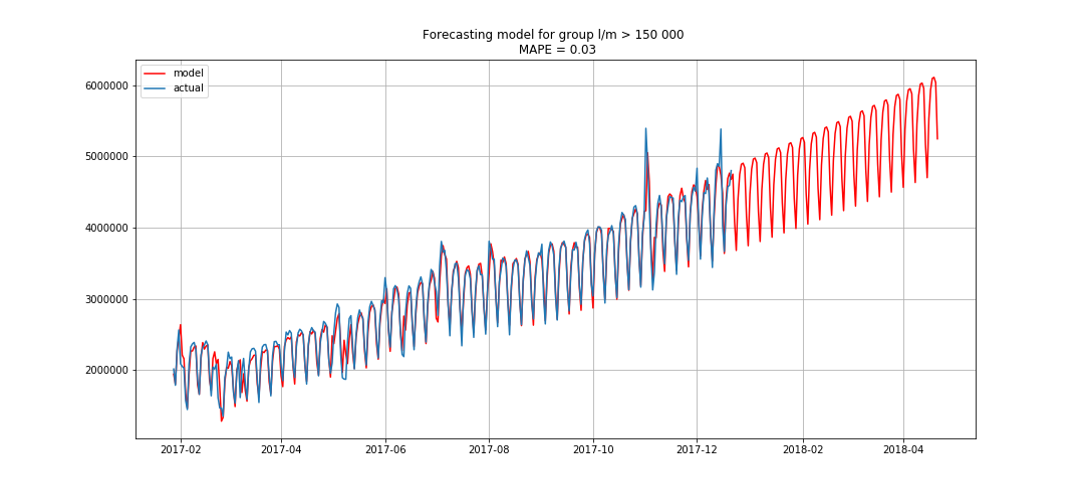
ब्लू वास्तविक डेटा दिखाता है, लाल - पूर्वानुमान। त्रुटि 3% से 6% तक थी। उदाहरण के लिए, मौसमी चोटियों और छुट्टियों को ध्यान में रखते हुए और भी सटीक गणना की जा सकती है।
जब हम ऐसा कर रहे थे, एक टीम ने हमारे साथ पकड़ना शुरू किया, जिससे हर 15-20 मिनट में हमारा परिणाम बेहतर हो गया। हम भी उपद्रव करने लगे और मामले में कुछ करने की ठान ली।
उन्होंने समानांतर में एक और मॉडल बनाना शुरू किया, जिसने आंकड़ों को महत्व के आधार पर रैंक किया, इसकी सटीकता पहले की तुलना में थोड़ी कम थी। और जब प्रतियोगियों ने हमें हराया, तो हमने दोनों मॉडलों को संयोजित करने का प्रयास किया। इससे हमें मीट्रिक में थोड़ी वृद्धि हुई - 37.24671% तक, नतीजतन, हमने अपना पहला स्थान हासिल किया और इसे अंत तक बनाए रखा।
जीत के लिए, हमारी रुकी-औकी टीम को 100 हजार रूबल, सम्मान, सम्मान और ... आत्म-सम्मान से भरा हुआ एक प्रमाण पत्र मिला, मैं स्पा गई थी! ;)
जेट इन्फोसिस्टम्स डेवलपमेंट टीम